
So, somebody on the team has started saying "this would be faster in Go." It might be the new staff engineer. It might be the SRE who's tired of bouncing PHP-FPM pools at 4am. It might be you, after a particularly bad night with the event loop and a memory graph that looks like a staircase. Either way, the idea is in the room, and the next steps are predictable: somebody draws a rewrite plan on a whiteboard, somebody else nervously asks how long it'll take, and then nothing happens for three weeks.
This article is for those three weeks.
The honest answer to "should we rewrite this in Go?" isn't "yes, look how fast Go is" and it isn't "no, you'll fail like every other rewrite". It's a stack of trade-offs, most of which are about your team and your operational reality, not the language. Performance matters - sometimes a lot - but it's usually the smallest variable. Skills, organisational risk, and how you keep the lights on during the migration matter more. Let's walk through them in the order they'll actually bite.
Why "rewrite it in Go" keeps coming up
There's a reason this conversation happens at almost every company with a 5+ year old PHP or Node service. Go has a specific shape that fits a specific kind of pain.
If you're running PHP-FPM, the pain is usually shaped like workers. Each request gets a process. The process boots a framework, hits a database, returns a response, and dies. Memory per request is bounded but never amortised. Long-running anything - WebSockets, background jobs, in-process caches - sits awkwardly outside the request/response model. You end up with Supervisor configs, Redis-backed queues, and a separate worker fleet that nobody loves maintaining.
If you're running Node, the pain is usually shaped like the event loop. CPU-bound work blocks everything. You can't think clearly about parallelism. Memory is hard to reason about because V8 GC pauses come whenever they feel like it. You add worker_threads, then cluster, then a load balancer, then a sidecar in another language for the bit that was actually CPU-heavy. The tooling is great until you need to debug a memory leak across three layers of async.
Go shows up at this stage looking like the answer to both. Goroutines collapse the workers-vs-event-loop split into a single mental model. A single binary deploys to a single process and uses cores without sharding. Static types catch the silly stuff at compile time. The standard library has an HTTP server you can actually ship. GC pauses are short and predictable. Deploys are scp and a systemd unit, if you want them to be.
All of that is real. None of it is a free win.
Performance: what actually changes
Let's start with the variable that gets quoted most and understood least. "Go is faster" is true on average and useless in specifics. What changes when you move a service from PHP or Node to Go is rarely raw single-request latency - it's what your tail looks like under load, and how many machines you need to serve the same traffic.
The model shifts. PHP-FPM is a pool of OS processes. Node is one OS thread spinning an event loop. Go is one process scheduling goroutines onto a configurable set of OS threads. The differences are mostly about how each handles concurrent work:
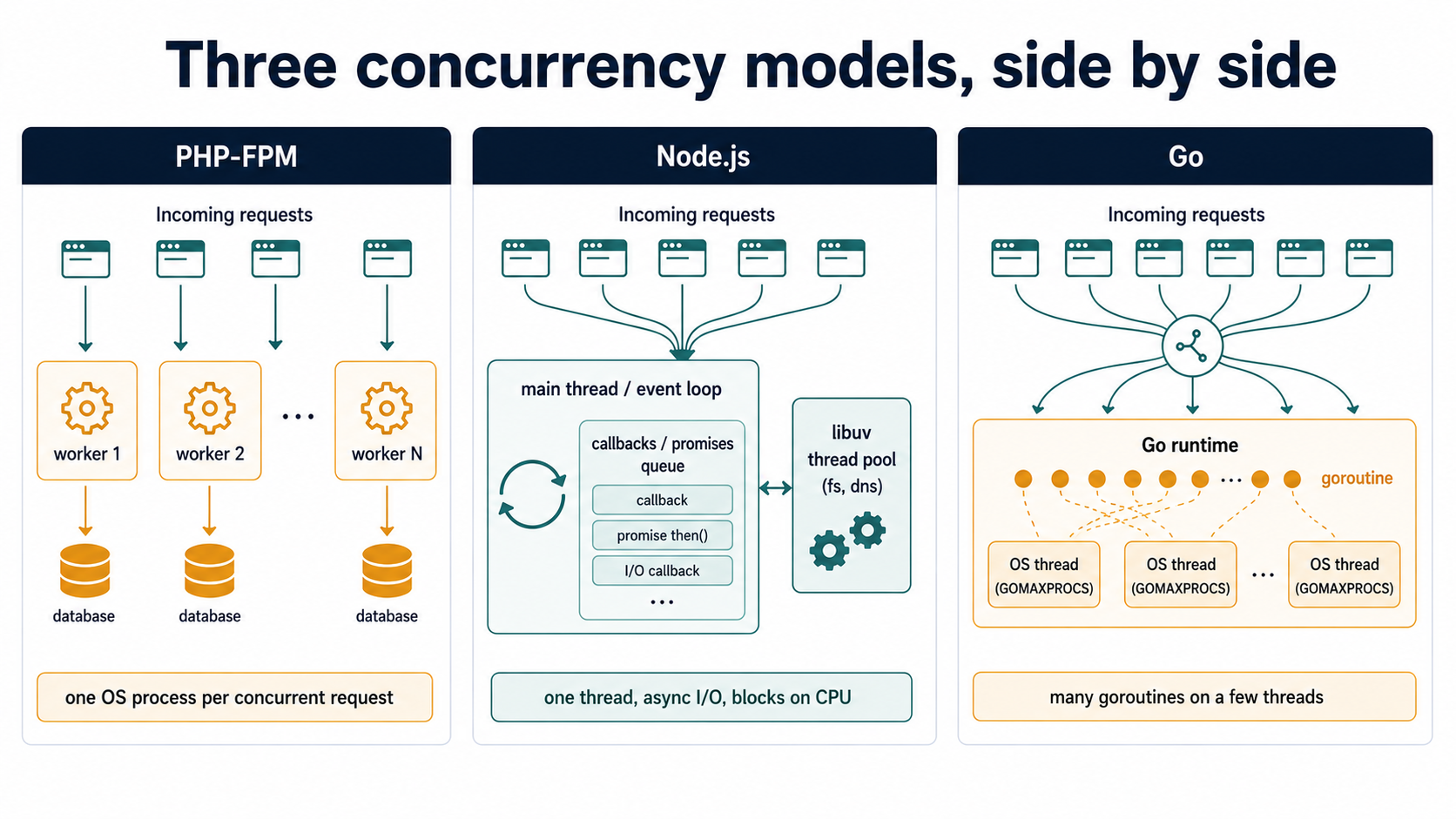
A few things follow from those shapes.
CPU-bound work is where Go usually wins outright. Hashing, image processing, parsing big payloads, anything that ties up a core - PHP can do it but you pay per-request startup; Node can do it but it blocks every other in-flight request on that worker; Go can do it in a goroutine while the rest of the service keeps serving. If your hot loop is CPU, you'll feel the difference before you finish reading the metrics dashboard.
I/O-bound work is where the comparison narrows. A service that mostly waits on Postgres and Redis isn't going to magically halve its p99 just because the runtime changed. Postgres still takes the same time to do its index scan. The wire is the wire. What you usually gain on I/O-heavy services is not lower median latency - it's a flatter tail under load, because Go's scheduler doesn't queue requests behind a single-threaded event loop, and you're not waiting for a PHP worker to free up.
The constant factors are real, just smaller than people quote. A hello-world handler in Go will serve more requests per second than the same handler in Node, which will serve more than the same in PHP-FPM under most setups. But the multiplier you see in microbenchmarks (10x, 50x) collapses fast once you add a database, a serialisation step, a couple of middlewares, and the network. The real-world win is more often 1.5x-3x on throughput and a smaller, calmer fleet.
Here's the same trivial JSON endpoint in all three, just so the shapes are next to each other:
package main
import (
"encoding/json"
"net/http"
)
type Order struct {
ID string `json:"id"`
Total int `json:"total"`
}
func handleOrder(w http.ResponseWriter, r *http.Request) {
o := Order{ID: r.URL.Query().Get("id"), Total: 4200}
w.Header().Set("Content-Type", "application/json")
_ = json.NewEncoder(w).Encode(o)
}
func main() {
http.HandleFunc("/order", handleOrder)
_ = http.ListenAndServe(":8080", nil)
}import express from "express";
const app = express();
app.get("/order", (req, res) => {
res.json({ id: req.query.id, total: 4200 });
});
app.listen(8080);<?php
namespace App\Http\Controllers;
use Illuminate\Http\JsonResponse;
use Illuminate\Http\Request;
class OrderController extends Controller
{
public function show(Request $request): JsonResponse
{
return response()->json([
'id' => $request->query('id'),
'total' => 4200,
]);
}
}None of those snippets are doing anything interesting. They exist to make the next sentence land. The Go version, by default, will use all your cores. The Node version will use one until you wrap it in cluster or a process manager. The PHP version will use whatever PHP-FPM is configured to use, with a hard cap on concurrent in-flight requests equal to your pm.max_children. Same logic, three completely different operational shapes.
Memory works the same way. Go services run with a single resident set you can plot. Node services give you a V8 heap graph that you'll learn to read. PHP services give you a pile of short-lived processes - rss looks flat because nothing lives long enough to leak visibly, which is comforting until you find out a particular request shape pushes a worker over memory_limit and you only see it as an error rate.
The takeaway here is not "Go is faster, rewrite for performance". It's "Go gives you a different operational shape, and that shape is what you're actually buying". If your problem is "we're paying for too many PHP workers to keep p99 reasonable" or "every Node service in the team has its own bespoke clustering setup", the shape will help. If your problem is "a single endpoint is slow and we don't know why", the shape will not.
The skill gap nobody scopes properly
Here's where rewrites quietly run aground. The technical migration isn't the hard part; the team migration is.
Go looks small. The spec fits in a long afternoon. There are no classes, no decorators, no metaprogramming. People come back from a weekend with a working CLI and think "this is easy". Then they write production Go for six months and the same code review comes around every week.
The categories of things people actually need to learn are predictable:
Error handling as control flow. if err != nil { return err } is the simplest line in the language, and the hardest one to internalise. Engineers coming from PHP exceptions or Node promise chains will spend a few weeks resisting the pattern, a few months going through it grudgingly, and then suddenly defending it at length in a thread on Hacker News. The transition is real and it takes time. Code reviews during that period are exhausting - every PR has the same comment.
Concurrency primitives. Goroutines and channels are not the same as async/await. The mental model swaps from "this function returns a promise of a value" to "this function might block; I might call it in a goroutine; the caller might be waiting on a channel". You'll see beginners spawn unbounded goroutines, forget to drain channels, hold mutexes across I/O, and confuse context.Context for a config struct. None of that is shameful, but you have to budget for it.
Pointers and value semantics. PHP and Node engineers haven't usually thought about whether something is a value or a pointer to a value since university. Go forces the question into every method receiver and every struct field. You'll review a lot of func (u User) Save() (no pointer, no mutation, silently broken) until people internalise the difference.
Project layout and dependency hygiene. There is no Laravel, no NestJS, no Express. Go has the standard library, a handful of small routers (chi, gorilla/mux), and go.mod. Teams coming from a strong framework background will spend their first quarter rebuilding things their framework gave them for free - configuration loading, request validation, response shapes, structured logging - and not always well. This is fine, but only if you treat it as expected.
Testing culture. Go's testing story is go test, table-driven tests, and a strong norm against heavy mocking. PHP teams used to PHPUnit's mock objects and Node teams used to Jest's auto-mocking will reach for gomock or testify/mock, write a hundred mocks, and then discover that everyone in the Go community gently rolls their eyes at them for it. The norm is real and pushes back if you ignore it.
A rough rule of thumb: a senior engineer who's strong in PHP or Node can write fine Go in about two months and good Go in about six. A mid-level engineer takes twice that. A junior is essentially learning systems programming for the first time and that's a year of mentoring. None of that is a problem if you scope it; it's a disaster if you assumed the rewrite would take a quarter.
The rewrite risks that wreck the project
Programming language migrations have a long history of going badly, and most of the failure modes have nothing to do with the language being migrated to.
The big-bang rewrite. Six months of parallel development, a switchover weekend, three years of mythology. Joel Spolsky wrote Things You Should Never Do about this in 2000 and it's still right. The version that survives in your team's chat is usually phrased as "we have to rewrite from scratch, the old code is unmaintainable" - which is sometimes true and almost never a good enough reason. The old code encodes years of edge cases and customer-specific behaviour you don't remember. Throwing it out throws those out too.
Feature freeze for the duration. Closely related. Product gets told the team has to pause new work to migrate. Product agrees for the first six weeks. By week ten, three sales-driven features have snuck back in, the migration team is dual-implementing everything in both stacks, and the project's timeline has quietly tripled. The fix is to not pretend the feature pipeline can stop, and to plan migration as continuous co-existence rather than a freeze.
Underestimating the surface area. The service you think you're rewriting is the service plus its cron jobs, its Artisan/CLI commands, its admin scripts, its webhook handlers, its custom middleware that nobody remembers writing. Every PHP project has a routes/console.php or a bin/ directory full of one-off scripts. Every Node project has a few scripts/ files used in deploys. None of those show up in your "rewrite the API" plan and all of them need a home in Go.
Drift between the two implementations. While you're rewriting, the old service keeps shipping. Bug fixes land in PHP. Behaviour gets clarified in Node. Three months in, you have two services that diverge in small but important ways - a rounding rule, a timezone, a default sort order. When you finally cut over, customers notice every one of them.
The "we'll do it properly this time" trap. Migrations are tempting moments to fix everything. Let's also redo the database schema. Let's also switch from REST to gRPC. Let's also adopt event sourcing. Let's also extract these four bounded contexts into microservices. Each of those decisions doubles the project's risk. The cheapest, fastest, most likely-to-succeed migration is the one that ports current behaviour to Go, line for line where possible, and saves the architecture improvements for a second pass.
Performance hubris. This one is specific to Go migrations. The team writes the first Go service, sees a 5x throughput improvement on a synthetic benchmark, and starts promising a 5x reduction in infrastructure cost. Production is never the synthetic benchmark. The cost-saving estimate quietly gets revised down, then becomes a footnote, then becomes the reason the next migration doesn't get funded.
The pattern in all of these is the same: the language matters less than the project management. Migrations fail because of scope, drift, and politics, not because someone forgot how chan works.
Interop: how you survive the migration
Once you've decided to do this, the part nobody enjoys planning is also the part that decides whether you ship. You have a working PHP or Node service. You have a Go service that's almost ready for one endpoint. How do you switch traffic to it without taking the whole product down?
This is where the strangler fig pattern earns its name. Coined by Martin Fowler back in 2004, the idea is to grow the new system around the old one, route by route, until the old one is a husk you can finally cut out. The new service starts handling one URL, then five, then most of them; the old service shrinks the same way; at some point you delete it.
The mechanics are simpler than they sound. You put a reverse proxy in front of both services - usually nginx, Envoy, or an API gateway you already have - and shift routes one by one:
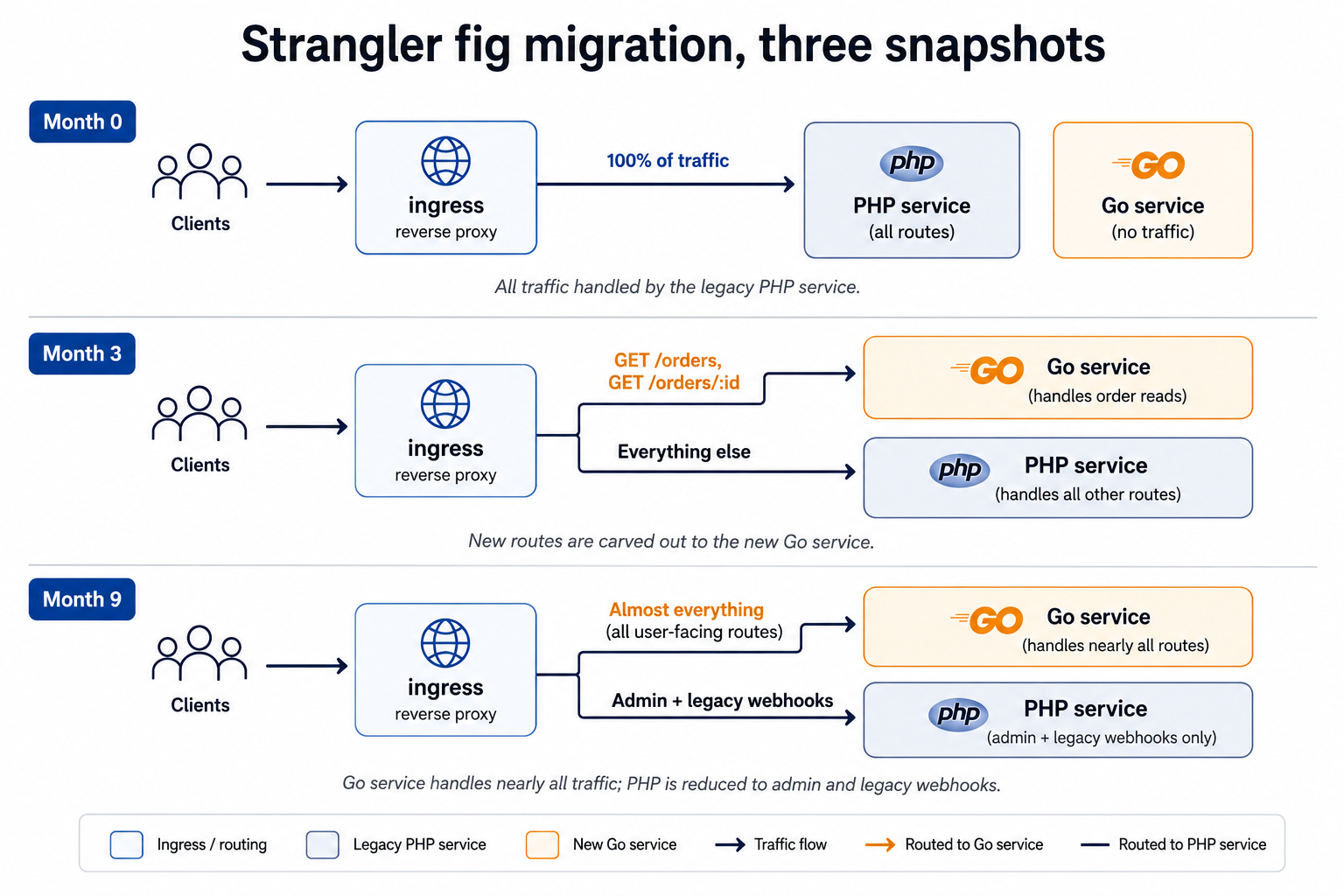
A few patterns that come up in every real migration:
Pick first routes carefully. The best starter route is read-only, idempotent, well-tested, and low-traffic enough that a regression won't take down the business. A GET /healthcheck doesn't count - it's too trivial to teach anything. GET /products/:id is usually a great first migration: it exercises your database access, your JSON serialisation, your auth middleware, and your observability stack, but failure modes are bounded.
Share the database, at least at first. Both services pointing at the same Postgres or MySQL is fine. It's not pretty in a slide deck, but it's the cheapest way to keep both services serving real data without dual writes or eventual-consistency drama. The schema is the schema. Whichever service handles the request reads and writes it.
Wrap legacy calls instead of reimplementing them. When the Go service needs something the PHP service has - sending a templated email, calling a billing helper, hitting an internal endpoint - call it. Don't reimplement. The point of the migration is to move traffic, not to ship a second implementation of every utility. You can replace those bridges later.
// SendInvoiceEmail calls the legacy PHP service for the templated email
// flow. The Go service owns the order, but the email templates and the
// SendGrid integration still live on the PHP side. We can move them
// later; for now we just bridge.
func SendInvoiceEmail(ctx context.Context, orderID string) error {
url := fmt.Sprintf("%s/internal/emails/invoice", os.Getenv("LEGACY_BASE_URL"))
body, _ := json.Marshal(map[string]string{"order_id": orderID})
req, _ := http.NewRequestWithContext(ctx, "POST", url, bytes.NewReader(body))
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer "+os.Getenv("INTERNAL_TOKEN"))
resp, err := http.DefaultClient.Do(req)
if err != nil {
return fmt.Errorf("legacy email bridge: %w", err)
}
defer resp.Body.Close()
if resp.StatusCode >= 300 {
return fmt.Errorf("legacy email bridge: status %d", resp.StatusCode)
}
return nil
}The bridge is ugly. It's supposed to be. Every line of it is a TODO: reimplement in Go that you'll get to after you've moved the routes that matter. The mistake is to treat the bridge as a goal rather than a stepping stone - or, the other mistake, to treat it as so embarrassing that you reimplement the email service before you've finished moving the order endpoints.
Mirror traffic before you switch. For risky routes - anything that writes - point the proxy at the old service for real, and also fire the same request at the new service in the background, comparing responses. You don't return the new service's response to the user. You log the diff. After a week of clean diffs you start trusting the new code. Tools like nginx's mirror directive or a small custom shadow-proxy make this cheap.
Carry the contract, not the code. When you port a route, the goal is byte-for-byte identical responses. Same field names, same ordering when ordering matters, same error codes, same null vs missing field semantics. Resist the urge to "clean up" the response shape during the port. Clients in the wild are coupled to your JSON in ways you don't fully know. Clean up the response in a v2 endpoint later, after the port is done.
Keep the queues shared. If the legacy service publishes to Kafka or pushes to Redis or runs Sidekiq/Bee/whatever, the new Go service joins the same broker rather than building a parallel queue infrastructure. Cross-language message passing is what queues are for. Use it.
Decide what "done" looks like up front. Some teams plan to delete the legacy service completely. Other teams plan to keep it for admin tools, internal scripts, and the long tail of edge cases that aren't worth porting. Both are valid. Not deciding is what kills migrations - the legacy service ends up half-supported, both teams half-own it, and the migration is "in progress" three years later.
When the answer is "don't"
It's worth saying this out loud, because every honest article about a rewrite has to. There are situations where the right call is to keep the PHP or Node service and put the energy elsewhere.
If the service is small, stable, and rarely changed, a rewrite has very little upside. The bugs are known. The performance is good enough. The team is comfortable. Rewriting it in Go for ideological tidiness is a great way to introduce new bugs into something that works.
If the team has no Go experience and no senior engineer to lead the migration, you're not signing up for a rewrite - you're signing up for learning Go in production, which is a different and much riskier project. Hire or train first, then migrate.
If the bottleneck is the database, the network, or a third-party API, the language won't fix it. Run the profiler. If 80% of your latency is SELECT * FROM orders WHERE customer_id = ? with no index, no amount of Go will save you. Add the index.
If the company is in a stage where shipping new features matters more than reducing infrastructure cost or tail latency, the cycles you'd spend on the migration are cycles you're not spending on whatever the business actually needs. The migration is real engineering work. It competes for the same hours.
If you only have one service and it's also where all your engineers live, you're going to give yourself a Conway's Law headache by splitting the team across two stacks before you've split the codebase. Migrate when you have at least one engineer who can fully own the Go side without help, ideally two.
And if the conversation about migrating to Go feels like it's mostly about aesthetics - the new staff engineer's preference, the SRE's irritation, a blog post somebody read on the weekend - park it. Wait until there's a specific operational pain you can point to, and a specific business outcome you expect from the migration. "We want lower p99" is a reason. "Go is just nicer" is not.
None of this is meant to talk you out of it. Go is a great choice for a lot of services, and "we migrated to Go" is one of the most common quietly-successful engineering stories in our industry. The teams that do it well plan the team migration alongside the code migration, ship the strangler instead of the big-bang, port the contract before they port the code, and treat the first six months of awkward Go as a normal cost of business.
The teams that do it badly try to fix everything at once. Don't be those teams. Move one route, then the next one. The harbour gets quieter on its own.





