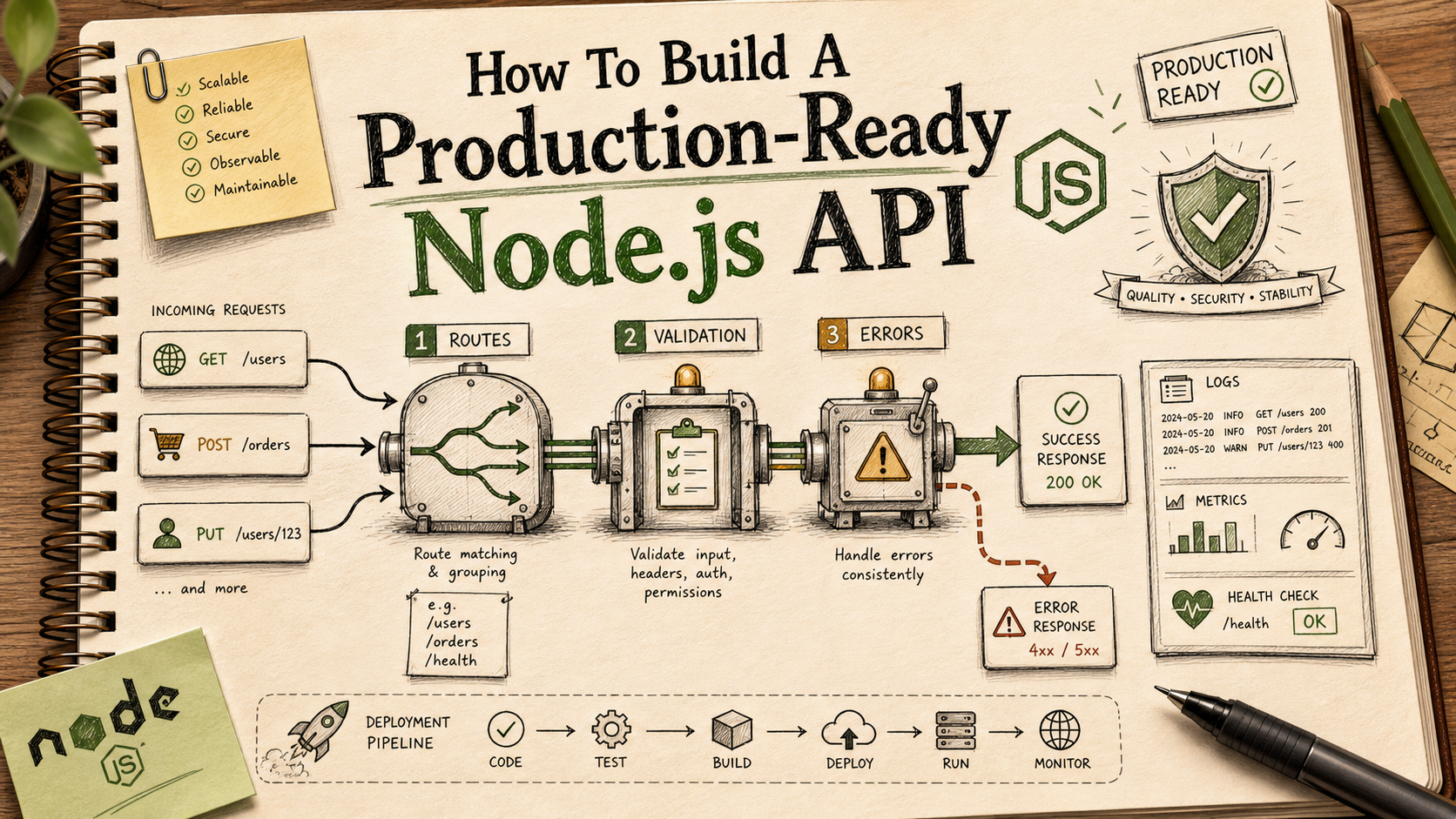
You can ship a Node API in an hour. You can keep one alive for two years if you also do the boring parts: validate inputs at the edge, classify errors, log enough to debug at 3 a.m., and shut down without dropping requests. That's most of what "production-ready" actually means.
This is the checklist I run through before any new service goes behind a load balancer. It's not exhaustive, and it skips the things every framework already does for you. It focuses on the decisions you'll regret skipping.
The Layers, In One Diagram's Worth Of Words
A request walks through your service in roughly the same order every time. From outside in: transport (HTTP framework, body parser), edge concerns (helmet, CORS, rate limit, request ID), auth (token verification, session lookup), validation (zod / joi / valibot on params, query, body), route handler (thin), service / domain logic (where decisions live), persistence and side effects (DB, queue, external APIs), response shaping, then error middleware at the bottom catching anything that throws.
If you can name what lives in each layer for your service, you have an architecture. If you can't, you have a bag of routes — and that bag is what bites you when the second engineer joins the team.
Validate At The Edge, Always
Trust nothing that crosses your process boundary. The HTTP body, query params, headers, webhook payloads, queue messages, files — they all need a schema. TypeScript only checks what you compile, not what arrives at runtime.
import { Router } from 'express';
import { z } from 'zod';
const CreateUser = z.object({
email: z.string().email(),
name: z.string().min(1).max(100),
role: z.enum(['admin', 'member']),
});
export const users = Router();
users.post('/', async (req, res, next) => {
try {
const input = CreateUser.parse(req.body);
const user = await userService.create(input);
res.status(201).json(user);
} catch (err) {
next(err);
}
});Two things to notice. First, the schema is outside the handler, so it's reusable in tests and in OpenAPI generation. Second, every error goes to next(err) — not res.status(400).json(...). Centralized error handling lives in one place, and it's much easier to keep consistent.
Errors Are A Type, Not A String
Production code separates two failure modes: operational errors (bad input, expired token, conflict, rate limited — expected, recoverable, return a 4xx) and programmer errors (a TypeError, an undefined field, a bug — unexpected, log and return 500). Mixing them is how you end up showing stack traces to users.
export class AppError extends Error {
constructor(
message: string,
public statusCode = 500,
public code = 'internal_error',
public expose = false,
) {
super(message);
this.name = new.target.name;
}
}
export class NotFound extends AppError {
constructor(what: string) { super(`${what} not found`, 404, 'not_found', true); }
}
export class Conflict extends AppError {
constructor(msg: string) { super(msg, 409, 'conflict', true); }
}The error middleware then has one job: decide what to leak.
export function errorHandler(err, req, res, _next) {
const isApp = err instanceof AppError;
const status = isApp ? err.statusCode : 500;
req.log?.error({ err, requestId: req.id }, 'request failed');
res.status(status).json({
error: isApp && err.expose ? err.message : 'internal_error',
code: isApp ? err.code : 'internal_error',
requestId: req.id,
});
}requestId in the response means the user can paste one ID into a bug report and you can find every log line for that request.

Structured Logs From Day One
console.log is fine until your logs aggregator wants JSON. Switch to pino at minute zero — it's fast, structured by default, and supports child loggers for per-request context.
import pino from 'pino';
export const logger = pino({
level: process.env.LOG_LEVEL ?? 'info',
base: { service: 'billing-api', env: process.env.NODE_ENV },
redact: ['req.headers.authorization', 'req.headers.cookie', '*.password'],
});Then attach a child logger per request, with the request ID already in scope:
app.use((req, res, next) => {
req.id = req.header('x-request-id') ?? crypto.randomUUID();
req.log = logger.child({ requestId: req.id, path: req.path, method: req.method });
res.setHeader('x-request-id', req.id);
next();
});Now every log line a handler emits — and every error caught downstream — carries the same requestId. That single field makes incident triage feel like a different job.
The Security Floor, Not The Ceiling
Don't skip the four things every public API needs:
helmetfor sensible default headers (CSP, HSTS in production, noX-Powered-By).- CORS configured to specific origins in prod, never
*for credentialed routes. - Rate limiting with
express-rate-limitorrate-limiter-flexible(the latter scales across instances via Redis). - Body size limits —
express.json({ limit: '100kb' })for JSON, plus a separate route for any large payloads. Default100kbis sane;50mbis how you DOS yourself.
This is the floor. Auth, RBAC, input sanitization, secret management, dependency audits — those are layers above. But shipping without the floor is a "the breach was inevitable" Slack message waiting to happen.
Graceful Shutdown Is The Test Of A Real Service
When your orchestrator sends SIGTERM, you have ~30 seconds (or whatever terminationGracePeriodSeconds is) to drain in-flight work, close DB pools, and exit cleanly. A service that hard-exits on SIGTERM drops requests on every deploy.
const server = app.listen(PORT, () => logger.info({ port: PORT }, 'listening'));
async function shutdown(signal: string) {
logger.info({ signal }, 'shutting down');
server.close(async () => {
try {
await db.$disconnect(); // prisma
await queue.close(); // bullmq
logger.info('clean exit');
process.exit(0);
} catch (err) {
logger.error({ err }, 'shutdown error');
process.exit(1);
}
});
// hard cap so a stuck request can't hold the pod forever
setTimeout(() => process.exit(1), 25_000).unref();
}
process.on('SIGTERM', () => shutdown('SIGTERM'));
process.on('SIGINT', () => shutdown('SIGINT'));Two non-negotiables: server.close() first (stop accepting new connections, let in-flight ones finish) and .unref() on the hard-cap timer so it doesn't keep the loop alive on its own.
Health Checks, Not Just /ping
Orchestrators want two endpoints with different semantics:
- Liveness (
/healthz) — is the process alive? Almost always returns 200. Failing this restarts the pod. - Readiness (
/readyz) — is this instance ready to receive traffic? Checks DB, cache, queue connectivity. Failing this removes the pod from the load balancer until it recovers.
The mistake is making /healthz check the database — then a slow DB cascades into a restart loop. Liveness should be almost unconditional. Readiness is where you check dependencies.
A One-Sentence Mental Model
A production Node API is a small core of business logic surrounded by boring, well-named layers — validate at the edge, classify your errors, log with structure, drain on shutdown — and the boring layers are exactly what makes the small core safe to change.