
You're starting a new React app, the first list view needs data from an API, and someone in the chat asks the question that has been asked in every React project for the last five years: "RTK Query or React Query?" You open both docs in side-by-side tabs, they look almost identical at the surface, useGetThingQuery here, useQuery there, both promise caching, invalidation, refetching, devtools, and the choice starts to feel like a personality test rather than a technical decision.
Here's the thing: it's not a personality test, and it's not a "which one is better" debate. RTK Query and React Query (now called TanStack Query) are two libraries that solve the same surface-level problem, cache server state for a React app, but they solve it with completely different assumptions about the rest of your stack. The right answer almost always falls out of one question: what does the rest of your app look like? Let's walk through what each one actually optimises for, and what kind of project each one is quietly assuming you have.
They're both solving server state, not client state
Before getting into the differences, it's worth saying out loud what they have in common, because skipping this step is how people end up choosing one for the wrong reason.
Both libraries exist because server state is not client state. Your form's isOpen boolean, your filter selections, the current step of a wizard, that's client state. It's owned by the UI, it changes when the user interacts, and useState or useReducer handles it fine. Server state is everything that lives behind an API: the list of users, the current invoice, the search results. It's remote, asynchronous, possibly stale the moment you fetch it, and shared between multiple parts of the UI. Trying to manage it with useState (and a stack of useEffect calls to refetch and dedupe) is what every junior backend-leaning React project does first, and it's also where every one of them eventually breaks.
Both RTK Query and React Query encode the same set of answers for server state:
- A cache keyed by a query identifier, so two components asking for the same thing share one fetch.
- Stale-while-revalidate, show the cached data immediately, refetch in the background, update when the new data arrives.
- Loading and error states as first-class hook return values, not booleans you have to wire up yourself.
- Refetch on focus, on reconnect, on interval, out of the box.
- Mutations with a path to invalidate the affected queries.
- Optimistic updates for the cases where you can predict the server's response.
- Devtools that let you see what's in the cache, what's stale, and what's currently fetching.
If you only need that list, both libraries will give it to you, and the project will be fine either way. The decision is about everything around that list, where the cache lives, how it integrates with the rest of your state, how you describe relationships between data, and what your team already knows.
RTK Query: server state inside Redux
RTK Query ships as part of Redux Toolkit, and it leans into that fact harder than most people realise the first time they use it. The cache it builds is not a separate object hidden somewhere: it's a slice of your Redux store. You can open the Redux DevTools, expand the slice, and watch every fetched query sit there next to the rest of your app state, with a status (pending, fulfilled, rejected), a subscription count, and the data itself. Time-travel debugging works on it. Redux middleware sees it. Persistence libraries like redux-persist can include or exclude it. Whether you wanted those properties or not, they come with the package.
The API surface is also a little different than the React Query model people are used to. You define an API slice with a list of endpoints, and the library generates hooks for you:
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react';
export interface User {
id: number;
name: string;
email: string;
}
export const usersApi = createApi({
reducerPath: 'usersApi',
baseQuery: fetchBaseQuery({ baseUrl: '/api' }),
tagTypes: ['User'],
endpoints: (build) => ({
getUsers: build.query<User[], void>({
query: () => '/users',
providesTags: (result) =>
result
? [
...result.map(({ id }) => ({ type: 'User' as const, id })),
{ type: 'User', id: 'LIST' },
]
: [{ type: 'User', id: 'LIST' }],
}),
getUser: build.query<User, number>({
query: (id) => `/users/${id}`,
providesTags: (_r, _e, id) => [{ type: 'User', id }],
}),
addUser: build.mutation<User, Partial<User>>({
query: (body) => ({ url: '/users', method: 'POST', body }),
invalidatesTags: [{ type: 'User', id: 'LIST' }],
}),
}),
});
export const { useGetUsersQuery, useGetUserQuery, useAddUserMutation } = usersApi;A few things to notice. The endpoints are declared in one place, not scattered across component files. Each query knows what tags it provides and each mutation knows what tags it invalidates. The hook names are generated from the endpoint names, you don't pick queryKey arrays at each call site. And the whole thing plugs into the Redux store like any other slice:
import { configureStore } from '@reduxjs/toolkit';
import { setupListeners } from '@reduxjs/toolkit/query';
import { usersApi } from './services/usersApi';
export const store = configureStore({
reducer: {
[usersApi.reducerPath]: usersApi.reducer,
// ...your other slices
},
middleware: (gDM) => gDM().concat(usersApi.middleware),
});
setupListeners(store.dispatch);Component usage looks like the React Query version, just with generated hook names:
import { useGetUsersQuery, useAddUserMutation } from '../services/usersApi';
export function UserList() {
const { data: users, isLoading, error } = useGetUsersQuery();
const [addUser, { isLoading: adding }] = useAddUserMutation();
if (isLoading) return <p>Loading...</p>;
if (error) return <p>Something went wrong.</p>;
return (
<div>
<ul>{users?.map((u) => <li key={u.id}>{u.name}</li>)}</ul>
<button
onClick={() => addUser({ name: 'New User', email: 'new@example.com' })}
disabled={adding}
>
Add user
</button>
</div>
);
}The hidden cost (and the hidden benefit, depending on where you sit) is that you're now committed to Redux Toolkit. You have a store, middleware, a provider at the root of the tree, and the mental model that comes with it. If you weren't planning to use Redux for anything else, this is a lot of ceremony for cache management.
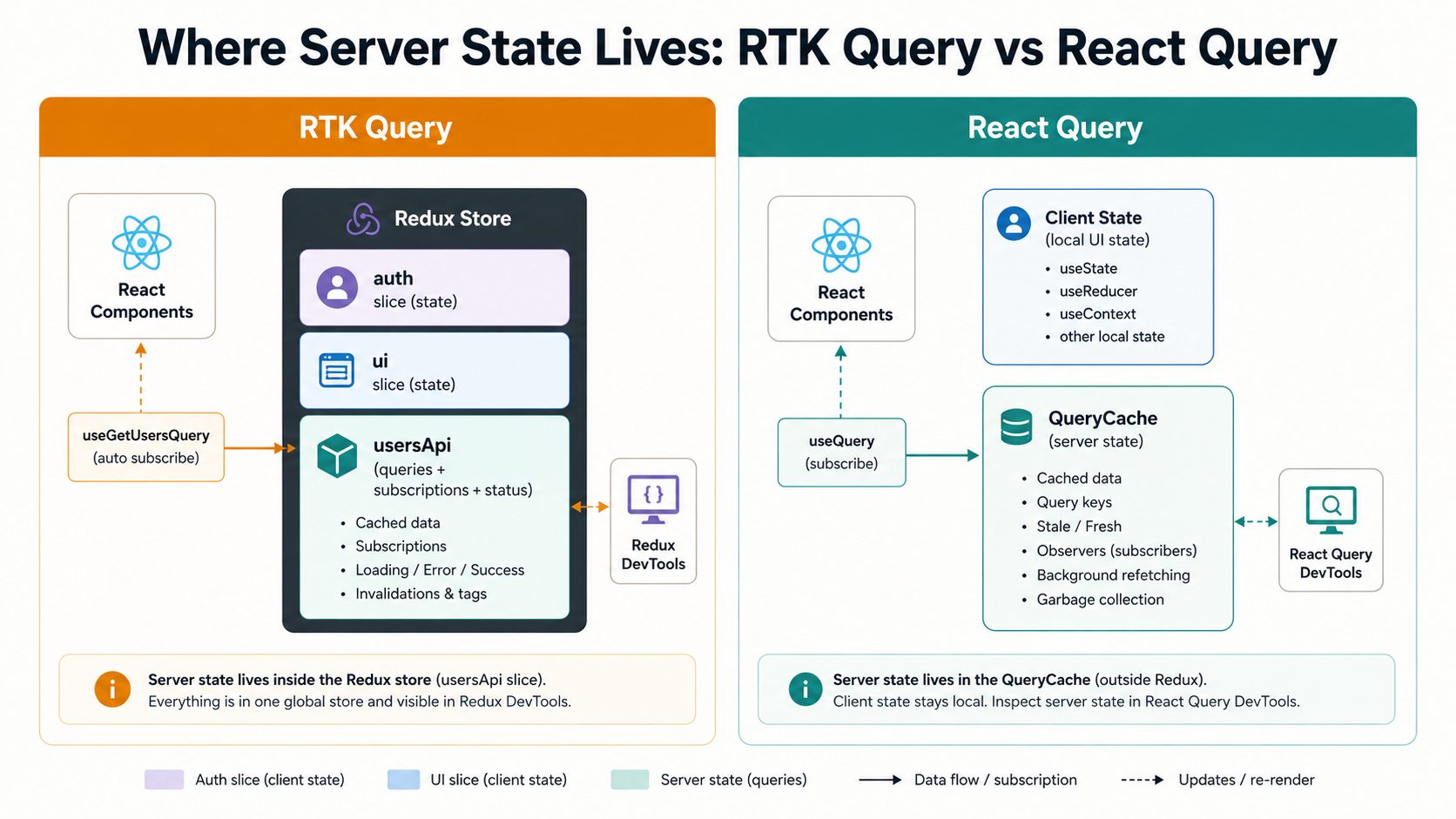
React Query: server state in its own world
React Query, or TanStack Query, since v4, takes the opposite position. It owns its own cache, called the QueryCache, and that cache has nothing to do with Redux, Zustand, Jotai, or whatever else you're using for client state. You wrap your app in a QueryClientProvider, and from then on every useQuery call talks to the client directly:
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
import { ReactQueryDevtools } from '@tanstack/react-query-devtools';
const queryClient = new QueryClient({
defaultOptions: {
queries: { staleTime: 30_000 },
},
});
createRoot(document.getElementById('root')!).render(
<QueryClientProvider client={queryClient}>
<App />
<ReactQueryDevtools />
</QueryClientProvider>,
);The hooks are written at the call site, with the data-fetching function inline:
import { useQuery, useMutation, useQueryClient } from '@tanstack/react-query';
async function fetchUsers(): Promise<User[]> {
const res = await fetch('/api/users');
if (!res.ok) throw new Error('Failed to load users');
return res.json();
}
export function UserList() {
const queryClient = useQueryClient();
const { data: users, isLoading, error } = useQuery({
queryKey: ['users'],
queryFn: fetchUsers,
});
const addUser = useMutation({
mutationFn: async (body: Partial<User>) => {
const res = await fetch('/api/users', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(body),
});
if (!res.ok) throw new Error('Failed to add user');
return res.json() as Promise<User>;
},
onSuccess: () => {
queryClient.invalidateQueries({ queryKey: ['users'] });
},
});
if (isLoading) return <p>Loading...</p>;
if (error) return <p>Something went wrong.</p>;
return (
<div>
<ul>{users?.map((u) => <li key={u.id}>{u.name}</li>)}</ul>
<button
onClick={() => addUser.mutate({ name: 'New User', email: 'new@example.com' })}
disabled={addUser.isPending}
>
Add user
</button>
</div>
);
}Notice what's different. The queryKey is an inline array, there's no central declaration. The queryFn is just a function you wrote, using whatever HTTP client you like, fetch, axios, a typed client from openapi-fetch, a GraphQL request. Invalidation is imperative: after a mutation succeeds, you tell the client which keys to invalidate, and the matching queries refetch.
There's no store. There's no reducer. There's no middleware. There's a QueryClient instance with a QueryCache and a MutationCache inside it, and it lives in memory for as long as the provider is mounted. If you don't already use Redux, you don't need to start.
That's the trade. RTK Query says "your server state is just another slice". React Query says "your server state is its own thing, with its own home". Both are coherent positions. Which one fits depends entirely on the rest of your application.
Invalidation: tags vs query keys
The single biggest day-to-day difference in how you actually write code with these libraries is the invalidation model, and it's the place where the philosophical split shows up most clearly in practice.
RTK Query uses a tag system. Each query declares the tags it provides, each mutation declares the tags it invalidates. You define a relationship once, in the endpoint declaration, and the library handles the rest:
getUsers: build.query<User[], void>({
query: () => '/users',
providesTags: [{ type: 'User', id: 'LIST' }],
}),
addUser: build.mutation<User, Partial<User>>({
query: (body) => ({ url: '/users', method: 'POST', body }),
invalidatesTags: [{ type: 'User', id: 'LIST' }], // refetches getUsers
}),
deleteUser: build.mutation<void, number>({
query: (id) => ({ url: `/users/${id}`, method: 'DELETE' }),
invalidatesTags: (_r, _e, id) => [
{ type: 'User', id }, // any query that providesTags for this user
{ type: 'User', id: 'LIST' }, // and the list
],
}),You never write "after this mutation, refetch this list" at the call site. The wiring is declared once, and the call site is clean. Adding a new mutation just means thinking about which tags it should invalidate. That's powerful when you have a lot of cross-entity relationships, because you describe them at the schema level, not at the component level.
React Query uses query keys directly, and invalidation is imperative, you call queryClient.invalidateQueries({ queryKey: ['users'] }) from your mutation's onSuccess (or wherever it makes sense). The matching against query keys is prefix-based, which is more powerful than it sounds:
// Invalidate everything users-related — list, detail, by-team, by-role.
queryClient.invalidateQueries({ queryKey: ['users'] });
// Invalidate just one specific user.
queryClient.invalidateQueries({ queryKey: ['users', userId] });
// Invalidate every list view, regardless of filters.
queryClient.invalidateQueries({ queryKey: ['users', 'list'] });The mental model is "keys are paths into a hierarchy". As long as you're disciplined about structuring keys (['users'], ['users', id], ['users', 'list', filters], ['posts', 'by-user', userId]), invalidation falls out naturally. The cost is that the discipline lives in your team's head, not in a declaration the linter can check.
The Redux question, asked plainly
If you boil all the above down, RTK Query is making a bet: you are either already using Redux, or you're about to. Everything in the library is more pleasant if that's true, and more friction if it isn't. Conversely, React Query is making the bet that server state caching shouldn't drag a state management library into your app to begin with.
So the question you should ask yourself, honestly, is: does this app actually need Redux for anything else?
Not "would Redux be nice to have someday". Not "Redux is industry standard". The question is whether you have client state that genuinely benefits from a central store with reducers, middleware, and time-travel, multi-step wizards that need to be paused and resumed, complex undo/redo, cross-cutting concerns that touch many slices, a shared cart-like object updated from twelve different components. If yes, RTK Query becomes one less library to add, you're already paying the Redux tax, may as well get caching for free.
If your client state is mostly "this dropdown is open" and "this is the current tab", and you'd be reaching for useState or a small Zustand store anyway, then React Query is the lighter answer. You won't miss what Redux brings. You'll get a smaller bundle, a smaller learning surface, and one less provider at the root of your tree.
This isn't a moral judgement. It's a question about what the rest of your stack already commits to. The library is downstream of that decision, not the other way around.
Things that actually differ in practice
Beyond the philosophy, a few practical bullets that come up once you start using each library seriously.
Hook generation. RTK Query generates hooks from your endpoint definitions, including TypeScript types for arguments and responses. If you have an OpenAPI spec, the official @rtk-query/codegen-openapi package can generate the entire API slice for you. With React Query, you write each useQuery call manually, though tools like openapi-fetch + openapi-typescript give you typed fetchers that you can then plug into queryFn. The end result is similar, typed, autocompleted hooks, but the route there is different.
Polling, prefetching, infinite queries. Both libraries support polling, prefetching, and paginated / infinite queries. The APIs look different in detail (pollingInterval on an RTK Query hook vs refetchInterval in React Query options), but the capability is there in both. If a tutorial says "library X can do Y and library Z can't", double-check, there's usually a parallel API in the other one.
Framework reach. TanStack Query is intentionally not React-only. It has first-class adapters for Solid, Vue, and Svelte under the same TanStack Query umbrella, with shared concepts. RTK Query is React + Redux, primarily; the core is framework-agnostic in theory but the ergonomic story is React. If your company has multiple frontends in multiple frameworks and you want one cache mental model across them, that's a thumb on the scale.
Bundle size. Both libraries ship a few tens of kilobytes minified-and-gzipped, and exact numbers shift between versions, so don't pick on bundle size alone. The bigger size question is whether you're also importing Redux Toolkit just to get RTK Query. If the rest of your store would otherwise be empty, that's the cost that matters.
SSR and frameworks like Next.js. React Query has well-trodden patterns for Next.js, hydrating from server-fetched data, prefetching in server components, working with the App Router. RTK Query also supports SSR, but the integration is heavier because you're also threading the Redux store through. If your project is Next.js-first and you're not otherwise using Redux, React Query tends to be the smoother fit.
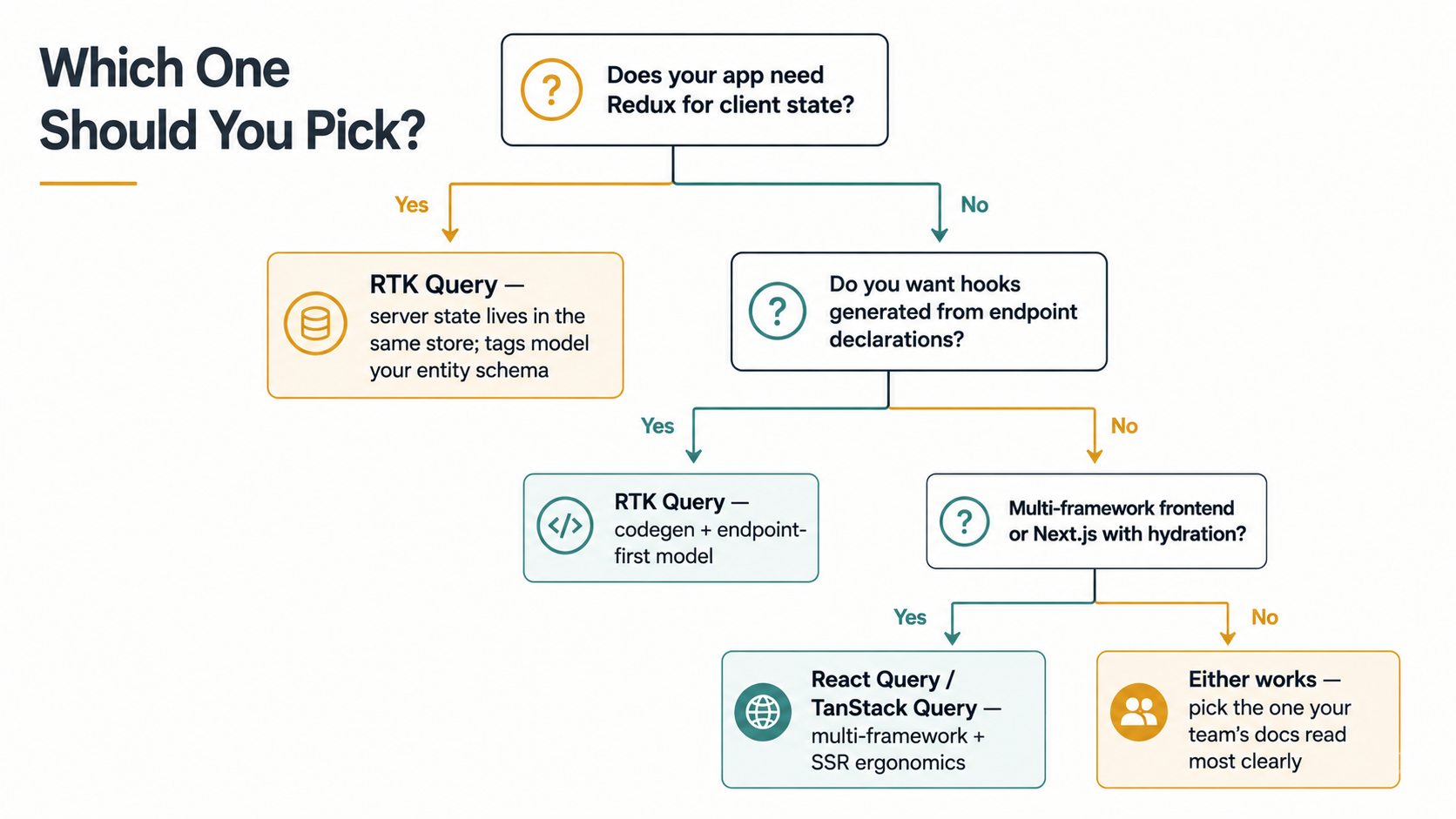
The decision in two sentences
If your app already uses Redux for state your reducers and middleware actually care about, RTK Query is almost certainly the right call: the cache is in the place you're already looking, and the tag model maps cleanly to your entity schema. If your app doesn't need Redux for anything else, React Query gives you the same server-state ergonomics with a smaller surface and a cache that doesn't pretend to be part of your application state.
Everything else, bundle size by a few KB, exactly which hook is shorter, whose devtools you prefer, is noise compared to that one question. Answer it honestly, and the rest of the choice answers itself.





