
You ship an endpoint. Locally it returns in 40ms. The PR sails through review. Two weeks later, your APM lights up with a single endpoint averaging 1.8 seconds, and the database CPU graph looks like a flat tire. You open the trace and see it: one request firing 51 SQL queries. One to load the orders. Fifty more to load each order's customer.
That's N+1.
It's the most boring, most repeatable performance bug in backend engineering, and it never stops shipping. Every framework has tools to prevent it. Every team gets bitten by it anyway. The reason isn't laziness. It's that ORMs are explicitly designed to make the N+1 version of your code look identical to the joined version. Only the query count changes, and the query count is invisible until something breaks.
This piece is the long version of what to do about it in Node. We'll walk through where N+1 actually comes from, why each popular ORM has its own flavour of the trap, how to fix it cleanly with eager loading, how to escape it with batching when eager loading isn't an option, and how to make the bug impossible to merge in the first place.
What N+1 Actually Means
The name comes from the query count. You run 1 query to load a parent collection, then N queries, one per row in that collection, to load a child relation. Total: N+1.
The shape in real code almost always looks like this:
// fetches all orders, then fires one customer query per order
const orders = await Order.findAll({ where: { status: 'paid' } });
for (const order of orders) {
const customer = await order.getCustomer(); // <-- one query, every loop
order.customer = customer;
}If you load 50 orders, you fire 51 queries. If you load 1000, you fire 1001. The endpoint scales with the size of the result set instead of being constant, and the database starts paying the round-trip cost over and over for what could have been a single JOIN.
The brutal part is that none of those individual queries are slow. Each one returns in 3ms. Add a network hop, and you're at maybe 5ms per query. Fifty of those is a quarter of a second the user is waiting for, and you didn't even add a feature. You just listed some orders.
This is the part that confuses people: the slow query log won't catch it. Each query is fast. The database isn't doing anything wrong. The bug lives entirely in your application layer, in the loop that doesn't know it's a loop.
Why ORMs Quietly Encourage The Bug
Every ORM in the Node ecosystem will give you N+1 if you ask for it innocently. The reason is the same in all of them: lazy loading. Accessing a relation property fires a query, and accessing properties looks like free reads in JavaScript.
Here's the same bug in five popular libraries.
Sequelize
const orders = await Order.findAll();
for (const order of orders) {
const customer = await order.getCustomer(); // N queries
}TypeORM
const orders = await orderRepo.find();
for (const order of orders) {
const customer = await order.customer; // N queries via lazy relation
}Mongoose
const orders = await Order.find();
for (const order of orders) {
const customer = await User.findById(order.customerId); // N queries
}Prisma
Prisma actually doesn't have lazy loading. Relations are only populated if you ask for them. But the bug still shows up when people loop and re-fetch:
const orders = await prisma.order.findMany();
for (const order of orders) {
const customer = await prisma.user.findUnique({ where: { id: order.customerId } });
}Drizzle
const orders = await db.select().from(ordersTable);
for (const order of orders) {
const [customer] = await db.select().from(usersTable).where(eq(usersTable.id, order.customerId));
}Notice the pattern. The shape of the bug is the same everywhere: load a list, loop, fetch one related record per iteration. The reason every ORM has it isn't a design flaw. It's that "give me the related object for this entity" is the most natural thing to want to write, and the ORM has no idea you're about to ask for it fifty more times.
Eager Loading Is The First Fix
For anything you can predict, the fix is to tell the ORM up front: "I'll need the customer for every order in this query." The ORM then generates one query with a JOIN (or a follow-up IN (...) query) and returns parents with children already attached.
Each library expresses this differently, but the idea is identical.
const orders = await Order.findAll({
include: [{ model: Customer, as: 'customer' }],
});
// one query with a LEFT JOINconst orders = await orderRepo.find({
relations: { customer: true },
});
// one query with a LEFT JOIN (when relations are not lazy)const orders = await prisma.order.findMany({
include: { customer: true },
});
// two queries: one for orders, one IN(...) for customers — but constant, not N+1const orders = await db.query.orders.findMany({
with: { customer: true },
});
// uses the relations() config; one or two queries depending on cardinalityconst orders = await Order.find().populate('customer');
// one find on orders, one IN(...) query on usersTwo things worth noticing about the "fixed" versions:
- The application code barely changed. That's why N+1 keeps shipping: the difference between the broken and the fixed version is one
includeorwithorpopulate, and reviewers rarely catch a missing one. - Not all eager loading is a single JOIN. Prisma and Mongoose deliberately issue a second query with
WHERE id IN (...)instead of aJOIN, because hydrating duplicated rows from a JOIN in JavaScript is often slower than two clean queries. That's fine. It's still constant query count, which is the only number that matters.
The skill of eager loading isn't knowing the syntax. It's catching every relation a code path actually walks. If your serializer touches order.customer.organization.billingPlan, you need all three relations included, not just customer. Stage that mental walk every time you write the query.
When Eager Loading Isn't Enough: DataLoader
Eager loading works when the parent that needs the children knows about them at query time. It falls apart in two situations:
- GraphQL resolvers, where each field is resolved independently and the parent has no idea what fields the client will ask for.
- Long object graphs assembled by services that don't share a query, where the orders service returns orders, then a separate customer service is asked to enrich them.
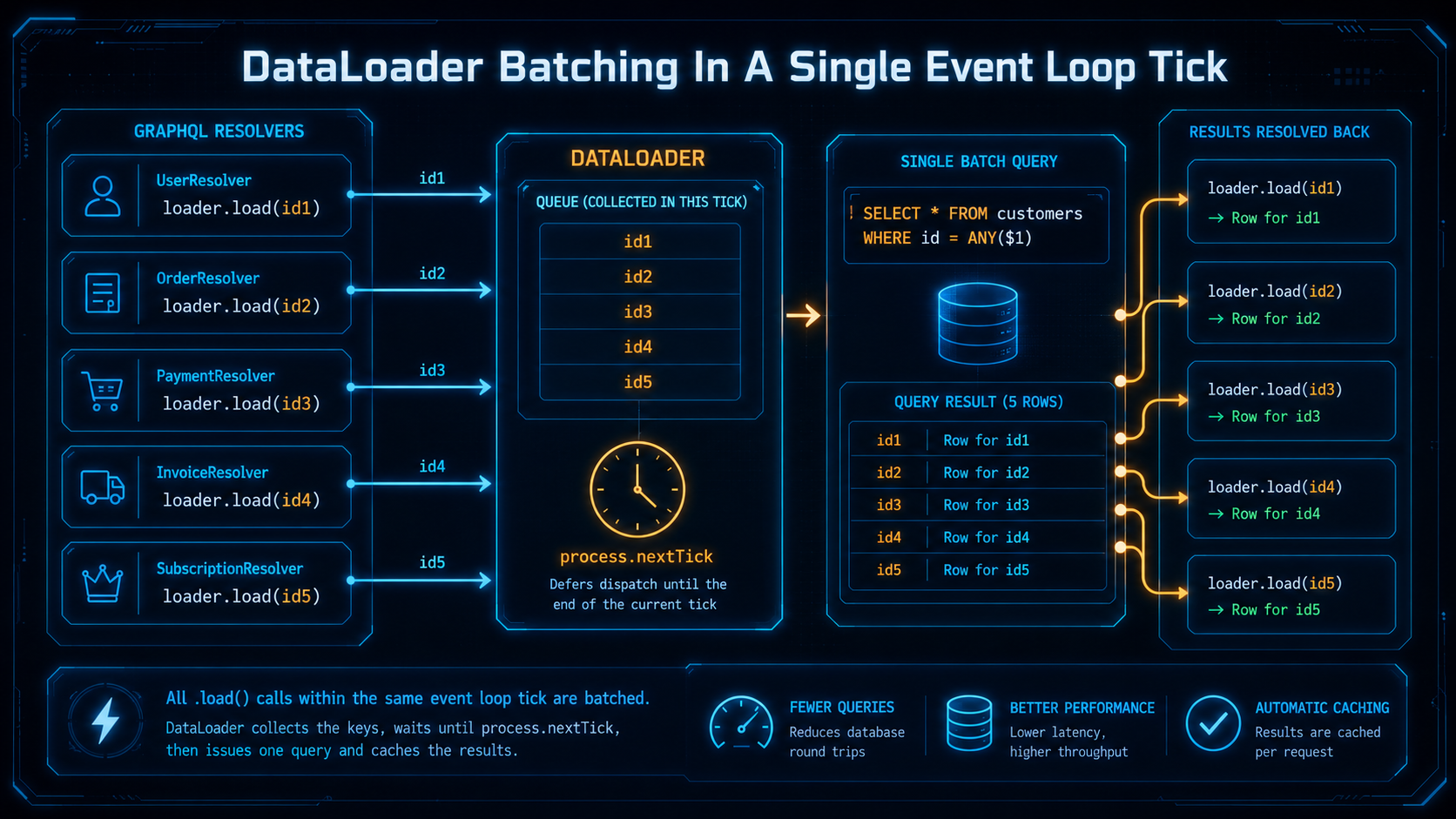
For both, the canonical fix is DataLoader, a tiny library from the Facebook/Meta team that batches and caches per-request lookups.
The trick is simple. You define a batch function that takes an array of keys and returns an array of results in the same order. DataLoader buffers requests during a single tick of the event loop, then calls the batch function once with all the collected keys.
import DataLoader from 'dataloader';
import { db } from './db';
export function createCustomerLoader() {
return new DataLoader<string, Customer>(async (ids) => {
const rows = await db.query(
'SELECT * FROM customers WHERE id = ANY($1::uuid[])',
[ids],
);
const byId = new Map(rows.map((c) => [c.id, c]));
// CRITICAL: return results in the same order as the input keys
return ids.map((id) => byId.get(id) ?? new Error(`Customer ${id} not found`));
});
}In a GraphQL resolver:
const resolvers = {
Order: {
customer: (order, _args, ctx) => ctx.loaders.customer.load(order.customerId),
},
};Even though the resolver runs once per order, DataLoader collects all the customerIds asked for in the same tick, fires one WHERE id = ANY(...) query, and hands each resolver its result. The N+1 becomes a 1+1.
Three things to get right or it doesn't work:
- One loader per request, not one global loader. The cache must die with the request, or you'll serve stale data to the next user.
- Batch function returns must match input order. This is the contract. Wrap your DB rows in a
Map, then map over the input keys. Don't return the raw rows. They come back in whatever order the database felt like. - Return
Errorinstances for missing keys. DataLoader treats them as per-key errors instead of failing the whole batch.
DataLoader looks like a GraphQL-only library because that's where it was born, but it's just as useful in REST. Anytime you have a code path that enriches a list of items by calling a service or a database per item, DataLoader turns the N calls into one. The "tick" it batches across is the JavaScript event loop, not anything framework-specific.
Dropping To SQL When The ORM Gets In The Way
There are cases where neither eager loading nor DataLoader is the cleanest answer. Aggregations across relations, conditional joins, and complex filtering often want a single hand-written query.
Take this: load the 50 most recent orders, with their customer and the customer's organization, and only include orders where the organization has the enterprise plan. In Prisma it's a nested where that gets ugly. In SQL it's three joins.
SELECT o.*, c.name AS customer_name, org.name AS org_name
FROM orders o
JOIN customers c ON c.id = o.customer_id
JOIN organizations org ON org.id = c.organization_id
WHERE org.plan = 'enterprise'
ORDER BY o.created_at DESC
LIMIT 50;One query. Indexed correctly, it'll run in single-digit milliseconds even against millions of rows. The ORM's worth comes from CRUD ergonomics and type safety, not from being the only way to talk to the database. The 5-10% of queries that matter most for performance are usually the ones worth dropping to raw SQL for.
Drizzle and Kysely both let you do this without giving up type safety, which is part of why they've gained ground. With Prisma, $queryRaw works fine for the rare case. Just template-tag your params and keep the query in one file so it stays reviewable.
The Hidden N+1: Serializers And Lifecycle Hooks
The N+1 you write in a route handler is the easy kind. The one that ships is almost always somewhere else.
Serializers. You wrote a clean route that uses include correctly. Then someone added a toJson() method on the model that calls this.tags(), which lazy-loads. Now every response triggers a hidden query per item, regardless of how carefully you fetched.
Lifecycle hooks. A Sequelize afterFind hook that loads an audit log per record. A Mongoose post('find') hook that hydrates a permission. These run inside the framework's data-access path, so they're easy to forget about.
Computed fields in GraphQL. A User.fullName resolver that loads user.profile if it's not present. Looks innocent. Fires N queries when a list of users is requested.
Authorization checks. Every middleware that runs per resource, the "can this user see this order?" check, is a candidate for N+1 if it loads anything from the database. The fix is usually to load all the orders' permissions once at the top of the request, or to use a DataLoader for the policy lookups.
When you're hunting an N+1 in a live system, the route handler is almost never where you'll find it. Look at the serializer first, then the model layer, then any middleware that runs per item. The query log will tell you what's firing. You just have to map it back to the code path.
Observability Is The Real Fix
The thing that ships the bug isn't bad code. It's invisibility. If you can't see the query count, you can't catch the regression. So step one of every Node service that talks to a database is: make the query count visible.
In development, log every query and a per-request total:
// db.ts — pg pool wrapper
import { Pool } from 'pg';
import { AsyncLocalStorage } from 'node:async_hooks';
const requestContext = new AsyncLocalStorage<{ count: number }>();
const pool = new Pool({ /* ... */ });
const originalQuery = pool.query.bind(pool);
pool.query = (async (...args: Parameters<typeof originalQuery>) => {
const ctx = requestContext.getStore();
if (ctx) ctx.count++;
return originalQuery(...args);
}) as typeof pool.query;
export function withQueryCounting<T>(fn: () => Promise<T>) {
return requestContext.run({ count: 0 }, async () => {
const start = Date.now();
const result = await fn();
const { count } = requestContext.getStore()!;
const ms = Date.now() - start;
console.log(`[db] ${count} queries in ${ms}ms`);
return result;
});
}Wire it as Express middleware:
app.use((req, _res, next) => withQueryCounting(() => new Promise((resolve) => {
res.on('finish', resolve);
next();
})));Once you can see [db] 51 queries in 230ms in your terminal, the N+1 stops being abstract. You'll fix it before you commit, because the number is offensive.
In production, the same idea lives in your APM. OpenTelemetry's database instrumentation will give you query count per span. Datadog, New Relic, and Sentry all expose a database-queries-per-request metric. Set an alert on the 95th percentile and N+1s announce themselves.
Catching N+1 In Tests
Once you have query counting, you can make N+1 a test failure. The pattern is straightforward: wrap the endpoint call, count queries, assert a maximum.
import { request } from 'supertest';
import { app } from './app';
import { countQueries } from './test/db';
test('GET /orders is constant-query regardless of result size', async () => {
await seed({ orders: 50 });
const { count } = await countQueries(async () => {
const res = await request(app).get('/orders').expect(200);
expect(res.body).toHaveLength(50);
});
expect(count).toBeLessThanOrEqual(3); // 1 for orders + 1 for customers + 1 for tags
});The threshold is the trick. Don't assert count === 1. That breaks every time you legitimately add a relation. Set it to the maximum number of queries the endpoint should ever need given the relations it hydrates. When that number changes, you have a conversation, not a silent regression.
The same pattern works for GraphQL endpoints: wrap your test client, count queries during the request, assert the cap. The point isn't to prevent any growth in queries; it's to prevent growth that scales with the input size.
GraphQL Deserves Its Own Note
GraphQL is the place N+1 lives rent-free, because the query the client sends doesn't map to a single database query. Every field with its own resolver is an opportunity to fire one more query.
Three rules that prevent most GraphQL N+1s:
1. Every relation field on a type goes through a DataLoader. Don't reach into the ORM from a resolver. If Order.customer is asked for, it calls ctx.loaders.customer.load(order.customerId). Always. This makes the resolver one line and makes N+1 impossible by construction.
2. Aggregate the query at the top of the field, not inside the loop. If a list resolver needs to know "did this user like this post" for a list of posts, don't loop. Fetch all likes for (user.id, postIds) once, build a Map, return from it.
3. Use a complexity analyser. Tools like graphql-cost-analysis let you reject queries that would explode into too many resolutions. A client asking for users { orders { items { product { reviews { author { orders { ... } } } } } } } should get a 400, not melt your database.
The general principle: in GraphQL, treat every field with a non-scalar type as a place that will be called once per parent, and design accordingly. If you would not be comfortable with that field firing N queries, it needs a loader.
A Useful Mental Checklist Before You Merge
When you're reviewing your own diff (or someone else's), three questions catch most N+1s before they ship:
- "Does any property access inside a loop touch a relation?" If yes, eager load it, or batch it.
- "Does the serialiser, the hook, the middleware, or the GraphQL resolver touch a relation that wasn't asked for at the top?" If yes, it'll fire per item.
- "What's the query count for this endpoint with 1 item versus 100 items?" If those numbers differ by more than a constant, you have an N+1. Run the test.
Most of the time the fix is small. Add the include. Add the loader. Move the fetch up one level so it sees the whole list. The expensive part is noticing.
The Underlying Lesson
N+1 isn't really a database bug. It's a visibility bug. The ORM hands you a beautiful object-graph abstraction, you write code that walks the graph, and the cost of each step is invisible until the system is under real load. Every fix in this article, whether eager loading, DataLoader, or dropping to SQL, is just a way to make the graph traversal explicit again.
The single change that pays back the most is logging the query count per request and looking at it. Once that number is in front of you, the rest becomes obvious. Until then, you're flying blind, and the bug ships every time.





