Claude can generate tests very quickly. That sounds great — but fast test generation can also create useless test files. You know the kind: tests that only check mocks, tests that repeat implementation details, tests that pass even when behavior is broken, tests that assert the wrong thing, tests that cover happy paths but miss real risks, tests that make refactoring harder instead of safer.
So the goal is not "generate many tests." The goal is "generate tests that protect behavior" — and that distinction changes everything. Claude is useful for test generation when you give it the right strategy: explain current behavior, identify risks, find edge cases, write characterization tests, mock external systems carefully, and manually review the final tests. It should help you think like a test designer, not just fill a tests/ folder.
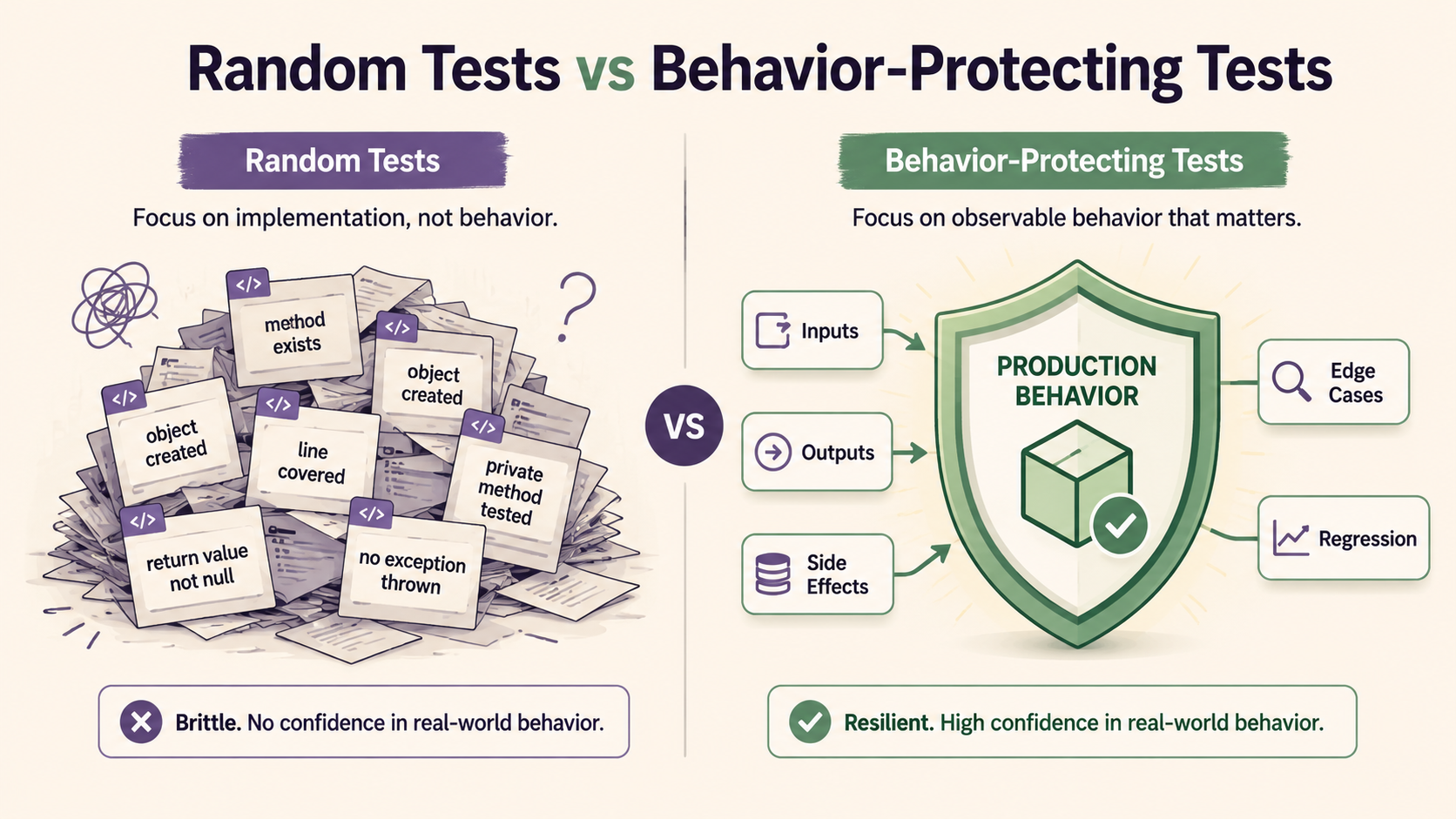
Random Tests Are Easy To Generate
Imagine this service:
final class DiscountService
{
public function calculate(User $user, Cart $cart): int
{
if ($user->is_vip && $cart->total > 10000) {
return 20;
}
if ($cart->coupon === 'WELCOME' && !$user->has_orders) {
return 15;
}
if ($cart->total > 5000) {
return 5;
}
return 0;
}
}A weak prompt is "generate tests for this class." Claude may come back with a few happy-path tests — okay, but not enough. A better prompt forces it to think about behavior first:
Generate behavior-protecting PHPUnit tests for this class.
First explain the business rules.
Then create tests for:
- VIP large cart discount,
- welcome coupon for first order,
- generic large cart discount,
- no discount,
- boundary values around 10000 and 5000,
- rule priority when multiple rules match.
Do not test private implementation details.
Use clear test names that describe behavior.Now the tests are much better:
public function testVipUserWithCartAboveTenThousandGetsTwentyPercentDiscount(): void
{
$service = new DiscountService();
$user = new User(is_vip: true, has_orders: true);
$cart = new Cart(total: 10001, coupon: null);
self::assertSame(20, $service->calculate($user, $cart));
}
public function testCartExactlyTenThousandDoesNotGetVipDiscount(): void
{
$service = new DiscountService();
$user = new User(is_vip: true, has_orders: true);
$cart = new Cart(total: 10000, coupon: null);
self::assertSame(5, $service->calculate($user, $cart));
}
public function testVipRuleHasPriorityOverWelcomeCoupon(): void
{
$service = new DiscountService();
$user = new User(is_vip: true, has_orders: false);
$cart = new Cart(total: 12000, coupon: 'WELCOME');
self::assertSame(20, $service->calculate($user, $cart));
}The boundary test (exactly 10000 doesn't trigger the VIP discount because the rule is > 10000) and the priority test (VIP rule wins over WELCOME) are exactly where Claude helps when prompted well — they're the cases a tired developer skips and a careful test designer adds.
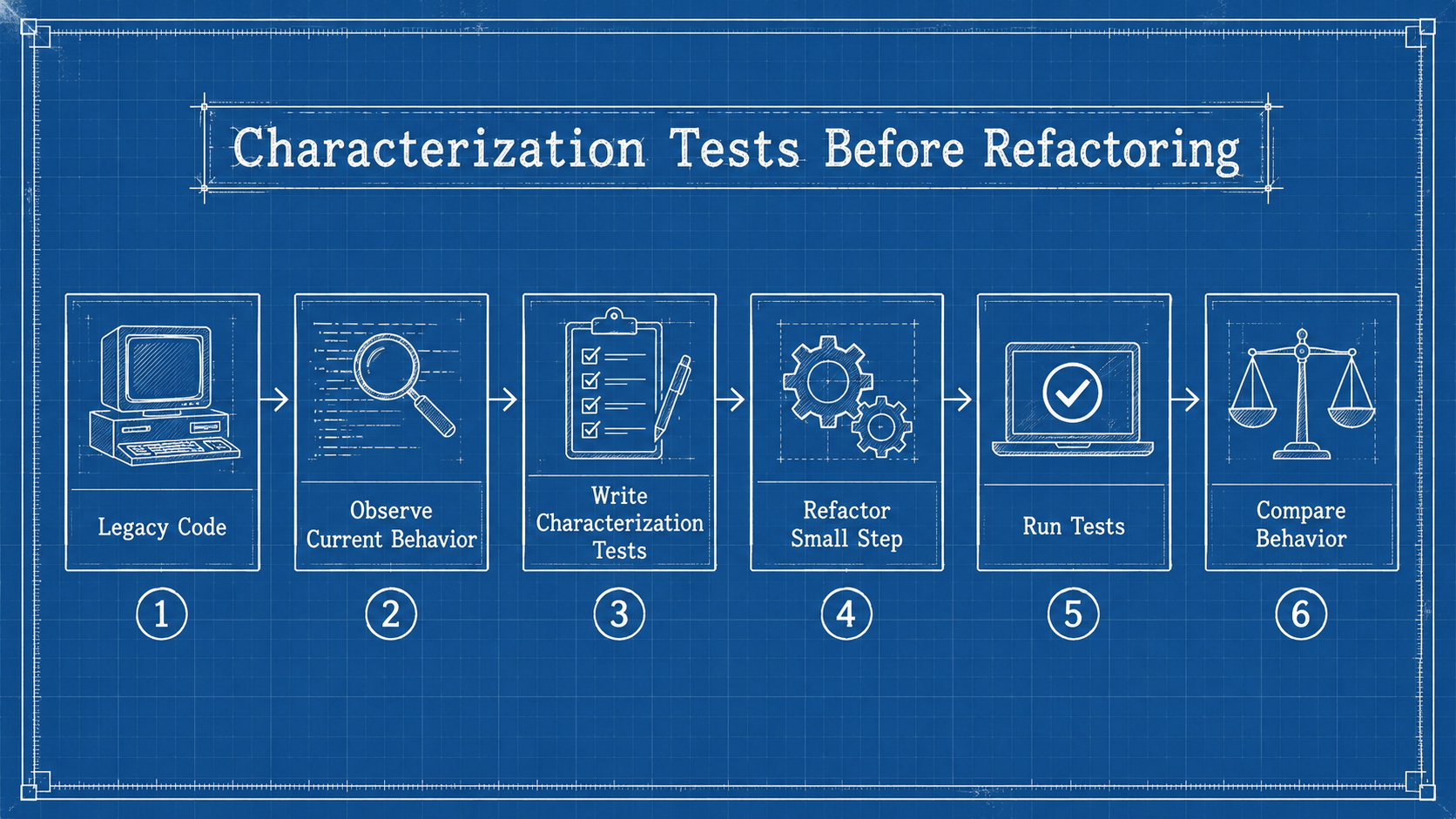
Characterization Tests For Legacy Code
Legacy code often has behavior nobody wants to explain out loud, and yet production depends on it. Before you refactor, you need characterization tests — tests that capture current behavior, even if that behavior is strange. Take this:
final class ShippingPriceCalculator
{
public function calculate(string $country, int $subtotal, bool $isVip): int
{
if ($country === 'US' && $subtotal > 5000) {
return 0;
}
if ($isVip) {
return 299;
}
if ($country === 'CA') {
return 799;
}
return 999;
}
}Before refactoring, ask:
Analyze this legacy method.
Do not refactor.
First:
- describe current behavior in plain English,
- identify rule priority,
- identify boundary values,
- identify surprising behavior,
- generate characterization tests that lock current behavior.Claude should notice that US free shipping is checked before VIP shipping — so a VIP user in the US with a high subtotal gets free shipping, not 299. It should also check that exactly 5000 doesn't qualify because the condition is > 5000, not >= 5000. That's an off-by-one that will absolutely matter the day someone "tidies up" the comparison:
public function testUsSubtotalExactlyFiveThousandDoesNotGetFreeShipping(): void
{
$calculator = new ShippingPriceCalculator();
self::assertSame(
999,
$calculator->calculate(country: 'US', subtotal: 5000, isVip: false),
);
}This kind of test protects behavior before cleanup — the refactor can run, and if it changes the off-by-one, the test fails loudly instead of quietly shipping a regression.
Ask Claude To Find Edge Cases
Developers often miss edge cases because they understand the happy path too well. Claude can help brainstorm them — it doesn't share your familiarity blindness.
Find edge cases for this function.
Consider:
- boundary values,
- null or empty input,
- invalid enum/status values,
- time zones,
- duplicate requests,
- retries,
- permission differences,
- external service failures,
- race conditions,
- large datasets.
Return only edge cases that are relevant to this code.
For each edge case, explain the expected behavior and test idea.For a payment retry service like this:
final class PaymentRetryService
{
public function shouldRetry(PaymentAttempt $attempt): bool
{
if ($attempt->status !== 'failed') {
return false;
}
if ($attempt->retry_count >= 3) {
return false;
}
if ($attempt->failed_at->diffInMinutes(now()) < 30) {
return false;
}
return true;
}
}The useful test set covers each rule's exit point and the boundary of the cooldown window:
public function testDoesNotRetrySuccessfulPayment(): void
{
$attempt = PaymentAttempt::factory()->make([
'status' => 'succeeded',
'retry_count' => 0,
'failed_at' => now()->subHour(),
]);
self::assertFalse($this->service->shouldRetry($attempt));
}
public function testDoesNotRetryWhenRetryLimitReached(): void
{
$attempt = PaymentAttempt::factory()->make([
'status' => 'failed',
'retry_count' => 3,
'failed_at' => now()->subHour(),
]);
self::assertFalse($this->service->shouldRetry($attempt));
}
public function testDoesNotRetryBeforeThirtyMinuteCooldown(): void
{
$attempt = PaymentAttempt::factory()->make([
'status' => 'failed',
'retry_count' => 1,
'failed_at' => now()->subMinutes(29),
]);
self::assertFalse($this->service->shouldRetry($attempt));
}
public function testRetriesAfterCooldownWhenLimitNotReached(): void
{
$attempt = PaymentAttempt::factory()->make([
'status' => 'failed',
'retry_count' => 1,
'failed_at' => now()->subMinutes(31),
]);
self::assertTrue($this->service->shouldRetry($attempt));
}This is exactly where AI is helpful — it lists the boring cases you might skip, and once they're on the page you can see what's worth keeping.
Test Data Generation
Claude can also help create good test data, but you need to push it past the obvious. "Create test data" gets you generic placeholder fixtures. Pinning the data to your real flow is what makes it useful:
Create realistic test data for this checkout flow.
Include:
- a normal paid order,
- a failed payment attempt,
- a user with no previous orders,
- a user with multiple subscriptions,
- an expired coupon,
- a high-value cart,
- edge cases around discount thresholds.
Use Laravel factories.
Keep data minimal.
Explain why each record exists.A typical output looks something like:
$user = User::factory()->create();
$product = Product::factory()->create([
'price' => 4999,
]);
$coupon = Coupon::factory()->create([
'code' => 'WELCOME',
'expires_at' => now()->addDay(),
'first_order_only' => true,
]);
$cart = Cart::factory()
->for($user)
->hasAttached($product, ['quantity' => 1])
->create([
'coupon_id' => $coupon->id,
]);Good test data should be small and intentional. Don't generate huge fixtures unless the test is specifically about performance or pagination — if you're not asserting against the size, the size is just noise.
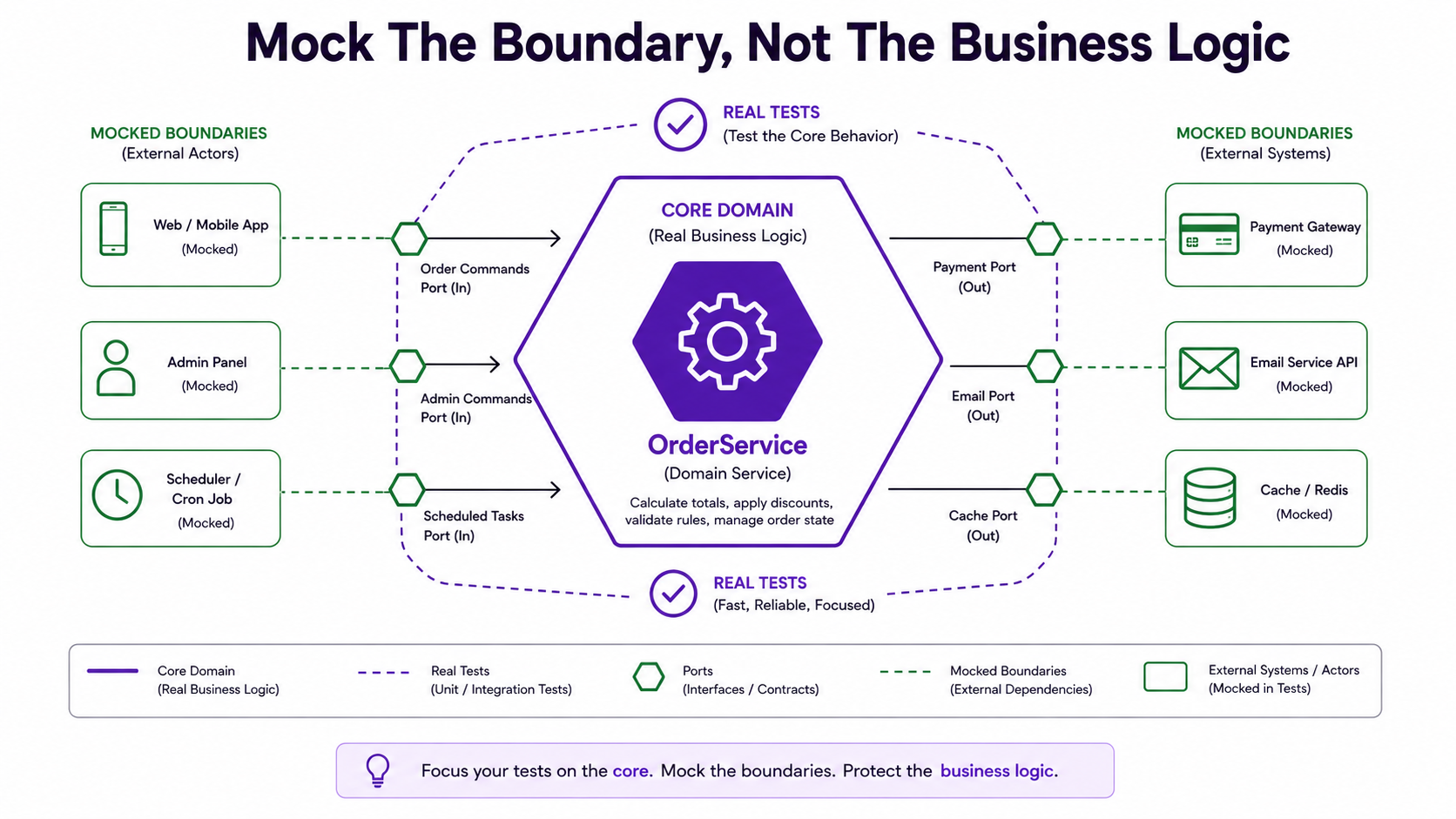
Mocking External Services
External services should usually be mocked in unit and feature tests, but be careful — if you mock too much, you test nothing. The line that works in practice: mock the boundary, leave the business logic real.
final class PaymentService
{
public function charge(Order $order): PaymentResult
{
$result = $this->gateway->charge(
customerId: $order->customer_gateway_id,
amount: $order->total,
idempotencyKey: "order:{$order->id}",
);
if (!$result->successful()) {
throw new PaymentFailedException($result->message());
}
$order->markAsPaid($result->transactionId());
return $result;
}
}A good prompt makes the boundary explicit:
Generate tests for this payment service.
Mock the external gateway only.
Do not mock the order behavior.
Verify:
- gateway receives correct amount,
- idempotency key is stable,
- successful payment marks order as paid,
- failed payment throws expected exception,
- failed payment does not mark order as paid.
Explain what is mocked and why.A good test that comes back from that prompt:
public function testSuccessfulChargeMarksOrderAsPaid(): void
{
$gateway = Mockery::mock(PaymentGateway::class);
$order = Order::factory()->create([
'total' => 4999,
'status' => 'pending',
]);
$gateway
->shouldReceive('charge')
->once()
->withArgs(function (string $customerId, int $amount, string $idempotencyKey) use ($order) {
return $amount === 4999
&& $idempotencyKey === "order:{$order->id}";
})
->andReturn(PaymentResult::success('txn_123'));
$service = new PaymentService($gateway);
$service->charge($order);
self::assertSame('paid', $order->refresh()->status);
self::assertSame('txn_123', $order->transaction_id);
}The mock is useful because you don't want to call the real gateway in a unit test. But the order behavior remains real — the assertion that the order is marked paid is the behavior you care about. That's the balance.
Ask Claude To Review Its Own Tests
After generating tests, don't accept them immediately — ask Claude to review them:
Review these generated tests critically.
Look for:
- tests that only test mocks,
- tests coupled to implementation details,
- missing assertions,
- missing negative cases,
- weak test names,
- unrealistic test data,
- duplicate coverage,
- behavior that is not actually protected.
Suggest improvements.This is surprisingly effective. AI-generated tests often look nice but assert too little — like this:
public function testServiceCallsGateway(): void
{
$gateway->shouldReceive('charge')->once();
$service->charge($order);
$this->assertTrue(true);
}That test is weak because it doesn't verify the important behavior — it asserts the gateway was called, but says nothing about what was passed in or what state changed afterward. The same intent, written better:
public function testServiceSendsStableIdempotencyKeyAndMarksOrderAsPaid(): void
{
// ...
}Test names should describe behavior. If the name doesn't read as a sentence about the system, the test probably isn't either.
Use Tests To Protect Refactoring
The best Claude testing workflow looks like this:
1. Explain current behavior.
2. Generate characterization tests.
3. Review and edit tests manually.
4. Run tests against current code.
5. Refactor in small steps.
6. Run tests again.
7. Add new tests for the new behavior if needed.Don't generate tests after the refactor only — generate them before. That's how tests become a safety net instead of a sandbag.
Practical Prompt Library
Save these. They're the four prompts that produce the most useful output across most codebases.
Behavior Test Prompt
Generate behavior-protecting tests for this code.
First explain the behavior in plain English.
Then write tests for:
- normal path,
- important edge cases,
- failure cases,
- authorization if relevant,
- side effects,
- response shape if HTTP,
- boundary values.
Do not test private implementation details.
Explain why each test exists.Characterization Test Prompt
This is legacy code.
Do not refactor.
Generate characterization tests that capture current behavior.
Focus on:
- current outputs,
- rule priority,
- side effects,
- exceptions,
- boundary values,
- surprising behavior.
Mark any behavior that looks strange but is currently part of the system.Mocking Prompt
Generate tests for this service.
Mock only external boundaries:
- payment gateways,
- HTTP APIs,
- email providers,
- queues if needed.
Do not mock domain logic.
Verify important state changes and side effects.
Explain each mock.Test Review Prompt
Review these tests.
Find:
- weak assertions,
- over-mocking,
- missing cases,
- implementation coupling,
- unrealistic data,
- duplicate tests,
- missing regression coverage.
Suggest specific improvements.Final Thoughts
Claude is very useful for test generation, but only when you give it the right job. Don't ask for "more tests" — ask for tests that protect behavior. Ask for characterization tests before refactoring, ask for edge cases, ask for realistic data, ask it to mock external systems carefully, and ask it to review the generated tests critically. Then you review everything yourself.
That's the right balance. AI can help you write tests faster, but your engineering judgment decides whether those tests actually matter.