Automated testing is one of the best places to use AI agents.
Not because an agent magically understands your business better than your team. It does not.
The real value is more practical: an agent can read a service, inspect existing tests, search for edge cases, generate test data, run the test suite, compare failures, and propose missing scenarios faster than most humans can do manually.
That makes AI useful for the boring but important parts of testing.
And honestly, that is where AI shines.
A good testing agent is not a replacement for engineering judgment. It is more like a very fast junior-to-mid-level assistant with endless patience. You still decide what behavior matters. You still review the tests. You still protect the architecture.
But the agent can help you move from this:
"We should add more tests someday."to this:
"Here are 18 missing scenarios, 6 edge cases, 3 current behavior risks, and a proposed test file that passes locally."That is a big difference.
In this article, we will build a practical mental model for using Claude agents for automated testing. The examples are written in a backend-friendly style, mostly PHP/Laravel flavored, but the same ideas apply to Node.js, Go, Python, Java, or almost any service codebase.
What Is A Testing Agent?
A testing agent is not just a prompt that says, "write tests."
That usually creates shallow tests.
A real testing agent has a job, context, constraints, and a repeatable workflow. It should know what kind of tests it is allowed to create, which commands it can run, what files it should inspect, and what it should avoid changing.
A simple definition:
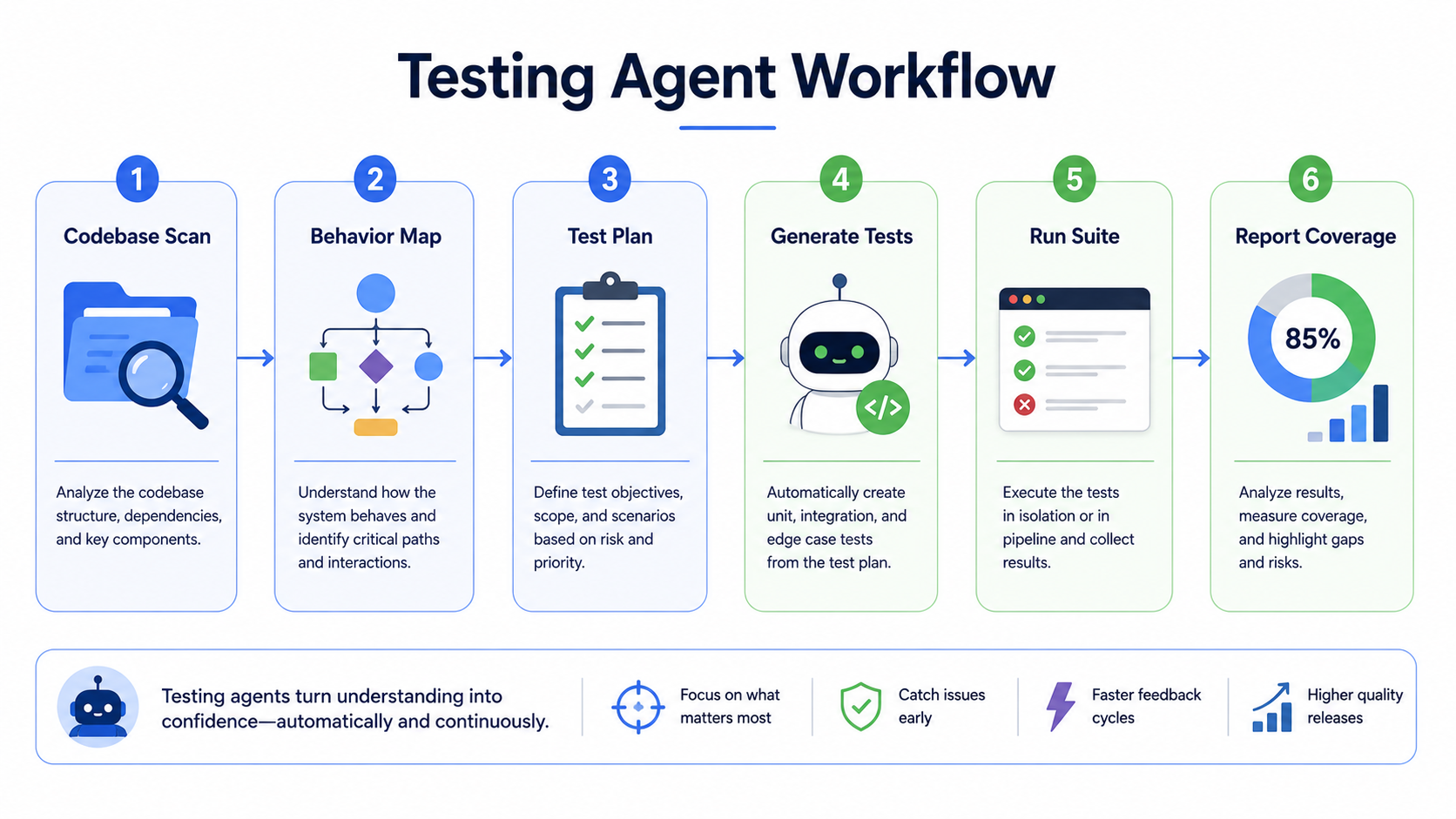
A testing agent is an AI workflow that analyzes code behavior, identifies risk, creates or updates tests, runs them, and reports what behavior is now protected.
That last part matters: reports what behavior is protected.
Tests are not valuable because they exist. Tests are valuable because they protect behavior you care about.
For example, this prompt is too weak:
Write tests for this service.This prompt is much better:
Analyze this service and create tests that protect the current behavior.
Do not refactor the implementation yet.
Focus on edge cases, validation rules, failed dependencies, and database state changes.
After writing tests, run the relevant test command and summarize what behavior is now covered.Now the agent has a mission.
It must analyze first. It must not refactor. It must focus on risk. It must run tests. It must explain coverage in human language.
That is much closer to how a senior engineer thinks.
Start With The Current Behavior, Not The Ideal Design
One of the biggest mistakes with AI-generated tests is asking for "good tests" before defining what "good" means.
In a mature codebase, especially a legacy one, the first goal is often not perfect design.
The first goal is safety.
Before you refactor, optimize, or rewrite, you need to know what the current code does. That is where characterization tests are useful.
A characterization test captures existing behavior, even if the behavior is weird.
Imagine this service:
final class DiscountService
{
public function calculateDiscount(User $user, Cart $cart): int
{
if ($cart->total() <= 0) {
return 0;
}
if ($user->isVip()) {
return 20;
}
if ($cart->total() > 500) {
return 10;
}
if ($user->createdAt()->diffInDays(now()) < 7) {
return 5;
}
return 0;
}
}At first glance, this looks simple.
But there are already business questions hiding inside it:
- What happens when a VIP user has an expensive cart?
- Should a new user with a $600 cart get 10% or 5%?
- Should zero-total carts always get no discount?
- Does the order of rules matter?
A testing agent can help discover these questions.
You can ask:
Analyze DiscountService and list the observable behaviors that should be protected before refactoring.
Do not suggest design changes yet.
Group the behaviors by rule priority and edge cases.A useful answer might produce something like:
Current observable behavior:
1. Cart total <= 0 always returns 0, even for VIP users.
2. VIP users receive 20 before expensive-cart logic is checked.
3. Non-VIP users with cart total > 500 receive 10.
4. New non-VIP users with cart total <= 500 receive 5.
5. Existing non-VIP users with cart total <= 500 receive 0.That list is testable.
Now you can ask the agent to create characterization tests:
Create PHPUnit tests for the observable behaviors listed above.
Use clear test method names.
Avoid mocks unless needed.
Do not change production code.Example result:
final class DiscountServiceTest extends TestCase
{
public function test_zero_total_cart_gets_no_discount_even_for_vip_user(): void
{
$user = UserFactory::vip()->make();
$cart = CartFactory::withTotal(0)->make();
$discount = (new DiscountService())->calculateDiscount($user, $cart);
$this->assertSame(0, $discount);
}
public function test_vip_user_gets_twenty_percent_before_expensive_cart_rule(): void
{
$user = UserFactory::vip()->make();
$cart = CartFactory::withTotal(1000)->make();
$discount = (new DiscountService())->calculateDiscount($user, $cart);
$this->assertSame(20, $discount);
}
public function test_non_vip_user_with_expensive_cart_gets_ten_percent(): void
{
$user = UserFactory::regular()->make();
$cart = CartFactory::withTotal(700)->make();
$discount = (new DiscountService())->calculateDiscount($user, $cart);
$this->assertSame(10, $discount);
}
}Are these tests perfect? Maybe not.
Are they useful before refactoring? Yes.
They freeze the current behavior so you can safely improve the internals later.
Use Separate Agent Roles For Better Results
One agent trying to do everything can become messy.
A better pattern is to split responsibilities.
For example:
Testing Strategist Agent
- Reads the service.
- Finds behavior and risk.
- Creates a test plan.
- Does not write test files.
Test Writer Agent
- Uses the approved test plan.
- Creates test code.
- Follows project conventions.
- Does not refactor production code.
Test Runner Agent
- Runs the relevant test command.
- Reports failures.
- Does not rewrite code unless asked.
Coverage Reviewer Agent
- Compares changed code with tests.
- Finds missing edge cases.
- Suggests next tests.This structure reduces chaos.
You do not want one agent to inspect code, invent requirements, rewrite the implementation, generate tests, and silently change your architecture in one pass. That is risky.
Use narrow roles.
Here is a practical testing strategist prompt:
You are a Testing Strategist Agent.
Goal:
Analyze the current service and produce a test plan.
Rules:
- Do not modify files.
- Do not propose refactoring yet.
- Focus on observable behavior.
- Identify edge cases and failure modes.
- Mark each test as unit, integration, regression, or characterization.
Output:
1. Behavior summary
2. Risky branches
3. Proposed test cases
4. Required fixtures or factories
5. Commands to run after tests are createdThen give the test plan to the test writer:
You are a Test Writer Agent.
Use the approved test plan below.
Create tests only.
Follow existing test style in this repository.
Do not change production code.
After writing tests, explain which files changed and why.This is much safer than a single giant prompt.
Unit Tests: Let The Agent Find Branches And Boundaries
Unit tests are great for pure logic, validation, formatting, small services, policy classes, and domain rules.
AI agents are helpful here because they can quickly map branches.
Consider this validation method:
final class PasswordPolicy
{
public function validate(string $password): array
{
$errors = [];
if (strlen($password) < 12) {
$errors[] = 'Password must be at least 12 characters.';
}
if (! preg_match('/[A-Z]/', $password)) {
$errors[] = 'Password must contain an uppercase letter.';
}
if (! preg_match('/[0-9]/', $password)) {
$errors[] = 'Password must contain a number.';
}
if (str_contains(strtolower($password), 'password')) {
$errors[] = 'Password must not contain the word password.';
}
return $errors;
}
}You can ask:
Create a compact PHPUnit test matrix for PasswordPolicy.
Cover minimum length, uppercase, number, forbidden word, valid password, and multiple errors in one password.
Use a data provider where it improves readability.A good generated test may look like this:
final class PasswordPolicyTest extends TestCase
{
/**
* @dataProvider passwordProvider
*/
public function test_it_validates_password_rules(string $password, array $expectedErrors): void
{
$errors = (new PasswordPolicy())->validate($password);
$this->assertSame($expectedErrors, $errors);
}
public static function passwordProvider(): array
{
return [
'valid password' => [
'SafePassword123',
[],
],
'too short' => [
'Short1',
['Password must be at least 12 characters.'],
],
'missing uppercase' => [
'safe-password-123',
['Password must contain an uppercase letter.'],
],
'missing number' => [
'SafePasswordText',
[
'Password must contain a number.',
'Password must not contain the word password.',
],
],
];
}
}The important part is not that the agent wrote code.
The important part is that it can quickly generate a test matrix.
Then you review it.
You may notice that SafePassword123 contains the word password, because the check lowercases the password. So that "valid password" test is actually wrong.
This is exactly why review matters.
The agent is useful, but not authoritative.
A better valid example would be:
'valid password' => [
'SecureToken123',
[],
],AI can speed you up, but you still own correctness.
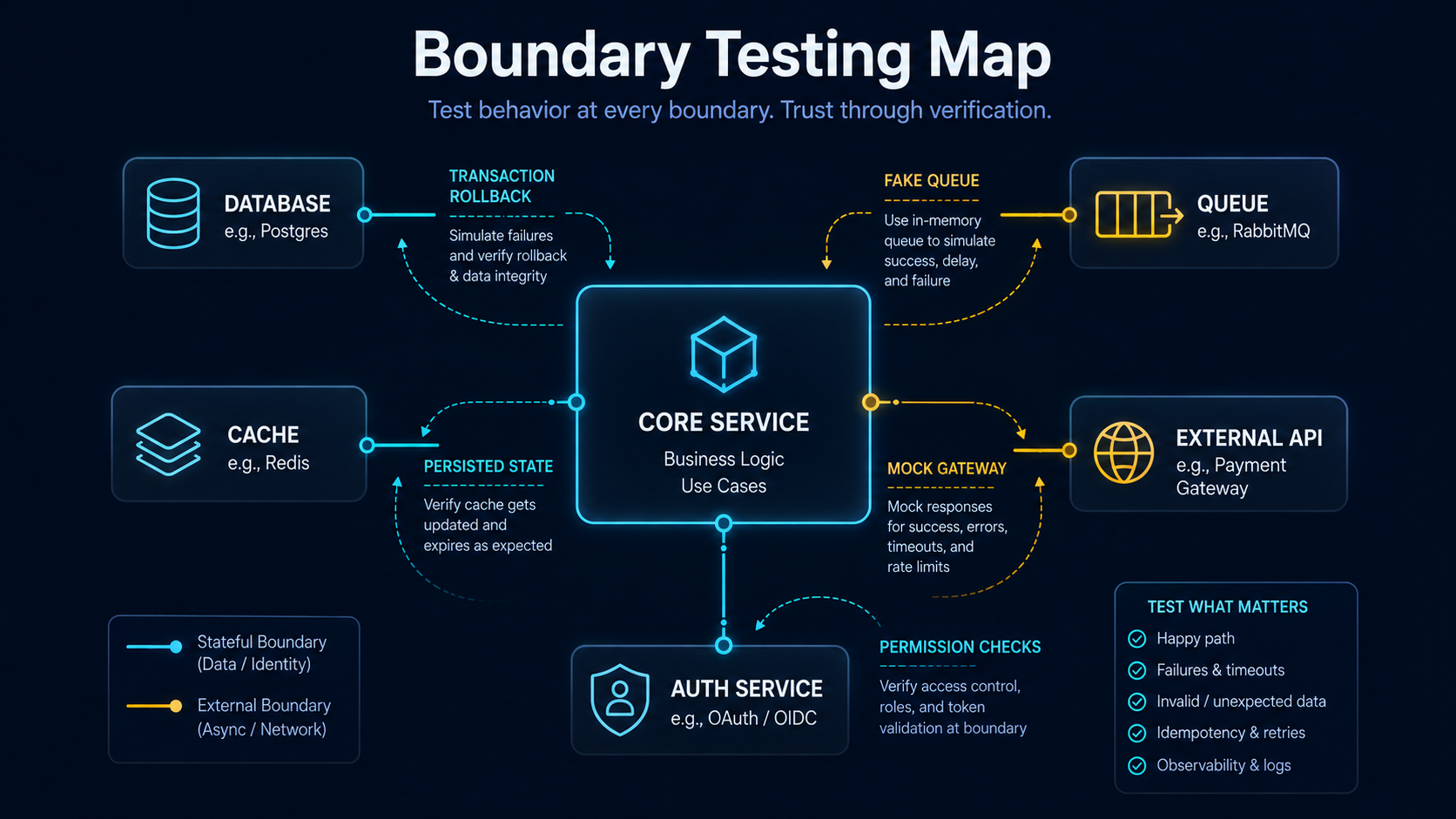
Integration Tests: Make The Agent Follow Real Boundaries
Unit tests are not enough.
Most production bugs happen at boundaries:
- database writes
- queues
- external APIs
- cache state
- authentication
- authorization
- transactions
- failed dependencies
- race conditions
Integration tests protect these boundaries.
Suppose you have a Laravel action that creates an order, charges payment, and dispatches a receipt job:
final class CreateOrderAction
{
public function __construct(
private PaymentGateway $payments,
private Dispatcher $events,
) {}
public function execute(User $user, Cart $cart): Order
{
return DB::transaction(function () use ($user, $cart) {
$order = Order::create([
'user_id' => $user->id,
'total' => $cart->total(),
'status' => 'pending',
]);
$charge = $this->payments->charge($user, $cart->total());
$order->update([
'status' => 'paid',
'payment_id' => $charge->id,
]);
SendReceiptJob::dispatch($order->id);
return $order;
});
}
}A weak prompt:
Write tests for CreateOrderAction.A strong prompt:
Analyze CreateOrderAction and create integration tests for database state, payment gateway success, payment gateway failure, transaction rollback, and receipt job dispatching.
Use Laravel testing helpers where appropriate.
Do not hit real external services.
Use fakes or mocks for payment and queues.Useful test cases:
public function test_it_creates_paid_order_and_dispatches_receipt(): void
{
Queue::fake();
$user = User::factory()->create();
$cart = CartFactory::withTotal(15000)->createForUser($user);
$paymentGateway = Mockery::mock(PaymentGateway::class);
$paymentGateway
->shouldReceive('charge')
->once()
->andReturn(new ChargeResult(id: 'ch_123'));
$order = (new CreateOrderAction($paymentGateway, app(Dispatcher::class)))
->execute($user, $cart);
$this->assertDatabaseHas('orders', [
'id' => $order->id,
'status' => 'paid',
'payment_id' => 'ch_123',
]);
Queue::assertPushed(SendReceiptJob::class, function (SendReceiptJob $job) use ($order) {
return $job->orderId === $order->id;
});
}Failure test:
public function test_it_rolls_back_order_when_payment_fails(): void
{
Queue::fake();
$user = User::factory()->create();
$cart = CartFactory::withTotal(15000)->createForUser($user);
$paymentGateway = Mockery::mock(PaymentGateway::class);
$paymentGateway
->shouldReceive('charge')
->once()
->andThrow(new PaymentFailedException('Card declined'));
$this->expectException(PaymentFailedException::class);
try {
(new CreateOrderAction($paymentGateway, app(Dispatcher::class)))
->execute($user, $cart);
} finally {
$this->assertDatabaseMissing('orders', [
'user_id' => $user->id,
'status' => 'pending',
]);
Queue::assertNothingPushed();
}
}This is where agents can help a lot.
They often find the missing "what if payment fails after the order is created?" test faster than a busy engineer scanning code late in the day.
Regression Tests: Turn Bugs Into Permanent Protection
A regression test is a test created because something broke before.
This is one of the most valuable uses for an AI testing agent.
When a bug report arrives, the agent can help you convert it into a test.
Example bug:
Users with expired subscriptions can still access premium videos if they refresh the page after midnight UTC.Agent prompt:
Create a regression test for this bug:
"Users with expired subscriptions can still access premium videos if they refresh the page after midnight UTC."
Steps:
1. Find the authorization logic for premium video access.
2. Identify how subscription expiration is checked.
3. Create a failing test that reproduces the bug.
4. Do not fix production code yet.
5. Explain why the test fails.This is powerful because it enforces the right order:
Bug report
↓
Failing regression test
↓
Production fix
↓
Passing test
↓
Protected behaviorDo not let the agent jump straight to the fix.
Make it write the failing test first.
That gives you evidence.
Test Data Generation: Useful, But Keep It Realistic
Agents are good at generating data combinations.
But random data is not automatically good data.
Good test data is intentional.
For example, for an address validation service, ask the agent for categories:
Create test data categories for an address validation service.
Include valid addresses, missing required fields, invalid postal codes, apartment numbers, international addresses, PO boxes, and provider timeout cases.
Do not invent provider-specific behavior unless it exists in the code or docs.Then convert categories into fixtures:
return [
'valid US address with apartment' => [
[
'line1' => '123 Main St',
'line2' => 'Apt 4B',
'city' => 'Minneapolis',
'state' => 'MN',
'postal_code' => '55401',
'country' => 'US',
],
true,
],
'missing postal code' => [
[
'line1' => '123 Main St',
'city' => 'Minneapolis',
'state' => 'MN',
'country' => 'US',
],
false,
],
];The agent can generate many cases quickly.
Your job is to remove unrealistic cases and add business-specific ones.
Edge Case Discovery: Ask For Weird Inputs
AI agents are useful for edge case brainstorming because they do not get bored.
For a price calculation service, ask:
Find edge cases for this price calculation service.
Focus on rounding, zero values, negative values, currency mismatch, discounts larger than subtotal, tax order, duplicate coupons, and integer overflow.
Return a prioritized list of test cases.For an API endpoint:
Find edge cases for this endpoint.
Focus on authentication, authorization, missing fields, malformed JSON, idempotency, duplicate requests, race conditions, pagination limits, and unexpected enum values.For a queue job:
Find edge cases for this queue job.
Focus on retries, duplicate execution, failed dependencies, partial database updates, idempotency, and poison messages.The trick is to name the risk categories.
Do not just say "find edge cases."
Tell the agent what kinds of edge cases matter.
Flaky Test Detection: Let The Agent Look For Patterns
Flaky tests are painful because they destroy trust.
AI agents can help by analyzing failure logs and spotting patterns:
Analyze these CI failures and identify possible flaky test causes.
Group by category: time dependency, shared database state, ordering dependency, external service dependency, random data, async race, or resource limits.
For each category, suggest a deterministic fix.Common flaky patterns:
Uses now() without freezing time.
Depends on test execution order.
Uses real network calls.
Waits with sleep(1) instead of polling with timeout.
Shares mutable global state.
Uses random data without fixed seed.
Assumes queue jobs finish immediately.Example fix for time:
public function test_trial_expires_after_seven_days(): void
{
Carbon::setTestNow('2026-05-03 10:00:00');
$user = User::factory()->create([
'trial_started_at' => now()->subDays(8),
]);
$this->assertTrue($user->trialExpired());
}A testing agent can scan for now(), sleep(), random factories, and external HTTP calls. It can suggest where tests may become flaky.
Again, review matters.
The agent may identify false positives. That is fine. It is still faster than manually scanning hundreds of tests.
Coverage Gap Analysis: Do Not Worship The Percentage
Coverage percentage can be useful, but it can also lie.
A project can have 85% coverage and still miss the most important failure path.
A better agent prompt:
Compare the changed production files with existing tests.
Find behavior that changed but is not directly covered by tests.
Ignore simple getters and framework boilerplate.
Prioritize payment, authorization, data deletion, queue dispatching, external API calls, and database writes.This is more useful than:
Increase coverage to 90%.You want risk-based coverage, not vanity coverage.
A useful report might look like:
Coverage gaps found:
High risk:
- Subscription cancellation now deletes scheduled renewal jobs, but no test asserts jobs are removed.
- Payment retry logic catches GatewayTimeoutException, but no test covers retry behavior.
Medium risk:
- User export now includes phone number, but API response test was not updated.
Low risk:
- New helper formats display name, simple branch not covered.That is actionable.

A Practical Agent Workflow For Pull Requests
Here is a workflow you can use in a real team:
Developer opens PR
↓
Testing Agent reads diff
↓
Agent identifies changed behavior
↓
Agent checks existing tests
↓
Agent suggests missing test cases
↓
Developer approves useful cases
↓
Agent writes tests
↓
CI runs
↓
Agent summarizes test protection in PR commentThe agent should not silently push huge changes.
Keep the human in the loop.
A good PR comment from the agent:
Testing summary:
Added:
- Regression test for failed payment retry after timeout.
- Integration test for order rollback when gateway throws exception.
- Unit test for discount priority between VIP and cart total rules.
Not covered:
- Concurrent duplicate checkout requests. This likely needs an idempotency test.
Commands run:
- php artisan test --filter=CreateOrderActionTest
- vendor/bin/phpunit tests/Unit/DiscountServiceTest.phpThat summary is useful for reviewers.
It explains why tests were added, not just that files changed.
Guardrails: What The Agent Must Not Do
Testing agents need strict boundaries.
Here are good rules:
Do not change production code unless explicitly asked.
Do not delete existing tests.
Do not weaken assertions to make tests pass.
Do not replace specific assertions with assertTrue(true)-style checks.
Do not mock the class under test.
Do not hide failures.
Do not update snapshots without explaining behavior changes.
Do not invent business requirements.That last one is important.
An agent can infer likely behavior, but it should label assumptions.
For example:
Assumption: expired subscriptions should not access premium videos.
Evidence: SubscriptionPolicy::canAccessPremium() checks expires_at.
Need confirmation: grace period behavior is not documented.That is a good agent response.
It separates evidence from assumption.
A Reusable Testing Agent Prompt
Here is a practical prompt you can reuse:
You are a senior testing agent working inside this repository.
Goal:
Create tests that protect current behavior and reduce regression risk.
Process:
1. Inspect the target code and nearby tests.
2. Summarize current observable behavior.
3. Identify risky branches, edge cases, and failure paths.
4. Propose a test plan before writing tests.
5. After approval, write tests only.
6. Run the smallest relevant test command.
7. Report what passed, what failed, and what behavior is protected.
Rules:
- Do not refactor production code.
- Do not change behavior to satisfy tests.
- Do not remove existing tests.
- Prefer clear assertions over broad snapshots.
- Use factories and fakes already used in this project.
- Label assumptions clearly.
Focus areas:
- Unit tests
- Integration tests
- Regression tests
- Characterization tests
- Test data generation
- Edge cases
- Flaky test risks
- Coverage gapsThis prompt is intentionally boring.
That is good.
Testing is not about dramatic AI demos. It is about repeatable protection.
Final Thoughts
Claude agents can be extremely useful for automated testing, but only when you treat them as structured engineering assistants.
Do not ask them to "write tests" and hope for the best.
Give them a role. Give them boundaries. Make them analyze before writing. Make them run tests. Make them explain what behavior is protected.
The best workflow is not AI instead of testing.
It is AI helping you test more carefully, more consistently, and earlier in the delivery process.
That is the real win.





