
Why I Am Writing This: A PHP Developer Crossing Into Go
I am a PHP developer.
I have shipped Laravel and Symfony services in production, debugged messy Eloquent queries at 2am, traced N+1 problems through real traffic, and lived inside enough service containers to know exactly how a framework feels when it grows up with your career.
I always intended to learn Go.
For years, "I'll seriously learn Go someday" sat on my list next to Rust, Elixir, and a dozen side projects. Someday kept getting pushed out by client work and PHP refactors that paid the rent.
Then someday arrived, and it was not a romantic story. It was an economic one.
PHP is the cheap stack. PHP developers are everywhere, the hosting is cheap, hiring is fast, the ecosystem is gigantic, the contracts are abundant. For many businesses, PHP is the obvious choice because it lets them ship CRUD-heavy web apps quickly without spending FAANG-level budgets.
Go is a different story. Go engineers are scarce and expensive. The companies hiring senior Go developers are usually doing infrastructure work, high-throughput backends, internal platforms, devtools, fintech, or anything where a single binary handling 10k requests per second matters more than developer headcount. Salaries reflect that gap.
So now I do both.
PHP pays the bills and ships features for clients who do not need the JVM or a static binary. Go is where I push my technical ceiling, work on systems that scale differently, and access a market where the dollars-per-hour curve bends upward. The two stacks coexist on my machine, and they coexist in my career.
If that situation sounds familiar — if you are a senior PHP developer who finally decided to take Go seriously, whether for the salary, for the systems work, or just for the engineering joy of it — this article is for you.
You are not starting from zero.
That is the most important thing to understand before learning Go.
If you are already a senior PHP, Laravel, Symfony, or backend developer, you already know the hard parts of backend engineering. You know how business rules become messy. You know why database indexes matter. You know how production bugs hide in small assumptions. You know that queues, retries, logs, caching, deployments, and observability are not "extra topics". They are the real job.
So your goal is not simply to memorize Go syntax.
Your real goal is to understand how Go wants you to build software.
That is a different thing.
PHP often feels framework-first. You start with Laravel or Symfony, and the framework gives you a request lifecycle, routing, dependency injection, validation, queues, configuration, migrations, commands, testing helpers, and a huge mental model around the application.
Go feels different.
Go asks you to write explicit code. It gives you a strong standard library, a simple type system, compiled binaries, small interfaces, composition, fast tooling, and concurrency primitives. But it does not hide as much behind a framework. You see more of the system directly.
That can feel strange at first.
It can also be very refreshing.
The fastest way to learn Go as a senior backend developer is not to learn every corner of the language specification first. The fastest way is to connect what you already know about production backend systems with Go's mental model.
Let's walk through that path.
The Mental Map: PHP vs Go
Before we go deeper, here is the single mental map that helped me most. Keep it nearby — every time something feels foreign in Go, this is usually why.
| PHP / Laravel world | Go world |
|---|---|
| Framework owns the lifecycle | You own main() |
| Service container resolves deps | Constructors wire deps explicitly |
| Exceptions bubble up | Errors are values |
| Magic methods, ORM, facades | Standard library + small packages |
| FPM process per request | One long-running binary |
Internalize that table and the rest of the article makes more sense.
Learn The Syntax, But Do Not Stay There Too Long
You need syntax, of course.
There is no way around it.
You should learn variables, constants, functions, structs, methods, slices, maps, pointers, packages, error handling, interfaces, goroutines, and channels. These are the basic building blocks of Go programs.
But syntax is not the hard part.
If you already know PHP, JavaScript, TypeScript, or another backend language, you can understand basic Go syntax quickly. The danger is spending too much time watching beginner tutorials while avoiding real code.
A simple Go function looks like this:
package main
import "fmt"
func CalculateDiscount(amount int) int {
if amount >= 500 {
return 50
}
if amount >= 100 {
return 10
}
return 0
}
func main() {
fmt.Println(CalculateDiscount(150))
}Nothing magical here.
The function accepts an int, returns an int, and uses simple control flow. If you come from PHP, this is easy to read.
A small but important detail: the capital C in CalculateDiscount is not a style choice. In Go, identifiers that start with an uppercase letter are exported (visible from other packages). Lowercase identifiers are package-private. There is no public or private keyword — visibility is encoded in the name itself. This is one of the first surprises for PHP developers.
Now compare that with something slightly more Go-like:
package main
import (
"encoding/json"
"fmt"
)
type User struct {
ID int64 `json:"id"`
Email string `json:"email"`
Name string `json:"name"`
}
func main() {
user := User{
ID: 1,
Email: "anna@example.com",
Name: "Anna",
}
data, err := json.Marshal(user)
if err != nil {
panic(err)
}
fmt.Println(string(data))
}Here you already see several important ideas:
structinstead of PHP associative arrays or DTO classes.- struct tags for JSON mapping (the backtick strings after each field).
- explicit error handling with the multi-value return.
- package-based standard library usage.
The official Go documentation is a great starting point. The Go documentation page recommends Effective Go as a must-read for new Go programmers, and Effective Go itself builds on the language specification, the Tour of Go, and How to Write Go Code. The "How to Write Go Code" guide also introduces modules, packages, commands, and the go tool.
Recommended first resources (in this order):
- Tour of Go — interactive, do every exercise. Two evenings, max.
- How to Write Go Code — modules, packages, the
gocommand. - Effective Go — idioms. Read once, re-read every few weeks.
- Go Documentation index — keep this open as a reference.
- Standard library docs — your daily companion.
Read them, but do not spend months in theory.
After a few days, start building small things.
That is where Go starts to make sense.
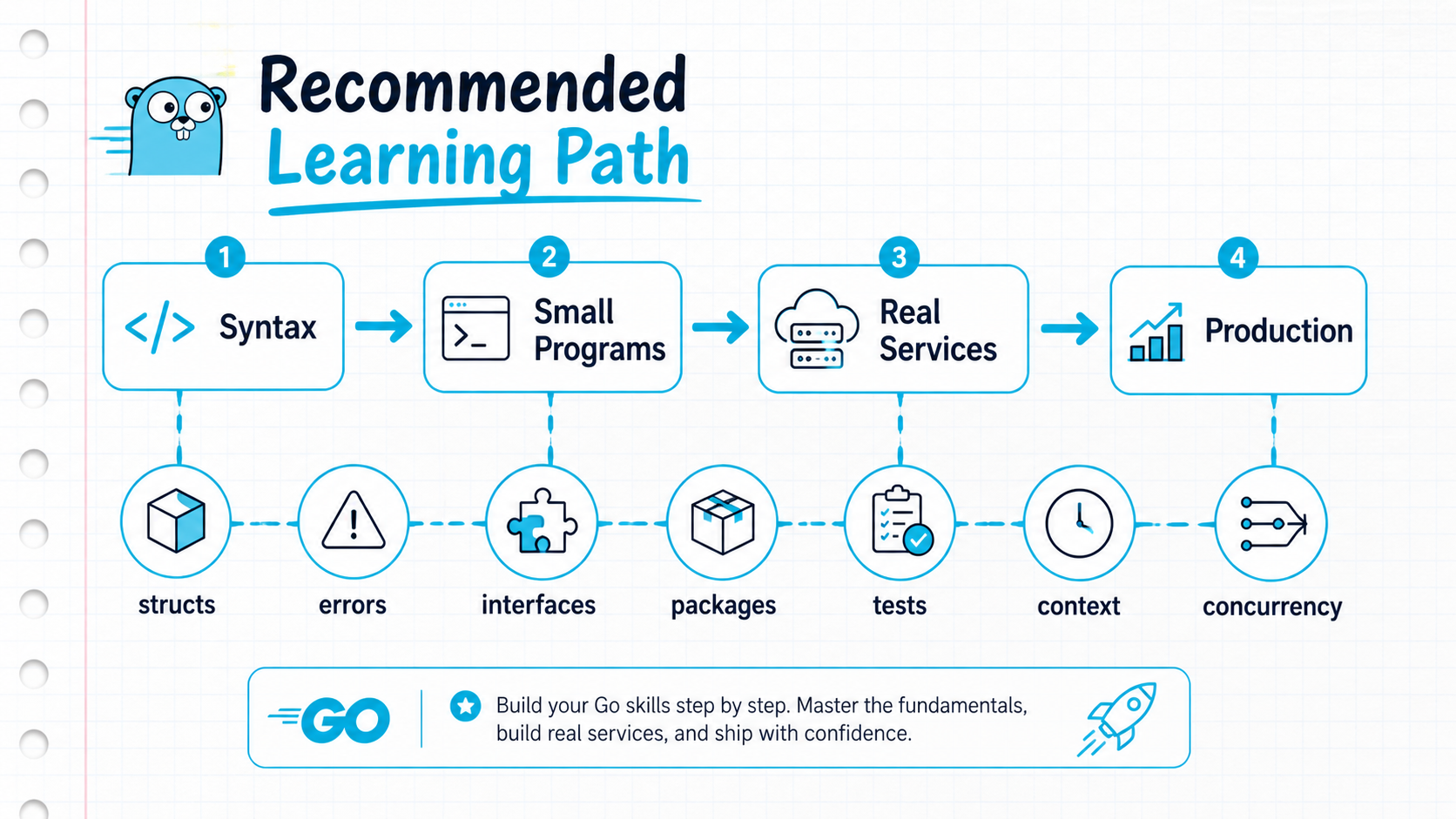
Understand Go's Type System
Go feels different after PHP because Go is statically typed.
That does not mean Go is complicated. Actually, Go's type system is intentionally small compared with languages like Rust, Scala, or TypeScript. But it changes how you design code.
In PHP, you may start with arrays, objects, framework models, service classes, and runtime behavior. In modern PHP (8.x), you can use strict types, typed properties, union types, enums, readonly, and static analysis tools like Psalm or PHPStan. That helps a lot.
But Go goes further because type checking is part of the compiler workflow from the beginning. Your code does not run until it compiles. You cannot ship a typo in production unless the typo also compiles cleanly.
A simple domain model may look like this:
type User struct {
ID int64
Email string
FirstName string
LastName string
}
func (u User) FullName() string {
return u.FirstName + " " + u.LastName
}This is not a class in the PHP sense.
Go does not have classical inheritance. You define data with struct and attach behavior with methods that have a receiver (func (u User) FullName() string). You compose behavior instead of building deep inheritance trees.
That is one of the first major mental shifts.
A practical note: methods can have either a value receiver (func (u User) ...) or a pointer receiver (func (u *User) ...). Use a pointer receiver when:
- the method needs to mutate the struct,
- the struct is large and copying it would be wasteful,
- you want consistency across all methods of a type.
Use a value receiver for small, immutable-feeling types. Be consistent within a single type — mixing both is a smell.
Zero Values Matter
Every Go type has a zero value.
For example:
var count int // 0
var name string // ""
var active bool // false
var user *User // nil
var tags []string // nil slice (works with len() and range)
var lookup map[string]int // nil map (reading is safe, writing PANICS)This sounds small, but it affects API design.
A struct can be usable without a constructor if its zero value is meaningful. Many Go standard library types are designed this way — bytes.Buffer, sync.Mutex, sync.WaitGroup, strings.Builder all work fine when declared as var b bytes.Buffer without any initialization.
As a backend developer, you should ask:
Is the zero value safe, or do I need explicit initialization?
For example, this config type probably needs validation:
type Config struct {
DatabaseURL string
Port int
}
func (c Config) Validate() error {
if c.DatabaseURL == "" {
return fmt.Errorf("database URL is required")
}
if c.Port <= 0 {
return fmt.Errorf("port must be greater than zero")
}
return nil
}Do not rely on hope.
Validate the configuration at startup.
Interfaces Are Behavior Contracts
Interfaces are one of the most important ideas in Go.
Here is a simple repository interface:
type UserRepository interface {
FindByID(ctx context.Context, id int64) (*User, error)
}In Go, interfaces are satisfied implicitly.
That means a type does not need to declare that it implements an interface. If it has the required methods, it implements the interface.
type PostgresUserRepository struct {
db *sql.DB
}
func (r *PostgresUserRepository) FindByID(ctx context.Context, id int64) (*User, error) {
// query database here
return nil, nil
}PostgresUserRepository now satisfies UserRepository because it has the FindByID method with the correct signature.
No implements keyword.
No service container registration magic.
Just behavior.
A common Go practice is to define small interfaces where they are used, not where they are implemented. That is different from many PHP codebases where interfaces often live beside concrete classes in the infrastructure layer.
For example:
type UserService struct {
users interface {
FindByID(ctx context.Context, id int64) (*User, error)
}
}This says: UserService does not care whether the data comes from PostgreSQL, Redis, an HTTP API, or a fake test implementation. It only cares that it can find a user by ID.
That is powerful.
It also keeps interfaces small. The Go community calls this "accept interfaces, return structs" — a guideline that makes refactoring much easier later.
Stop Looking For A Laravel Equivalent
This is one of the biggest mistakes PHP developers make when learning Go.
They ask:
What is the Laravel of Go?
That question is understandable.
But it is often the wrong question.
Laravel is a batteries-included framework. It gives you routing, controllers, middleware, validation, queues, events, notifications, migrations, ORM, authorization, scheduling, testing helpers, and a beautiful developer experience.
Go is usually built differently.
A production Go service may use:
net/httpfor HTTP handling (or a thin router likechi/gin/echoif needed).database/sqlwith a driver likepgx, or a query helper likesqlc/sqlx.- a migration tool like
golang-migrateorgoose. - a structured logger like
log/slog(standard library since Go 1.21). - a validation package like
go-playground/validator. - OpenTelemetry for tracing.
- Prometheus client for metrics.
- Docker or Kubernetes for deployment.
Instead of one large framework, you often assemble a service from smaller pieces.
That does not mean Go has no frameworks. It has web frameworks and routers like Gin, Echo, Fiber, and Chi. But idiomatic Go teams often prefer explicit composition over framework magic, especially since Go 1.22 made the standard net/http router much more capable.
Here is a small example with the standard library — and yes, this works as-is on Go 1.22+:
package main
import (
"encoding/json"
"log"
"net/http"
)
type HealthResponse struct {
Status string `json:"status"`
}
func healthHandler(w http.ResponseWriter, r *http.Request) {
response := HealthResponse{Status: "ok"}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(response)
}
func main() {
mux := http.NewServeMux()
mux.HandleFunc("GET /health", healthHandler)
log.Println("server started on :8080")
log.Fatal(http.ListenAndServe(":8080", mux))
}There is no controller class.
No framework bootstrapping file.
No service provider.
No hidden container.
Just an HTTP handler.
And that is the point.
Go wants boring, explicit code.
Constructor Injection Instead Of A Service Container
In Laravel, you often rely on the service container to resolve dependencies automatically through autowiring.
In Go, you commonly wire dependencies through constructors by hand.
type UserHandler struct {
service *UserService
}
func NewUserHandler(service *UserService) *UserHandler {
return &UserHandler{service: service}
}
type UserService struct {
repo UserRepository
}
func NewUserService(repo UserRepository) *UserService {
return &UserService{repo: repo}
}Then in main.go, you wire the application:
func main() {
db := connectDatabase()
userRepo := NewPostgresUserRepository(db)
userService := NewUserService(userRepo)
userHandler := NewUserHandler(userService)
mux := http.NewServeMux()
mux.HandleFunc("GET /users/{id}", userHandler.Show)
http.ListenAndServe(":8080", mux)
}At first, this may look manual.
But the benefit is clarity.
You can open main.go and see how the application is built. There is no app/Providers/AppServiceProvider.php to grep through, no services.yaml to mentally resolve, no attribute autowiring metadata to chase. The wiring is the code.
That is very Go.
For larger applications, tools like Google's wire generate this glue code at compile time. But you will rarely need it for the first year — the manual version is usually fine and easier to debug.
Build Small CLI Tools First
Before building a web API, build a few CLI tools.
This is one of the best shortcuts for backend developers.
A CLI tool teaches you files, flags, errors, packages, JSON, CSV, testing, and binary distribution without adding web infrastructure too early.
Good first CLI projects:
- CSV validator.
- log analyzer.
- HTTP health checker.
- JSON transformer.
- file renamer.
- database migration helper.
- config validator.
If you have worked with large CSV imports in PHP (probably with League\Csv or raw fgetcsv), build a Go version.
For example:
Build a CLI that reads a CSV file, validates rows, groups invalid records, and writes a JSON report.
Here is a tiny starting point:
package main
import (
"encoding/csv"
"fmt"
"os"
)
type InvalidRow struct {
Line int
Reason string
}
func main() {
if len(os.Args) < 2 {
fmt.Println("usage: csvcheck <file.csv>")
os.Exit(1)
}
file, err := os.Open(os.Args[1])
if err != nil {
fmt.Printf("open file: %v\n", err)
os.Exit(1)
}
defer file.Close()
reader := csv.NewReader(file)
records, err := reader.ReadAll()
if err != nil {
fmt.Printf("read csv: %v\n", err)
os.Exit(1)
}
invalidRows := make([]InvalidRow, 0)
for i, row := range records {
line := i + 1
if len(row) < 2 {
invalidRows = append(invalidRows, InvalidRow{
Line: line,
Reason: "expected at least 2 columns",
})
continue
}
if row[0] == "" {
invalidRows = append(invalidRows, InvalidRow{
Line: line,
Reason: "first column is required",
})
}
}
fmt.Printf("checked %d rows\n", len(records))
fmt.Printf("invalid rows: %d\n", len(invalidRows))
for _, invalid := range invalidRows {
fmt.Printf("line %d: %s\n", invalid.Line, invalid.Reason)
}
}This is not production-ready yet, but it already teaches useful Go:
- command-line arguments,
- file handling,
deferfor cleanup,- CSV parsing,
- slices,
- structs,
- error handling,
- clear program flow.
Then improve it step by step:
- add
flagpackage support for--input,--output,--strictflags, - stream rows with
reader.Read()in a loop instead ofReadAll(handles 10GB files without OOM), - write JSON reports with
encoding/json, - add table-driven tests for the validator,
- benchmark large files with
go test -bench, - process rows concurrently only if profiling proves it helps.
That last point matters.
Do not add goroutines just because Go supports them.
A streaming CSV reader on one core often beats a parallel version because the disk is the bottleneck — CPU sits idle waiting for I/O. Measure first.
Learn Error Handling Properly
Go error handling may feel verbose after PHP exceptions.
In PHP, you may throw an exception and catch it somewhere higher in the call stack. The path the error takes is invisible until something blows up.
In Go, errors are values.
That means error handling is part of normal control flow. Every function that can fail returns an error explicitly, and you decide what to do with it at every step.
user, err := repo.FindByID(ctx, id)
if err != nil {
return nil, fmt.Errorf("find user by id %d: %w", id, err)
}The %w verb wraps the error. That allows callers to inspect the original error later with errors.Is or errors.As. The string "find user by id 42: <original message>" becomes the new message, but the chain is preserved.
Example with sentinel errors:
var ErrUserNotFound = errors.New("user not found")
func (r *UserRepository) FindByID(ctx context.Context, id int64) (*User, error) {
user, err := r.queryUser(ctx, id)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
return nil, ErrUserNotFound
}
return nil, fmt.Errorf("query user: %w", err)
}
return user, nil
}Then the HTTP layer can decide how to convert the domain error into an HTTP response:
user, err := h.service.GetUser(r.Context(), id)
if err != nil {
if errors.Is(err, ErrUserNotFound) {
http.Error(w, "user not found", http.StatusNotFound)
return
}
http.Error(w, "internal server error", http.StatusInternalServerError)
return
}This creates an error boundary.
The repository knows about SQL.
The service knows about business meaning.
The HTTP handler knows about status codes.
That separation is important. Each layer translates errors into the vocabulary of the next layer up. The HTTP client never sees sql.ErrNoRows. The repository never thinks about HTTP 404.
errors.Is vs errors.As
Two helpers, two purposes:
errors.Is(err, target)— "is this error (or anything it wraps) equal totarget?" Use for sentinel errors likesql.ErrNoRows,io.EOF,ErrUserNotFound.errors.As(err, &targetVar)— "is this error (or anything it wraps) of a specific type? If so, give me a typed pointer." Use for structured errors like*pgconn.PgErrorwhere you want to inspect fields like the SQL state code.
var pgErr *pgconn.PgError
if errors.As(err, &pgErr) && pgErr.Code == "23505" {
return ErrDuplicateEmail
}When Should You Use Panic?
Use panic rarely.
A good rule:
- Use errors for expected failures (database down, bad input, network timeout).
- Use panic for programmer mistakes (nil dereference where a value was guaranteed) or unrecoverable startup failures (missing required dependency at boot).
For example, invalid user input is not a panic.
A missing required configuration value during application startup may be fatal, but even then, many teams prefer returning an error and exiting cleanly from main:
func run() error {
cfg, err := LoadConfig()
if err != nil {
return fmt.Errorf("load config: %w", err)
}
return startServer(cfg)
}
func main() {
if err := run(); err != nil {
log.Fatal(err)
}
}This pattern keeps main small and makes run testable.
That is a good habit. Almost every well-written Go service uses this main → run() error pattern.
Learn Context Early
context.Context is one of the most important concepts in backend Go.
You will see it everywhere:
func (s *UserService) GetUser(ctx context.Context, id int64) (*User, error) {
return s.repo.FindByID(ctx, id)
}At first, context may look like noise — every signature has it, it propagates everywhere, and you wonder why a parameter that "does nothing" is so prominent.
It is not noise.
Context carries cancellation, timeouts, and deadlines across API boundaries.
For example, if an HTTP request is canceled by the client (the user closes the tab, the load balancer kills the connection), the request context can cancel downstream database calls or HTTP calls. Without context, those queries keep running, eating connections and CPU for a result nobody will read.
func (h *UserHandler) Show(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithTimeout(r.Context(), 2*time.Second)
defer cancel()
user, err := h.service.GetUser(ctx, 123)
if err != nil {
http.Error(w, "failed to get user", http.StatusInternalServerError)
return
}
json.NewEncoder(w).Encode(user)
}That two-second timeout is now respected by every layer below: the service, the repository, and the actual database/sql call. If the database hangs, the request fails after 2s instead of waiting 30s for the default timeout (or worse, never).
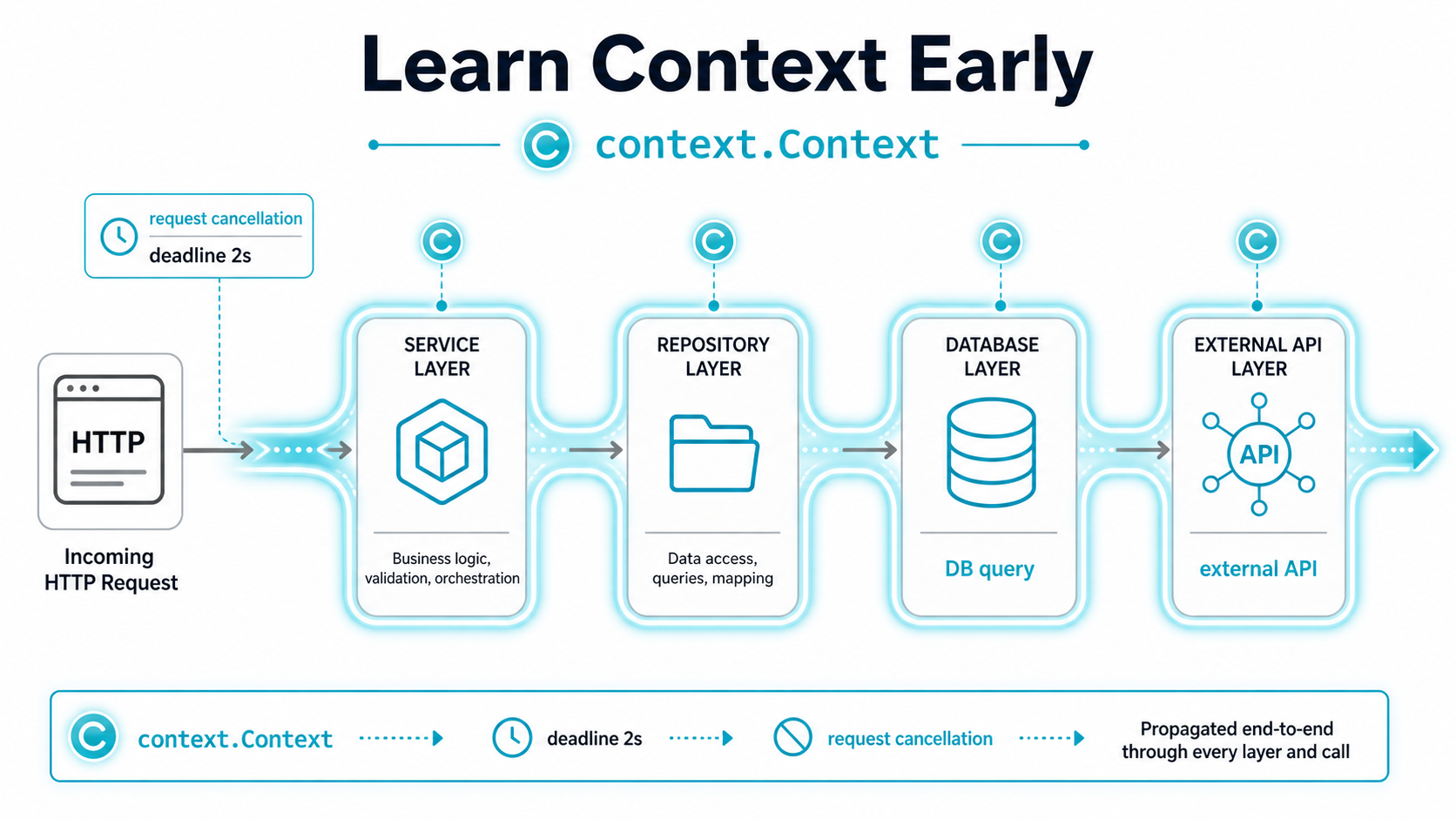
Important Context Rules
- Pass context as the first argument:
func DoThing(ctx context.Context, ...) error. - Do not store context in structs (it has request-scoped lifetime, structs usually do not).
- Do not pass
nilcontext. Usecontext.Background()orcontext.TODO(). - Use context values carefully (
context.WithValue) — only for request-scoped data like trace IDs or auth principals, never as a generic dependency container. - Always
defer cancel()immediately afterWithTimeout/WithCancelto free resources.
Context is not glamorous.
But it is production-critical.
A senior Go engineer should be comfortable with context within the first week of writing real code.
Build A Real HTTP API Without A Heavy Framework
After CLI tools, build a real HTTP API.
Not a toy "hello world" API.
Build a small but realistic task management service:
- users,
- projects,
- tasks,
- authentication (JWT or session — pick one and learn it deeply),
- PostgreSQL,
- migrations,
- validation,
- structured logging (
log/slog), - tests,
- Docker.
A practical Go project structure may look like this:
cmd/
api/
main.go # entrypoint, wiring only
internal/
config/
config.go # env parsing + validation
domain/
user.go # core types + business errors
task.go
httpapi/
handlers.go # HTTP layer
middleware.go
routes.go
service/
user_service.go # business logic
task_service.go
repository/
postgres_user_repository.go
postgres_task_repository.go
platform/
database/
postgres.go # pool setup, migrations
migrations/
001_create_users.sql
002_create_tasks.sql
go.mod
go.sum
Dockerfile
docker-compose.ymlThe internal directory is special to Go: code outside the parent tree cannot import packages inside internal. That helps protect application boundaries — your domain logic cannot accidentally be imported by a separate project.
You do not need to copy this structure exactly.
But you should have a reason for your structure.
Do not create 25 folders because you saw them in a blog post.
Start simple. Add structure when the code asks for it.
Example Handler
type TaskHandler struct {
service *TaskService
}
func NewTaskHandler(service *TaskService) *TaskHandler {
return &TaskHandler{service: service}
}
func (h *TaskHandler) Create(w http.ResponseWriter, r *http.Request) {
var input CreateTaskInput
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
http.Error(w, "invalid JSON", http.StatusBadRequest)
return
}
task, err := h.service.CreateTask(r.Context(), input)
if err != nil {
if errors.Is(err, ErrTaskTitleRequired) {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
http.Error(w, "failed to create task", http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
json.NewEncoder(w).Encode(task)
}Example Service
type TaskService struct {
tasks TaskRepository
}
func NewTaskService(tasks TaskRepository) *TaskService {
return &TaskService{tasks: tasks}
}
func (s *TaskService) CreateTask(ctx context.Context, input CreateTaskInput) (*Task, error) {
if input.Title == "" {
return nil, ErrTaskTitleRequired
}
task := &Task{
Title: input.Title,
ProjectID: input.ProjectID,
Status: "open",
}
if err := s.tasks.Create(ctx, task); err != nil {
return nil, fmt.Errorf("create task: %w", err)
}
return task, nil
}This is familiar if you come from Laravel service classes.
But the wiring is more explicit, and the type signatures actually mean something.
That is the point.
Learn Testing The Go Way
Go has a built-in testing package, and Go tooling makes tests feel like part of the language workflow. There is no PHPUnit to install, no phpunit.xml to configure — go test is just there.
Start with table-driven tests.
They are common in Go because they keep test cases compact and readable, and they are trivial to extend with new cases.
func TestCalculateDiscount(t *testing.T) {
tests := []struct {
name string
amount int
expected int
}{
{name: "no discount", amount: 50, expected: 0},
{name: "small discount at threshold", amount: 100, expected: 10},
{name: "small discount above threshold", amount: 150, expected: 10},
{name: "large discount at threshold", amount: 500, expected: 50},
{name: "large discount above threshold", amount: 700, expected: 50},
{name: "zero amount", amount: 0, expected: 0},
{name: "negative amount", amount: -10, expected: 0},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got := CalculateDiscount(tt.amount)
if got != tt.expected {
t.Fatalf("CalculateDiscount(%d) = %d, want %d", tt.amount, got, tt.expected)
}
})
}
}Notice how covering edge cases (zero, negative, exact thresholds) is just adding a row. This is why table-driven tests dominate idiomatic Go.
Run tests:
go test ./... # all packages
go test -v ./... # verbose
go test -run TestCalculate ./... # specific testRun tests with race detection:
go test -race ./...The official Go race detector documentation states that you can start by running tests with go test -race. It also notes an important limitation: the race detector only finds races that happen at runtime, so your tests or workload must actually execute the risky code paths.
That is a practical detail senior engineers should care about.
A passing race detector does not prove concurrency is perfect.
It proves it did not observe a race in the executed paths.
Run -race in CI for every PR.
Test HTTP Handlers With httptest
Go's standard library includes httptest, which is perfect for testing HTTP handlers without spinning up a real server.
func TestHealthHandler(t *testing.T) {
request := httptest.NewRequest(http.MethodGet, "/health", nil)
recorder := httptest.NewRecorder()
healthHandler(recorder, request)
if recorder.Code != http.StatusOK {
t.Fatalf("expected status 200, got %d", recorder.Code)
}
body := recorder.Body.String()
if !strings.Contains(body, "ok") {
t.Fatalf("expected body to contain 'ok', got %s", body)
}
}This is simple and fast.
No browser.
No real server.
No heavy framework.
For end-to-end tests against a real router, httptest.NewServer(handler) gives you a real HTTP server on a random port, perfect for integration tests.
Use Fuzzing For Input-Heavy Code
Go also supports fuzz testing in the standard toolchain (since Go 1.18). The official Go fuzzing tutorial explains that fuzzing runs random data against your test to find vulnerabilities or crash-causing inputs.
This is very useful for parsers, validators, encoders, decoders, import tools, and anything that accepts untrusted input.
Example:
func FuzzNormalizeEmail(f *testing.F) {
// Seed corpus — examples to start fuzzing from.
f.Add("TEST@example.com")
f.Add(" user@example.com ")
f.Add("")
f.Fuzz(func(t *testing.T, input string) {
normalized := NormalizeEmail(input)
// Property: normalized email should never contain spaces.
if strings.Contains(normalized, " ") {
t.Fatalf("normalized email contains spaces: %q (input: %q)", normalized, input)
}
})
}Run it:
go test -fuzz=FuzzNormalizeEmail
go test -fuzz=FuzzNormalizeEmail -fuzztime=30s # bounded run for CIFuzzing is not needed everywhere.
But for code that accepts unpredictable input (URL parsers, CSV importers, JWT decoders), it can find edge cases humans miss in minutes.
Learn Concurrency Slowly And Correctly
Go is famous for concurrency.
That does not mean every Go program needs goroutines everywhere.
A goroutine is a lightweight concurrent function execution:
go sendEmail(user)That looks easy.
And that is why it can become dangerous.
If you start goroutines without understanding cancellation, error handling, shared memory, and lifecycle management, you can create invisible production bugs: goroutine leaks that slowly eat memory, races that corrupt data once a week, deadlocks that only happen under load.
Start with basic tools:
- goroutines,
- channels (buffered and unbuffered),
sync.WaitGroupfor waiting on goroutines,sync.Mutexandsync.RWMutexfor shared state,- worker pools,
- fan-out/fan-in patterns,
- cancellation via context,
- the race detector to catch data races.
Here is a simple worker pool with proper cancellation:
type Job struct {
ID int
}
func worker(ctx context.Context, id int, jobs <-chan Job, wg *sync.WaitGroup) {
defer wg.Done()
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok {
return
}
fmt.Printf("worker %d processed job %d\n", id, job.ID)
}
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
jobs := make(chan Job)
var wg sync.WaitGroup
for i := 1; i <= 3; i++ {
wg.Add(1)
go worker(ctx, i, jobs, &wg)
}
for i := 1; i <= 10; i++ {
jobs <- Job{ID: i}
}
close(jobs)
wg.Wait() // ensures all workers finished before main returns
}This code demonstrates the idea, but production worker systems need more:
- graceful shutdown (drain in-flight jobs before exit),
- retries with backoff,
- exponential backoff with jitter,
- dead-letter queues for permanent failures,
- idempotency (workers can crash mid-job),
- metrics (jobs/second, queue depth, error rate),
- structured logging with job IDs,
- panic recovery boundaries (one bad job should not kill the worker),
- backpressure (slow down producers when consumers cannot keep up).
For coordinating multiple goroutines that can each fail, golang.org/x/sync/errgroup is invaluable — first failure cancels everyone, and you collect the error at the end.
Senior Go engineers know when not to use concurrency.
Sometimes a simple loop is better.
Sometimes the database is the bottleneck.
Sometimes concurrency makes the system faster.
Sometimes it just makes failure harder to debug.
Measure first.
Then optimize.
Learn Memory, Allocation, And Performance
You do not need to become a compiler engineer to write good Go.
But senior Go developers should understand basic performance behavior.
Important topics:
- stack vs heap basics (Go's garbage collector handles both, but heap allocations cost more),
- escape analysis (
go build -gcflags="-m"shows you why a value escaped to the heap), - allocations per operation (
go test -bench -benchmem), - slice internals (pointer, length, capacity),
- map behavior (random iteration order, growth costs),
- garbage collection pauses (usually sub-millisecond on modern Go),
- profiling before optimizing.
A common beginner mistake is trying to optimize everything too early.
Do not do that.
Write clear code first.
Then profile.
Go includes profiling support through pprof. You can collect CPU profiles, heap profiles, goroutine profiles, mutex profiles, and block profiles.
A simple CPU profile in a benchmark:
go test -bench=. -cpuprofile=cpu.out ./...
go tool pprof cpu.out
# inside pprof:
# top (top functions by CPU time)
# list MyFunction (annotated source)
# web (call graph in browser, requires graphviz)For HTTP services, you can expose pprof endpoints during development or behind protected internal access:
import _ "net/http/pprof" // blank import registers handlers
func main() {
go func() {
// pprof on a separate, internal-only port
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
startApplicationServer()
}Then in another terminal:
go tool pprof http://localhost:6060/debug/pprof/heap
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30Slices Are Not Just Arrays
Slices are one of the most important Go data structures, and they are also the most misunderstood.
A slice is a descriptor over an underlying array. It has three fields: a pointer to the array, a length, and a capacity.
items := make([]string, 0, 100) // length=0, capacity=100
items = append(items, "first") // length=1, capacity=100, no allocationPreallocating capacity can dramatically reduce allocations when you know the expected size.
For example:
func UserIDs(users []User) []int64 {
ids := make([]int64, 0, len(users)) // exact capacity → zero re-allocations
for _, user := range users {
ids = append(ids, user.ID)
}
return ids
}Without len(users) as the capacity hint, append would re-allocate the backing array several times as it grows (Go doubles the capacity when growing small slices).
This is simple and practical.
No micro-optimization drama.
Just avoid unnecessary allocations when the intent is obvious.
Learn Production Patterns
This is where Go becomes serious backend engineering.
A production Go service is not just handlers and structs.
You need the same things you need in any backend system:
- graceful shutdown,
- health checks,
- readiness and liveness probes,
- configuration management,
- structured logging,
- metrics,
- tracing,
- retries,
- timeouts,
- idempotency,
- backpressure,
- connection pools,
- queue workers,
- cron-like jobs,
- database migrations,
- safe deployments.
Go is excellent for this because the deployment story can be simple.
You can compile a service into a single static binary and run it in a container under 20MB. No PHP-FPM. No Apache. No Composer install at boot. Just one file.
But simple deployment does not remove production complexity.
You still need good runtime behavior.
Graceful Shutdown (Modern Idiomatic Pattern)
When a service receives a shutdown signal (SIGTERM in Kubernetes, Ctrl+C locally), it should stop accepting new work, finish active requests if possible, and close resources cleanly.
The modern idiomatic pattern uses signal.NotifyContext (added in Go 1.16) instead of manual channel plumbing:
package main
import (
"context"
"errors"
"log"
"net/http"
"os/signal"
"syscall"
"time"
)
func main() {
// Context cancels on SIGINT or SIGTERM.
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer stop()
mux := http.NewServeMux()
mux.HandleFunc("GET /health", healthHandler)
server := &http.Server{
Addr: ":8080",
Handler: mux,
ReadHeaderTimeout: 5 * time.Second,
}
go func() {
if err := server.ListenAndServe(); err != nil && !errors.Is(err, http.ErrServerClosed) {
log.Fatalf("server error: %v", err)
}
}()
log.Println("server started on :8080")
// Block until a signal arrives.
<-ctx.Done()
log.Println("shutdown signal received")
// Give in-flight requests up to 10s to finish.
shutdownCtx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
if err := server.Shutdown(shutdownCtx); err != nil {
log.Fatalf("graceful shutdown failed: %v", err)
}
log.Println("server stopped cleanly")
}A few things changed compared to the old pattern:
signal.NotifyContextreplaces the manualchan os.Signal+signal.Notify+<-stopdance.errors.Is(err, http.ErrServerClosed)instead oferr != http.ErrServerClosed— survives error wrapping.ReadHeaderTimeouton the server prevents Slowloris-style attacks (a public-facing server without it is a liability).
This kind of code matters in Kubernetes, ECS, systemd, and any real deployment environment. Without it, deploys generate a spike of 502s every time.
Timeouts Everywhere
One of the most practical production lessons:
Every network call should have a timeout.
No timeout means a dependency can freeze part of your system indefinitely. A misbehaving downstream service can take your whole pod out by exhausting goroutines that are blocked on a connection.
Example HTTP client:
client := &http.Client{
Timeout: 3 * time.Second,
}
request, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
return fmt.Errorf("build request: %w", err)
}
response, err := client.Do(request)
if err != nil {
return fmt.Errorf("call external service: %w", err)
}
defer response.Body.Close()A few notes:
http.NewRequestWithContextties the request to your context. If the parent context cancels, the HTTP call cancels too.client.Timeoutcovers the entire request lifecycle (DNS, connect, write, read body). For finer control, configurehttp.Transport.- Always call
response.Body.Close()— leaking response bodies is the #1 cause of mysterious connection exhaustion. - The default
http.DefaultClienthas no timeout. Never use it in production.
This is not Go-specific.
This is production-specific.
Go just makes it very visible — which is good.
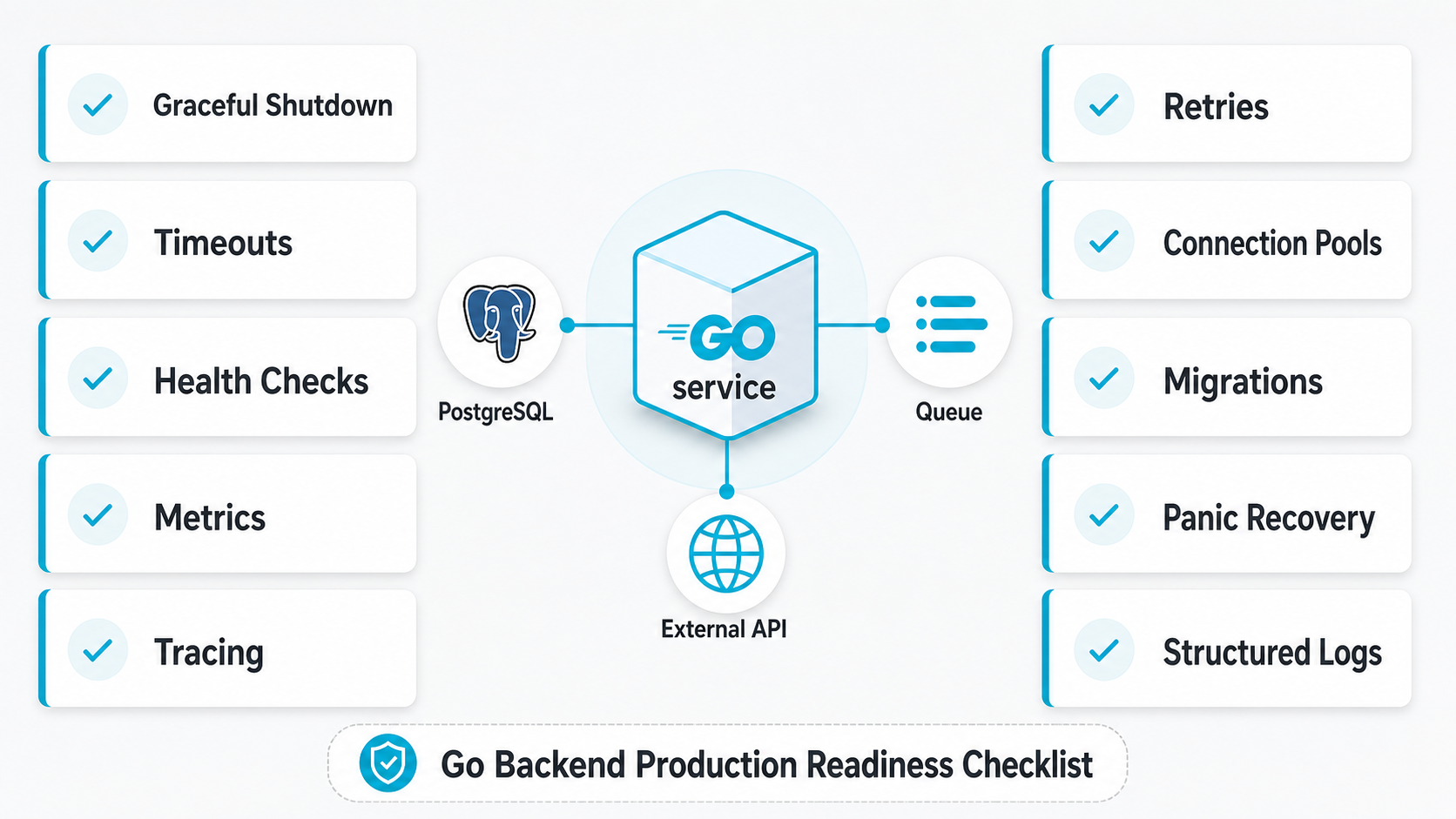
Build Three Portfolio-Level Go Projects
At some point, you need proof.
Not certificates.
Proof.
If you want to be taken seriously as a Go backend engineer, build projects that show production thinking.
Project 1: REST API Service
Build a REST API with:
- PostgreSQL,
- authentication (JWT or sessions),
- migrations,
- input validation,
- structured logging (
log/slog), - integration tests against a real DB (use
testcontainers-goor a Docker Compose test DB), - Docker Compose for local dev,
- graceful shutdown,
- health and readiness endpoints,
- a
MakefileorTaskfilefor the common commands.
This proves you can build normal backend services in Go.
Do not make it too simple.
A CRUD API without tests and production behavior is not enough for a senior profile.
Project 2: Concurrent Worker System
Build a queue consumer with:
- worker pool,
- retries,
- exponential backoff with jitter,
- dead-letter queue,
- idempotency keys,
- Prometheus metrics,
- graceful shutdown that drains in-flight jobs,
- race detector enabled in CI.
This proves you understand concurrency beyond toy examples.
A good project idea:
Build an email notification worker that reads jobs from a queue (Redis Streams, RabbitMQ, or SQS), retries temporary failures with exponential backoff and jitter, stores permanently failed messages in a dead-letter table, and exposes Prometheus metrics for queue depth, processing time, and error rate.
Project 3: CLI / Dev Tool
Build a practical tool that solves a real developer problem.
Ideas:
- log analyzer,
- CSV validator,
- config diff/checker,
- SQL migration safety scanner (catches
ALTER TABLE ... DROP COLUMNon big tables), - API contract validator,
- multi-stage release notes generator from commits.
This is especially useful because Go is great for CLI tools.
A single binary is easy to distribute (scoop, brew, go install, just a download link).
That is a strong portfolio signal — and these are tools you might actually use.
Read Production Go Code
You become better at Go by reading real Go code.
Not only tutorials.
Read production-grade open-source projects:
docker/cli— large CLI app, plugin system,kubernetes/kubernetes— massive, butstaging/src/k8s.io/client-gois a great reading target,prometheus/prometheus— production observability,hashicorp/terraform— provider plugin model,grafana/grafana— Go backend with rich frontend,gohugoio/hugo— large CLI tool,caddyserver/caddy— readable HTTP server.
Do not try to understand huge projects in one sitting.
Pick one small area:
- how they structure packages,
- how they pass context,
- how they handle errors,
- how they test,
- how they configure services,
- how they shut down processes,
- how they expose metrics.
Reading good Go code teaches style.
And style matters in Go.
Go code should be boring in a good way.
Clear names. Small interfaces. Direct error handling. Minimal magic. Practical tests. Explicit dependencies.
That is the vibe.
A Practical 12-Week Roadmap
You can learn enough Go to build serious backend systems in 12 focused weeks if you already have backend experience.
Not mastery.
But real, useful confidence — the kind that gets you through a senior Go interview and lets you ship a service to production.
Weeks 1–2: Syntax, Types, Packages, Errors
Focus on:
- basic syntax,
- structs,
- methods (value vs pointer receivers),
- slices,
- maps,
- pointers,
- packages,
- modules (
go mod init,go mod tidy,go get), - error handling (
errors.Is,errors.As,%w), - interfaces.
Build small exercises every day. Do not only read.
Write code.
Weeks 3–4: CLI Tools, Files, JSON, HTTP Clients
Build two or three CLI tools.
Good options:
- CSV validator (with streaming for big files),
- JSON transformer (jq-lite),
- HTTP health checker (multi-target, parallel),
- log analyzer (regex + summarization).
Practice:
os,io,bufio,encoding/json,encoding/csv,net/http(client side),- the
flagpackage orspf13/cobrafor serious CLIs, - tests for everything.
Weeks 5–6: REST API, PostgreSQL, Migrations
Build the task management API.
Add:
- routing with
net/http1.22+ ServeMux, - handlers, services, repositories,
- PostgreSQL via
pgxordatabase/sql, - migrations with
golang-migrate, - input validation,
- Docker Compose with the DB.
Keep the structure simple.
Make it work.
Then clean it up.
Weeks 7–8: Tests, Integration Tests, Benchmarks
Add serious tests.
Practice:
- table-driven tests,
httptestfor handlers,- fakes / in-memory implementations,
- integration tests with a real DB (testcontainers-go),
- test database setup/teardown,
- benchmarks (
go test -bench), - fuzzing where useful.
Run:
go test ./...
go test -race ./...
go test -bench=. -benchmem ./...
go test -fuzz=FuzzMyParserWeeks 9–10: Concurrency, Context, Workers
Build a worker system.
Practice:
- goroutines,
- channels,
- worker pools,
sync.WaitGroup,sync.Mutex,sync.Once,errgroup.Group,- cancellation via context,
- timeouts,
- retries with exponential backoff and jitter,
- dead-letter handling,
- idempotency.
This is where you learn when concurrency helps and when it hurts.
Week 11: Profiling, Performance, Observability
Add:
- structured logs with
log/slog, - metrics with
prometheus/client_golang, - tracing basics with OpenTelemetry,
- pprof endpoints (internal only),
- CPU profiling under load,
- heap profiling,
- connection pool tuning.
Do not optimize blindly.
Profile first.
Week 12: Final Production-Grade Project
Pick one final project and polish it for portfolio.
Add:
- a clear
README.mdthat a stranger can follow, - architecture notes,
- local setup in one command (
make up), - Docker Compose,
- tests with reasonable coverage,
- CI on GitHub Actions or similar,
- example requests / a Postman collection,
- screenshots or diagrams,
- deployment notes.
Make it easy for another engineer to run and understand in five minutes.
That matters more than feature count.
The Quick Track: Learn Go In A Few Days
Sometimes you do not have 12 weeks. Maybe you have an interview on Monday, a Go service to take over from a teammate, or just a long weekend and a strong urge to ship something.
Here is the compressed version for senior backend developers who already understand HTTP, SQL, queues, and production. This is not "learn Go properly" — it is "be productive in Go fast and clean up later".
Day 1 — Syntax + Mental Model (4–6 hours)
Goal: read any Go code without panicking.
- Morning (2h): Do the Tour of Go end to end. Skip nothing, but do not over-think.
- Afternoon (2h): Read these three pages:
- Effective Go (skim — read carefully sections on errors, interfaces, concurrency).
- Go Code Review Comments (the unofficial style law).
- How to Write Go Code (modules, packages).
- Evening (1–2h): Write three things from scratch in a single
main.go:- A
Userstruct with aFullName()method. - A function that returns
(int, error)and handles the error correctly. - A goroutine + channel that sends three numbers and prints them.
- A
If you got those three things working, you can read almost any Go codebase.
Day 2 — Build A CLI Tool (4–6 hours)
Goal: feel the language by shipping something tiny.
Build a CSV checker (the example earlier in this article). Then improve it:
- add
flag.String("input", "", "input file"), - stream rows with
reader.Read()instead ofReadAll, - output a JSON report with
encoding/json, - write 3–5 table-driven tests for the validator function.
End of day: you have a single binary you can go build and ship to anyone. That is genuinely satisfying after years of composer install.
Day 3 — HTTP Service With Real Patterns (6–8 hours)
Goal: build something a backend engineer would actually deploy.
Build a minimal task API with net/http 1.22+ ServeMux, no framework:
POST /tasks— create a task.GET /tasks/{id}— get one task.GET /tasks— list tasks.
Wire it like this:
main.go # signal.NotifyContext + server.Shutdown
handlers.go # HTTP layer
service.go # business logic
repository.go # in-memory map for now (sync.RWMutex)
domain.go # Task struct, errorsHit every key concept: structs, interfaces, context, errors with %w, graceful shutdown, table-driven tests with httptest.
Once it works in-memory, swap the repository for PostgreSQL using database/sql + pgx. Same interface, new implementation. That swap is the moment Go clicks.
Day 4 — Concurrency + Production Polish (6–8 hours)
Goal: write code you would not be embarrassed to deploy.
Add to the Day 3 service:
- a background worker that processes a
chan Task(e.g. sends a fake notification), sync.WaitGroupto drain the worker on shutdown,- request timeouts (
context.WithTimeoutin handlers), - structured logs with
log/slog, - a
/healthzendpoint, - a
Dockerfilewith multi-stage build (final image under 20MB), docker-compose.ymlwith Postgres,- CI:
go test -race ./...andgo vet ./....
End of day: you have a real Go service with the patterns that matter in production.
Day 5 (optional) — Read, Refactor, Fluency
Goal: polish style and patterns.
- Read 200–300 lines of one of:
caddy,prometheus,hugosource. - Refactor your Day 3–4 service: extract small interfaces where they are used, kill any panic, replace any
interface{}with concrete types or generics, clean error messages. - Skim the
log/slogdocs,errors,context. - Run
go vet,staticcheck, andgofmt -sover the codebase.
After five days, you have:
- working knowledge of Go syntax and idioms,
- one CLI tool and one HTTP service in your repo,
- hands-on experience with errors, context, concurrency, and graceful shutdown,
- enough production patterns to pass a "ship a small service" Go take-home.
You do not have:
- deep familiarity with the runtime, GC, or assembly,
- mastery of generics, build tags, cgo, or unsafe,
- years of "what is the right way" intuition.
Those come later. Five days gets you in the door. Twelve weeks gets you confident. The next year is where senior judgment forms.
What Senior Go Learning Really Means
Learning Go fast does not mean skipping fundamentals.
It means using your existing backend experience correctly.
You already understand many hard problems:
- APIs,
- databases,
- queues,
- caching,
- production bugs,
- logs,
- deployments,
- performance,
- business rules.
Now you need to translate that experience into Go's style.
Go will push you toward explicit code.
It will make errors visible.
It will make dependencies visible.
It will make concurrency powerful but also dangerous if you use it carelessly.
It will reward simple design.
That is why Go is such a good language for backend systems.
Not because it has the most features.
Because it has enough features, strong tooling, fast builds, simple deployment, and a culture that values readable production code.
You become senior in Go not when you know every keyword.
You become senior when you can build, test, deploy, debug, profile, and maintain real Go systems.
That is the roadmap.
Start small.
Build real tools.
Write tests.
Read production code.
Use concurrency carefully.
Profile before optimizing.
And most importantly: stop searching for magic.
Go works best when the code is clear enough that you do not need magic at all.
That is the part PHP never quite teaches you. Go does.





