You've felt this one before.
You join a team, open three services, and find three nearly-identical wrappers around the same internal API. One uses axios, one uses raw fetch, the third somehow still imports node-fetch. The request shapes drift. The response types are typed by hand in two places and any in the third. Auth is injected via a header in one, a constructor option in another, and an environment variable that nobody documented in the third.
Everyone knows it's a mess. Nobody owns it. So when the API adds a field, someone updates one consumer, ships a feature, and the other two services quietly keep sending the old shape. Three weeks later, on-call is paged for a "data inconsistency."
An internal SDK is the boring fix. You build one TypeScript package (@acme/orders-client, or whatever) that owns the request shapes, the types, the auth, and the retries. Every consuming service depends on that package. When the API changes, the SDK changes once, and the type system tells every consumer where they need to react.
This sounds simple, and the basic version is. What's not simple is building one your team actually wants to use. The web is full of SDKs that technically work and that nobody adopts because their ergonomics are off: clunky constructors, types that don't narrow, error shapes you have to unwrap, version pinning headaches. The difference between an adopted SDK and a shelf-warmer is mostly developer experience, and DX is a stack of small decisions that compound.
So let's walk through those decisions.
Decide what the SDK is for, before you write a line of it
The first mistake is treating the SDK as "the shared HTTP layer." That framing leaks. People start putting business logic in it, then domain models, then validation, then a thin caching layer, then they need a feature flag client because the SDK happens to be in every service, and now it's a god-package and you can't release it without breaking five teams.
Pick one of two shapes and stick to it.
Shape A, the thin client. The SDK is a typed transport. It owns the request URL, method, body, headers, and the parsed response. It handles auth and a small amount of cross-cutting concern: retries, timeouts, request IDs, basic telemetry hooks. It does not validate business invariants, it does not cache, it does not transform payloads into your domain model. One operation in the SDK maps to one HTTP call.
Shape B, the domain client. The SDK exposes a domain-flavoured API. orders.cancel(id, { reason }) instead of client.post("/orders/:id/cancel", { reason }). It can encapsulate multi-call flows (e.g. paginating until exhausted, retrying a polling endpoint until status flips). It still doesn't own business rules, but it shapes the surface so consumers don't have to think about HTTP.
Shape B sounds nicer. It's also more work to build, more work to evolve, and more dangerous when the underlying API changes. Most teams should start with Shape A, then graduate specific high-traffic endpoints to Shape B only when the call sites are obviously repetitive. Don't pre-build domain helpers for things that get called from one consumer.
Whichever you pick, write it on the README before any code. Future contributors will try to add things outside the boundary; the boundary needs to be a sentence they can read.
Types are the whole reason this exists
The reason your team will adopt a TypeScript SDK over hand-rolled fetches is not "fewer lines of code." It's that the editor knows what's in the response. Get the type story right and adoption is automatic. Get it wrong and people will still hand-roll fetches because your types are useless.
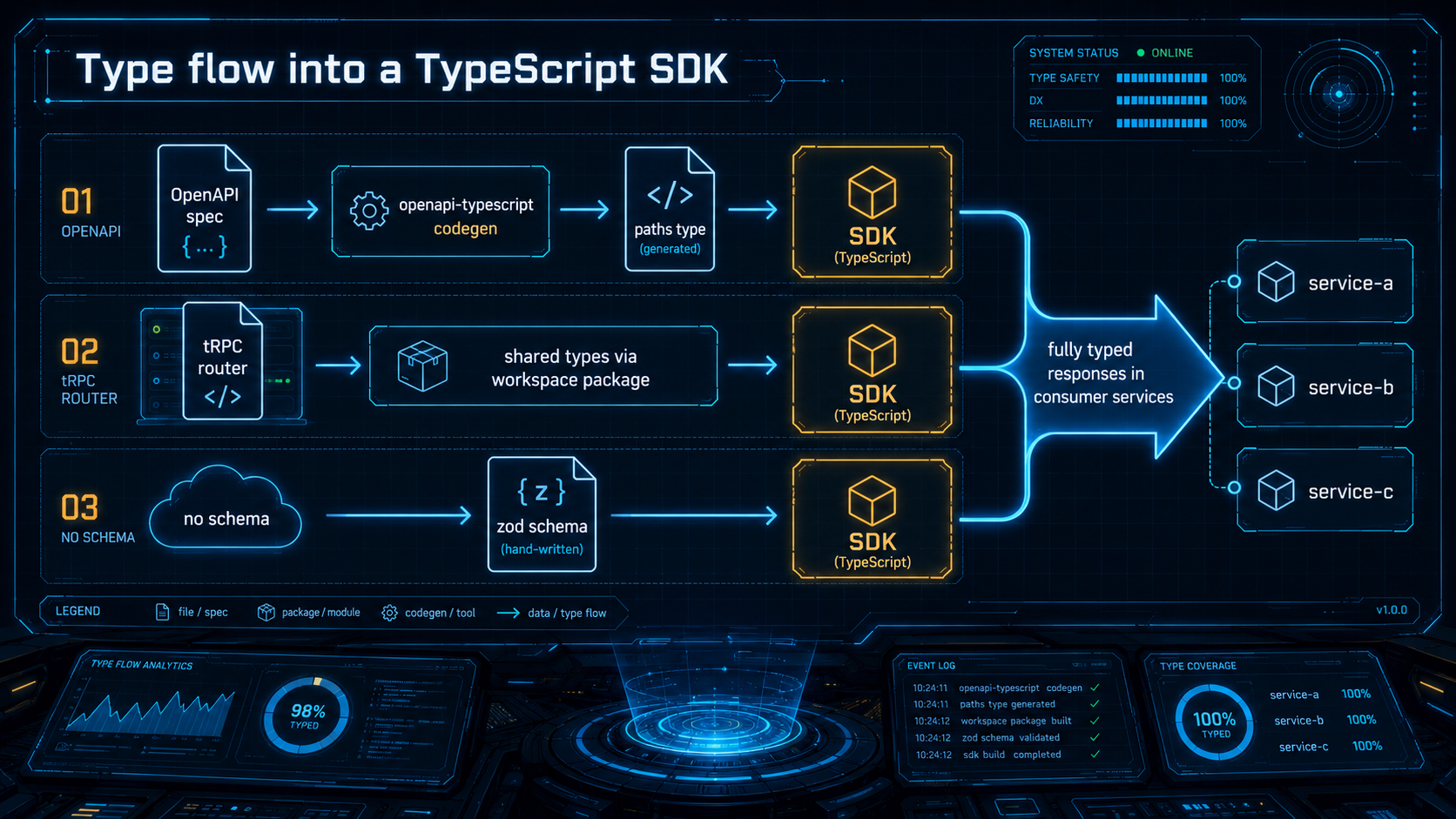
You have three credible options.
Generate from OpenAPI. If your service emits an OpenAPI spec, this is the path. openapi-typescript produces a flat type file from the spec; openapi-fetch provides a tiny typed fetch wrapper that consumes those types. The whole SDK becomes thin glue.
import createClient from "openapi-fetch";
import type { paths } from "./generated/schema";
export function createOrdersClient(opts: {
baseUrl: string;
token: () => Promise<string>;
}) {
const fetcher = createClient<paths>({ baseUrl: opts.baseUrl });
fetcher.use({
async onRequest({ request }) {
const token = await opts.token();
request.headers.set("authorization", `Bearer ${token}`);
return request;
},
});
return fetcher;
}The win: when the spec changes, you regenerate, ship a minor version, and every consumer gets new types. The loss: you depend on the spec being accurate, which means you depend on the backend team treating the spec as a first-class artifact, not as documentation that's allowed to drift.
Generate from tRPC / a typed-RPC framework. If your services are TypeScript on both sides and you already use tRPC, the SDK is almost free: share the server's router type via a workspace package and the client side has full inference. There's no codegen step at all; types flow through the type system.
Hand-write types. Sometimes you don't have an OpenAPI spec, the API isn't worth instrumenting one, or it's a legacy service that talks JSON without a schema. You can still write the types by hand and check them with a runtime validator like zod at the SDK boundary.
import { z } from "zod";
const Order = z.object({
id: z.string(),
status: z.enum(["pending", "paid", "cancelled"]),
total_cents: z.number().int().nonnegative(),
created_at: z.string().datetime(),
});
export type Order = z.infer<typeof Order>;
export async function getOrder(
http: HttpClient,
id: string,
): Promise<Order> {
const json = await http.get(`/orders/${id}`).then(r => r.json());
return Order.parse(json);
}Hand-written types feel like the slowest path. They're often the most honest one: if your backend doesn't have a schema, the SDK is the place where the schema is finally written down, and zod.parse at the boundary protects every consumer from a silently-changed field.
The mistake to avoid in all three cases: do not put any in the public surface. If something is genuinely dynamic, type it as unknown and force consumers to narrow it. Every any you leak is a class of bug that the SDK exists to prevent.
Pick a distribution channel and accept its trade-offs
You have to put the package somewhere. There are three real options.
Private npm registry. GitHub Packages, npm Enterprise, Verdaccio, or a JFrog Artifactory. Consumers install with a scoped name (@acme/orders-client), authenticated via an .npmrc token. This is the cleanest path if you have it set up, because it works exactly like the public npm flow your team already knows. Every consumer service has its own package.json and pins the SDK at a real version.
Monorepo workspace. If all your services live in one monorepo (Nx, Turborepo, pnpm workspaces, Yarn workspaces), the SDK is just another package in the repo. Consumers reference it via "workspace:*" or "*". No registry, no publish flow, no token plumbing. The trade-off is that you have to put every consumer in the monorepo, which is a much bigger architectural choice than the SDK itself.
Git URL dependencies. "orders-client": "git+ssh://git@github.com/acme/orders-client.git#v1.4.0". This works, but it's slow to install, doesn't cache well, and gives you no metadata layer. Avoid unless you have no choice, and if you find yourself reaching for it, the right next step is to stand up a private registry, not to keep going.
The order matters: monorepo if your repo layout permits it, private registry otherwise, git URLs as a last resort. Don't try to support all three at once.
Versioning is where SDKs go wrong
Semver is well-understood for libraries you share with strangers. For internal SDKs, the assumptions break in interesting ways.
First, your consumers are not strangers. You can ping them in Slack. You can grep their imports. This is a freedom: you can release breaking changes faster than a public library can, because you know who's affected.
Second, the backend and the SDK aren't independent. If the API ships a breaking change, the SDK has to ship one too. If consumers don't upgrade in sync, calls fail. So your real versioning question isn't "is this change breaking?" It's "does the backend deploy guarantee that all clients >= vN are compatible?"
That gives you two viable strategies.
Strict semver with a deprecation window. Backend changes that are about to break must first ship as additions in v1.X, with the old field deprecated. The SDK gets a v1.(X+1) that supports both. Consumers upgrade on their own schedule. When everyone is past the deprecation, the backend removes the old field, the SDK ships v2.0, and you're done. This is slow and disciplined and it works.
Lockstep with the backend. The SDK version always matches the backend version. v3.4 of the SDK only talks to v3.4 of the API. Breaking changes are routine; consumers upgrade as part of each backend release. This works only if you control the deploy schedule for every consumer, which is rarer than people assume.
Pick one and write it in the README. The worst version of this is "we use semver but also we keep making breaking changes on minor bumps because it's internal". It gives you the worst of both worlds, because consumers stop trusting the version number and pin to exact versions or start vendoring.
Build for both Node and bundlers without breaking either
Most internal SDKs are consumed by other Node services, which means CommonJS still matters: older codebases, scripts, edge functions on certain runtimes. You also want to be ready when someone uses the SDK from a Next.js app or a Vite-built worker, which means ESM has to work too.
A standard layout that handles both: ship dual entry points and let the resolver pick.
{
"name": "@acme/orders-client",
"version": "1.4.0",
"type": "module",
"main": "./dist/index.cjs",
"module": "./dist/index.js",
"types": "./dist/index.d.ts",
"exports": {
".": {
"types": "./dist/index.d.ts",
"import": "./dist/index.js",
"require": "./dist/index.cjs"
}
},
"files": ["dist"],
"sideEffects": false,
"engines": { "node": ">=18" }
}tsup is the simplest way to get both outputs and a single declaration file:
import { defineConfig } from "tsup";
export default defineConfig({
entry: ["src/index.ts"],
format: ["esm", "cjs"],
dts: true,
sourcemap: true,
clean: true,
target: "node18",
});Three details that look minor and aren't:
"sideEffects": false tells bundlers your modules are pure imports. Without it, tree-shaking gives up and consumers pull the whole SDK into every bundle, including the parts they don't use. If your SDK has 50 endpoints and a consumer calls one, this is the difference between a 2 KB import and a 200 KB one.
"engines": { "node": ">=18" } is honest. If you use fetch from the global, you need Node 18+. Pretending to support 16 because nobody bumped the field gets you a 3am bug report from an old service that's still on it.
The exports field is the modern way to declare entry points. Without it, your CJS consumers might quietly pull the ESM build, which fails in surprising ways. With it, Node and bundlers always pick the right file.
Errors should be discriminated, not stringified
A pattern that ruins SDK adoption: every failure is a generic Error with a stringified message. Consumers end up parsing error messages with regex to figure out what happened, which is exactly the chaos the SDK was supposed to remove.
Give failures a shape.
export type SdkError =
| { kind: "network"; cause: unknown }
| { kind: "timeout"; afterMs: number }
| { kind: "http"; status: number; body: unknown; requestId?: string }
| { kind: "validation"; issues: { path: string; message: string }[] }
| { kind: "auth"; reason: "missing_token" | "expired" | "forbidden" };
export class SdkException extends Error {
constructor(public readonly error: SdkError) {
super(`${error.kind}: ${describe(error)}`);
this.name = "SdkException";
}
}
function describe(e: SdkError): string {
switch (e.kind) {
case "network": return "request failed before reaching server";
case "timeout": return `request exceeded ${e.afterMs}ms`;
case "http": return `server responded ${e.status}`;
case "validation": return `response failed schema validation`;
case "auth": return `auth error: ${e.reason}`;
}
}Now consumers can match on error.kind and decide what to do: retry on network, escalate on auth, surface to the user on validation. The error itself carries enough structure to be logged usefully, and the request ID (if the backend sends one) is propagated for traceability.
Auth and retries belong inside, not in every call site
If consumers have to wire auth, retries, and timeouts themselves, your SDK is just a typed fetch. The whole point is to centralise this.
A pattern that scales: the SDK takes a factory of credentials, not credentials directly. That way, token rotation, refresh, and impersonation all live in one place.
export interface ClientOptions {
baseUrl: string;
/** Called before every request. Cache externally if you want. */
getToken: () => Promise<string>;
/** Timeout per request in ms. Default 10s. */
timeoutMs?: number;
/** Retry policy. Default: 2 retries on network errors and 5xx. */
retry?: { attempts: number; baseDelayMs: number };
/** Telemetry hook fired for every request, success or failure. */
onRequest?: (event: RequestEvent) => void;
}Three things to notice. getToken is a function, not a string, so the SDK doesn't have to know whether you're rotating tokens, calling STS, or reading from a cached secret. retry is a policy object, not a boolean, and anyone who's debugged retry storms knows the difference matters. onRequest is a hook, not a logger: it lets the consumer plug in their existing observability stack instead of inheriting whatever logging library you happen to like.
The retry implementation itself is small but worth showing because the defaults matter:
export async function withRetry<T>(
fn: () => Promise<T>,
policy: { attempts: number; baseDelayMs: number },
shouldRetry: (err: unknown) => boolean,
): Promise<T> {
let lastErr: unknown;
for (let i = 0; i <= policy.attempts; i++) {
try {
return await fn();
} catch (err) {
lastErr = err;
if (i === policy.attempts || !shouldRetry(err)) throw err;
const jitter = Math.random() * policy.baseDelayMs;
await new Promise(r =>
setTimeout(r, policy.baseDelayMs * 2 ** i + jitter),
);
}
}
throw lastErr;
}Exponential backoff with jitter. Retry only on the failures that are worth retrying: network errors, 502/503/504, request timeouts. Never retry on 4xx (you'll just re-burn the user's quota). Never retry on validation errors (the response is wrong, retrying won't fix it).
A few DX details that decide whether anyone uses this
These are small. They are also the difference between an SDK people import and one they avoid.
One default export of a factory function, not a class with config. createOrdersClient(opts) is easier to use, easier to mock, and easier to construct in tests than new OrdersClient(opts). Classes invite inheritance, which consumers will try, which will hurt everyone.
Named exports for everything else. Types, helpers, error class. Avoid a default export that's a kitchen sink object, since bundlers and IDEs treat named exports better.
Inline JSDoc on every public function. Editors show this on hover. Three lines of JSDoc save a hundred Slack questions.
Reasonable defaults that you actually picked, not the framework's defaults that you forgot to set. Timeout, retry policy, base URL convention, auth header name: pick all of these on day one, document them, and don't change them lightly.
A mock or test subpath that exports a fake client. Consumers will test code that uses your SDK. If they have to roll their own mock, half of them will do it wrong. Ship a test double:
export function createMockOrdersClient(
overrides: Partial<MockHandlers> = {},
): OrdersClient {
// returns an object with the same shape as the real client,
// backed by handlers consumers can override per-test
}import { createMockOrdersClient } from "@acme/orders-client/mock";
const client = createMockOrdersClient({
getOrder: async () => ({ id: "o_1", status: "paid", total_cents: 4200 }),
});This single file does more for SDK adoption than any amount of README polish.
A changelog the size of an actual changelog. "Bug fixes and improvements" tells consumers nothing. "Fixed getOrder returning null instead of throwing on 404, behaviour change, see migration note" is what a real changelog looks like, and it gets read.
When not to build an internal SDK
Sometimes the answer is no.
If exactly one service consumes the API, an SDK is overkill. A typed module inside that service is fine.
If the API is volatile and changes weekly, you'll spend more time chasing the SDK than writing application code. Stabilise the API first.
If your team doesn't have a clear owner for the SDK package (somebody whose name is on the PRs, who reviews changes, who can break ties when consumers disagree), it'll rot within a quarter. Internal libraries die from neglect more reliably than they die from bad design.
And if the only reason you're considering an SDK is "we want consistent retry logic," consider whether a shared HTTP middleware package would solve the problem with less commitment. SDKs are bigger than middleware. Don't build the bigger thing if the smaller thing fits.
The version of this that's worth building is the one with one shape, one type story, one distribution channel, real semver, dual builds, structured errors, sensible defaults, and a mock subpath. None of that is dramatic on its own. Together they're the difference between a package nobody adopts and one your teams reach for without thinking.
That last one, without thinking, is the whole goal.