
In July 2019, someone sent a single crafted HTTP request to a Capital One server. The request asked the server to go fetch a URL on the requester's behalf. The server obliged. The URL was http://169.254.169.254/latest/meta-data/iam/security-credentials/ISRM-WAF-Role, and what came back was a set of live AWS credentials. Those credentials could read the S3 buckets holding 100 million customer records. The fine was $80 million.
There was no zero-day. No memory corruption, no exotic crypto break. It was an app that fetched a URL it shouldn't have: a bug class your Node.js API can ship today in about four lines of code. That's the uncomfortable thing about API security: the breaches that end careers almost never come from the scary stuff. They come from the boring checklist nobody finished.
So let's finish it. Six areas, in the order they actually bite: response headers, input validation, secrets, SSRF, injection, and the observability that catches what the first five miss. This isn't a survey. It's the stuff I'd block a PR over.
Headers: the cheapest security you'll ever skip
Response headers are free defense-in-depth. You set a handful of strings on the way out and the browser enforces a pile of rules for you. And yet most APIs ship with the defaults, which means they ship telling the world X-Powered-By: Express.
The lazy-but-correct move is Helmet. One line and you get roughly fifteen headers configured to sane defaults:
import express from "express";
import helmet from "helmet";
const app = express();
app.use(helmet());Here's what's worth understanding rather than cargo-culting. Helmet's default Content-Security-Policy is genuinely strict:
default-src 'self'; base-uri 'self'; font-src 'self' https: data:;
form-action 'self'; frame-ancestors 'self'; img-src 'self' data:;
object-src 'none'; script-src 'self'; script-src-attr 'none';
style-src 'self' https: 'unsafe-inline'; upgrade-insecure-requestsFor a JSON API that serves no HTML, CSP barely matters: there's no document for a browser to apply it to. But frame-ancestors 'self' is your clickjacking defense, and Strict-Transport-Security: max-age=31536000; includeSubDomains is the one you actually want everywhere, because it tells browsers to never speak plain HTTP to you again.
The counterintuitive bit: Helmet removes X-Powered-By and disables X-XSS-Protection. That second one trips people up. There's an old header called X-XSS-Protection that sounds like exactly what you want, and Helmet sets it to 0. That's deliberate. The legacy XSS auditor it controlled was buggy enough that it introduced vulnerabilities of its own, so every major browser dropped it and the correct value today is "off." If a scanner dings you for "missing XSS protection header," the scanner is wrong.
Validation: parse, don't trust
Every value that crosses your network boundary is hostile until proven otherwise. Not "probably fine because the frontend sends the right shape." The frontend is a suggestion, and curl doesn't read your TypeScript types.
The modern Node approach is schema validation at the edge with something like Zod. The point isn't just rejecting bad data; it's that you parse untrusted input into a known-good typed value, and everything downstream gets to assume it's clean:
import { z } from "zod";
const TransferSchema = z.object({
toAccount: z.string().regex(/^\d{10}$/),
amountCents: z.number().int().positive().max(1_000_000_00),
memo: z.string().max(140).optional(),
});
app.post("/transfer", (req, res) => {
const parsed = TransferSchema.safeParse(req.body);
if (!parsed.success) {
return res.status(400).json({ error: "Invalid request" });
}
// parsed.data is fully typed and bounded from here down.
return doTransfer(parsed.data);
});Notice the .max() calls. They're not type checks; they're abuse limits. A limit query param without an upper bound is an invitation to ?limit=99999999 and a query that scans your whole table. A LIKE filter without a length cap is a CPU sink. Validation isn't only about type; it's about plausible range, and the range is where the denial-of-service bugs hide.
One trap worth naming: validation does not replace parameterized queries. They solve different problems. A value can be a perfectly valid string that's also '; DROP TABLE users; --. Validation narrows the attack surface and stops nonsense early; parameterization is what actually neutralizes injection. You want both, and reaching for one because you did the other is how people get burned.
Secrets: process.env is a shared room
Here's a fact that surprises people: when you load a secret into process.env, you've made it readable by every package in your dependency tree. Not just your code: every transitive dependency, all the way down. process.env is a global object. The analytics library you added last sprint, and its forty dependencies, can all read your database password and your Stripe key. Most won't. You're trusting that none of them (or none of the people who can publish updates to them) ever will.
That reframes the .env conversation. The usual advice ("don't commit .env to git") is table stakes, and you should absolutely gitignore it and scan your history. But the deeper issue is that dotenv is a loader, not a vault. It reads a file into the global free-for-all and walks away.
What good looks like in production:
import { z } from "zod";
// Validate at startup — crash loudly if a secret is missing,
// rather than discovering it at 2am when a request needs it.
const Env = z.object({
DATABASE_URL: z.string().url(),
JWT_SECRET: z.string().min(32),
STRIPE_KEY: z.string().startsWith("sk_"),
});
const env = Env.parse(process.env);
// Hand modules the one secret they need — not the whole process.env.
export const config = Object.freeze({
db: { url: env.DATABASE_URL },
});The pattern: validate every secret on boot so a misconfigured deploy fails immediately and visibly. Then stop passing process.env around. Hand each module the specific config it needs and freeze it, so a compromised dependency can't trivially enumerate the rest.
For anything past a hobby project, graduate off files entirely. Platform-injected env vars are fine to start; move to AWS Secrets Manager, HashiCorp Vault, or Doppler when you need rotation, access logging, and the ability to revoke a leaked credential without a redeploy. The bootstrapping exception is real and narrow: a single short-lived token in an env var, used once to authenticate to the secret store, is an acceptable seam.
SSRF: the bug that read Capital One's S3
Back to the opener. Server-Side Request Forgery is what happens when your server makes an outbound HTTP request to a URL the user influenced. Webhook registration, "import from URL," fetching a user's avatar from a link, an image proxy: all of these are SSRF waiting to happen.
The naive version:
// DANGEROUS — do not ship.
app.post("/import-avatar", async (req, res) => {
const img = await fetch(req.body.url); // user controls the URL
res.type("image/png").send(Buffer.from(await img.arrayBuffer()));
});An attacker doesn't point that at an image. They point it at http://169.254.169.254/latest/meta-data/, the cloud instance metadata service, a magic link-local IP that, on AWS's old IMDSv1, hands back IAM credentials to anything that asks, with no authentication. That's the exact door Capital One left open. Internal admin panels, localhost databases, and Kubernetes service endpoints are all reachable the same way.
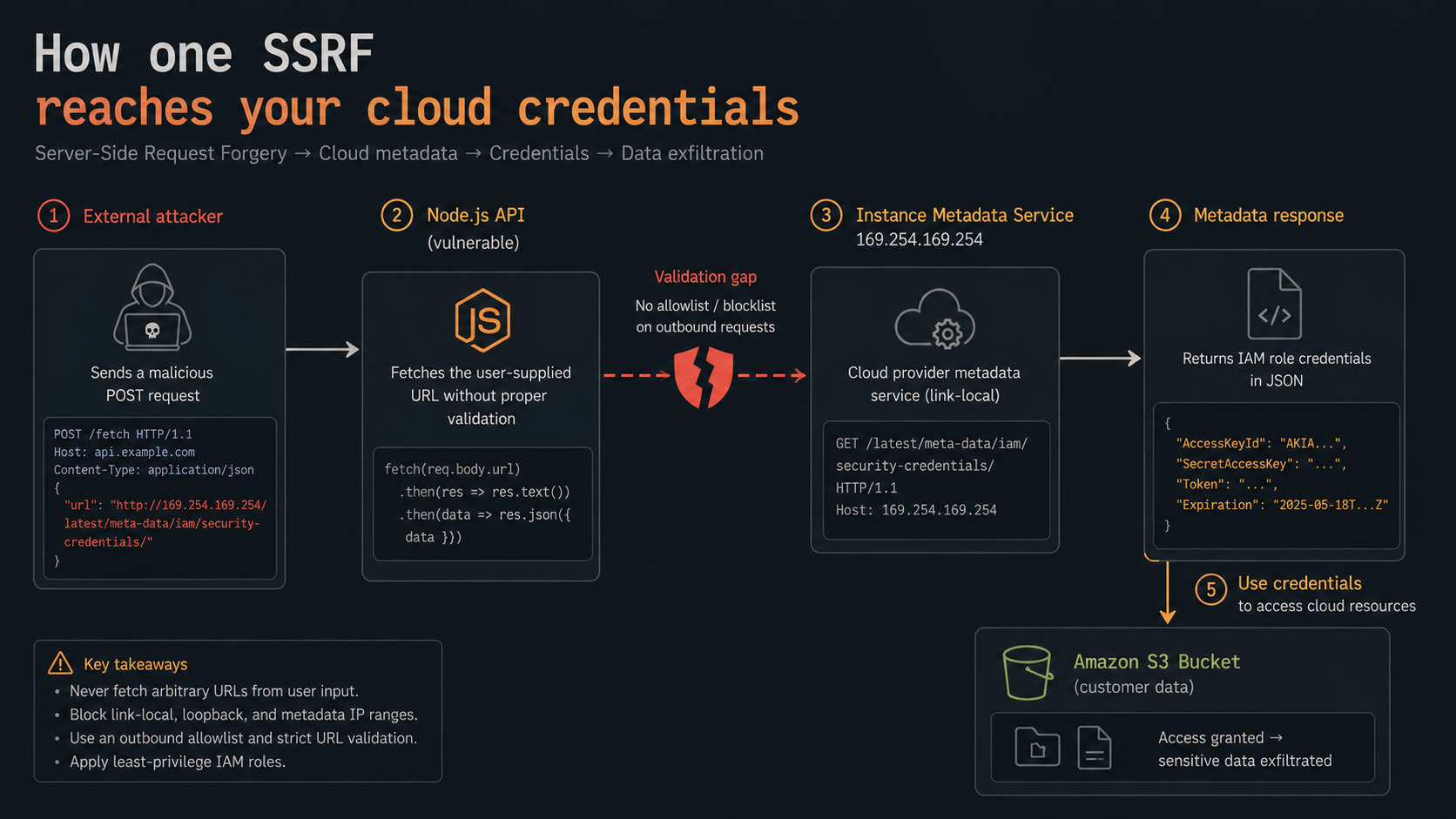
Why is SSRF so hard to kill? Because the obvious defenses don't work:
- Blocklists and regex fail. You cannot reliably parse a URL with a regex, and attackers have a deep bag of tricks:
http://0x7f000001/(hex localhost),http://[::1]/, decimal IP encoding,http://localhost.attacker.comresolving to a private IP, redirect chains that start public and end internal. - Validate-then-fetch has a TOCTOU hole called DNS rebinding. You resolve
evil.com, see a public IP, approve it, and in the gap beforefetchruns, the attacker's DNS server (with a 0-second TTL) flips the record to169.254.169.254. You validated one IP and connected to another.
The defense that actually holds is to validate at connection time, not parse time. Resolve the hostname yourself, check every resulting IP against the private/reserved/link-local ranges, and pin the connection to a vetted IP so the value can't change underneath you. This is fiddly enough that you should lean on a maintained library. request-filtering-agent gives you an http.Agent that blocks private and reserved ranges after DNS resolution:
import { useAgent } from "request-filtering-agent";
async function safeFetch(url) {
return fetch(url, {
// Blocks the connection if the resolved IP is private/reserved.
agent: useAgent(url),
redirect: "manual", // re-validate every hop yourself; don't auto-follow.
});
}And do the cloud-side half too: enforce IMDSv2, which requires a session token fetched via a PUT before any GET works, and that alone defeats simple GET-only SSRF. AWS shipped it in November 2019, four months after the breach. The sobering part: as of late 2024, only about a third of EC2 instances had actually migrated. The fix has existed for years; most fleets just haven't turned it on.
Injection: parameterize everything, concatenate nothing
Injection is the oldest bug in the book and it's still on every top-ten list, because the unsafe version reads so naturally. You have a value, you have a query, you glue them together:
// DANGEROUS — string concatenation into SQL.
const rows = await db.query(
`SELECT * FROM users WHERE email = '${req.query.email}'`
);Feed that an email of ' OR '1'='1, and the WHERE clause is now always true. Feed it something nastier and you're exfiltrating the table. The fix is parameterized queries: you hand the driver the query shape and the values separately, and the driver guarantees the values are never interpreted as SQL:
// SAFE — values bound as parameters, never parsed as SQL.
const rows = await db.query(
"SELECT * FROM users WHERE email = $1",
[req.query.email]
);Drivers like pg and mysql2 support this directly, and ORMs like Prisma, Drizzle, and Sequelize do it for you under the hood, which is most of the reason to use them. The trap is the escape hatch: every ORM has a raw() method, and the moment you build a raw query with template-literal interpolation, you've opted back into the unsafe world. Audit your raw, $queryRawUnsafe, and sequelize.query calls specifically; that's where injection survives in codebases that "use an ORM."
And it's not only SQL. The same disease shows up as:
- NoSQL injection: MongoDB will happily accept an object where you expected a string. If
req.body.usernamecomes in as{ "$ne": null }, a query likeUser.findOne({ username: req.body.username })matches the first user in the collection. This is exactly why the validation section mattered:z.string()would have rejected the object before it ever reached Mongo. - Command injection:
child_process.exec("convert " + filename)with a filename ofx.png; rm -rf /runs both commands. UseexecFile(orspawn) with an args array, which never invokes a shell, instead ofexecwith a concatenated string.
The unifying rule across all of them: never build an interpreted string by gluing in untrusted input. Pass data as data (bound parameters, args arrays, typed values), and the interpreter has nothing to misinterpret.
Observability: you can't defend what you can't see
The first five sections are prevention. This one is the admission that prevention isn't perfect. Something will get through, or someone will probe you for weeks before they find it, and the question that matters at 3am is: can you see it, and can you reconstruct what happened?
Structured logging is the foundation. Swap console.log for Pino, which emits JSON your log pipeline can actually query and does it fast, on the order of tens of thousands of lines a second with low overhead, because it offloads serialization to a worker thread. The security-critical feature is built-in redaction:
import pino from "pino";
export const logger = pino({
redact: {
paths: [
"req.headers.authorization",
"req.headers.cookie",
'req.body.password',
'req.body.token',
"*.creditCard",
],
censor: "[REDACTED]",
},
});Without that redact block, the first time you log a request object for debugging, you've written every user's bearer token and password to disk, and now your logs are the breach. Redaction isn't a nice-to-have; it's the difference between an audit log and a liability.
A few things worth logging deliberately, not by accident:
- A correlation/request ID per request, generated at the edge and threaded through every downstream call and log line. When you're tracing an attack, "show me everything that happened in request
a1b2c3" is the query that saves the night. Pino child loggers make this clean: attachrequestIdanduserIdonce and every line inherits it. - Authentication and authorization events: logins, failures, permission denials, password changes. A spike of 401s from one IP is reconnaissance; you only see it if you logged it.
- Rate-limit hits. Put a limiter in front of auth and expensive endpoints (
express-rate-limitor a Redis-backed one for multi-instance deploys), and log when it trips. Credential-stuffing and scraping show up here first.
The mindset shift: logs aren't just for debugging your own bugs. They're the evidence trail for someone else's attack, and the redaction policy is what keeps that trail from becoming the leak itself.
The checklist, condensed
If you skim back over the six areas, none of it is exotic. That's the point, and the trap. Each one is an afternoon of work that's trivially easy to defer past launch, and every breach in this article came from exactly that deferral.
So before the next deploy: Helmet's on, with HSTS. Every input is parsed and bounded at the edge, not trusted. Secrets are validated at boot and kept out of the global junk drawer. Outbound fetches from user-supplied URLs go through a filtering agent, and IMDSv2 is enforced. Queries are parameterized end to end, raw() calls audited. And logs are structured, redacted, and carry a request ID.
Capital One had a security team, a budget, and a SOC. What they didn't have was a server that refused to fetch 169.254.169.254. Four lines. The checklist is cheap; not finishing it is what's expensive.





