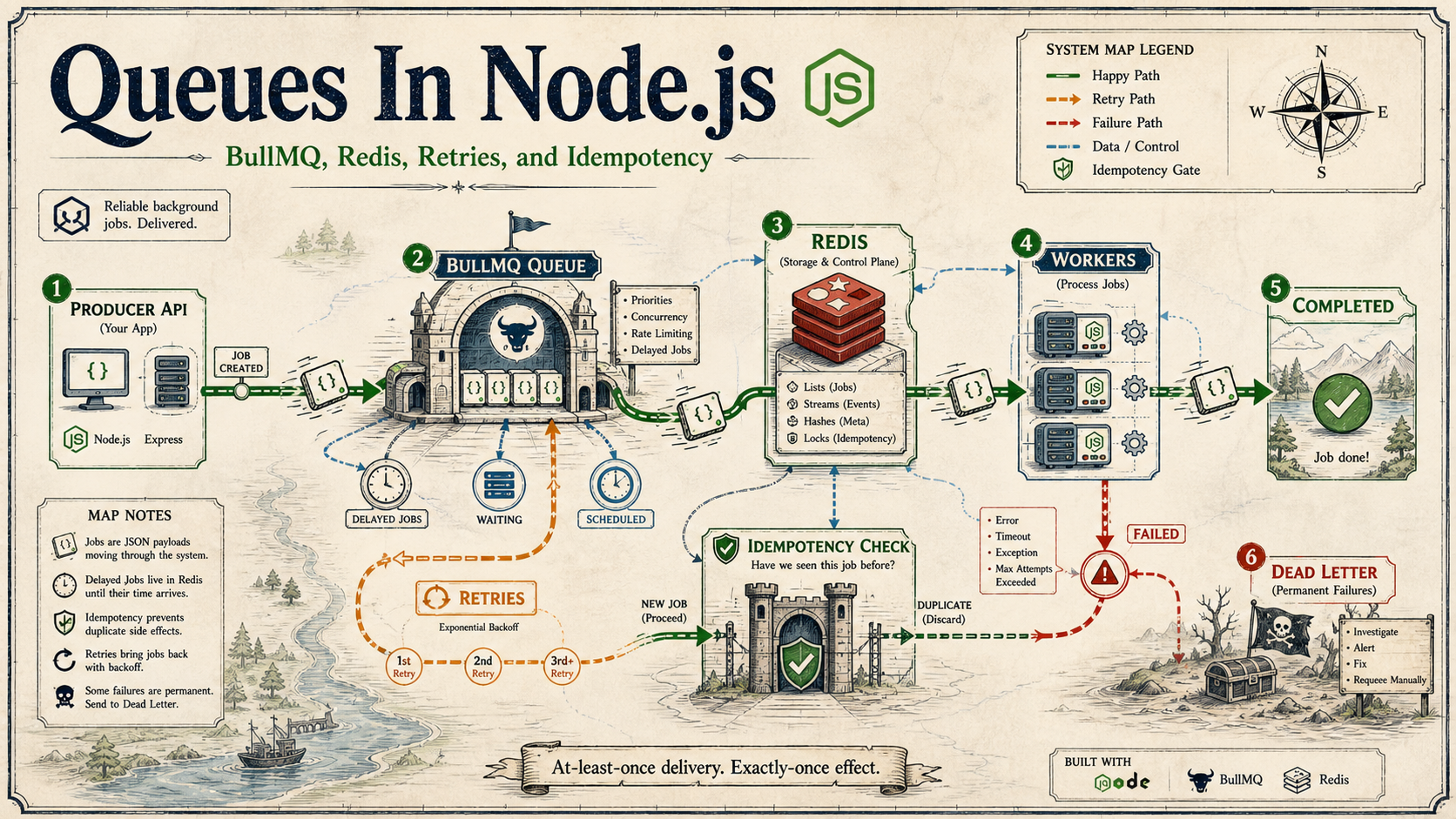
The first time you reach for a queue in Node.js, the motivation is usually simple. Some HTTP request is taking too long, or it depends on a flaky third-party API, or you want to send an email without making the user wait. So you push the work into a background queue and call it a day.
Then production happens. Jobs run twice. Jobs fail silently. A worker crashes during a charge and you have no idea whether the customer was billed. The queue did not break — your assumptions did.
BullMQ has become the default Node.js queue library for a reason: it is built directly on Redis, the API is small, and most of the production-grade features are right there. But you still have to use it correctly. Here is what that actually looks like.
Why BullMQ And Why Redis
BullMQ is a rewrite of the older bull library, written in TypeScript, with a cleaner separation between Queue, Worker, QueueEvents, and FlowProducer. It runs on Redis 6.2+ and uses Lua scripts to make state changes atomic across multiple consumers. That detail matters: when ten workers race for the same job, BullMQ guarantees only one gets it.
Redis is the right substrate for most app-level queues because the operations you need — append a job, claim it atomically, move it to a delayed set, mark it as failed — are exactly what Redis is fast at. You do not get Kafka-level throughput or replay, but you do get sub-millisecond enqueue latency and a queue you can actually inspect with redis-cli.
// queue.ts
import { Queue } from 'bullmq';
export const emailQueue = new Queue('emails', {
connection: { host: process.env.REDIS_HOST, port: 6379 },
defaultJobOptions: {
attempts: 5,
backoff: { type: 'exponential', delay: 1000 },
removeOnComplete: { age: 3600, count: 1000 },
removeOnFail: { age: 24 * 3600 },
},
});Set removeOnComplete and removeOnFail from day one. If you do not, completed jobs accumulate in Redis and you will eventually get paged about memory.
The Worker Is Not Your Handler
A common mistake is treating the Worker callback like an Express route — write the logic inline and move on. The Worker is a long-running consumer with its own concurrency, lifecycle, and failure modes. Keep it thin.
// worker.ts
import { Worker } from 'bullmq';
import { sendWelcomeEmail } from './mailer';
const worker = new Worker(
'emails',
async (job) => {
// Job data was JSON-serialized through Redis. Validate it.
const { userId, template } = job.data;
return sendWelcomeEmail(userId, template);
},
{
connection: { host: process.env.REDIS_HOST, port: 6379 },
concurrency: 10,
limiter: { max: 100, duration: 1000 }, // 100 jobs/sec ceiling
},
);
worker.on('failed', (job, err) => {
console.error({ jobId: job?.id, attempts: job?.attemptsMade, err: err.message });
});concurrency is per-worker-instance. If you run three Node processes each with concurrency: 10, you have 30 in-flight jobs. The limiter is a token bucket and applies across the whole queue when the workers share Redis — useful for honoring third-party rate limits.
Idempotency: The Only Honest Guarantee
Queues advertise "at-least-once" delivery. That means a job can run twice. Network glitches, worker restarts mid-job, retries after timeouts — all of these can produce a second execution of work you thought ran once.
The fix is not to trust the queue. The fix is to make the job safe to run twice. Two complementary tools:
1. Stable jobId for deduplication. If you give two jobs the same jobId, BullMQ rejects the second one (it returns the existing job instead of creating a new one). Derive the ID from the work itself, not from Date.now().
await emailQueue.add(
'welcome',
{ userId, template: 'welcome-v2' },
{ jobId: `welcome:${userId}` }, // dedupe at enqueue time
);2. Idempotency keys inside the handler. For the case where the job actually runs twice (because attempt 1 timed out but the side effect committed), guard the side effect with a key the database enforces.
await db.transaction(async (tx) => {
const inserted = await tx
.insert(charges)
.values({ idempotencyKey: `charge:${job.id}`, userId, cents: 1999 })
.onConflictDoNothing()
.returning();
if (inserted.length === 0) return; // already charged on a previous attempt
await stripe.charges.create({ amount: 1999, customer: userId });
});The pattern: write a row first with a unique constraint on the idempotency key, then perform the side effect. If the second attempt finds the row already exists, it skips the side effect.

Retries And Backoff Are A Policy Decision
attempts: 5 and backoff: { type: 'exponential', delay: 1000 } look harmless. Combined, they mean a job can keep retrying for roughly 1s + 2s + 4s + 8s = 15 seconds before giving up. That is fine for an email. It is wrong for a webhook from a payment provider you cannot replay.
Three rules I follow:
- Different queues for different SLAs. Emails, webhooks, and image processing have different acceptable retry windows. Mixing them in one queue means one slow handler starves the others.
- Custom backoff for known transient errors. BullMQ accepts a function:
backoff: (attemptsMade, err) => err.statusCode === 429 ? 60000 : 2000. HonorRetry-Afterwhen the upstream tells you when to come back. - Dead-letter the rest. When
attemptsis exhausted the job moves to thefailedset. That is your dead-letter queue. Build a tiny dashboard route or use Bull Board so a human can see what landed there.
Delayed, Repeatable, And Flow Jobs
Three features people miss because they look like configuration footnotes:
// Delayed: run in 30 minutes
await queue.add('reminder', { userId }, { delay: 30 * 60 * 1000 });
// Repeatable: cron-style scheduling via the modern Job Scheduler API (BullMQ 5.16+)
await queue.upsertJobScheduler(
'nightly-rollup', // stable scheduler id — re-runs are idempotent
{ pattern: '0 2 * * *', tz: 'UTC' },
{ name: 'nightly-rollup', data: {} },
);
// (The older queue.add(..., { repeat: { ... } }) still works but is being phased out.)
// Flow: parent job that waits for its children
import { FlowProducer } from 'bullmq';
const flow = new FlowProducer({ connection });
await flow.add({
name: 'send-report',
queueName: 'reports',
data: { userId },
children: [
{ name: 'fetch-events', queueName: 'analytics', data: { userId } },
{ name: 'render-pdf', queueName: 'pdf', data: { userId } },
],
});Repeatable jobs are stored in Redis, so duplicates can sneak in across deploys if you re-add them with slightly different options. The modern upsertJobScheduler API is idempotent by scheduler id — calling it on every boot with the same id re-uses the existing schedule. With the older add(..., { repeat }), set a stable repeat.key or check getRepeatableJobs() before adding.
FlowProducer is the underrated one. When you need "do A and B in parallel, then run C with their results," it removes a lot of ad-hoc orchestration code.
What A Worker Crash Actually Looks Like
Pull the power on a worker mid-job and Redis still has that job marked as active to that worker. BullMQ uses a per-job lock with lockDuration (default 30s). The worker renews the lock periodically. If the lock expires without renewal, the job is moved back to waiting and another worker can claim it.
This is the source of most "my job ran twice" stories. Your handler did 25 seconds of work, the lock expired, another worker grabbed it, and now both are running. The fix is honest: either keep handlers shorter than lockDuration, or extend the lock yourself with job.extendLock(token, ms) for long-running work, or accept that this can happen and lean on idempotency.
For graceful shutdown, listen for SIGTERM, call await worker.close(), and let in-flight jobs finish. Kubernetes gives you 30 seconds by default before SIGKILL — match lockDuration and your handler timeout to that budget.
A One-Sentence Mental Model
BullMQ does not make your jobs reliable; it makes Redis your coordination point so you can build reliability on top of dedupe IDs, idempotency keys, sensible retries, and a worker that cleans up after itself when the deploy comes.