
Microservices look great on a whiteboard. Three neat boxes, two arrows, one shared database that someone draws and then awkwardly erases. Then you ship it, traffic shows up, and suddenly you're staring at a Slack thread titled "why is checkout 8 seconds" with seventeen people in it.
This isn't an article about whether you should split a monolith, you probably shouldn't, until you have to. It's about what actually happens when you commit to Node.js microservices in production: where the service lines go, how messages move between them, what failure looks like, how you see anything at all when something breaks at 3am, and how you deploy a fleet of small Node processes without it turning into a part-time job.
Pour a coffee. This one's going to be long, because the topic is.
What "microservice" actually buys you (and what it costs)
Before we talk about service boundaries, let's be honest about the trade. A microservice is a deployable unit with its own process, its own data ownership, its own release cadence, and its own failure domain. You get:
- Independent deploys. The payments team can ship at 2pm without coordinating with search.
- Failure isolation. If the recommendations service melts, checkout still works.
- Tech-stack freedom. Search can be Go, payments can be Node, ML inference can be Python.
- Scale where it hurts. You scale the 80%-CPU service to 12 replicas without paying for 12 copies of everything else.
You pay for it with:
- Distributed everything. Every method call is now a network call that can be slow, missing, duplicated, or out of order.
- Consistency is now your problem. No more "wrap it in a transaction." You're shipping eventual consistency whether you wanted to or not.
- Operational surface area. Ten services means ten dashboards, ten deploy pipelines, ten on-call playbooks.
- A different debugging mindset. Stack traces don't cross process boundaries. You need traces, structured logs, and the patience of a saint.
If you've ever heard someone say "we'd have shipped this in a day on the monolith," they're usually right. Microservices buy you long-term independence at the cost of short-term simplicity. Make sure you're spending the money on something you actually need.
Drawing service boundaries
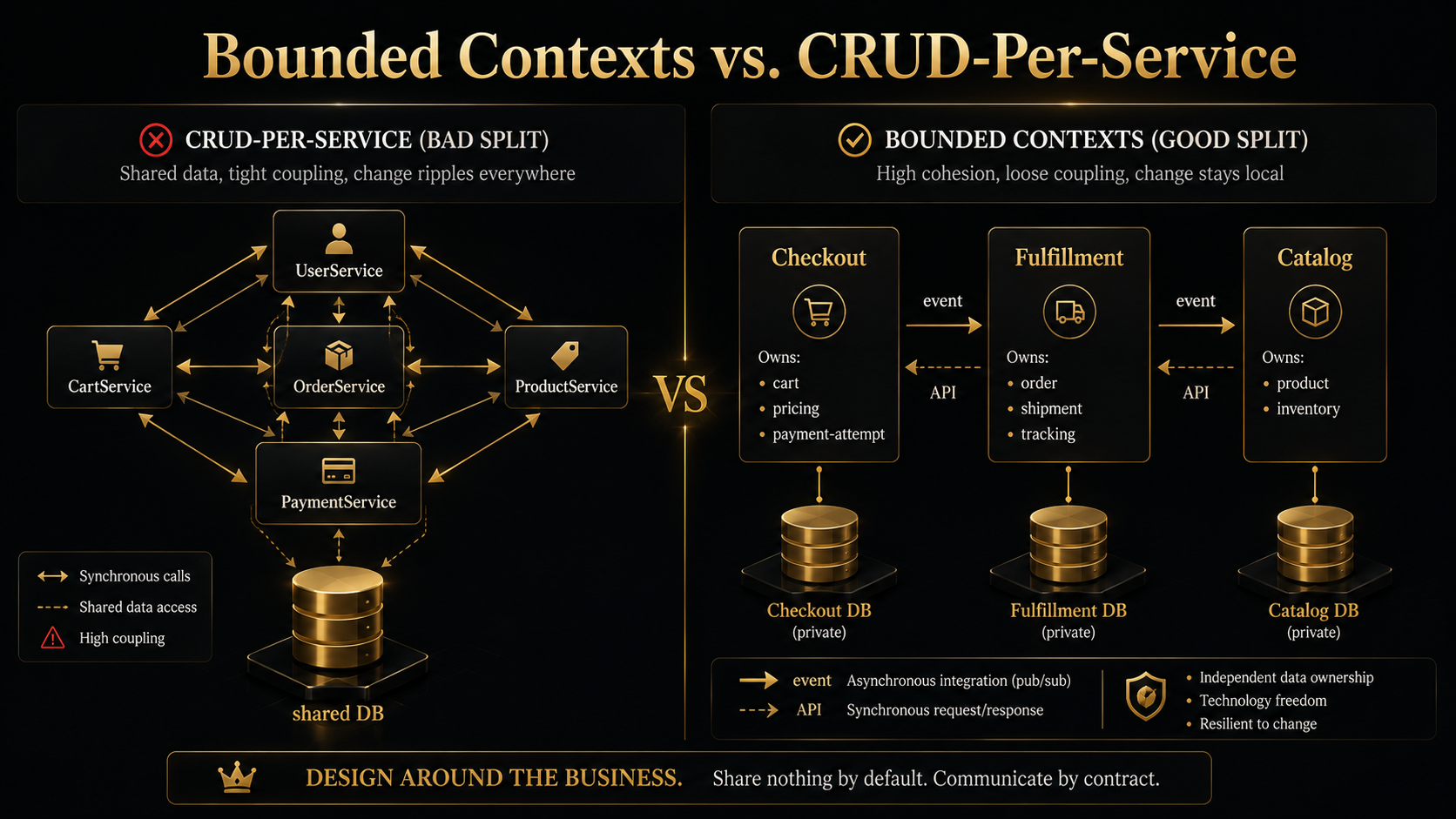
This is the part everyone gets wrong, including past versions of you and me. The bad heuristic is "one service per noun", UserService, OrderService, ProductService, CartService. You end up with services that all talk to each other constantly because the domain isn't actually decomposed; you just sharded a CRUD layer.
The better heuristic comes from domain-driven design: split along bounded contexts, not nouns. A bounded context is a region of the business where words mean the same thing consistently. "Order" inside the checkout context is a half-formed thing with a cart, an address, and a payment attempt. "Order" inside the fulfillment context is a finalized record with shipping labels and tracking numbers. Same word, different model, different lifecycle, different team. That's two services.
Three concrete questions to ask before you cut a line:
1. Who owns the data? If two services both write to the same table, you don't have two services, you have one service in a trench coat. Each service should own its data exclusively. Other services read it through APIs or events, never through SQL.
2. Can it release on its own schedule? If shipping inventory always requires shipping orders in lock-step, the boundary is wrong. You haven't decoupled; you've just added latency.
3. What happens if it's down for 10 minutes? If the answer is "everything stops," it's not really a separate service, it's a critical dependency dressed up as one. Either fold it back in, or make the caller resilient.
A pattern that works in practice: start with a modular monolith. One Node.js codebase, one deploy, but strict internal boundaries, folders that import only from their own public API, no shared mutable state, separate database schemas per module. When a module genuinely needs to scale or release independently, you extract it. By that point the seams are obvious because you've already drawn them in code.
The mistake is going the other direction: starting with five services on day one and discovering, six months in, that two of them are always deployed together and one is just a CRUD wrapper around someone else's table. Now you have to un-microservice it, which is the worst kind of refactor.
The Node.js part: what makes it well-suited (and where it bites)
Node.js is a fantastic fit for microservices for one big reason: services are mostly I/O. They wait on databases, queues, downstream APIs, disks. The event loop is built for exactly that, thousands of concurrent in-flight operations on a single thread, scheduled cooperatively.
But the same property that makes it shine is what bites you when you're careless:
- A single blocked tick blocks the entire process. Synchronous
JSON.parseon a 50MB payload, a regex with catastrophic backtracking, a synccrypto.pbkdf2Synccall, any of these freeze the service. Not "make it slow." Freeze it. Health checks fail, retries pile up, your one Node process becomes a black hole for the cluster. - CPU-bound work needs worker threads. Node 10.5 introduced the
worker_threadsmodule specifically for this. If your service does image transforms, heavy JSON crunching, or cryptographic work in the request path, that work belongs in a worker thread, not the main loop. Otherwise you're choosing between latency and throughput for every concurrent request. - Unhandled promise rejections used to be warnings; since Node 15 they crash the process by default. That's the right behavior, let the orchestrator restart it, but it means every async path needs error handling, including the ones you forgot about.
- Memory leaks compound at scale. A leak that takes 24 hours to OOM on one box takes the same 24 hours when you scale to 30 boxes. They just all crash at once.
The practical rule: pick Node for services that are mostly waiting on something. Pick something else for services that are mostly grinding (Go, Rust, even Python if there's a C extension doing the work). You can mix them happily, that's part of the point.
How services should actually talk
You have two main shapes of communication, and a lot of bad patterns come from picking the wrong one.
Synchronous (request/response)
HTTP and gRPC fall here. Service A calls service B and waits for an answer. Use this when:
- The caller genuinely cannot continue without the answer.
- The latency budget allows for a round trip.
- The callee is fast and reliable.
Use it sparingly. Every sync call is a coupling: A is now only as available as B, and chains compound multiplicatively. Three sync hops at 99% availability each gives you 97% availability overall. Five hops at 99.9% gives you 99.5%. The math is not your friend.
For sync, prefer gRPC over JSON-over-HTTP between services. Schema-first, typed, binary on the wire, streaming built in, much faster to serialize. JSON-over-HTTP is fine for edges (browser, mobile, third parties); inside the mesh, the cost of schemaless string-based communication adds up.
import { credentials } from "@grpc/grpc-js";
import { PaymentsClient } from "@/gen/payments_grpc_pb";
export const payments = new PaymentsClient(
process.env.PAYMENTS_ADDR!,
credentials.createInsecure(),
{
"grpc.keepalive_time_ms": 10_000,
"grpc.keepalive_timeout_ms": 5_000,
"grpc.max_receive_message_length": 4 * 1024 * 1024,
}
);Note the keepalive settings, without them, intermediate load balancers will silently drop idle connections, and the first call after a quiet period will mysteriously fail. This is a top-three "why is one request a second slow" cause in production gRPC.
Asynchronous (messaging)
A publishes an event or job, B (and C, and D, and the analytics team's future intern) consume it. Use this when:
- The caller doesn't need an immediate answer.
- You want fan-out (multiple consumers).
- You want failure isolation, if the consumer is down, messages queue up rather than failing the caller.
- You want temporal decoupling, the consumer can be slower than the producer for a while.
This is where most of the resilience in a microservice architecture comes from. Every sync call you can turn into an async event makes the system more available. Order placed? Fire an OrderPlaced event and let inventory, notifications, analytics, and the recommendation model each handle it on their own schedule. Don't have the order service wait for them.
The trade is eventual consistency. The moment after OrderPlaced fires, the order exists but the email hasn't been sent, the warehouse hasn't been notified, the recommendation hasn't updated. That window might be milliseconds; it might be seconds. Your product, your APIs, and your users need to be okay with that.
Picking a message broker
This deserves its own section because the choice has long tails. The three you'll most often encounter from Node:
RabbitMQ. Mature, traditional message broker. Routes messages through exchanges to queues using topic, direct, or header bindings. Per-message acknowledgements, dead-letter exchanges, priority queues. Great for work-queue workloads, one producer, N consumers, each message handled once. The Node client is amqplib. Defaults that bite you: messages are non-persistent unless you mark them so and declare the queue durable.
Apache Kafka. Not really a message broker, a distributed commit log. Producers append to partitioned topics, consumers track their own offset. Built for high-throughput streaming and event sourcing. You get replay (consume from any point in history), strong ordering within a partition, and consumer-group scaling. You pay with operational complexity (it's a stateful distributed system you have to actually understand) and the fact that "I just want a simple queue" is the wrong tool. From Node, use kafkajs.
NATS / NATS JetStream. Lightweight pub/sub, with JetStream adding persistence and replay. Very fast, very simple to operate compared to Kafka. JetStream is younger than Kafka so the ecosystem is smaller, but for many event-driven workloads it's a great middle ground.
Rough decision tree: work queue with per-message handling and complex routing → RabbitMQ. Event stream with replay, ordering guarantees, and high throughput → Kafka. Pub/sub with persistence where Kafka feels like overkill → NATS JetStream.
Whichever you pick, the message contract is now part of your public API. Once consumers depend on a field, you can't remove it without breaking them. Treat schema changes the same way you'd treat HTTP API changes: additive, versioned, with a migration plan.
export type OrderPlacedV1 = {
schema: "order.placed.v1";
eventId: string; // UUID, for idempotent consumers
occurredAt: string; // ISO-8601
orderId: string;
customerId: string;
total: { amount: number; currency: string };
items: Array<{ sku: string; qty: number }>;
};The schema field is the cheapest versioning you can buy. When you need a v2, you publish it alongside v1 for a deprecation window, and consumers migrate on their own schedule. Skipping this and just adding fields to an unversioned event is fine until the day it isn't.
At-least-once is the default, design for it
Here is the single most important thing to internalize about messaging: most brokers deliver at-least-once. That means your consumer will, eventually, see the same message twice. Network blips, consumer crashes between processing and ack, broker rebalances, retry loops, all of them produce duplicates. This is not a bug; it's the cost of durability.
The implication: every consumer must be idempotent. Processing the same message twice must produce the same result as processing it once.
The standard pattern is an idempotency key stored in the database, checked atomically with the work:
import { db } from "@/db";
export async function handleOrderPlaced(event: OrderPlacedV1) {
await db.tx(async (t) => {
const inserted = await t.processedEvents.insertIgnore({
eventId: event.eventId,
handler: "payments.handleOrderPlaced",
processedAt: new Date(),
});
if (!inserted) return; // already processed, ack and move on
await t.payments.createPending({
orderId: event.orderId,
amount: event.total.amount,
currency: event.total.currency,
});
await t.outbox.append({
type: "payment.pending.v1",
eventId: crypto.randomUUID(),
payload: { orderId: event.orderId },
});
});
}Three things to notice. First, the processedEvents insert is conditional (insertIgnore, a unique constraint on eventId + handler). If the row already exists, we silently bail. Second, the actual work and the dedup row are in the same database transaction, so they commit or roll back together. Third, the outbox: we're publishing a new event by inserting into an outbox table in the same transaction, not by calling the broker. More on that next.
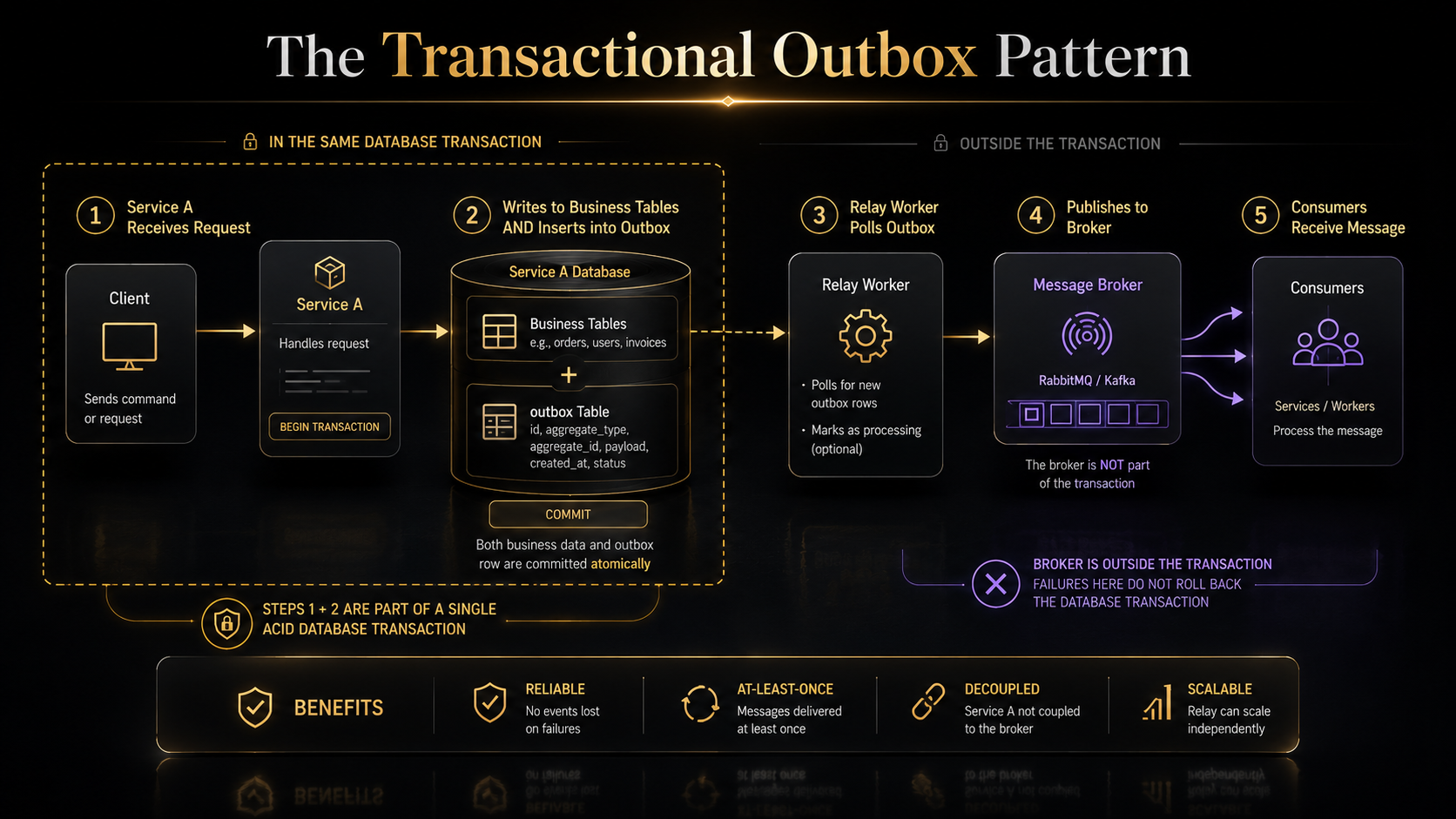
The outbox pattern
You have a problem: a handler needs to update the database and publish a message. If you write to the DB first, then publish, and the process dies in between, the DB has the new state but no message went out. If you publish first then write, you might publish and then fail the DB write. Either way, you've lost atomicity.
The outbox pattern fixes this. Instead of publishing directly, the handler inserts the message into an outbox table in the same transaction as the DB write. A separate process (a worker or a Debezium-style CDC pipeline) reads the outbox and publishes to the broker, marking rows as sent.
The guarantee: the message is in the outbox if and only if the business state was committed. There's no window where one happened without the other. The worker can be at-least-once; downstream consumers are already idempotent (you built them that way three sections ago), so duplicates are fine.
export async function relay(broker: Broker, db: DB) {
while (true) {
const batch = await db.outbox.fetchUnsent({ limit: 100 });
if (batch.length === 0) {
await sleep(250);
continue;
}
for (const row of batch) {
try {
await broker.publish(row.type, row.payload, { messageId: row.eventId });
await db.outbox.markSent(row.id);
} catch (err) {
await db.outbox.bumpAttempt(row.id, err.message);
// exponential backoff handled by next fetchUnsent ordering
}
}
}
}This is one of the patterns where the cost of not using it is a 4am incident where the customer charged card never reflected in the order system. Build it from day one.
Retries, backoff, and the dead-letter queue
Things will fail. The downstream service will be slow, the database will deadlock, a third-party API will rate-limit you. Your retry strategy is one of the most important things you'll design, and most teams get it wrong in the same ways:
Mistake one: tight loops. Retry immediately, three times, exit. Under load, this turns a 200ms hiccup into a thundering herd that knocks the downstream over for good.
Mistake two: no jitter. Exponential backoff without jitter means every client retries at exactly the same intervals. When a service comes back up, all clients hit it simultaneously at t = 1s, 2s, 4s, 8s. Same outage, different shape.
Mistake three: retrying things that can't be retried. A 400 Bad Request is not going to start working because you tried again. Retry transient errors (timeouts, 5xx, 429); don't retry permanent ones.
Mistake four: retrying forever. Some messages are poison. They will never succeed. If you keep retrying, you block the queue behind them.
The standard playbook:
- Categorize the error. Transient (retry) vs. permanent (don't). Network timeouts and 5xx are transient. 4xx (except 408 and 429) are permanent.
- Exponential backoff with full jitter. Wait
random(0, base * 2^attempt), capped at some maximum. The randomness prevents thundering herds. - Cap retry attempts, typically 5-10 depending on the operation's tolerance for delay.
- After the cap, send the message to a dead-letter queue (DLQ) for human inspection. Don't drop it, don't keep retrying, park it.
export async function withRetry<T>(
fn: () => Promise<T>,
opts: { maxAttempts: number; baseMs: number; capMs: number }
): Promise<T> {
let attempt = 0;
while (true) {
try {
return await fn();
} catch (err) {
attempt++;
if (!isTransient(err) || attempt >= opts.maxAttempts) throw err;
const exp = Math.min(opts.capMs, opts.baseMs * 2 ** (attempt - 1));
const wait = Math.floor(Math.random() * exp); // full jitter
await sleep(wait);
}
}
}For consumers, the DLQ is the safety valve. A typical RabbitMQ setup uses a x-dead-letter-exchange argument on the work queue, routing failed messages (after N nacks or a TTL) to a DLQ where they sit until someone looks at them. In Kafka, you publish to a parallel *.dlq topic. Either way, alert on DLQ depth, a non-empty DLQ usually means a bug, not a transient issue.
Circuit breakers and bulkheads
Two patterns from the Hystrix / "Release It!" school that earn their keep:
Circuit breaker. Wrap calls to a downstream service in a breaker that tracks failure rate. When it crosses a threshold (say, 50% of the last 20 calls failing), the breaker opens, subsequent calls fail immediately without even attempting the network call, for some cooldown period. Then it half-opens, lets a probe through, and either closes (success) or reopens (failure). This prevents you from hammering a dying service and gives it room to recover. In Node, libraries like opossum handle this well.
Bulkhead. Limit the number of concurrent operations against any one downstream so that if it goes slow, it can't soak up all your resources. If your service has 100 worker connections and the search service starts taking 30 seconds per call, an unbounded pattern lets all 100 connections pile up waiting on search, and now nothing else works. A bulkhead caps "max in-flight calls to search" at, say, 10, after that, calls fail fast instead of queueing.
The combination is what keeps a single bad downstream from cascading into a total outage. The circuit breaker says "stop trying for a bit"; the bulkhead says "even when you are trying, don't let it eat everything."
Sagas: distributed transactions without distributed transactions
You can't BEGIN; ... COMMIT; across services. So how do you do "place an order" that spans payment, inventory, and shipping, where any of them can fail?
The answer is a saga: a sequence of local transactions, each with a compensating action that undoes it. Two flavors:
Orchestration saga. A central orchestrator (often the service that "owns" the workflow) calls each step in turn and decides what to do next. Easier to reason about, easier to debug, has a clear place to live (one service).
Choreography saga. No central coordinator; each service reacts to events from the others. More decoupled, but harder to understand because the workflow is implicit in the event chain.
For "place an order," an orchestration saga might look like:
- Orchestrator:
CreateOrder(local, in orders DB, statuspending). - Call
payments.charge. On failure → compensateCancelOrder. - Call
inventory.reserve. On failure → compensateRefundPayment+CancelOrder. - Call
shipping.schedule. On failure → compensateReleaseInventory+RefundPayment+CancelOrder. - Mark order
confirmed.
The compensations are not transactional rollbacks, they're new actions that semantically undo the previous step. A "refund" is not "un-charge"; it's a separate transaction that produces the same business outcome.
Two ways teams blow this up:
- Forgetting that compensations can fail. Your refund call can fail. You need retries, idempotency, and ultimately a DLQ + manual intervention path for the rare cases where it can't be done.
- Trying to make the saga atomic. It isn't. There will be windows where the order is "pending" and the payment is "charged." Your UI, APIs, and downstream consumers need to handle that.
The trick is to think of every step as having three states: not started, in progress, done. The orchestrator's job is to drive forward until everything is done, or backward until everything is undone. Crash recovery means picking up wherever you left off, which is why the orchestrator's state has to be persisted, usually in its own database, often using an outbox to publish the next command.
Observability: traces, metrics, logs (in that order of usefulness)
In a monolith, when something is wrong, you read the stack trace and grep the log. In a microservice system, a single user action touches eight services and you have no idea which one tripped. Without observability, debugging is divination.
You need three pillars, and the order matters:
Distributed traces. A trace is the full story of a request as it moves through every service. Each hop is a span; spans nest into a tree. With traces you can see "this checkout took 4.2 seconds; 3.8 of those were waiting on the recommendations service." Without traces, you spend two hours on Slack saying "is it slow on your end?"
OpenTelemetry is the standard. It's a CNCF project that provides a vendor-neutral SDK and wire format (OTLP) for instrumenting code. You instrument once, and you can ship traces to Jaeger, Tempo, Honeycomb, Datadog, Lightstep, or whoever else, just by changing the exporter. The Node SDK auto-instruments most popular libraries (Express, Fastify, gRPC, pg, mysql2, ioredis, kafkajs, amqplib) with one import:
import { NodeSDK } from "@opentelemetry/sdk-node";
import { getNodeAutoInstrumentations } from "@opentelemetry/auto-instrumentations-node";
import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-grpc";
import { Resource } from "@opentelemetry/resources";
import { SemanticResourceAttributes } from "@opentelemetry/semantic-conventions";
export const sdk = new NodeSDK({
resource: new Resource({
[SemanticResourceAttributes.SERVICE_NAME]: process.env.SERVICE_NAME,
[SemanticResourceAttributes.SERVICE_VERSION]: process.env.SERVICE_VERSION,
[SemanticResourceAttributes.DEPLOYMENT_ENVIRONMENT]: process.env.ENV,
}),
traceExporter: new OTLPTraceExporter({ url: process.env.OTLP_ENDPOINT }),
instrumentations: [getNodeAutoInstrumentations()],
});
sdk.start();Crucially, the trace context (traceparent header) must propagate over your message broker too. The auto-instrumentations handle HTTP and gRPC for you. For Kafka/RabbitMQ, the OTel instrumentation injects the trace context into message headers, make sure your custom producer/consumer wrappers don't strip headers.
Metrics. Aggregates over time. RED for services (Rate, Errors, Duration) and USE for resources (Utilization, Saturation, Errors). Prometheus is the de-facto pull-based metrics system; prom-client is the Node library. Track at minimum, per service: request rate by route, error rate, p50/p95/p99 latency, event-loop lag, RSS memory, GC pauses, broker consumer lag, DB pool saturation. Most production incidents announce themselves in metrics 5-30 minutes before users notice.
Structured logs. Last because they're the most expensive per-unit-of-insight in a distributed system. Use a structured logger (pino is the canonical Node choice, it's fast enough that you can leave it on at info-level in production). Every log line includes trace_id, span_id, service, env, and the relevant business IDs (order_id, user_id). The trace ID is the join key, when you see a slow trace in your APM, you grep your log store by trace ID and get every log line from every service involved.
import pino from "pino";
import { trace, context } from "@opentelemetry/api";
export const logger = pino({
level: process.env.LOG_LEVEL ?? "info",
base: {
service: process.env.SERVICE_NAME,
env: process.env.ENV,
version: process.env.SERVICE_VERSION,
},
mixin() {
const span = trace.getSpan(context.active());
if (!span) return {};
const { traceId, spanId } = span.spanContext();
return { trace_id: traceId, span_id: spanId };
},
timestamp: pino.stdTimeFunctions.isoTime,
});The mixin makes every log line automatically carry the current trace context. You don't have to remember to add it; it's there for free.
One more thing: emit logs as JSON to stdout, and let the platform handle log shipping. Don't write to files inside the container. Don't ship logs from your app process to Elasticsearch directly. Stdout → container runtime → a sidecar or daemon (Fluent Bit, Vector, the cloud provider's agent) → your log store. This decoupling is what lets you change log destinations without redeploying every service.
Health checks: liveness, readiness, startup
Three different questions, often conflated:
- Liveness: is this process alive? If no, restart it. Should never depend on downstream services, if your DB is down, restarting your service does not fix it, and a liveness check that fails on DB outage will turn a database blip into a cluster-wide CrashLoopBackOff.
- Readiness: is this process ready to serve traffic right now? If no, take it out of the load balancer rotation but don't kill it. Can depend on critical downstreams (DB pool not exhausted, can reach the broker), but be careful, a strict readiness check during a transient blip can take your whole fleet out.
- Startup: has this process finished initializing? Only relevant for things that need a slow warmup (a large in-memory cache, a model loaded into worker threads). Kubernetes added this as a separate probe so liveness wouldn't kill slow-starting services prematurely.
A pattern that works: /healthz is a static 200 (liveness). /readyz checks DB ping, broker connection, and any critical downstream, returning 503 if any are unhealthy. /startup returns 200 only after init is complete.
Configuration, secrets, and the twelve-factor habits worth keeping
Most of "the twelve-factor app" is dated, but a few rules have aged well and they matter doubly in microservices:
- Config in the environment, not in code. Every service reads
process.env.SOMETHINGfor anything that varies between environments. Noif (env === 'production')branches in business logic. - Strict separation of build and run. The artifact you build (a container image, a tarball) is identical across dev, staging, and prod. Only configuration changes between them.
- Stateless processes. No in-memory session storage. No "this replica owns this customer." Any replica can serve any request, which is what makes horizontal scaling actually work.
Secrets get their own treatment. Don't bake them into images. Don't put them in env vars committed to git. Use a secrets manager (Vault, AWS Secrets Manager, Doppler, Kubernetes secrets backed by an external provider) and load them at process start, with rotation in mind.
import { z } from "zod";
const Schema = z.object({
NODE_ENV: z.enum(["development", "staging", "production"]),
SERVICE_NAME: z.string(),
PORT: z.coerce.number().int().positive(),
DATABASE_URL: z.string().url(),
BROKER_URL: z.string().url(),
OTLP_ENDPOINT: z.string().url(),
LOG_LEVEL: z.enum(["trace", "debug", "info", "warn", "error"]).default("info"),
});
const parsed = Schema.safeParse(process.env);
if (!parsed.success) {
console.error("Invalid configuration", parsed.error.flatten().fieldErrors);
process.exit(1);
}
export const config = parsed.data;Failing at boot with a clear message beats failing at request time with a cryptic stack trace. Every service should validate its config on startup and refuse to run if anything is missing or malformed.
Deployment: containers, Kubernetes, and the boring parts that matter
Almost every Node microservice these days ships as a Docker container deployed to Kubernetes. Some things to actually get right:
Build a small image. Use a multi-stage build, install only production dependencies in the final stage, run as a non-root user, and use a minimal base image. The official node:20-alpine is small and fine for most workloads; if you have native deps that don't build on Alpine, node:20-slim (Debian-based) is a reasonable next step.
# syntax=docker/dockerfile:1
FROM node:20-alpine AS build
WORKDIR /app
COPY package.json package-lock.json ./
RUN npm ci
COPY . .
RUN npm run build
FROM node:20-alpine AS runtime
WORKDIR /app
ENV NODE_ENV=production
COPY package.json package-lock.json ./
RUN npm ci --omit=dev && npm cache clean --force
COPY --from=build /app/dist ./dist
USER node
EXPOSE 3000
CMD ["node", "dist/index.js"]Handle SIGTERM gracefully. Kubernetes sends SIGTERM to your container when it wants the pod to stop, then waits terminationGracePeriodSeconds (default 30s) before SIGKILL. Your service should: stop accepting new requests, finish in-flight ones, drain consumer queues (stop fetching, finish what you have), close DB and broker connections, then exit. Without this, every rolling deploy and node drain produces a handful of failed requests.
import { app } from "./app";
import { consumer } from "./consumer";
import { logger } from "@/shared/logger";
const server = app.listen(config.PORT, () => {
logger.info({ port: config.PORT }, "listening");
});
async function shutdown(signal: string) {
logger.info({ signal }, "shutdown started");
server.close(); // stop accepting new requests
await consumer.disconnect(); // stop fetching new messages
// give in-flight handlers a moment to finish
await new Promise((r) => setTimeout(r, 5_000));
await closeAllConnections();
logger.info("shutdown complete");
process.exit(0);
}
process.on("SIGTERM", () => shutdown("SIGTERM"));
process.on("SIGINT", () => shutdown("SIGINT"));Set resource requests and limits. Requests are what the scheduler reserves; limits are the hard cap. For Node, set --max-old-space-size lower than your memory limit (e.g., 75% of it) so V8 GCs aggressively before the kernel OOM-kills you. Without this, you'll see pods get killed with no warning and no useful log line. Just gone.
Use rolling updates, but think about it. The default RollingUpdate strategy with maxSurge: 25%, maxUnavailable: 25% works for most services. For stateful or capacity-sensitive ones (consumers with partition assignment, services at high utilization), tune it. For services where versioning across replicas during a rollout is unsafe (rare, usually due to shared resources), consider blue/green or canary.
Pick a deployment strategy per service, not per company. Some services can ship 10x a day with full rolling deploys; some need canary releases with metric-based promotion; some need blue/green for fast rollback. The right answer depends on blast radius and confidence in your tests. Tools like Argo Rollouts and Flagger automate canary/blue-green on top of Kubernetes.

Service-to-service auth and the network you can't trust
Inside a Kubernetes cluster, by default, any pod can talk to any other pod on any port. That is a lot of implicit trust. Three layers that actually move the needle:
- NetworkPolicy. Kubernetes-native firewall rules. Default-deny ingress in every namespace, then allow specific service-to-service paths explicitly. The first time you do this is annoying; after that, you sleep better.
- mTLS for service-to-service. Every pod has a workload identity and a short-lived cert, and every connection is authenticated and encrypted at the transport layer. The two common ways to get this: a service mesh (Istio, Linkerd) that gives you mTLS for free at the sidecar level, or SPIFFE/SPIRE if you want it without the mesh. The mesh route is heavier but adds a lot of other nice things (traffic shifting, retries, timeouts, observability) you'd otherwise have to build per-service.
- Workload identity, not API keys. A service should authenticate to AWS, GCP, or Azure via cloud-native workload identity (IRSA on EKS, Workload Identity on GKE), not via long-lived access keys stored in env vars. Short-lived, automatically rotated, scoped per service.
The threat model for microservices isn't "an attacker is on the public internet." It's "an attacker is already inside one pod", a compromised dependency, a vulnerable endpoint, a misconfigured ingress. Defense in depth at the network layer is what limits the blast radius when that happens.
A few things I'd push back on
Not every "best practice" deserves the name. A handful of patterns that get repeated and aren't always right:
API gateway as a single entry point. Good for cross-cutting concerns (auth, rate limiting, TLS termination) at the edge. Bad when it becomes a god service that knows about every backend's business logic. Keep gateways thin, auth, routing, basic shaping, and push business logic into the services that own it.
One database per service, always. Strong principle. But for related services in the same bounded context that always deploy together, a shared schema (different tables, but one DB instance) is sometimes the more honest design. The principle you're really protecting is "no service writes to another service's tables." A shared DB engine with strict table ownership isn't the worst sin.
Microservices everywhere. The cost of distributed systems is real. A team of five with one product is almost always better off with a modular monolith. Microservices are an organizational scaling solution as much as a technical one, they let independent teams ship independently. If you don't have multiple independent teams, you're paying for organizational scale you don't need.
Sync HTTP between services for everything. It's easy. It's also the path to a brittle, low-availability system. Every time you find yourself writing an HTTP call between services, ask: could this be an event? Often the answer is yes, and the system gets more resilient as a result.
What "ready for production" actually looks like
If you want a checklist of what makes a Node microservice production-worthy, here's the bar I'd use. Each item is non-negotiable and explains the failure mode it prevents:
- Strict config validation on boot. Prevents silent misconfiguration in prod.
- Structured JSON logs to stdout with trace IDs. Makes debugging across services possible.
- OpenTelemetry traces propagated through HTTP, gRPC, and messages. Makes "where is the latency" answerable.
- Prometheus metrics with RED + event-loop lag + GC + business KPIs. Catches problems before users do.
- Liveness, readiness, and (where needed) startup probes. Stops bad deploys from cascading.
- Graceful SIGTERM handling that drains both HTTP and consumers. Eliminates rolling-deploy errors.
- Idempotent consumers backed by an idempotency table. Survives at-least-once delivery.
- Outbox pattern for any handler that writes DB + publishes a message. Makes the dual-write problem disappear.
- Retry with exponential backoff + full jitter + capped attempts + DLQ. Survives transient failures without cascading.
- Circuit breaker and bulkhead on every external dependency. Prevents one bad downstream from taking everything down.
- Resource requests, limits, and
--max-old-space-sizeset conservatively. Prevents kernel OOM-kills mid-request. - NetworkPolicy default-deny, mTLS between services, workload identity for cloud APIs. Limits blast radius when one pod is compromised.
- Versioned message schemas with explicit
schemafield. Lets consumers migrate without coordination. - CI gate: unit tests, contract tests against the schemas this service exposes, and a smoke test that boots the service with mocked deps. Stops most regressions before they ship.
You don't need all of this on day one of every service. You need to know which ones you're skipping and why, and to fill them in before they bite you.
Microservices reward systems-thinking and punish casualness. The teams that do well with them aren't the ones with the cleanest service diagrams, they're the ones who treat every cross-service interaction as something that can go wrong, design for that explicitly, and instrument the system well enough that when it does go wrong, the answer is visible inside of a minute rather than an afternoon.
Build for the failure modes you can see. Stay curious about the ones you can't. And keep something to drink nearby, production systems are a long conversation, not a problem you solve once.





