Picture this. You have three Node.js workers all subscribed to the same queue. A job lands - "send the Friday digest email to user 9182" - and for a reason nobody traced yet, two workers pull the same job and both call sendEmail(). The user gets the digest twice. Support ticket. Slack thread. Postmortem.
Or this. A nightly cron runs from three replicas to be "resilient." All three replicas fire at midnight. The reconciliation script that's only supposed to run once now runs three times in parallel, and one of them sees stale data, and now there's an inventory row claiming -7 units.
Or this. A user clicks "Confirm" twice in 80 milliseconds because your loading spinner showed up late, and two requests hit two different pods, and now there are two charges on their card.
All three of these come from the same root cause. You have more than one process able to do the same thing at the same time, and nothing is stopping them from doing it.
That's what distributed locks are for. Not for performance, not for cleverness - for the unglamorous job of making sure that at most one process holds permission to do a piece of work at any given moment, even when those processes live on different machines and don't know each other exist.
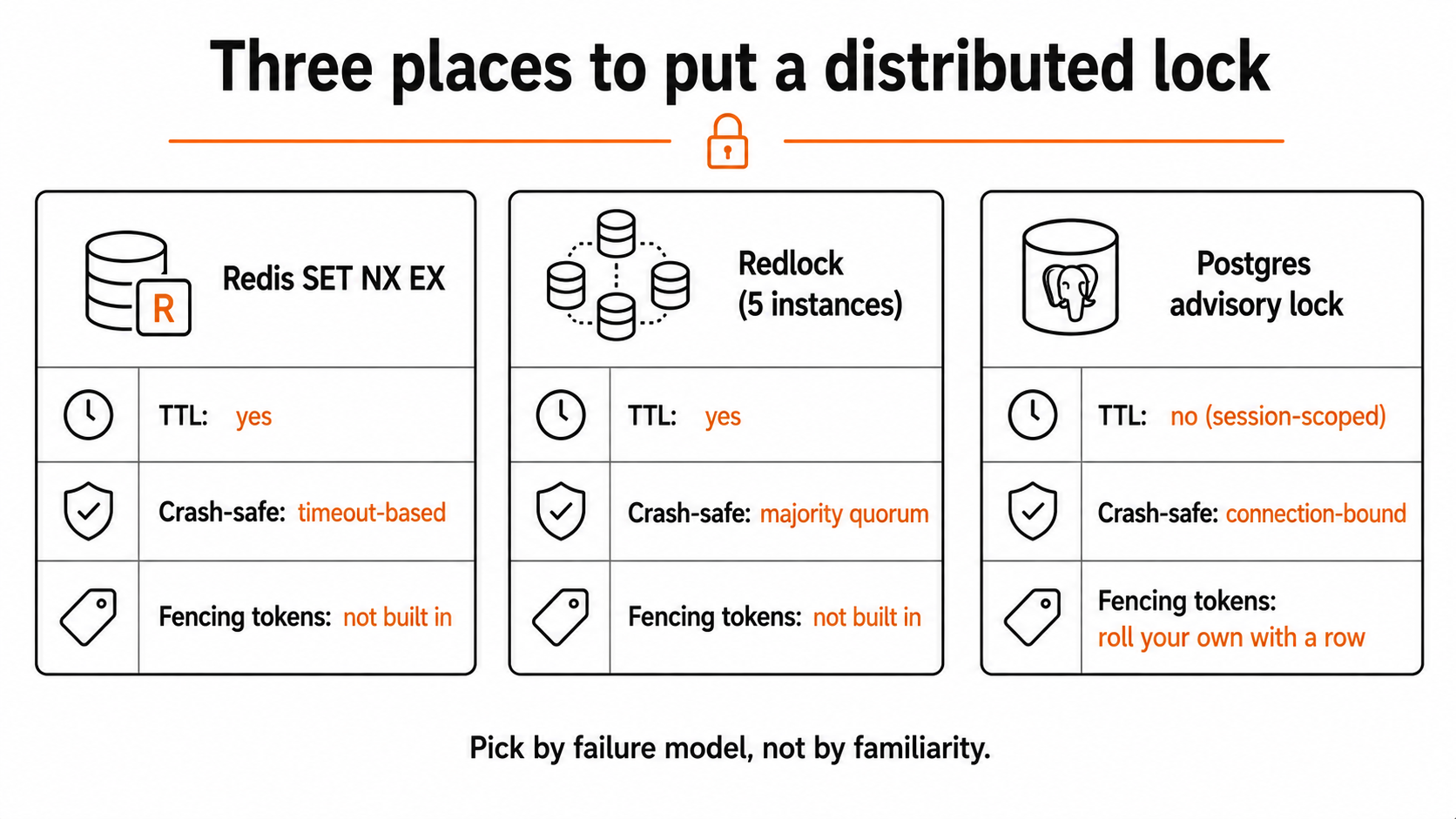
This piece is about how to actually build that in Node.js. We'll start with the naive version everyone writes first, watch it break, walk through the real-world building blocks - Redis with SET NX EX, the Redlock algorithm, PostgreSQL advisory locks, fencing tokens - and end with the patterns I'd actually trust on a production system.
Why Process-Level Locks Aren't Enough
The first time you reach for a lock in Node.js, your instinct is to use something like a Map of mutexes in memory. Maybe you grab async-mutex from npm and slap a per-key lock around the critical section:
import { Mutex } from 'async-mutex';
const locks = new Map<string, Mutex>();
async function withLock<T>(key: string, fn: () => Promise<T>): Promise<T> {
let m = locks.get(key);
if (!m) {
m = new Mutex();
locks.set(key, m);
}
return m.runExclusive(fn);
}
// Usage
await withLock(`user:${userId}:digest`, () => sendDigest(userId));This works perfectly. As long as your Node.js app is one process. The second you scale to two pods, you have two locks maps, two Mutex instances per key, and neither of them knows the other exists. Worker A grabs its local lock, Worker B grabs its local lock, both call sendDigest, and you're back where you started.
The fundamental problem is that the lock has to live somewhere both processes can see. That means outside Node.js. Usually that's Redis, sometimes PostgreSQL, sometimes Zookeeper or etcd if you've already invested in them. The choice matters less than understanding what you're actually buying - and what you're not.
The Smallest Thing That Could Possibly Work: SET NX EX
Redis ships a primitive built almost exactly for this. The SET command with the NX and EX flags says "set this key to this value, but only if it doesn't already exist, and let it expire after N seconds."
import Redis from 'ioredis';
import { randomUUID } from 'node:crypto';
const redis = new Redis();
async function acquireLock(key: string, ttlSeconds: number) {
const token = randomUUID();
const ok = await redis.set(`lock:${key}`, token, 'EX', ttlSeconds, 'NX');
return ok === 'OK' ? token : null;
}
async function releaseLock(key: string, token: string) {
// Only release if we still own it
const script = `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
`;
return redis.eval(script, 1, `lock:${key}`, token);
}A few things to notice, because each of them prevents a specific bug:
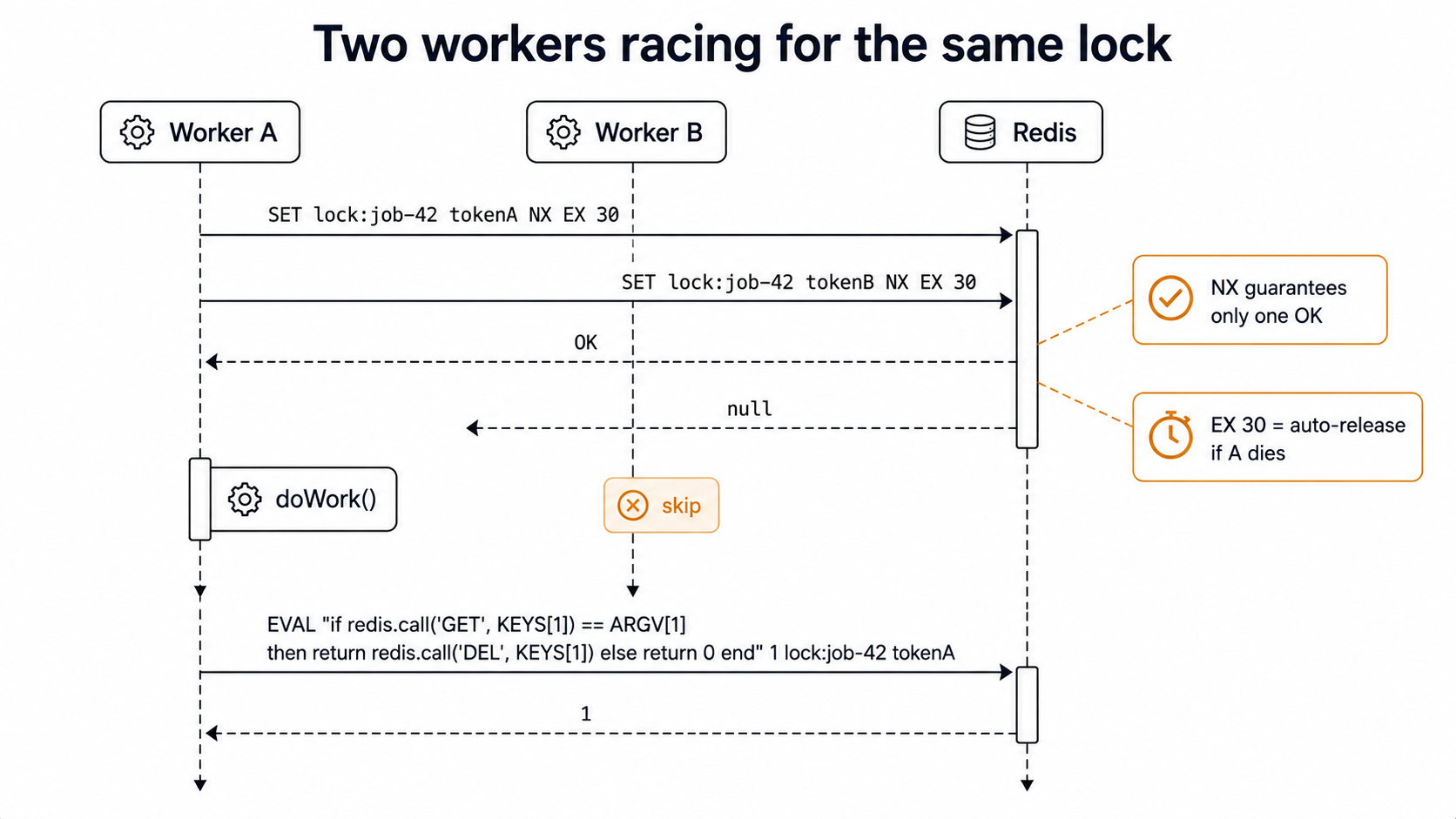
The NX flag is the "if not exists" part. If two workers race to acquire the same key, exactly one of them will get OK back. The other gets null. There is no in-between. Redis is single-threaded for command execution, so this check-and-set is atomic at the server.
The EX flag is non-negotiable. If you forget the TTL and your worker crashes between acquiring and releasing, the lock is held forever. You'll get a 3am page because every replica is silently failing to acquire a key that no living process owns.
The random token is the part most tutorials skip and most teams later regret. When you DEL the key on release, you have to make sure you're deleting your lock, not somebody else's. If your worker hangs for 31 seconds on a TTL of 30, the lock expires, another worker grabs it, then your original worker wakes up and calls DEL - you've just unlocked someone else's critical section. The Lua script enforces "only delete if the value still matches the token I wrote." That check-and-delete also has to be atomic, which is why it's a Lua EVAL rather than two round trips.
That's the whole basic pattern. Wrap it in a helper:
async function withLock<T>(
key: string,
ttlSeconds: number,
fn: () => Promise<T>,
): Promise<T | null> {
const token = await acquireLock(key, ttlSeconds);
if (!token) return null;
try {
return await fn();
} finally {
await releaseLock(key, token);
}
}
// Usage
const result = await withLock(`user:${userId}:digest`, 30, () => sendDigest(userId));
if (result === null) {
console.log('Another worker is already handling this user, skipping.');
}For 90% of "stop duplicate jobs" use cases, this is the right answer. It's simple, it's well-understood, and it survives the failure mode you care about most - a worker dying without releasing.
The Part Where The TTL Bites You
The TTL is what makes the lock crash-safe. It's also the thing that makes it subtly wrong.
The problem is this. You set a TTL of 30 seconds because that feels like enough headroom for the job. The job actually takes 35 seconds today because the third-party API is slow. At second 30, your lock expires. At second 31, another worker acquires the same lock. At second 35, your original worker finishes - and at this point both workers think they hold the lock.
If your critical section is "send an email," you've now sent it twice. If it's "transfer $50 from account A to B," you've transferred it twice. The TTL didn't protect you because the world doesn't agree with you about how long your job took.
There are three ways to deal with this, and you usually want a combination.
1. Pick a TTL longer than your worst-case job duration, by a comfortable margin. Measure. Don't guess. If sendDigest p99 is 8 seconds, a 30-second TTL leaves a 22-second buffer. If something pushes p99 above 25 seconds, your alerting should fire long before your lock starts overlapping.
2. Renew the lock while you're still working. Sometimes called lock extension or heartbeating. Periodically (say, every TTL/3 seconds), you re-issue the lock with a fresh expiry - but only if you still own it. The atomic check-and-extend looks like this:
async function extendLock(key: string, token: string, ttlSeconds: number) {
const script = `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("PEXPIRE", KEYS[1], ARGV[2])
else
return 0
end
`;
const result = await redis.eval(script, 1, `lock:${key}`, token, ttlSeconds * 1000);
return result === 1;
}You start a setInterval that extends the lock every 10 seconds for a 30-second TTL. If the extension returns 0, it means you no longer own the lock (someone else took it after it expired) and you should bail out of the work immediately - finishing it now would be unsafe.
3. Make the work idempotent at the storage layer, not just at the lock layer. This is the one nobody likes hearing, because it's the most work. But if your critical section is "INSERT a row," put a unique constraint on the natural key so a second insert fails. If it's "send email," store an email_send_attempt record before sending and check it on retry. The lock becomes a cheap and best-effort serialization, and idempotency at the storage layer is your real correctness boundary. This is the pattern Stripe uses with idempotency keys, and it scales better than anything else when the stakes are real.
A lock alone is probably enough for "send the Friday digest." A lock plus idempotent storage is what you need for "process this payment."
Redlock, And Why It's More Controversial Than You'd Think
If a single Redis instance is your lock store, then the moment that Redis goes down or has a network blip, every lock is gone. For some systems that's acceptable. For others - financial, inventory, anything with real money - it's not.
Redis's author Antirez published an algorithm called Redlock that distributes the lock across N independent Redis instances (typically 5) and considers the lock acquired only if a majority responds OK within a short window. The npm package redlock (the one by Mike Marcacci, still actively maintained) implements this:
import Redis from 'ioredis';
import Redlock from 'redlock';
const redlock = new Redlock(
[
new Redis({ host: 'redis-a' }),
new Redis({ host: 'redis-b' }),
new Redis({ host: 'redis-c' }),
new Redis({ host: 'redis-d' }),
new Redis({ host: 'redis-e' }),
],
{
retryCount: 3,
retryDelay: 200,
},
);
await redlock.using([`user:${userId}:digest`], 30_000, async (signal) => {
if (signal.aborted) throw signal.error;
await sendDigest(userId);
});The using helper handles acquisition, automatic extension, the signal for cooperative abort if the lock is lost mid-work, and release. If you're going to use Redlock, this is the API to use - the lower-level acquire/release is harder to use correctly.
Now, the controversy. In 2016, Martin Kleppmann (the Designing Data-Intensive Applications author) wrote a widely-read critique arguing that Redlock isn't safe enough for use cases that need real correctness - for example, anything where you'd be unhappy with even a rare double-execution of a critical section. His argument is that any algorithm based on timeouts and clock-bounded majorities can be broken by GC pauses, OS scheduler delays, and clock drift on the client. A worker can think it still holds the lock when, by the wall clock, it expired several seconds ago. Antirez responded; both posts are worth reading if you're thinking of using this in something serious.
The practical takeaway is straightforward. Use Redlock if you want a step up from single-Redis availability, but don't believe it gives you correctness in the database-transaction sense. For "best-effort serialization, please don't run twice," it's great. For "money must not move twice," you still need idempotency at the storage layer (see the previous section), or you need a different lock primitive entirely.
Fencing Tokens: The Bit That Makes Locks Actually Safe
The thing that makes locks fragile is the assumption that "I hold the lock" implies "any operation I do right now is the only one happening." That assumption breaks every time your process is delayed for longer than the TTL and the storage layer doesn't know.
Kleppmann's recommended fix is the fencing token. The idea is simple: every time someone acquires the lock, the lock service hands out a monotonically increasing number. The protected resource - the database, the file, whatever - remembers the highest token it's ever seen and rejects any write tagged with a lower one.
Worker A acquires lock → gets token 33
Worker A pauses (GC, OS suspend, whatever)
Lock expires
Worker B acquires lock → gets token 34
Worker B writes to DB with token 34 → DB stores "last token = 34"
Worker A wakes up, still thinks it holds the lock
Worker A writes to DB with token 33 → DB rejects (33 < 34)Redis on its own does not give you fencing tokens. You can build them - for example, by combining INCR on a counter key with SET NX EX on the lock, atomically through a Lua script - but the harder part is enforcing the token on the resource. If your "resource" is a Postgres row, you need a lock_token bigint column and conditional updates. If it's a file in S3, you need to encode the token into the object key or compare against a metadata field. If it's an external API call (sending email, charging a card), the API has to support idempotency keys, which is the same idea by another name.
This is the strongest pattern in this article. If your critical section's worst case is "we did a duplicate action somewhere downstream," fencing tokens close that gap. Most teams skip them because they take more wiring than dropping in redlock. That's a defensible trade-off - just know which trade-off you're making.
PostgreSQL Advisory Locks: The Quiet Workhorse
If you're already using Postgres and you don't want to introduce Redis just for locking, Postgres has a feature that gets surprisingly little attention: advisory locks. These are lock primitives at the connection level that Postgres manages for you, with two flavours - session-scoped and transaction-scoped.
import { Client } from 'pg';
async function withTxAdvisoryLock<T>(
client: Client,
key: bigint,
fn: () => Promise<T>,
): Promise<T | null> {
await client.query('BEGIN');
try {
const { rows } = await client.query<{ pg_try_advisory_xact_lock: boolean }>(
'SELECT pg_try_advisory_xact_lock($1)',
[key.toString()],
);
if (!rows[0].pg_try_advisory_xact_lock) {
await client.query('ROLLBACK');
return null;
}
const result = await fn();
await client.query('COMMIT');
return result;
} catch (err) {
await client.query('ROLLBACK');
throw err;
}
}A few things make this pleasant. The lock is automatically released when the transaction commits or rolls back (or when the session ends, for session locks) - there's no TTL because Postgres tracks it through the connection. There's no separate service to operate. And it composes naturally with the actual database work you're doing, because it lives in the same transaction.
The constraint is that the key must be a 64-bit integer (or two 32-bit ones), so you typically hash your logical key:
import { createHash } from 'node:crypto';
function lockKey(name: string): bigint {
const buf = createHash('sha256').update(name).digest();
// Take 8 bytes, interpret as signed 64-bit
return buf.readBigInt64BE(0);
}
const key = lockKey(`user:${userId}:digest`);When does this beat Redis? When your critical section is mostly database work anyway, when you don't want operational overhead from another service, and when you care about strong consistency. Postgres advisory locks don't have the clock-skew / GC-pause vulnerabilities that Redis-based locks have, because the lock state lives on the database server and is tied to your connection's session - if your worker dies, the connection drops, and Postgres releases the lock cleanly.
The cost is throughput. Each lock is a transaction round trip. If you're acquiring tens of thousands of short-lived locks per second, Redis will be faster. For "one lock per cron job" or "one lock per user per minute," advisory locks are a great default.
Where Distributed Locks Actually Earn Their Keep
A few patterns where I reach for these by default in Node.js services.
Singleton cron jobs across replicas. You have a service deployed with three replicas for HA. You also want a job to run once an hour. Without coordination, all three run it. With a lock keyed on cron:hourly-rollup:2026-05-16-14 (date and hour in the name) and a TTL slightly longer than the worst-case job duration, only the first replica to reach the scheduler wins. The other two no-op. If the winning replica dies mid-job, the TTL releases the lock and the next hourly tick is unaffected.
Idempotency at the queue boundary. Even if your queue (BullMQ, SQS, RabbitMQ) claims "at least once" delivery, a transient redelivery while a worker is still processing can put the same job on two workers. Wrapping the handler in withLock(jobId, …) makes that a no-op rather than a duplicate execution. BullMQ actually does some of this internally with its own lock keys; the pattern still applies for cross-cutting handlers or for jobs identified by a payload field rather than an ID.
External resource reservations. Booking systems, inventory deductions, slot allocations. The lock isn't the correctness boundary here (the database transaction is), but it serializes the intent so you don't waste DB transactions racing against each other.
Rate-limited integrations. If you have an integration with a third party that only allows one in-flight call at a time per customer (yes, those exist), a per-customer lock around the call site is the simplest way to enforce that across all your workers.
What I don't reach for them for. Anything that should fundamentally be a transaction - money movement, order finalization, inventory write - should live inside the database with proper row locks or serializable isolation, not behind a separate lock service that the database doesn't know about. Locks help you avoid double work; transactions help you avoid wrong work. They're not interchangeable.
The Failure Modes That Will Eventually Find You
If you're going to put any of this in production, the bugs you'll see are usually one of these. Treat this section as a checklist of things to verify before you ship.
The "I forgot the TTL" bug. Worker crashes holding the lock, lock lives forever, every subsequent run silently no-ops. Symptom: a job that used to run starts not running, with no error. Add a "lock acquired after waiting > Xs" metric so you notice the queue piling up.
The "I'm deleting someone else's lock" bug. Worker takes longer than TTL, lock expires, another worker takes it, original worker finishes and calls DEL without a value check. Now worker 3 takes the lock immediately, and worker 2 is still running its critical section. Fix: always use the token-based check-and-delete Lua script. Don't trust your own naive DEL.
The "extension that never extends" bug. You add a setInterval to extend the lock every 10 seconds, but the interval is scheduled on the event loop, and your CPU-bound critical section starves it. By second 35 the lock has expired and the worker doesn't know. Fix: do CPU-heavy work in a worker thread, keep the main loop alive to handle extensions, and bail out of the work if an extension returns 0.
The "lock works locally, fails on Kubernetes" bug. Pods get rescheduled with no warning. A SIGTERM gives you ~30 seconds to shut down cleanly. If your critical section is mid-flight, you need to either (a) finish quickly and release, (b) have an idempotent retry that handles the leftover lock once it TTLs out, or (c) catch SIGTERM and let the lock release explicitly. Quietly assuming your process won't be interrupted is what makes "works locally, weird in prod" a permanent thread on your team's Slack.
The "Redis was actually a single instance pretending to be a cluster" bug. You have Redis Sentinel or a managed Redis that fails over to a replica during incidents. The replica may not have replicated your SET NX EX yet when the failover happens. Now your lock is gone, two workers acquire it on the new primary, and you're in trouble. This is the failure mode Redlock was designed to mitigate. If you only have a single Redis and you care about this case, switch to advisory locks or Redlock, or accept the risk explicitly.
The "clock drift in containers" bug. If your TTL logic assumes both your client and Redis agree on wall-clock time, NTP skew or a container with a frozen clock can quietly make timeouts behave wrong. For high-stakes locks, use fencing tokens so absolute time doesn't matter - only the order of token issuance does.
A Sketch Of A Production-Worthy Wrapper
Putting most of this together, here's the shape of a lock helper I'd be comfortable shipping. It's not a library - it's a starting point you can paste and adapt.
import Redis from 'ioredis';
import { randomUUID } from 'node:crypto';
const RELEASE_SCRIPT = `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
`;
const EXTEND_SCRIPT = `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("PEXPIRE", KEYS[1], ARGV[2])
else
return 0
end
`;
export class LockLost extends Error {}
export async function withDistributedLock<T>(
redis: Redis,
rawKey: string,
opts: { ttlMs: number; renewEveryMs?: number },
fn: (signal: { lost: boolean }) => Promise<T>,
): Promise<T | null> {
const key = `lock:${rawKey}`;
const token = randomUUID();
const acquired = await redis.set(key, token, 'PX', opts.ttlMs, 'NX');
if (acquired !== 'OK') return null;
const signal = { lost: false };
const renewEvery = opts.renewEveryMs ?? Math.floor(opts.ttlMs / 3);
const timer = setInterval(async () => {
try {
const ok = await redis.eval(EXTEND_SCRIPT, 1, key, token, opts.ttlMs);
if (ok !== 1) signal.lost = true;
} catch {
signal.lost = true;
}
}, renewEvery);
try {
const result = await fn(signal);
if (signal.lost) throw new LockLost(`Lost lock on ${rawKey} during work`);
return result;
} finally {
clearInterval(timer);
try {
await redis.eval(RELEASE_SCRIPT, 1, key, token);
} catch {
// Lock will expire on its own; don't crash the caller on release failure.
}
}
}A few notes on what's in there and what's deliberately not.
The signal.lost field is checked after the work finishes. The caller's fn can also check it mid-work to bail early if it's doing something long-running. That's the only honest way to handle lost-lock - we can't truly preempt a running async function, only signal to it that it should stop trusting the lock.
The release error is swallowed. That feels wrong until you remember the lock will TTL out anyway, and crashing on release just hides the actual work's result from the caller. Log it; don't throw.
No retry-with-backoff. If the lock isn't available, the function returns null and the caller decides what to do - usually that's "this job is being handled, skip." If you want a queue-on-busy pattern, build it one layer up; baking it in here mixes two concerns.
No Redlock, no fencing tokens. Add them when you've measured that you need them. Most services won't.
Where To Go From Here
The shortest version of all of this: a distributed lock is a tool for avoiding duplicate work, not for guaranteeing correctness. Use Redis with SET NX EX for the common case, advisory locks if you're a Postgres shop and don't want extra infra, Redlock if your availability story demands it. Add fencing tokens or idempotency keys for the cases where a duplicate would be more than a small embarrassment.
The pattern you write will look almost identical across all of these. Acquire with an expiry. Hold a unique token. Release atomically. Extend if you can't predict your duration. Make the underlying work as idempotent as you can stand to.
The first time one of these saves you from a duplicate-charge incident at 2am, you'll be glad you got the boring details right.