
Most "auth in Node.js" tutorials stop right at the point where the interesting decisions start. You sign a JWT with jsonwebtoken, stick it in a header, verify it on each request, and the article ends with "and that's it, you have authentication." Then you deploy that to production and within a quarter you've discovered that you can't log a user out, your tokens are too big, refresh logic is a mess, and your "JWT secret" is a single string that hasn't been rotated since the repo was created.
This piece is for the next step. You already know what a JWT is. You can decode the header on jwt.io with your eyes closed. The question is what to do once the toy version is behind you and the system has real users, mobile clients, third-party integrations, and a security review on the calendar.
Let's go beyond the basics.
The Real Cost Of "Stateless"
The JWT pitch is that the server doesn't have to store anything. You sign claims, the client carries them, you verify the signature, done. That's true until you need to log someone out, change their permissions immediately, or kick a compromised device. Then the "stateless" property turns into "I can't revoke this thing."
You have three honest options when this hits:
The first is short-lived tokens. Set the access token's exp to something like 5-15 minutes. The window of damage is limited because the token just times out. This is the foundation everything else builds on.
The second is a denylist. Maintain a server-side set of revoked token IDs (jti claim) and check it on every request. This works, but you've now reintroduced the database lookup that JWTs were supposed to eliminate. You've built a session table with extra cryptography.
The third is two tokens: a short access token plus a long-lived refresh token. The access token is stateless and expires quickly. The refresh token is checked against the database. Logout deletes the refresh token. Revocation is fast because the access token can't survive long enough to matter.
The third option is what most real Node systems land on, and it's the one most tutorials gloss over. So let's actually build it.
Refresh Tokens, Done Right
A refresh token is just a string the client trades for a new access token. The hard parts are: how do you store it, how do you rotate it, and how do you know when one's been stolen.
The shape of the flow:
import { SignJWT } from 'jose';
import { randomBytes, createHash, randomUUID } from 'node:crypto';
const ACCESS_TTL = '10m';
const REFRESH_TTL_DAYS = 30;
export async function issueTokenPair(userId: string, deviceId: string) {
const access = await new SignJWT({ sub: userId })
.setProtectedHeader({ alg: 'EdDSA', kid: currentSigningKey.id })
.setIssuedAt()
.setExpirationTime(ACCESS_TTL)
.setAudience('api.example.com')
.setIssuer('auth.example.com')
.sign(currentSigningKey.privateKey);
const refreshPlain = randomBytes(32).toString('base64url');
const refreshHash = createHash('sha256').update(refreshPlain).digest('hex');
await db.refreshTokens.insert({
hash: refreshHash,
userId,
deviceId,
familyId: randomUUID(),
expiresAt: new Date(Date.now() + REFRESH_TTL_DAYS * 86_400_000),
createdAt: new Date(),
});
return { access, refresh: refreshPlain };
}A few things worth pulling apart in that snippet.
The refresh token is random bytes, not a JWT. You don't need claims in it, the server is the source of truth. Treating it as an opaque secret is simpler, smaller, and easier to revoke.
You store the hash, never the raw value. If your database leaks, the attacker gets SHA-256 digests, not usable tokens. Same principle as password hashing, just less expensive because the input has 256 bits of entropy and doesn't need bcrypt.
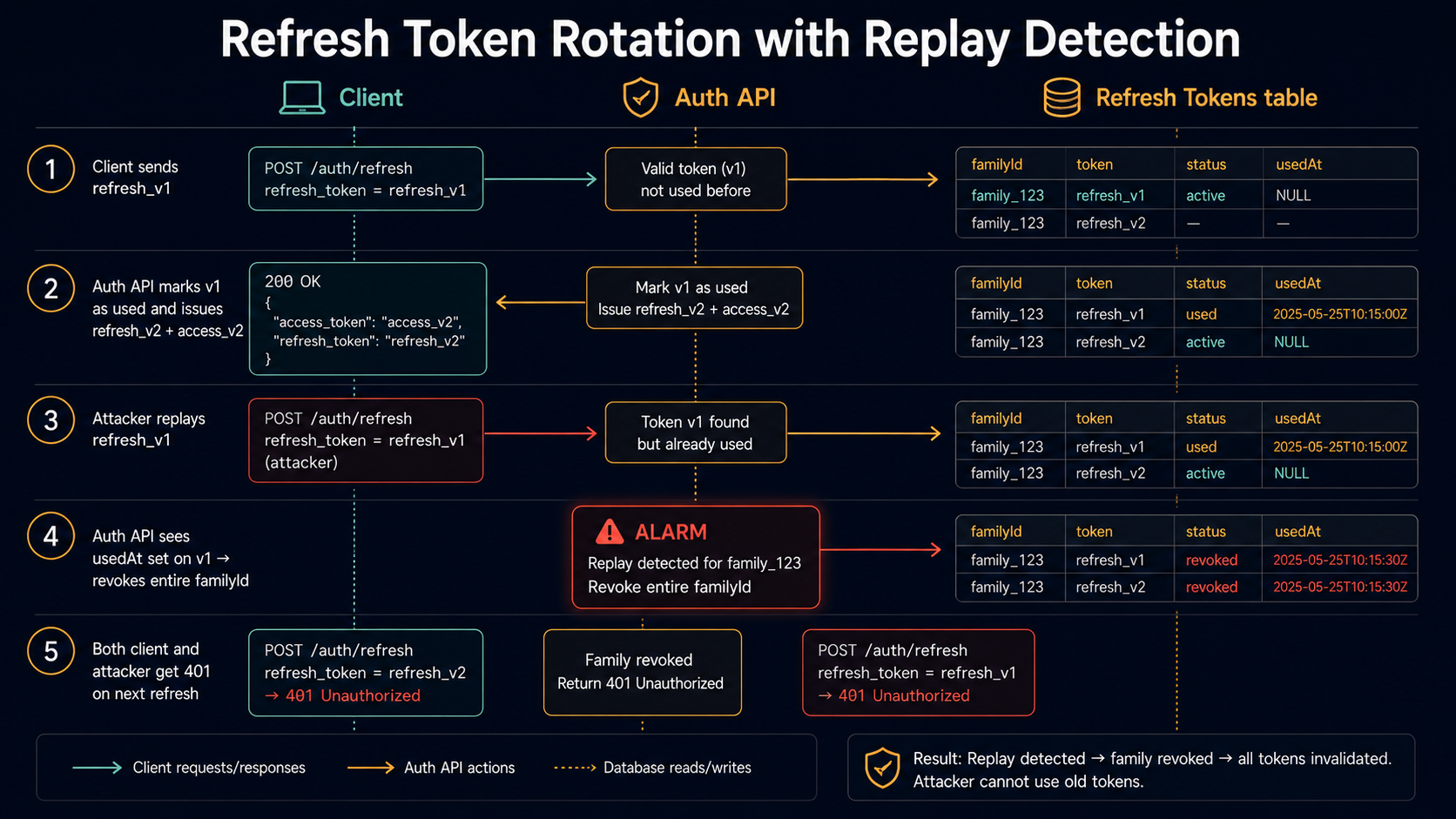
The familyId matters. It's the key to detecting replay attacks. Every refresh issued by trading in an older refresh belongs to the same family. If two clients try to use the same refresh token, one of them is an attacker, and you can revoke the entire family in one query.
The deviceId lets the user see and revoke individual sessions ("log out my iPad") without invalidating everything.
The rotation itself looks like this:
export async function rotateRefresh(refreshPlain: string) {
const hash = createHash('sha256').update(refreshPlain).digest('hex');
const row = await db.refreshTokens.findByHash(hash);
if (!row) throw new InvalidRefreshError();
if (row.expiresAt < new Date()) throw new ExpiredRefreshError();
if (row.usedAt) {
// This refresh was already redeemed. Either the client retried after a
// network drop, or an attacker is replaying a stolen token. We don't know
// which, so we assume the worst: kill the whole family.
await db.refreshTokens.revokeFamily(row.familyId);
throw new ReplayedRefreshError();
}
await db.refreshTokens.markUsed(row.id);
return issueTokenPairForExistingFamily(row.userId, row.deviceId, row.familyId);
}The "replay = kill the family" rule is the part people skip. Without it, an attacker who steals a refresh token can keep using the stolen copy alongside the legitimate user; with it, the second use trips an alarm and revokes everything. The legitimate user is forced to re-authenticate once, which is a fine price for catching theft.
This pattern has a name in the OAuth world: refresh token rotation with reuse detection. Auth0 documents it, the IETF OAuth 2.0 Security Best Current Practice (RFC 9700) recommends it, and most managed auth providers do it by default. Doing it yourself is maybe 50 lines of code plus a table.
Where Does The Token Live On The Client
This is where security reviewers get loud and many guides stay quiet. You signed a token. Now where does it sit on the browser?
The two real options are an httpOnly cookie and JavaScript-readable storage (localStorage, sessionStorage, or an in-memory variable).
A cookie marked httpOnly, secure, sameSite=strict (or lax) is the safer default for a browser app. JavaScript can't read it, so an XSS attack can't steal it directly. The trade-off is CSRF, but sameSite plus a same-site API means CSRF is mostly a solved problem for first-party requests, and you can add a double-submit token if you're paranoid.
LocalStorage is convenient for SPAs that fetch from a cross-origin API. It's also accessible to every script that runs on your page. If a single dependency in your dependency tree gets compromised (and the npm ecosystem has had this happen, repeatedly), your tokens leave with the next request. There's no "httpOnly" for localStorage.
The hybrid that works well for a Next.js or Remix app talking to a same-domain API: access token in memory, refresh token in an httpOnly cookie. The access token is short-lived, never persisted, vanishes on page refresh, and when it does the cookie-bound refresh quietly issues a new one. XSS can grab the in-memory access token (window of damage: 10 minutes) but can't touch the refresh.
For native mobile apps, both tokens live in the OS keychain (iOS Keychain, Android Keystore). Don't put auth tokens in AsyncStorage. Don't.
For machine-to-machine, neither side has a browser, neither has a user. You use a different OAuth flow entirely.
OAuth And OIDC, Demystified For Backend Devs
You'll eventually hit the moment where someone says "we need to log in with Google" or "we're integrating with their SSO." That's OAuth 2.0 territory, layered with OpenID Connect (OIDC) when you actually need the user's identity.
The short version: OAuth is for authorization (can this client access this resource), OIDC is for authentication (who is this user). OIDC is built on top of OAuth and adds an id_token (a JWT) that proves identity. If you only use OAuth without OIDC, you get an access token to call APIs, but you don't actually know who logged in.
There are four flows in the spec that matter in 2026. Three of them you might use, one of them you shouldn't.
Authorization Code with PKCE is the default. The browser redirects to the identity provider, the user logs in, the provider redirects back with a code, and your backend trades the code (plus a PKCE verifier) for an access_token, refresh_token, and id_token. PKCE (RFC 7636) replaced the older "client secret in the browser" model for SPAs and mobile, and it's now recommended for confidential clients too. Extra defense costs nothing.
Client Credentials is the machine-to-machine flow. No user, no browser. A service ID and secret are traded directly for an access token. Use this for internal service-to-service auth where the caller represents an application, not a person.
Device Code is the flow you use for things without a browser: a smart TV, a CLI tool, a Raspberry Pi. The device shows a code, the user enters it on another device's browser, and the original device polls for the token.
The flow you shouldn't use is Implicit (response_type=token in the URL fragment). It was the original SPA flow before PKCE. It's deprecated, both in spec guidance and in real provider docs. If a tutorial tells you to use implicit flow in 2026, it's stale.
For Node, the libraries to actually pick up:
openid-clientby Filip Skokan: the gold-standard OIDC client. It handles discovery, PKCE, token endpoint exchanges, and signature validation. Maintained, audited, and the reference implementation that other Node OIDC libraries quietly follow. The v6 release (late 2024) is a complete functional rewrite, so older snippets you find online usingIssuer.discoverandnew issuer.Client()are v5 API.oauth4webapi: same author, lower-level, no Node-isms, works in edge runtimes (Cloudflare Workers, Vercel Edge). Pick this if you're not on a traditional Node server.- Passport: still works, still common, but the OAuth strategies are thin wrappers and the project's pace is slower than it used to be. Fine for legacy. For a new service,
openid-clientis the more honest pick.
Here's the modern v6 shape:
import * as client from 'openid-client';
const server = new URL('https://accounts.google.com');
const clientId = process.env.GOOGLE_CLIENT_ID!;
const clientSecret = process.env.GOOGLE_CLIENT_SECRET!;
const config = await client.discovery(server, clientId, clientSecret);
// Login redirect
const codeVerifier = client.randomPKCECodeVerifier();
const codeChallenge = await client.calculatePKCECodeChallenge(codeVerifier);
const state = client.randomState();
// Stash codeVerifier + state in an httpOnly cookie
const authUrl = client.buildAuthorizationUrl(config, {
redirect_uri: 'https://example.com/auth/callback',
scope: 'openid email profile',
code_challenge: codeChallenge,
code_challenge_method: 'S256',
state,
});
// Callback
const currentUrl = new URL(req.url, 'https://example.com');
const tokens = await client.authorizationCodeGrant(config, currentUrl, {
pkceCodeVerifier: codeVerifier,
expectedState: state,
});
// tokens has id_token, access_token, refresh_token, claims()
const claims = tokens.claims()!;
const userId = claims.sub;A subtle point most people miss: don't trust the id_token payload until you've validated it. openid-client does this for you (signature check, issuer match, audience match, exp/nbf, nonce), but if you ever roll your own (say, validating an incoming id_token from a different service), you have to validate all of those. Skipping any one is a CVE waiting to happen.
Sessions Aren't Dead
For a server-rendered app (Next.js with traditional sessions, Remix, Nuxt, Express + EJS), a server-side session is often still the cleanest answer. Cookie carries an opaque session ID. Server looks it up in Redis or Postgres. Done.
The advantages people forget about JWTs:
- Revocation is one row delete.
- Permission changes apply on the next request.
- The cookie is tiny: 32 bytes versus a few hundred.
- You don't have to think about key rotation, denylists, or refresh token mechanics.
The trade-off is the database hit per request, but if your sessions are in Redis on the same network, that's sub-millisecond and not worth optimizing away. Almost every real "we should JWT for performance" argument falls apart when you measure.
The libraries that hold up in 2026:
iron-sessionfor Next.js / Node: encrypted, signed cookies, no external store needed. Great for low-volume apps.express-sessionwithconnect-redis: the boring, battle-tested combo. Still works.- better-auth: newer, full-featured (sessions + OAuth + 2FA + magic links), gaining real adoption. Took on the role Lucia had before Lucia's maintainer sunset the project in 2024.
The pattern I've seen work cleanly: sessions for the browser, JWTs for the API. Your web app uses cookie sessions because they're simple and revocable. Your mobile app and external API consumers use OAuth + JWT because cookies are awkward on those transports. The session can be exchanged for a short-lived JWT when the browser needs to call a service that only speaks tokens.
Key Rotation And JWKS
Here's the part of the security review that catches teams off guard: "When was the last time you rotated your JWT signing key?"
If you used jsonwebtoken with a single JWT_SECRET env var and you've never thought about this, the answer is "never." That secret has been the same since the repo was created. If anyone (an ex-employee, a leaked Heroku snapshot, an old CI run) has seen it, they can sign tokens that pass verification today.
The fix isn't "rotate the secret on a calendar." The fix is building rotation in from the start so it's a non-event when you do it.
The mechanism is JSON Web Key Sets (JWKS, RFC 7517). The server publishes a list of valid public keys at /.well-known/jwks.json, each tagged with a kid (key ID). Tokens include the kid in the header. Verifiers look up the right key by kid. When you rotate, you publish the new key alongside the old one, start signing with the new one, and remove the old one after every token signed with it has expired.
import { createPublicKey, generateKeyPairSync } from 'node:crypto';
import { exportJWK } from 'jose';
// Two keys: previous and current. New tokens always use current.
// Verifiers accept both until previous-key tokens expire.
const previousKey = loadKeyFromKMS('jwt-key-2026-04');
const currentKey = loadKeyFromKMS('jwt-key-2026-05');
export async function jwks() {
return {
keys: [
{ ...(await exportJWK(currentKey.publicKey)), kid: currentKey.id, alg: 'EdDSA', use: 'sig' },
{ ...(await exportJWK(previousKey.publicKey)), kid: previousKey.id, alg: 'EdDSA', use: 'sig' },
],
};
}The verifier side, using jose:
import { createRemoteJWKSet, jwtVerify } from 'jose';
const JWKS = createRemoteJWKSet(new URL('https://auth.example.com/.well-known/jwks.json'));
export async function verifyAccess(token: string) {
const { payload } = await jwtVerify(token, JWKS, {
issuer: 'auth.example.com',
audience: 'api.example.com',
});
return payload;
}createRemoteJWKSet caches the response and refreshes it when a kid shows up that isn't in cache, so rotation works without code changes on the consuming side. This is the same pattern Google, Auth0, Okta, and every other identity provider uses.
EdDSA (Ed25519) is the algorithm I'd default to today. Smaller keys, smaller signatures, no curve-vs-curve gotchas, no padding choices. RS256 is fine and more widely supported. HS256 (HMAC) is acceptable when you control both ends and the secret stays inside one trust boundary, but the moment you have multiple verifiers, you need asymmetric.
The Pitfalls You'll Hit
A short list of things that have shipped in real Node services and caused real incidents.
Forgetting to pin the algorithm. jsonwebtoken historically defaulted to whatever the token header said, which meant an attacker could send alg: none and skip signature verification entirely. Modern versions fixed this, but if you ever manually call verify(), pass algorithms: ['EdDSA'] explicitly. Don't let the token tell you how to verify itself.
HMAC key reused as a public key. This was a famous library-level CVE: if your verifier accepts both RS256 and HS256, an attacker can take your public RSA key (which is, well, public), use it as an HMAC secret, sign a token with alg: HS256, and your verifier will happily check it because the "secret" matches. Pin the algorithm. Always.
Missing exp, iss, aud checks. A token with no exp is valid forever. A token without aud validation could be a token meant for another service in your fleet. jose's jwtVerify checks exp by default and lets you assert issuer and audience. Use those options. Don't ship without them.
Storing the refresh token in localStorage. This is the most common "secure by mistake" pattern. The whole point of refresh rotation is that the long-lived secret is hard to steal. If it lives in localStorage, it isn't.
Letting "logout" mean "delete the cookie". Deleting the access token cookie logs out the browser. It does nothing about the refresh token still sitting in the database, or about access tokens still alive on other devices. Real logout deletes the refresh row server-side. Real "log me out everywhere" deletes every refresh row for the user.
exp in seconds, not milliseconds. JWT exp is seconds since epoch. JavaScript's Date.now() is milliseconds. Off by 1000x means tokens that look like they'll expire in a year actually expire in 6 hours. Use setExpirationTime('10m') from jose and don't compute seconds by hand.
No clock skew tolerance. If your auth server's clock is 3 seconds ahead of your API server's clock, every freshly issued token will look "not yet valid" (nbf) on the API side for the first 3 seconds. jose accepts a clockTolerance option; set it to something small like 5 seconds.
A Threat-Model Lens
Most of this article is mechanical: how to do the thing safely. The other half of auth is knowing what you're defending against, because the right answer depends on the threat.
A few common threats and what actually mitigates them:
Stolen access token. Mitigation: short expiry. Damage window is bounded by exp. Refresh rotation can't help here because the access token is already valid.
Stolen refresh token. Mitigation: rotation + replay detection. The first time the attacker uses it, you see the legitimate user's next refresh fail with usedAt set, and the family dies.
XSS reads tokens out of localStorage. Mitigation: don't put tokens in localStorage. Use httpOnly cookies for anything long-lived.
CSRF against a cookie-based session. Mitigation: sameSite cookies + a CSRF token for state-changing requests + same-origin API where possible.
Compromised signing key. Mitigation: JWKS-based rotation. You can pull the bad key from the published keyset in seconds and existing tokens still verify against the new one.
Compromised dependency in the auth path. This one's the scariest because it's hard to prevent and hard to detect. Mitigation: minimize the attack surface, fewer dependencies, audited libraries, lockfiles, dependabot, SBOM. None of this is auth-specific but auth is exactly where you don't want a supply-chain surprise.
You don't have to defend against everything. You have to be honest about which threats apply to your system and which mitigations you've actually shipped, not which ones you've intended to ship since Q3.
So What Should You Actually Build
If you're starting a new Node service today and want to stop reading and pick something:
For a single web app on a single domain, server-side sessions in Redis. iron-session if it's Next.js, express-session + connect-redis if it's Express. Don't reach for JWTs until you have a reason.
For a multi-service API platform, OIDC via openid-client with refresh token rotation, JWTs signed with EdDSA, JWKS rotation, access token in memory, refresh in httpOnly cookie or native keychain. That's the boring, well-documented, audited path.
For external developer-facing APIs (your customers' apps call your API), OAuth 2.0 with Authorization Code + PKCE, scopes per token, audited consent screens, and refresh rotation. This is the mode where you become an identity provider, and it's harder than the inside-the-house cases.
For most teams in the middle, managed auth is worth it. Auth0, Clerk, Stack Auth, Logto, Keycloak (self-hosted) all do the boring parts well and let you focus on whatever your actual product does. Rolling your own is fine as a learning exercise; it's an awkward thing to maintain across a team for years.
What none of these change is the bit you do have to understand: where tokens live, how they're rotated, what your revocation story is, and what you're defending against. Get those clear in your head and the library choice becomes a detail.





