
So, you've shipped a Go service. Maybe two. Handlers feel clean, the package layout is sane, and go test ./... runs in under a second. Then the first real bug lands (a race in the cache, a transaction that doesn't roll back, a JSON field that quietly went missing), and you suddenly realize the test suite you've been adding to for a year doesn't tell you anything useful about whether the next deploy is safe.
That's the moment a lot of teams discover the difference between having tests and having a testing strategy. The Go ecosystem makes the first one easy. The second one is on you.
This piece is about the second one. We'll go through the layers that earn their keep in a backend Go service: unit tests, table-driven tests, integration tests, and the small set of compiler-and-runtime tools (-race, build tags, t.Cleanup, httptest, testcontainers) that actually keep the suite honest. By the end you should know what each layer is for, what each one shouldn't be doing, and how to draw the lines so that adding a test doesn't feel like a coin flip.
What "strategy" even means here
A backend service is a lot of code, and most of it isn't equally interesting from a testing point of view. Some of it is pure logic: validators, mappers, parsers, business rules. Some of it is glue: HTTP handlers, database queries, queue consumers. Some of it is integration with the outside world: third-party APIs, message brokers, S3, Stripe.
The mistake teams make is testing all of that at the same altitude. You either end up unit-testing your HTTP handlers with so many mocks that the test is basically a copy of the implementation, or you spin up a Postgres container for every check, and a full run takes ten minutes.
A real strategy says: each layer of the code has a layer of tests that matches it. Pure logic gets fast, in-memory tests. Boundary code (handlers, repositories) gets tests that exercise the boundary on real wires. The full system gets a few, deliberate end-to-end checks, not a hundred, not zero.
That's the spine. Everything below is the muscle.
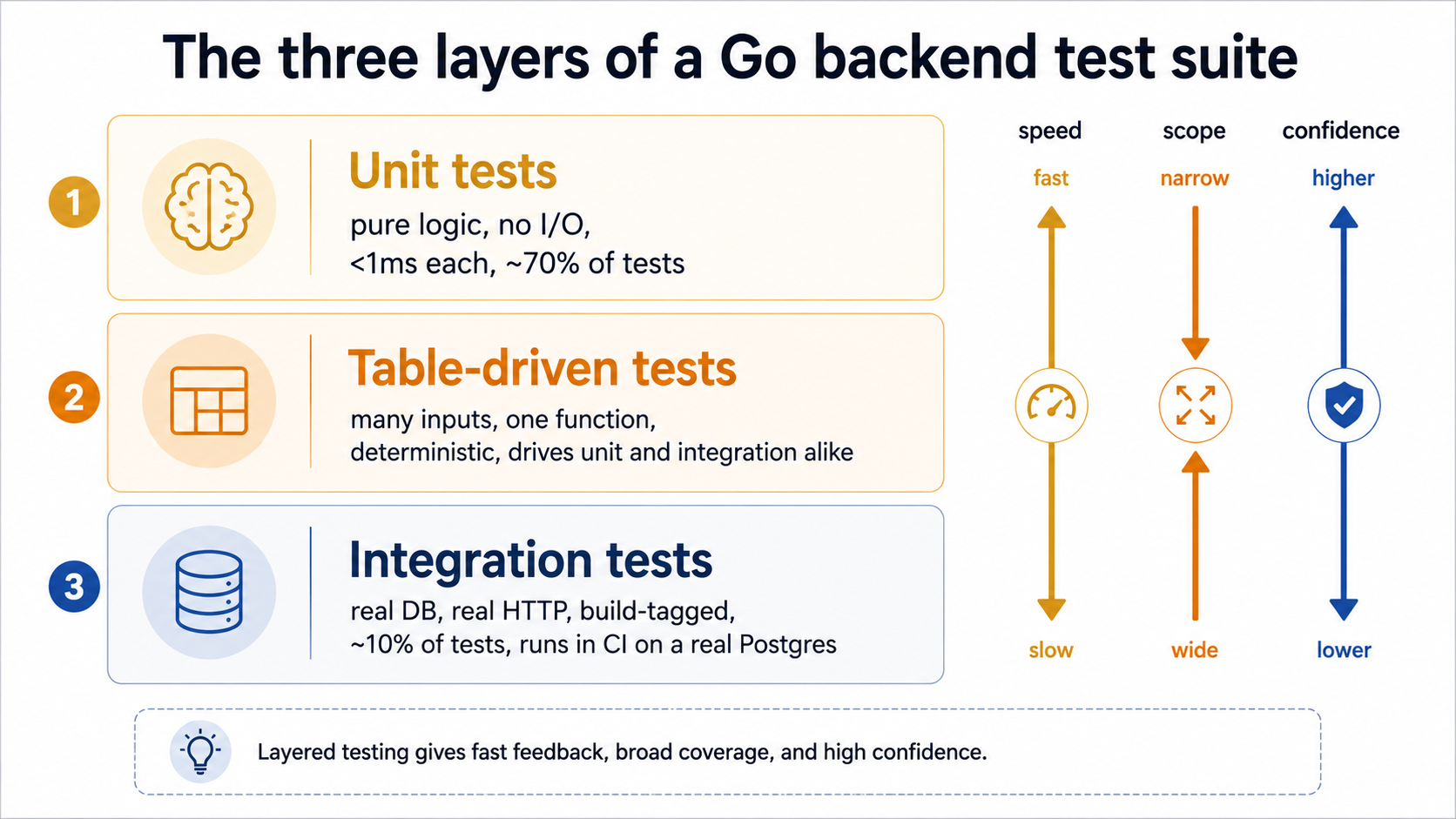
Layer 1: Unit tests, small, fast, almost boring
The unit test is the cheapest test you can write. It calls one function with one set of inputs, asserts one or two things about the output, and finishes in microseconds. Nothing on disk, nothing on the network, no goroutine that outlives the test.
In a backend service, the natural home for unit tests is anywhere the code is pure logic. Validators. Mappers between DTOs and domain types. Pricing or scoring rules. Permission checks that take a user and a resource and return a boolean. Things that don't care about the database or the network.
Here's a tiny example. A function that decides whether an order qualifies for free shipping:
package pricing
import "errors"
type Order struct {
Subtotal int // cents
Country string // ISO 3166-1 alpha-2
Membership string // "none" | "plus" | "prime"
}
var ErrInvalidCountry = errors.New("country code required")
func QualifiesForFreeShipping(o Order) (bool, error) {
if o.Country == "" {
return false, ErrInvalidCountry
}
if o.Membership == "prime" {
return true, nil
}
if o.Country == "US" && o.Subtotal >= 5000 {
return true, nil
}
if o.Country != "US" && o.Subtotal >= 7500 {
return true, nil
}
return false, nil
}A first cut of the test is honest, but a little wasteful:
package pricing
import "testing"
func TestQualifiesForFreeShipping_PrimeAlwaysQualifies(t *testing.T) {
ok, err := QualifiesForFreeShipping(Order{
Subtotal: 100,
Country: "DE",
Membership: "prime",
})
if err != nil {
t.Fatalf("unexpected error: %v", err)
}
if !ok {
t.Fatal("expected prime member to qualify")
}
}That's a unit test. One function in, one function out, no fixtures, no setup. It will pass or fail for one reason. If it fails, the failure points at the function under test, not at the orchestration around it.
A few small habits make these unit tests pay off:
- External test package when you can. Put the test file in
package pricing_test(notpackage pricing) when you only want to use the public API. It enforces the boundary you'd want anyway, and stops you accidentally testing private state that a caller can't reach. Usepackage pricing(the internal one) only when you need to reach a private helper. t.Helper()in helpers. If you write aassertNoError(t, err)helper, the first line of its body should bet.Helper(). Otherwise failures will point at the helper, not at the call site, and you'll lose half a minute every time hunting the real line.t.Cleanupoverdefer. When a test allocates a resource (a temp file, a mock server), register the teardown witht.Cleanup(...). It runs even whent.Fatalaborts the test mid-way, and the test reads top-to-bottom without a tail ofdefers.t.TempDir()overos.MkdirTemp. The directory is created for the test and removed by the runner. No leftover litter in/tmp, no leaked state between runs.
Unit tests aren't glamorous. They don't catch architecture bugs. But they're the layer where you can move fastest, and the layer where flaky behavior is the most embarrassing, because there's nothing for the flake to hide behind.
Layer 2: Table-driven tests, Go's actually-killer feature
The first time you write three near-identical unit tests with different inputs, the next move is obvious: collapse them into a table. Almost every mature Go codebase you'll touch uses this pattern, and once you're used to it, going back to one-test-per-case feels like writing assembly.
Same shipping rule, table-driven:
package pricing
import (
"errors"
"testing"
)
func TestQualifiesForFreeShipping(t *testing.T) {
cases := []struct {
name string
order Order
want bool
wantErr error
}{
{
name: "prime member qualifies regardless of total",
order: Order{Subtotal: 100, Country: "DE", Membership: "prime"},
want: true,
},
{
name: "US order above 50 dollars qualifies",
order: Order{Subtotal: 6000, Country: "US", Membership: "none"},
want: true,
},
{
name: "US order below 50 dollars does not",
order: Order{Subtotal: 4999, Country: "US", Membership: "none"},
want: false,
},
{
name: "international order needs 75 dollars",
order: Order{Subtotal: 7500, Country: "DE", Membership: "none"},
want: true,
},
{
name: "missing country is an error",
order: Order{Subtotal: 9999, Country: "", Membership: "plus"},
wantErr: ErrInvalidCountry,
},
}
for _, tc := range cases {
tc := tc // capture for parallel
t.Run(tc.name, func(t *testing.T) {
t.Parallel()
got, err := QualifiesForFreeShipping(tc.order)
if tc.wantErr != nil {
if !errors.Is(err, tc.wantErr) {
t.Fatalf("err: got %v, want %v", err, tc.wantErr)
}
return
}
if err != nil {
t.Fatalf("unexpected error: %v", err)
}
if got != tc.want {
t.Fatalf("got %v, want %v", got, tc.want)
}
})
}
}A few things to notice, because they're the difference between a table-driven test that helps and one that hurts:
The name field has a sentence in it, not a slug. When this fails in CI you want the failure line to say TestQualifiesForFreeShipping/US_order_below_50_dollars_does_not and have that be self-explanatory. Cryptic case names ("case_3", "edge_a") are a code smell. If you can't name the case, you don't know what it's testing.
The tc := tc line right before t.Run is the table-driven test's most famous footgun. Without it, every goroutine sees the last value of tc, because the loop variable was being shared. As of Go 1.22 the loop-variable scoping rules changed so this is no longer required for for ... range over a slice. But a lot of code still runs on older versions or with the older semantics, and the explicit capture costs nothing. (If your go.mod is go 1.22 or newer, you can drop it.)
t.Parallel() inside t.Run is what makes table-driven tests fast. Twenty test cases that each call a pure function will run in parallel and finish in roughly the time of the slowest one. Don't add t.Parallel() to cases that share mutable state, but for pure-function tables, it should be reflex.
The wantErr field uses a sentinel, not a string. Comparing errors by errors.Is is much more robust than err.Error() == "expected message", which breaks the first time you wrap the error with fmt.Errorf("%w", ...) in production code.
When not to table-drive
The trap with table-driven tests is reaching for them every time. They shine when many cases exercise the same shape of input and output. They become a mess when:
- Cases need very different setup (one needs a DB, one doesn't).
- Cases assert on very different things.
- The struct grows to fifteen fields, half of them only used by two cases.
If you find yourself adding optional fields to the case struct and writing if tc.somethingSpecial { ... } branches inside the loop, the table is fighting you. Break the odd cases out into their own functions. A test file with one table and three separate cases is fine; it's nearly always better than a table with branches.
Layer 3: Mocks, fakes, and the interface at the boundary
Backend code constantly interacts with things outside the process: a database, an HTTP client, a queue, a clock. The question that decides whether your test suite is pleasant or miserable is how you stand those collaborators in for tests.
In Go, the idiomatic move is to keep the interface narrow and define it at the consumer side, not at the dependency side. That is, your OrderService doesn't import the gigantic *sql.DB API; it imports an OrderRepo interface that only has the three methods the service actually uses:
package orders
import "context"
type Repo interface {
Find(ctx context.Context, id string) (Order, error)
Save(ctx context.Context, o Order) error
MarkPaid(ctx context.Context, id string) error
}
type Clock interface {
Now() time.Time
}
type Service struct {
repo Repo
clock Clock
}Two payoffs. First, the service is trivially testable: pass in any implementation of Repo and Clock. Second, the shape of the dependency is documented right where it's used, so a new reader doesn't have to guess which of the 90 methods on *sql.DB the service actually calls.
For the tests, you've got three options.
A hand-rolled fake is a struct that implements the interface with in-memory state:
type fakeRepo struct {
orders map[string]Order
saved []Order
}
func (f *fakeRepo) Find(_ context.Context, id string) (Order, error) {
o, ok := f.orders[id]
if !ok {
return Order{}, ErrNotFound
}
return o, nil
}
func (f *fakeRepo) Save(_ context.Context, o Order) error {
if f.orders == nil {
f.orders = map[string]Order{}
}
f.orders[o.ID] = o
f.saved = append(f.saved, o)
return nil
}
func (f *fakeRepo) MarkPaid(_ context.Context, id string) error {
o := f.orders[id]
o.Status = "paid"
f.orders[id] = o
return nil
}A stub is a fake with a single canned response, often a function field for the method you care about:
type stubRepo struct {
FindFn func(ctx context.Context, id string) (Order, error)
Repo // embed to satisfy the rest by panicking
}
func (s stubRepo) Find(ctx context.Context, id string) (Order, error) {
return s.FindFn(ctx, id)
}A generated mock uses a tool like mockgen or mockery to spit out a struct from the interface, with built-in expectation tracking. It's powerful but it's also where I see test suites go off the rails. Once you start writing mockRepo.EXPECT().Find(gomock.Any()).Return(...).Times(2), you've stopped testing behavior and started testing call sequences. That makes the test rigid to the implementation in a way that costs you every refactor.
A rough rule that has held up well for me: fakes for state, stubs for one-shot answers, mocks only when you really need to assert the call sequence (e.g., "did the service call Publish exactly once, even on retry?"). If a hand-rolled fake costs you fifty lines of test-helper code and runs forever, that's still cheaper than a thousand-line generated mock file in your repo that no human reads.
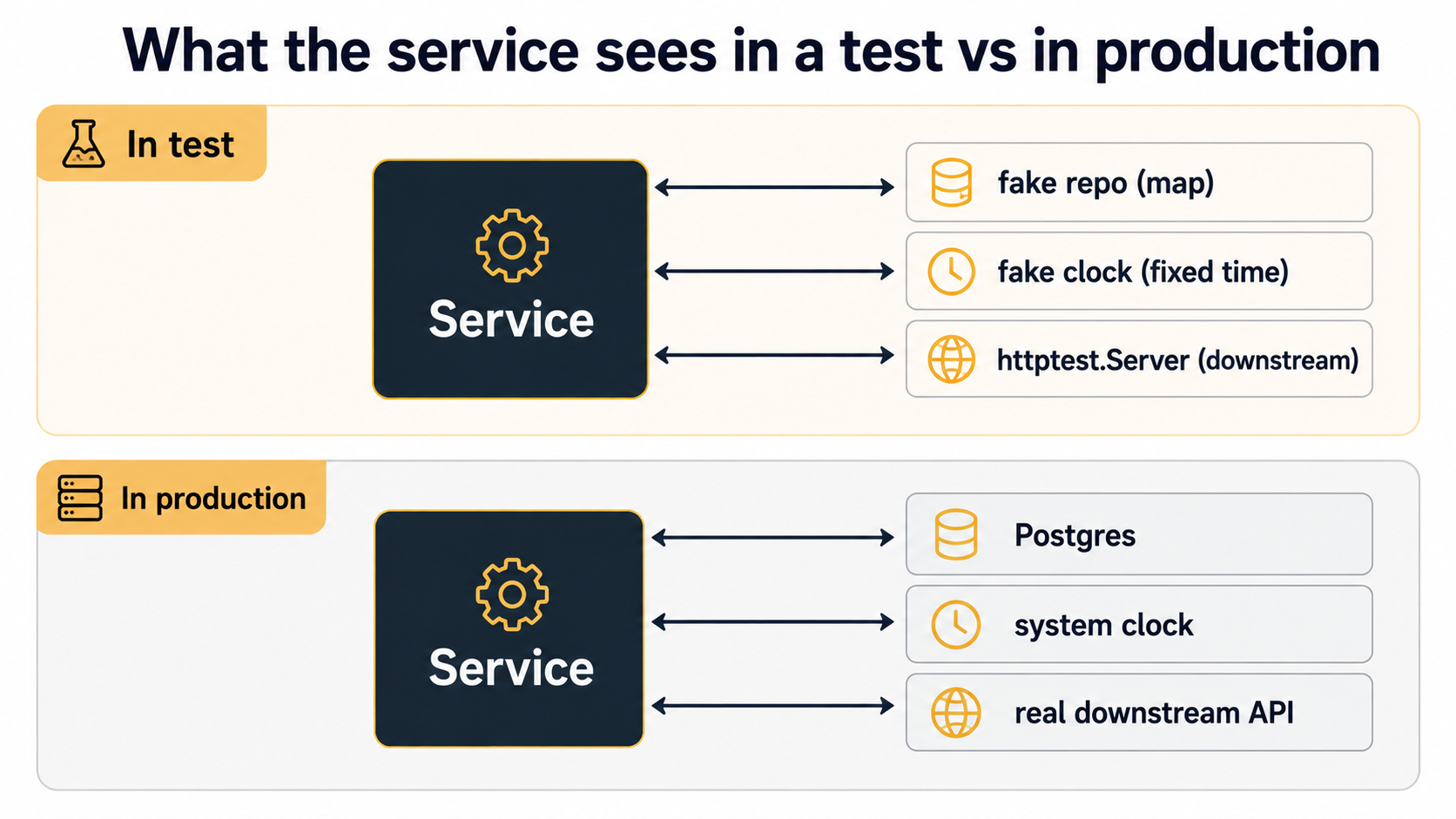
A note on the clock
Clock deserves its own line because it's the most common bug source I see and the easiest to fix. Any code that does "if more than 24 hours have passed" or "schedule for next Monday" needs an injectable clock, not time.Now() called directly inside the function. In tests, the fake clock returns a fixed time, and you assert that the code behaves correctly across the boundary. In production, the real clock returns time.Now(). Same shape, swappable end.
Layer 4: Integration tests, real wires, real signals
At some point you have to test the code that touches the database, because no in-memory fake will catch the bugs that live in the SQL itself. A missing index that turns a 50ms query into a 5s query. A NULL constraint that the schema enforces but your domain model doesn't. A transaction that doesn't roll back the way you expected. None of those will show up in a fake.
This is what integration tests are for. The contract is:
- The test runs against a real Postgres / MySQL / Redis / whatever your production uses, ideally the same major version.
- The schema is the real schema, applied via your normal migration tool, not a hand-edited
CREATE TABLEin the test file. - The test cleans up after itself, so the order of tests doesn't matter and parallel runs don't collide.
The Go ecosystem has a few good ways to get there.
testcontainers-go
testcontainers-go starts a real container per test run (or per package) and gives you the connection string. It's the most realistic option and the one I reach for first these days:
//go:build integration
package store
import (
"context"
"database/sql"
"testing"
"time"
_ "github.com/jackc/pgx/v5/stdlib"
"github.com/testcontainers/testcontainers-go"
"github.com/testcontainers/testcontainers-go/modules/postgres"
"github.com/testcontainers/testcontainers-go/wait"
)
func startPostgres(t *testing.T) *sql.DB {
t.Helper()
ctx := context.Background()
pg, err := postgres.Run(ctx,
"postgres:16-alpine",
postgres.WithDatabase("test"),
postgres.WithUsername("test"),
postgres.WithPassword("test"),
testcontainers.WithWaitStrategy(
wait.ForLog("database system is ready to accept connections").
WithOccurrence(2).
WithStartupTimeout(60*time.Second),
),
)
if err != nil {
t.Fatalf("start postgres: %v", err)
}
t.Cleanup(func() {
_ = pg.Terminate(ctx)
})
dsn, err := pg.ConnectionString(ctx, "sslmode=disable")
if err != nil {
t.Fatalf("dsn: %v", err)
}
db, err := sql.Open("pgx", dsn)
if err != nil {
t.Fatalf("open db: %v", err)
}
if err := applyMigrations(db); err != nil {
t.Fatalf("migrate: %v", err)
}
return db
}Two notes on that snippet. The file has a //go:build integration build tag, which means go test ./... won't run it. You opt into the integration suite with go test -tags=integration ./.... That separation matters: nobody wants go test ./... to spin up containers when they're iterating on a validator.
The wait strategy isn't optional. Postgres logs "database system is ready" twice during startup (once for initdb, once for the real boot), and waiting for the second occurrence is what stops the test from connecting against a half-started server. This is exactly the kind of detail you'd never figure out from inside the test until it flaked in CI three times.
The "shared container, per-test transaction" pattern
Starting a container per test is correct but slow. A common optimization is one shared container per package, with each test running inside a transaction that gets rolled back at the end:
//go:build integration
package store
import (
"context"
"testing"
)
var sharedDB *sql.DB
func TestMain(m *testing.M) {
sharedDB = mustStartPostgresForPackage()
code := m.Run()
sharedDB.Close()
os.Exit(code)
}
func TestOrderRepo_SaveAndFind(t *testing.T) {
ctx := context.Background()
tx, err := sharedDB.BeginTx(ctx, nil)
if err != nil {
t.Fatal(err)
}
t.Cleanup(func() { _ = tx.Rollback() })
repo := NewOrderRepoFromTx(tx)
if err := repo.Save(ctx, Order{ID: "o-1", Total: 9900}); err != nil {
t.Fatalf("save: %v", err)
}
got, err := repo.Find(ctx, "o-1")
if err != nil {
t.Fatalf("find: %v", err)
}
if got.Total != 9900 {
t.Fatalf("total: got %d, want 9900", got.Total)
}
}The trick is that tx.Rollback() undoes every insert, update, delete the test did, even on failure, because t.Cleanup runs on t.Fatal. Tests don't see each other's data, you don't have to truncate tables between runs, and the whole suite runs against one container.
Two caveats. The repo has to accept something that looks like a DB-or-Tx, which usually means an interface that both *sql.DB and *sql.Tx satisfy. And you can't test code that itself opens transactions this way, because a nested transaction in Postgres becomes a savepoint, which behaves slightly differently. For those cases, fall back to per-test container or per-test truncate.
HTTP handlers with httptest
Handlers get tested with net/http/httptest, which gives you a real *http.Request and a real *httptest.ResponseRecorder, with no mocking of the framework and no spinning up a port.
package api
import (
"encoding/json"
"net/http"
"net/http/httptest"
"strings"
"testing"
)
func TestCreateOrderHandler_RejectsEmptyBody(t *testing.T) {
h := NewOrderHandler(newFakeService())
req := httptest.NewRequest(http.MethodPost, "/orders", strings.NewReader(""))
req.Header.Set("Content-Type", "application/json")
rec := httptest.NewRecorder()
h.ServeHTTP(rec, req)
if rec.Code != http.StatusBadRequest {
t.Fatalf("status: got %d, want %d", rec.Code, http.StatusBadRequest)
}
var body struct {
Error string `json:"error"`
}
if err := json.NewDecoder(rec.Body).Decode(&body); err != nil {
t.Fatalf("decode response: %v", err)
}
if body.Error == "" {
t.Fatal("expected error message in response body")
}
}This is the sweet spot for handler-level tests. You're exercising the routing, the decoding, the response shape, and the status code (the entire HTTP-shaped layer), without any of the brittleness of a real network. The service underneath is a fake. The slow bits (DB, downstream APIs) are not in this test.
When you want to test that your service correctly calls an external HTTP API, you flip it around: httptest.NewServer gives you a real server you can point your client at, with a handler that asserts the request it receives:
func TestStripeClient_SendsAmount(t *testing.T) {
var seen struct {
amount int
}
srv := httptest.NewServer(http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
_ = json.NewDecoder(r.Body).Decode(&seen)
_, _ = w.Write([]byte(`{"id":"ch_test"}`))
}))
t.Cleanup(srv.Close)
client := NewStripeClient(srv.URL, "test-key")
if _, err := client.Charge(context.Background(), 9900); err != nil {
t.Fatal(err)
}
if seen.amount != 9900 {
t.Fatalf("got amount %d, want 9900", seen.amount)
}
}That test gives you real confidence that the HTTP serialization is correct, without ever touching the real Stripe.
Layer 5: End-to-end tests, fewest, most deliberate
End-to-end tests run the whole service the way a client would. Spin up the binary (or the docker-compose), seed any required state, hit it over HTTP from the outside, assert what the system did.
The temptation is to write a lot of them, because they feel the most realistic. The trap is that they're the slowest, the flakiest, and the ones that fail for unrelated reasons most often. A good e2e suite for a backend service is dozens of tests, not hundreds, covering the few flows that absolutely cannot regress (sign-up, payment, the one critical workflow your business runs on) and not trying to catch every edge case.
If a bug can be caught at the unit or integration layer, catch it there. E2e is the place where you prove the seams between layers fit, not the place where you exercise individual permutations.
A small but important habit: keep e2e tests in their own package and build-tagged separately (//go:build e2e). You don't want them in the default go test ./... run, and you probably want them in a different CI stage with its own timeout budget.
The flags you'll actually use
The Go test runner has a lot of flags. Most you'll never touch. A handful matter every day.
-race is the one that matters most. It instruments your binary with a race detector and reports any concurrent unsynchronized access to memory. The performance hit is real (tests can be 2-10x slower), so you don't always run it locally, but your CI must run go test -race ./... on every PR. Goroutine bugs are nearly impossible to track down in production; the race detector finds them while you still have the diff open. (Treat any new race detector warning as a P0. They don't false-positive often, and when they do, the cause is usually still worth knowing about.)
-count=1 disables test caching. Useful when you've changed something outside the Go module (env var, file in testdata/) and the runner is reporting cached results. Don't normalize running with -count=1 always; the cache is doing real work for you.
-short lets a test opt out of slow paths with if testing.Short() { t.Skip(...) }. Useful for table-driven tests that have one massive fuzz-like case mixed in with a hundred fast ones. You can go test -short ./... for iterating, and the full thing in CI.
-run filters which tests run by regex. go test -run 'TestQualifies.*/prime' ./pkg/pricing is how you re-run a single sub-test while you're debugging. You don't need to comment out the rest of the table.
-parallel N controls the cap on concurrent parallel tests in a single binary; the default is GOMAXPROCS. Worth knowing exists. Almost never worth changing.
-cover and -coverprofile=cover.out give you coverage. Useful diagnostically, dangerous as a target. A line being "covered" by a test that doesn't actually assert anything about it is a number, not a signal. By all means look at the coverage report when you suspect a section is undertested; don't gate merges on a magic percentage.
Fuzz testing (go test -fuzz, added in Go 1.18) is a separate animal worth knowing about. Any function that takes structured-but-untrusted input (a parser, a deserializer, a validator) is a candidate. You write a func FuzzMyParser(f *testing.F), give it a few seed inputs with f.Add(...), and call f.Fuzz(func(t *testing.T, input []byte) { ... }) with an invariant check. The runner mutates the seeds and looks for ones that panic or break the invariant. It's not a layer of its own (you don't run it on every commit), but for any code that parses bytes you don't control, an hour of fuzzing on a Friday will pay you back at some point.
What good test code looks like in a PR
I've reviewed a lot of Go tests over the years, and the difference between a test suite that helps and one that gets in the way often comes down to a few habits.
Name tests by behavior, not by function. TestQualifiesForFreeShipping_PrimeAlwaysQualifies is better than TestQualifies_3. When a CI failure surfaces, the test name is the headline.
Assert one or two specific things, not the whole world. A test that checks "the response equals exactly this 50-field struct" will fail every time anyone touches the response shape, even when the test's actual concern (status code, the one field you care about) is still correct. Use targeted assertions. if got.Status != "paid" beats if !reflect.DeepEqual(got, wholeThing).
Don't test what the framework already tests. A test that asserts chi.Mux actually routes /orders/{id} to your handler is testing chi, not your code. Spend the budget on the actual logic.
Resist the urge to share fixtures across packages. A testutil package that lives in your repo and offers helpers is great. A testfixtures.LoadGoldenOrder() that loads a complex JSON blob multiple unrelated tests depend on is a slow-burning footgun. The day someone changes the fixture for their test, eight other tests start failing in unrelated places.
t.Helper() in every helper. Mentioned before, worth repeating. The failure should point at your test, not at the helper.
Make tests deterministic. No time.Now() inside the assertion. No math/rand without a fixed seed. No iterating over map[...]X and asserting on order. Tests that pass 99 out of 100 times are not actually passing.
Prefer stdlib testing with light helpers over heavy assertion libraries. Testify is fine, and require.NoError(t, err) reads nicely. But the Go test you write today is going to be read by someone in three years who's never used testify. The lower-dependency you stay, the more durable your test suite is. And the stdlib testing package is good: t.Run, t.Helper, t.Cleanup, t.TempDir, t.Setenv, t.Parallel together cover almost everything most teams need.
Putting the layers together
You don't pick one of these layers for your service. You use all of them, deliberately, at the altitude they're cheapest. For a typical backend:
- Pure logic: unit tests, lots of them, table-driven, run in milliseconds, run on every save.
- Service-layer code with fake dependencies: unit-ish tests, table-driven where the inputs are uniform, broken into individual tests when they aren't.
- Repository code that touches the database: integration tests, build-tagged, against a real Postgres in a container, transaction-rolled-back where possible.
- HTTP handlers:
httptest-based tests with a fake service underneath; they exercise the HTTP boundary without involving the DB. - HTTP clients to other services:
httptest.NewServer-based, asserting on what you sent, returning what the real service would. - The two or three workflows that absolutely cannot regress: end-to-end, run in a slower CI stage, kept few.
That's the shape. The flag toolbox (-race always, -short sometimes, -cover diagnostically, fuzz for parser-shaped code) sits on top of the whole thing. The dependency seams (interfaces at the consumer, narrow, swappable) are what make the layers cleanly testable in the first place. If you find yourself unable to test some piece of code without dragging in half the world, the problem is almost always the seam, not the test. Go fix the interface and the test gets easy.
Get those layers right, and go test ./... stops being a chore and starts being the thing that tells you, in under a minute, whether the deploy is safe.





