
You've been handed a method called processOrder and asked to "just refactor it before the migration".
It's 380 lines long. There are 14 parameters, half of them booleans named things like skipDiscount and forceRecalculate. It calls into seven other methods you've never opened. There's a comment from 2018 that says // DON'T TOUCH - Finance will riot. The original author left in 2020. The ticket has two sentences and no acceptance criteria.
Your first instinct is reasonable. You open Cursor, select the whole method, and type "refactor this for readability". And that's where, statistically, things start to go wrong.
The problem isn't the AI. The AI is doing exactly what you asked. The problem is that you asked it to change something you don't yet understand. That's the order of operations almost everyone gets wrong, and the cost of getting it wrong used to be hours of debugging - now it's a 4,000-line diff that looks beautiful in review and quietly breaks the nightly billing job.
The fix is simple to describe and surprisingly hard to actually do: understand first, then refactor. The AI is excellent at both steps. But only if you treat them as two separate jobs.
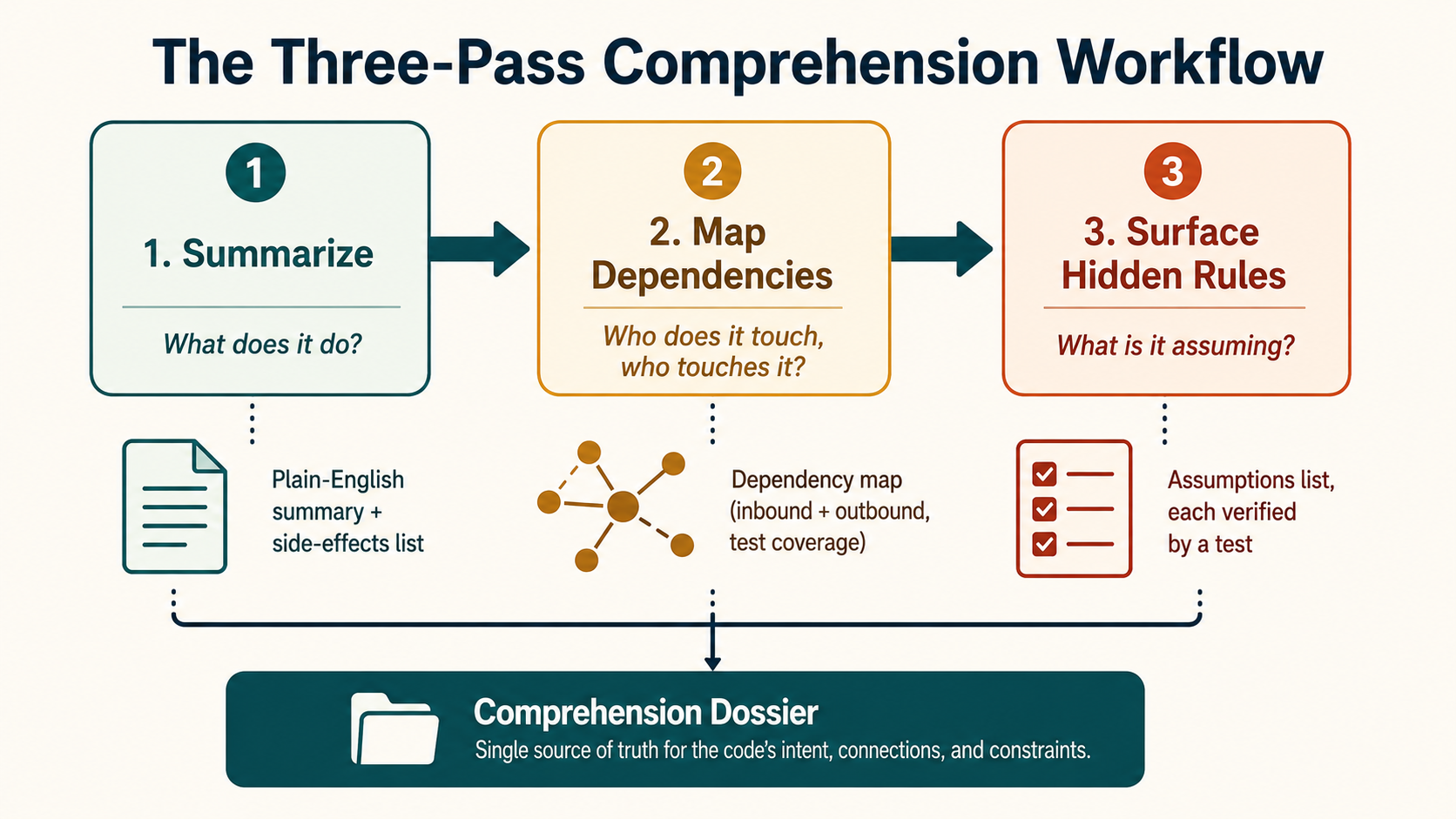
This piece is about that first job. Three concrete workflows for using AI to understand a legacy method before it changes a single character: summarization, dependency mapping, and hidden-rule surfacing. None of them write code. All of them produce an artifact you can read, share, and verify. And together they form what I'd call a comprehension dossier - the thing you wish the original author had left behind.
Why "Understanding" Is The Step We Skip
The industry doesn't reward understanding. It rewards diffs. Story points, PR counts, "throughput" - all of them measure the volume of changes you produce, not the depth of what you know about the system. So when AI showed up and made changes ten times cheaper, the natural instinct was to make ten times more changes. The instinct to also make understanding ten times cheaper came later, if at all.
That's a mistake, and it's getting more expensive every quarter.
AI is a force multiplier. Whatever you point it at, it does faster. Point it at "refactor", and you get a refactor at AI speed - including all the parts you didn't realize the method was doing. Point it at "explain", and you get understanding at AI speed - including the parts of the method you would never have noticed by reading. Same model, completely different value, depending only on the verb you chose.
The senior-engineer move here is to spend the first hour on the explain side and earn the right to spend the second hour on the change side. That hour buys you a refactor that lands cleanly, a PR that reviews itself, and a Sunday evening that doesn't get interrupted by a pager.
There's a natural order to the three passes below, and it matters. You can't map dependencies of something you can't summarize. You can't see hidden rules until you know who the consumers are. Each pass builds on the last. Skipping ahead is how you end up with a "refactor" that breaks something nobody told you about.
Pass 1 - Summarization (What Does It Actually Do?)
This is the highest-leverage AI use case in legacy code, and almost no one runs it as its own step. People go straight from "let me skim this method" to "let me refactor it" and skip the part where they get a clear, written description of what it does.
The goal of Pass 1 is to produce a one-paragraph plain-English description of the method, written from the outside in. What does it take? What does it return? What does it change in the world? Not a line-by-line walkthrough. A summary, the kind you'd type into Slack to explain the method to a teammate over coffee.
The prompt is boring on purpose:
Below is a single method from a legacy codebase. I want you to:
1. Describe in 3-5 sentences what this method does, from a caller's perspective.
2. List every input parameter and what it appears to be used for.
3. List every value the method returns (or "void" + what it mutates).
4. List every side effect: database writes, network calls, file I/O,
event emissions, exceptions thrown, fields mutated on the input objects.
Do not suggest improvements. Do not explain how it could be simplified.
I am not refactoring yet. I am only trying to understand.
<<< method goes here >>>The "do not suggest improvements" line is doing a lot of work. Without it, the model drifts within two paragraphs into "here's how I'd clean this up", which is precisely the thing you're trying not to do right now. You're not building a plan yet. You're building a baseline.
Read the output critically. The model will sometimes invent a side effect that isn't there ("this method probably logs to an audit table" - it doesn't) or miss a real one ("calls the mailer inside a try/catch with no rethrow, silently swallows email failures" - it does, but the model walked past it). Both failure modes are common. Treat the summary as a starting hypothesis, then scan the method once with the summary in hand to check each claim against the actual code.
When you're done, you should have a single short paragraph that captures the method's behavior at the boundary - inputs, outputs, side effects - and a list of any claims you couldn't verify. That paragraph is the anchor for everything that comes next. Pin it somewhere it won't get lost: the ticket, a Notion doc, the top of the method's file. You'll re-read it three times before you ship the refactor.
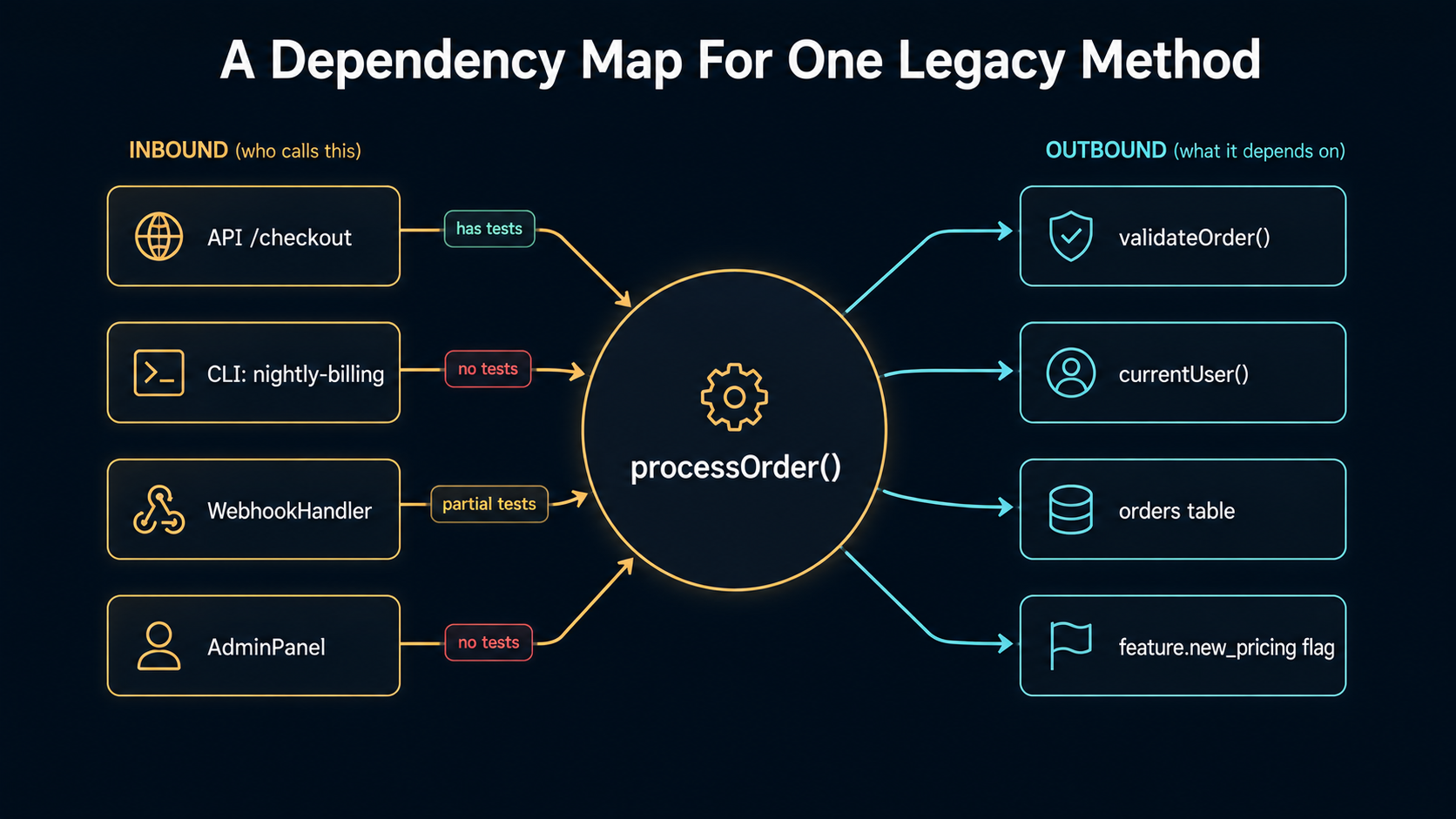
Pass 2 - Dependency Mapping (Who Cares About This Method?)
A method does not live in isolation. The thing that breaks when you refactor it isn't the method itself - it's the seven callers that depended on its old behavior in ways the method's own code doesn't reveal.
This is where AI saves you the most time, because enumeration is something models are unreasonably good at. Walking a real codebase by hand to find every call site, every override, every test, every config reference - that's hours of grep, click, scroll, miss-something, grep again. AI does it in minutes with the right setup.
The workflow has two halves: what the method calls into, and who calls it.
Half one - outbound dependencies. What does this method touch?
For the method below, list every external dependency it uses:
- Every other method or function it calls.
- Every static helper or utility.
- Every database table or query.
- Every environment variable or config flag.
- Every external service (HTTP client, queue, cache, etc.).
- Every global or singleton it reads from or writes to.
For each entry, note whether the dependency is "obvious from the signature"
or "hidden in the body".
<<< method goes here >>>The obvious vs hidden framing is the important part. Hidden dependencies are the ones that bite: a currentUser() global buried five lines deep, a cache wrapper that quietly serves stale data, a feature flag that flips behavior in production but not in staging, a logger that swallows exceptions in test mode. Surfacing them upfront is the whole point of this half. Once they're on paper, they're tractable. Until then, they're traps.
Half two - inbound dependencies. Who calls this method?
This one needs more than just the method body. The model needs the codebase. In modern AI coding tools (Cursor, Claude Code, Aider, Continue, Cody) you can simply ask:
Search the codebase for every call site of `OrderService.process`.
For each one, tell me:
- The file and line.
- The conditions under which it's called (the surrounding `if`,
the function it lives in, the route or job it belongs to).
- What the caller does with the return value.
- Whether the caller has its own test coverage that exercises this call.That last point matters more than people realize. A caller without test coverage is a caller whose behavior you cannot safely change, because nothing will catch the regression. The model can tell you which call sites are "load-bearing but unprotected". Those are your highest-risk consumers, and they're where your characterization tests need to go first.
You're now building a map. Not a UML diagram (please do not make a UML diagram). A simple one-page sketch: the method in the middle, arrows out to its dependencies, arrows in from its callers, every arrow annotated with what the other end cares about. A whiteboard is fine. A napkin is fine.
When the sketch is complete, you should be able to answer the question: "If I change the return type of this method from Order to OrderResult, how many places break, and which of them have tests?" The answer to that question is the difference between a one-day refactor and a three-week incident.
Pass 3 - Hidden Rules (The Stuff The Code Doesn't Say)
This is the hardest pass and the one with the most upside. Hidden rules are the implicit invariants the method relies on but doesn't enforce. The things that used to be true about the inputs, the database, the surrounding system, the time of day, the calling context - that nobody documented but everybody assumed.
A few categories, with shapes I'd recognize in any large codebase:
- Order-of-operations assumptions. "This method must be called after
validateOrderhas run on the same request." Nothing in the code says so. Call them out of order and you get a corrupted record that passes every validation later. - Input-shape assumptions. "The
itemsarray always has at least one element, because the upstream filter removes empty carts." The upstream filter got refactored away two years ago. The method now silently returns0for empty arrays and the dashboard quietly under-reports revenue. - Environmental assumptions. "This method assumes the request is wrapped in a database transaction." Run it from a CLI command, and you get partial writes when the third query fails.
- Temporal assumptions. "This method assumes the current date is a business day." Run it from a Saturday cron and the resulting invoices have invalid due dates.
- Field-presence assumptions. "If
customer.tieris null, treat asstandard." Nothing in the code sayscustomer.tiercan be null - but if it ever is, the rest of the codebase will crash because it assumes the field is always set. - Concurrency assumptions. "Only one caller will ever invoke this for a given order at the same time." The original author was right in 2017. The new retry policy added in 2023 is wrong.
The prompt:
Read this method carefully and list every assumption it appears to make
about its inputs, its environment, or the broader system state.
I'm specifically looking for things that aren't enforced in the code
but that the method clearly relies on. Examples:
- "Assumes `user.organization` is loaded" (used, never checked).
- "Assumes there's an active DB transaction" (rollback-able operations
happen but no transaction is started here).
- "Assumes the calling code has already verified permissions"
(no auth check inside).
- "Assumes the input array is sorted by date" (relies on order
without sorting).
Do not speculate. Only flag assumptions that are visible in the code,
anywhere a value is *used* without first being *checked* or *guaranteed*.
<<< method goes here >>>The used without checked or guaranteed framing keeps the model anchored. Without it you get speculation ("the method assumes the user has a name"). With it you get testable claims ("the method dereferences customer.subscription.tier without a null check on customer.subscription").
Now - and this is the important part - verify each one with a real test, not by reading. Write a small test that violates the assumption. Pass in customer.tier = null. Run the method outside a transaction. Pass an empty items array. See what happens. If the test fails with a null pointer or a partial write, the hidden rule was real. If it passes, the assumption was overcautious and you've just learned that the method is more robust than it looked.
This pass takes the longest. Twenty assumptions isn't unusual for a 300-line legacy method. Most of them turn out to be either trivially true or already protected by something else upstream. The three or four that genuinely fall over when you actually probe them - those are the reason you do this pass at all. Those are the bugs that would have shipped with your "clean refactor" and surfaced two months later, blamed on AI for the rest of time.
What You're Left With
Three passes, each producing a tangible artifact. Together they form a comprehension dossier for the method:
- A summary - a short plain-English paragraph capturing behavior and side effects.
- A dependency map - inbound and outbound, with test-coverage annotations on the callers.
- A list of hidden rules - each one either verified by a test or marked "needs investigation".
It takes longer than people expect. Maybe two hours for a complex method. Maybe a full afternoon for a 500-line monster with thirty call sites and a tangled history. That's enough time to feel uncomfortable about not having "shipped anything yet" - which is the moment to remember why you're doing this.
The trade is unambiguous. Without the dossier, the refactor takes a day to write, a week to debug, and there's a non-zero chance it never fully stabilizes. With the dossier, the refactor takes the same day to write but an afternoon to verify, because you already know what could break and you've already written tests against it. The math is in favor of the dossier almost every time, and AI is what makes the dossier cheap enough to actually build in 2026 rather than three years from now.
A nice side effect: the dossier itself is a teaching artifact. The next person who has to touch this method (it might be you in six months) gets to start from your notes instead of from zero. If you save them anywhere durable - the ticket, a wiki, a comment block in the method - you've turned a private hour of comprehension into a permanent piece of institutional memory.
A Note On Tooling
The three workflows above are deliberately tool-agnostic. They work in Cursor, Claude Code, Aider, Continue, Copilot Chat, Cody, or just a chat window with copy-paste. The difference between them is mostly how much of the codebase the model can see at once.
- Pass 1 (summarization) works anywhere. The model only needs the method body.
- Pass 2 (dependency mapping) wants a tool with whole-repo grep. Cursor, Claude Code, Aider, Cody all qualify. Copy-paste chat works for outbound deps but is painful for inbound.
- Pass 3 (hidden rules) is mostly the method body, with occasional dives into the immediate callers. Anywhere with file-level context is fine.
If your tool has a "compose a system prompt" feature, set it to something like: "You help engineers understand legacy code. You never suggest changes. You report what is, not what should be." It cuts down on the model's natural drift toward "let me clean this up for you", which is the single most common failure mode of code-aware models when you actually wanted them to sit on their hands.
The Real Skill Is Restraint
The hardest part of all of this is not the prompts. It's resisting the urge to skip straight to the change.
The model is fast. You can have a refactored version of the method in your editor in under two minutes. It will look reasonable. It will pass the existing tests, because the existing tests don't cover any of the things you didn't know about. It will make it through code review, because the diff is "just cleanup" and nobody on your team has the time or context to push back. And then it will be merged. And then it will quietly break a downstream consumer that nobody owns. And then the on-call engineer will spend Saturday morning figuring out why the nightly billing job started skipping accounts with tier = null.
Comprehension is unglamorous. There's no diff at the end of the day. The tracker still says "in progress". You can't show your manager a screenshot of a comprehension dossier and feel productive in the same way you can show them a green PR.
But the gap between engineers who do comprehension first and engineers who refactor first is widening fast, because the cost of not understanding is being amplified by the same tools that make refactoring cheap. The model multiplies whatever discipline you brought to the task. Bring none, and you get fast confident changes to things you didn't understand. Bring the three passes above, and you get the same speed on the change plus the only thing that actually makes legacy refactoring safe: a clear picture, written down, of what was there before you touched it.
Understand first, with help. Then change, with confidence. The order is the whole game.





