You've been in this meeting before.
Someone draws a box on the whiteboard, labels it api, and then draws an arrow out of it to another box labeled payments, and another to notifications, and another to users. They turn around and say, with full conviction, "we should split this into microservices." Heads nod. Nobody pushes back because nobody wants to be the person defending the monolith. By the time the meeting ends, you have a vague mandate to start carving up a perfectly fine Node.js app into half a dozen tiny services, each with its own repo, its own deploy pipeline, its own dashboard, and its own way of breaking at 3am.
A year later, you're holding the operational complexity of a distributed system, but you're solving the same problems you had before. You just pay more in network hops, observability tooling, and engineering hours to keep the wiring intact.
This piece is not a defense of monoliths or an attack on microservices. Both are real architectures with real use cases. The point is that the choice between them, in a Node.js project specifically, has a different shape than the generic blog posts make it sound. Node has its own quirks (a single-threaded event loop, easy in-process communication, instant inter-module calls, npm workspaces) and those quirks tilt the math in ways you should think about before you start drawing arrows.
Let's break it down honestly.
What "monolith" and "microservices" actually mean
Strip the marketing off and you get two structural choices.
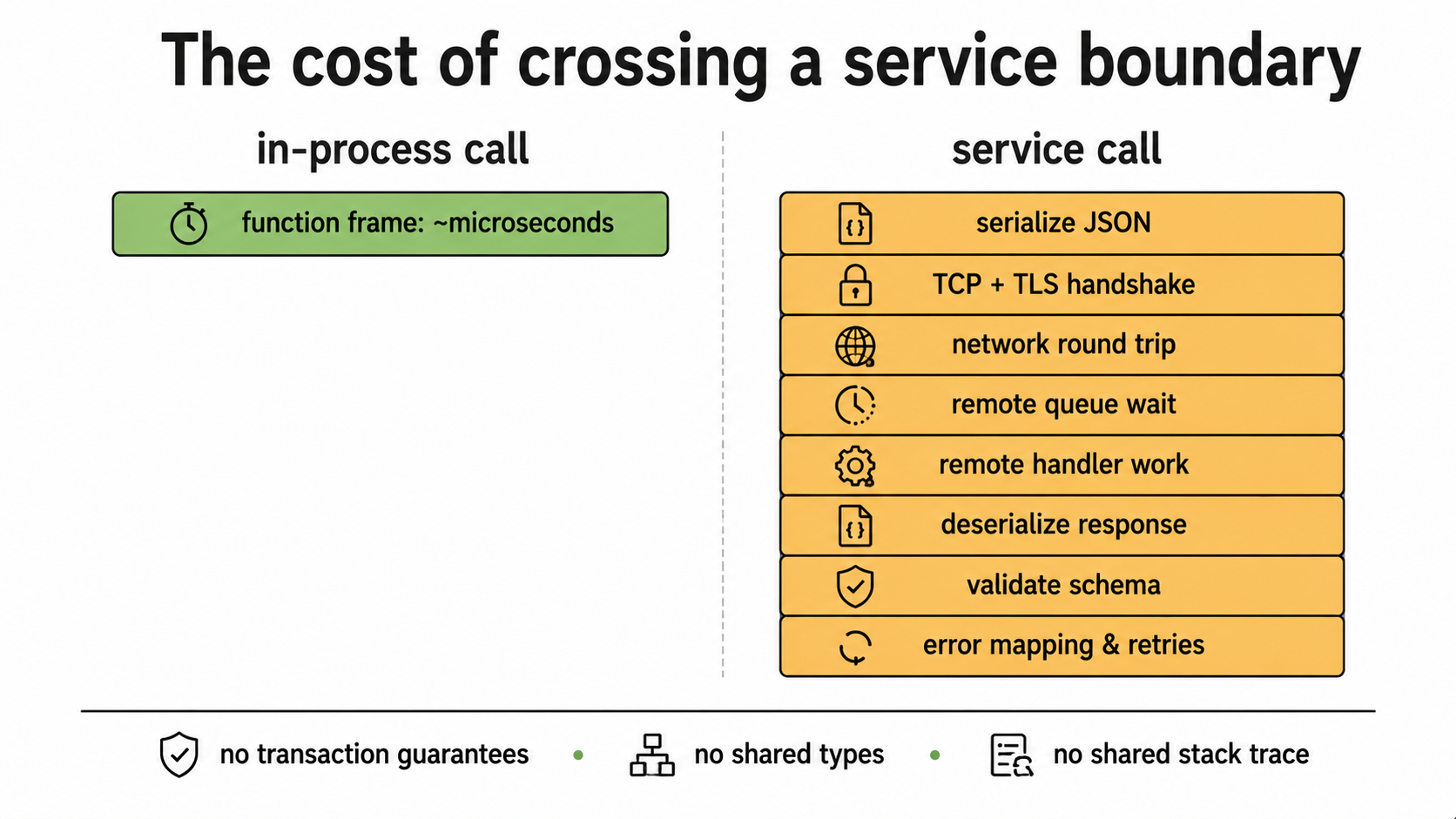
A monolith is a single deployable unit. One process (or a fleet of identical replicas of that process), one codebase, one deployment pipeline. Inside the process, modules call each other directly. If orders.ts needs something from inventory.ts, it imports a function and calls it. The cost of that call is a function frame on the stack.
A microservice architecture is many deployable units, each with its own codebase (or at least its own deployment), each with its own runtime, each communicating with the others over a network: HTTP, gRPC, message queues, whatever. If orders needs something from inventory, it makes a network call. The cost of that call is a serialization step, a TCP round trip, the other service's queue depth, and the possibility that the call fails in five interesting new ways.
That's the structural difference. Everything else (team autonomy, scaling, language polyglot, fault isolation) is a downstream consequence of where you put the seams between deployable units.
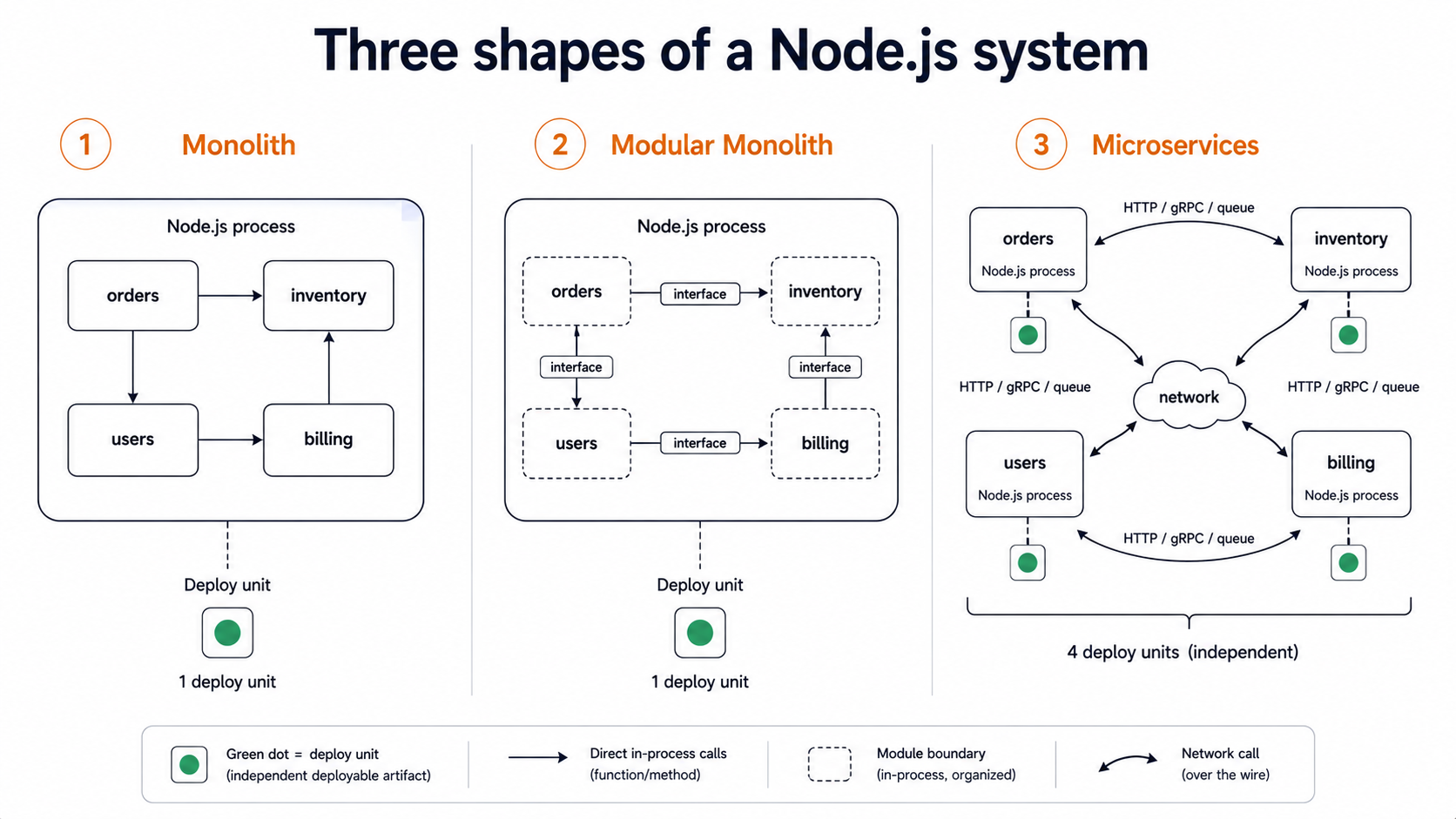
A third option, which most of this article is secretly about, is the modular monolith: a single deployable unit with strong internal boundaries between modules. Same codebase, same deploy, but the modules talk through well-defined interfaces and don't reach into each other's data. We'll come back to this.
What Node.js quietly gives you in a monolith
Before you split anything, it's worth being clear about what you give up.
In a Node.js monolith, two modules communicate through a function call inside the same V8 isolate. There's no serialization. There's no network. There's no marshaling of dates into strings and back. There's no chance the call fails because TLS expired or a sidecar restarted. You pass an object reference, you get an object reference back, and the whole thing happens in microseconds.
import { reserveStock } from "../inventory/reserve-stock";
import { chargeCustomer } from "../billing/charge-customer";
export async function placeOrder(order: Order) {
const reservation = await reserveStock(order.items);
const charge = await chargeCustomer(order.customerId, order.total);
return { reservation, charge };
}In this snippet, placeOrder is calling into two other modules. The await is for asynchronous work (a database query, probably), not for a network hop between services. If reserveStock throws, the error surfaces on the same stack. If the request handler holding this call gets a timeout from the client, you cancel one thing.
Now picture the same flow split across three services:
export async function placeOrder(order: Order) {
const reservation = await fetch("http://inventory.internal/reserve", {
method: "POST",
body: JSON.stringify({ items: order.items }),
}).then(handle);
const charge = await fetch("http://billing.internal/charge", {
method: "POST",
body: JSON.stringify({ customerId: order.customerId, total: order.total }),
}).then(handle);
return { reservation, charge };
}Same shape, same intent. But now the request can fail because inventory is rolling out a new version. It can fail because billing is rate-limited by Stripe and chose to return 503 instead of buffering. It can succeed at inventory and fail at billing, leaving you with stock reserved against a charge that never happened. It can succeed at both and fail at the response serializer in the calling service, leaving you with a charged customer who thinks the order failed. None of these problems exist in the monolith version, because the monolith version is one transaction in one process.
You can solve every one of these problems. The point is that you didn't have them before, and now you do. The bill comes due in retry logic, idempotency keys, distributed traces, and the half-dozen Saga patterns you'll Google your way through over the next six months.
What you actually buy with a microservice
Microservices aren't cosplay. The benefits are real, just specific.
The clearest one is independent deployability. If you have eight teams, and every team has to coordinate a single deploy of a giant Node.js app, you spend a lot of meeting time on release trains. Split the deploys, and team A can ship a fix at 11am without team B's broken migration blocking them. This is the original microservices pitch, and it's still the most honest one.
The second is fault isolation at the process level. If a memory leak in your reporting code slowly eats the heap, in a monolith it eventually crashes the same process that serves user logins. In a microservices setup, reporting crashes its own process and login keeps running. You can achieve some of this with worker processes inside Node (more on that below), but a separate service is a stricter boundary.
The third is independent scaling. If your image-processing endpoint is CPU-bound and 90% of the traffic is read-mostly chat history, you don't want to scale them as one unit. In Node specifically this is sharper than in JVM apps, because Node is single-threaded. One heavy synchronous operation can starve every other request in that process. Splitting that workload into its own service lets you scale it horizontally and isolate the CPU pressure.
The fourth is polyglot freedom. If your team genuinely needs to run a Python model server next to a Node API, you've already crossed a process boundary, and the conversation is no longer "monolith vs microservices". It's "how many services" and "what's the contract between them." That's a valid reason to be in microservices territory.
The fifth, often overlooked, is organizational. Conway's Law works in both directions: your architecture will end up looking like your org chart, and your org chart will adapt to your architecture. If you genuinely have three independent teams who own three independent product areas, a shared codebase with shared CI is going to grind. Splitting it acknowledges what's already true.
None of these benefits are inevitable, though. A single team of four working on three repos with three deploy pipelines and one shared Postgres is doing microservices cosplay. They have all the operational cost and none of the autonomy payoff.
What you actually pay with a microservice
This is the part the diagrams skip over.
You pay for the network. Every cross-service call is a TCP connection, a TLS handshake (if you're sane), a serializer, a deserializer, and a chance of failure. In a Node app where a request used to fan out into ten in-process function calls, the same request now fans out into ten HTTP calls. Even if each one is fast (say, 10ms p50), you've added 100ms to a request that used to be 5ms. And p99 is much worse than p50, because the network has a fat tail.
You pay for serialization. JSON over the wire isn't free. Stringify, send bytes, parse, validate, hydrate. Dates become strings. Big payloads become slow. You start writing code like this:
async function callService<T>(url: string, body: unknown): Promise<T> {
const res = await fetch(url, {
method: "POST",
headers: { "content-type": "application/json", "x-trace-id": getTraceId() },
body: JSON.stringify(body),
signal: AbortSignal.timeout(2000),
});
if (!res.ok) throw new ServiceError(res.status, await res.text());
return (await res.json()) as T;
}Every service-to-service call now needs timeouts, retries, idempotency, tracing headers, and a schema validator on each side. You used to call a function. Now you call a function that does all of the above and could fail in nine ways.
You pay for the operational surface. Each service gets its own:
- Build pipeline (Dockerfile, CI job, image registry entry).
- Deploy pipeline (manifest, Helm chart, or platform config).
- Runtime config (env vars, secrets, feature flags duplicated across services).
- Observability wiring (logs shipping, metrics scraping, traces).
- Alerts (each service needs its own latency, error rate, and resource alerts).
- Dependency management (each one has its own
package.json, lockfile, and security patching cadence).
For one service this is fine. For twenty services, you've created a job for one or two engineers full-time, and that job is "platform engineering" whether you call it that or not.
You pay for the data. The hardest cost. We'll dedicate a whole section to it below.
You pay for the latency tax on local development. A Node monolith starts in two seconds and you can step through it in your IDE. Twenty services don't all start in two seconds, and stepping across service boundaries means correlating logs, not following a stack trace. You'll either spend a year building a great local dev environment (Docker Compose, mocked services, contract tests), or you'll let developers run "just the service they're working on" and discover integration bugs only in staging.
This isn't a hypothetical bill. It's a real org-chart-shaped expense that doesn't show up until you're already committed.
The Node-specific wrinkle: the event loop
Node has one CPU-bound failure mode that's worth a section by itself.
Node runs your application code on a single thread: the event loop. Asynchronous I/O is non-blocking; CPU-bound code is not. If one request hands the event loop a for loop that runs for 200ms, every other request on that same process waits 200ms. There is no fairness scheduler. Whatever started first finishes first.
In a monolith, this means a single misbehaving handler can degrade the whole app. A regex with catastrophic backtracking, a JSON parse of a 50MB payload, a sync fs.readFileSync, a bcrypt.hashSync on a high-traffic endpoint. Any of these can stall the event loop and tank latency for everything else. The fix is the same as it always was: make CPU work non-blocking, push it to a worker thread, or push it off the box entirely.
import { Worker } from "node:worker_threads";
export function hashOnWorker(password: string): Promise<string> {
return new Promise((resolve, reject) => {
const worker = new Worker("./hash-worker.js", { workerData: password });
worker.once("message", resolve);
worker.once("error", reject);
});
}A worker thread keeps you inside the monolith but isolates the CPU work. A separate microservice does the same thing with more ceremony. Which one is the right move depends on how much of that CPU work you have, how often you do it, and whether anything else (independent scaling, separate deploy cadence) makes the extra cost worth it.
For most Node teams, the answer is: try the worker thread first. It's twenty lines of code and zero new infrastructure. If the workload genuinely needs its own scaling envelope, that's when you graduate to a separate service.
The modular monolith: where most teams should actually start
Here's the architecture you almost never hear pitched at conferences, and it's the one most teams should build first.
A modular monolith is a single Node.js application (one deploy, one process model, one repo) with strict internal module boundaries. Each module owns its own data, exposes a typed interface to the rest of the app, and is forbidden from reaching into another module's internals. You enforce this with the tools you already have: TypeScript exports, ESLint boundaries, npm workspaces.
A typical layout:
apps/
api/
src/
main.ts
packages/
orders/
src/
index.ts // public interface — what other modules can import
internal/
place-order.ts
repository.ts
package.json
inventory/
src/
index.ts
internal/
reserve-stock.ts
package.json
billing/
src/
index.ts
internal/
charge-customer.ts
package.jsonThe index.ts of each package is the public API. Everything in internal/ is invisible to other packages, by convention and ideally by tooling (an ESLint rule that bans imports from */internal/* outside the owning package). When orders needs to talk to inventory, it imports from inventory, not from inventory/internal/reserve-stock.
You can run this whole thing as one Node process. You can deploy it as one container. You can step through it in one debugger. You can refactor across module boundaries with a single PR.
And here's the trick: when the day comes that you genuinely need to extract billing into its own service, because Stripe webhooks need their own scaling envelope or because the compliance team needs an isolated deploy with stricter access controls, the work is mostly just turning that module's public interface into an HTTP client. The seams are already where they need to be. You spent the whole time building toward a possible split without paying the cost up front.
Data is the hardest part of the split
If there's one place microservices articles understate the cost, it's the database.
A monolith usually has one database. Every module reads and writes it. Joins are free. Transactions are real. If placeOrder needs to decrement stock and create a charge and insert an order row, it does all three inside a single BEGIN/COMMIT block, and either all of them happen or none of them do.
Once you split services, the database typically splits with them. That's the whole point. inventory owns its data, billing owns its data, orders owns its data. No service reads another service's tables.
You've just given up two enormous primitives at once.
You've given up the join. If you want to render an order with the customer's name and the items' current names, you used to write one query with three joins. Now you make three network calls. You either denormalize (each service keeps a cached copy of the parts of other domains it needs) or you call out at request time (slow and flaky). Both options have real cost.
You've given up the transaction. There's no BEGIN/COMMIT across services. If orders writes a row and then billing fails, the order row is still there. You need to either compensate (Saga pattern: orders exposes a "cancel this order" endpoint that billing calls when it fails) or rely on eventual consistency through events (each service publishes domain events; subscribers update their own copies of the data; eventually the system is consistent, but at any given moment it might not be).
async function placeOrderSaga(order: Order) {
const reservation = await inventoryClient.reserve(order.items);
try {
const charge = await billingClient.charge(order.customerId, order.total);
return { reservation, charge };
} catch (err) {
// Compensate. This had better be idempotent.
await inventoryClient.releaseReservation(reservation.id);
throw err;
}
}That looks fine until the compensation call also fails. Now you have stock that's reserved against an order that doesn't exist and a charge that may or may not have gone through. You need a reliable event log, a retry mechanism, and probably a dead-letter queue with humans on the other end.
You can build all of this. People do. But it is a different category of system than a single Postgres database holding the truth about everything. If your business doesn't yet have the kind of scale or organizational shape that demands per-domain data ownership, paying this cost is wasteful.
When the math actually flips
If microservices are this expensive, when are they worth it?
A few real triggers, in roughly increasing order of strength:
Independent scaling pressure. One workload has fundamentally different resource needs from the rest of the app: CPU-bound image processing, memory-heavy ML inference, IO-heavy log ingestion. Worker threads or a separate process can solve this without going full microservices, but a separate service makes sense once the workload has its own fleet sizing requirements.
Independent deploy cadence by team. Two teams genuinely block each other on every deploy because of shared CI, conflicting migrations, or release coordination. Splitting deploys is the cheapest way to unblock them, even if they technically still share a database for a while.
Genuine fault isolation requirements. A regulatory or contractual requirement that a specific workload runs in a separately deployable, separately auditable boundary. Payments services often look like this. Anything touching PCI or PHI often looks like this.
Polyglot tech that already exists. You already have a Python service next to a Node service. You're already in a multi-service world. The question is no longer "should we" but "where else should the seams be."
Independent third-party integrations that need their own retry/queue posture. A webhook ingestion service can crash, restart, and replay events without anyone noticing. Embedding that in the same process as your synchronous user-facing API conflates two very different reliability postures.
What's not on this list:
- "Microservices are best practice."
- "Big companies do it."
- "Our codebase is getting big."
- "We want to use Rust for one thing."
- "Our team likes Kubernetes."
A growing codebase is a refactoring problem. The right answer is usually a modular monolith, not a fleet of services.
How to actually decide, in five honest questions
When the next person draws the box and the arrow and says "let's go microservices," ask these out loud.
What concrete problem are we trying to solve? Not "scaling" in the abstract. A specific endpoint that's slow. A specific team that's blocked. A specific compliance requirement. If you can't fill in the concrete problem, you don't have one yet.
Could we solve it inside the monolith first? A worker thread for the CPU work. A separate read replica for the heavy reporting queries. A bounded module with its own schema inside the same database. A queue for the async work that doesn't need to block the main request.
Do we have the org shape to support more services? One team can run two or three services. Four or five teams can run twenty. One team running twenty services means one team doing platform work full-time instead of product work.
Are we ready for the data split? Are we comfortable replacing joins with denormalization, transactions with sagas, foreign keys with eventual consistency? Because that's the bill.
What's the cheapest first step? Often it's not "extract a service." It's "draw a hard module boundary inside the monolith and start enforcing it." The split, if it ever happens, becomes a much smaller piece of work once the seams are visible.
If the answers come back honest, you'll find that most "we need microservices" conversations end with "we need a modular monolith, plus one extracted service for that one CPU-heavy job," and that is a perfectly good architecture.
A note on tooling: don't conflate it with architecture
Kubernetes, service meshes, gRPC, Kafka, message brokers: all great tools. None of them are an architecture. You can run a monolith on Kubernetes. You can run microservices on a single VM with PM2. You can run a modular monolith and still use Kafka for async work. You can run microservices and still call most of them with plain fetch.
Tools serve the architecture, not the other way around. If somebody pitches "we need microservices so we can use service mesh", that's not a real argument. The mesh is for managing the service-to-service network you've already chosen to have. If you didn't need that network in the first place, you don't need the mesh.
The Node ecosystem has good tools at every layer. NestJS, Fastify, and Express all run a monolith happily. tRPC and Zod give you typed interfaces across modules with almost no overhead. BullMQ, Kafka, and NATS all give you async messaging if you want it. Pick the architecture first, then pick the tools that fit.
The honest closing
Most Node.js codebases that are described as "too big to be a monolith" are not too big. They are too tangled. The fix for tangle is module boundaries, not network boundaries. A modular monolith with strict imports and a clean domain model will do for the next three years what a poorly-split microservices system will spend three years trying to undo.
The right time to split is when you have a specific problem that splitting solves and you've already exhausted the in-process options. When that day comes, you'll be glad you spent the early years building strong seams instead of weak distributed transactions. And when it doesn't come (which, for most teams, it doesn't), you'll have shipped a lot of product instead of building a lot of platform.
Pick the architecture that matches the problem you actually have. Not the one on the conference slide.