
You're starting a new Go service. You need a database layer. The familiar fork in the road shows up almost immediately.
Reach for an ORM, and you get types and migrations for free, but you also get a query builder, lazy loading, soft N+1s, and a runtime that decides at the last minute what SQL to send. Roll your own with database/sql, and you keep full control of the SQL, but every query is Rows, Scan, nil pointers, three error checks, and a slow march toward a hand-grown repository layer that looks suspiciously like a worse version of GORM.
sqlc is the third option, and it picks neither side.
You write the SQL yourself, in real .sql files. sqlc reads them, type-checks them against your schema, and generates the Go code that runs them. The queries are owned by the repo, not by a builder. The types are correct because the generator looked at the columns. There is no engine to debug at 2am, because there is no engine: just compiled Go that does exactly what your SQL says.
That sounds underwhelming. It is the point.
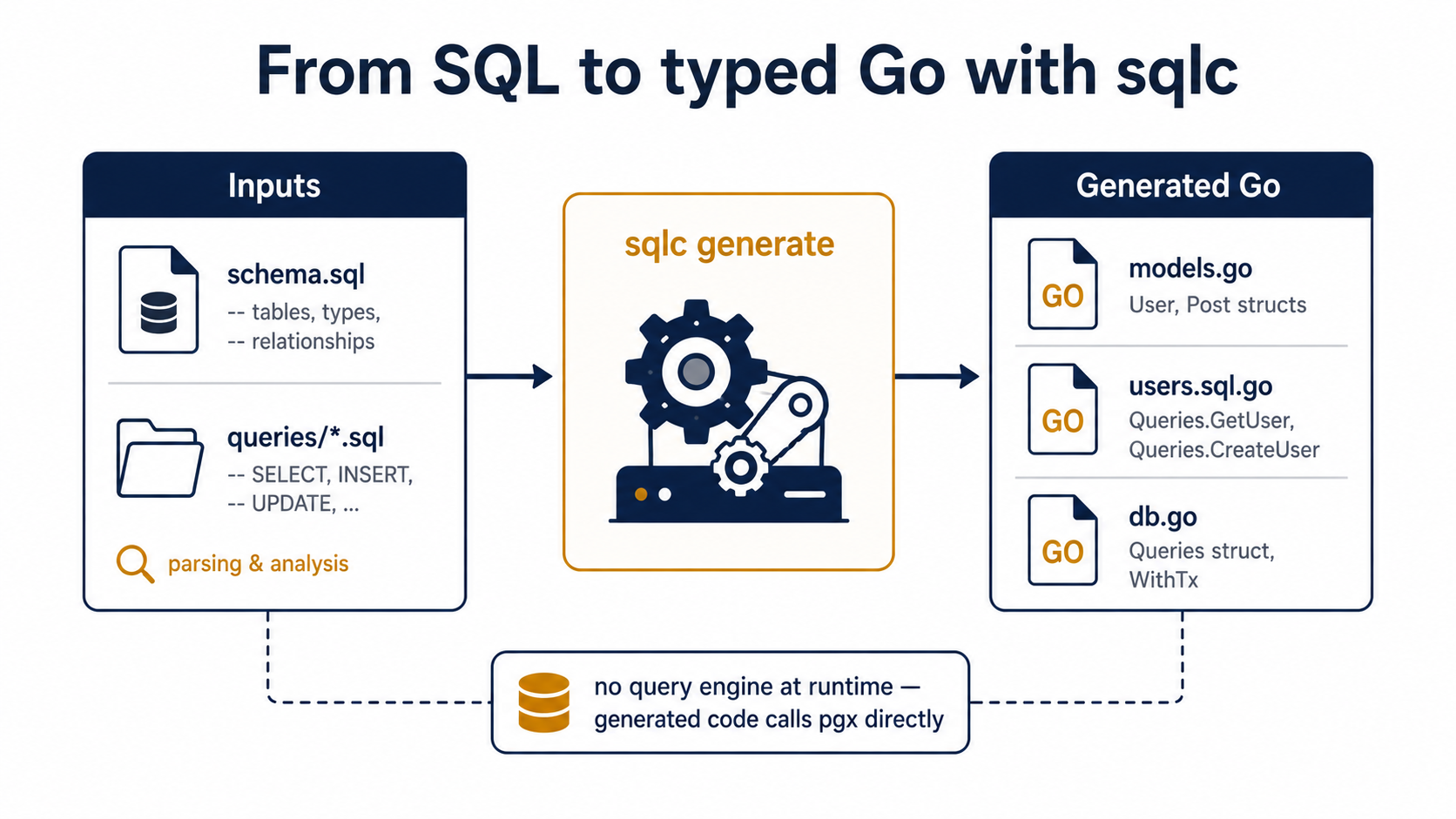
What sqlc actually does
sqlc is a code generator. You give it two things:
- A schema, usually one or more migration files, or a single
schema.sql. - A queries file (or many) with named SQL statements.
You run sqlc generate, and it writes Go files into a package you nominate. From then on, the rest of your code talks to those generated functions, not to database/sql directly.
Here's a tiny shape of it. The schema:
CREATE TABLE users (
id BIGSERIAL PRIMARY KEY,
email TEXT NOT NULL UNIQUE,
full_name TEXT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE TABLE posts (
id BIGSERIAL PRIMARY KEY,
author_id BIGINT NOT NULL REFERENCES users(id),
title TEXT NOT NULL,
body TEXT NOT NULL,
published BOOLEAN NOT NULL DEFAULT FALSE,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);The queries:
-- name: GetUser :one
SELECT id, email, full_name, created_at
FROM users
WHERE id = $1;
-- name: ListRecentUsers :many
SELECT id, email, full_name, created_at
FROM users
ORDER BY created_at DESC
LIMIT $1;
-- name: CreateUser :one
INSERT INTO users (email, full_name)
VALUES ($1, $2)
RETURNING id, email, full_name, created_at;
-- name: DeleteUser :exec
DELETE FROM users WHERE id = $1;The -- name: GetUser :one line is the only magic in the file, and it isn't much magic. :one means return one row, :many means return a slice, :exec means no rows, just an error. There are a few more annotations (:execrows, :execresult, :batchexec, :copyfrom) but you can go a long way knowing just those three.
The sqlc.yaml config at the repo root wires the pieces together:
version: "2"
sql:
- engine: "postgresql"
queries: "db/queries"
schema: "db/schema.sql"
gen:
go:
package: "db"
out: "internal/db"
sql_package: "pgx/v5"Run sqlc generate, and internal/db/ fills with Go files. That directory is now under version control and part of your build. The generator produces idempotent output, so two developers running sqlc generate on the same inputs get byte-identical code.
What the generated code looks like
This is the part that wins people over. sqlc doesn't generate a query builder. It generates the exact function you'd write by hand if you had infinite patience.
For the queries above, the relevant bits look roughly like this (trimmed for clarity):
type User struct {
ID int64
Email string
FullName string
CreatedAt time.Time
}const getUser = `-- name: GetUser :one
SELECT id, email, full_name, created_at
FROM users
WHERE id = $1
`
func (q *Queries) GetUser(ctx context.Context, id int64) (User, error) {
row := q.db.QueryRow(ctx, getUser, id)
var i User
err := row.Scan(&i.ID, &i.Email, &i.FullName, &i.CreatedAt)
return i, err
}
const createUser = `-- name: CreateUser :one
INSERT INTO users (email, full_name)
VALUES ($1, $2)
RETURNING id, email, full_name, created_at
`
type CreateUserParams struct {
Email string
FullName string
}
func (q *Queries) CreateUser(ctx context.Context, arg CreateUserParams) (User, error) {
row := q.db.QueryRow(ctx, createUser, arg.Email, arg.FullName)
var i User
err := row.Scan(&i.ID, &i.Email, &i.FullName, &i.CreatedAt)
return i, err
}Read that and notice what isn't there. No reflection. No interface{}. No tag-based scanning. No prepared statement cache hidden inside a driver wrapper you can't see. The SQL string lives right next to the function that runs it, so a stack trace that lands in GetUser points you at the exact statement you'd run in psql if you wanted to reproduce it.
The Queries struct itself is a tiny thing:
type Queries struct {
db DBTX
}
func New(db DBTX) *Queries {
return &Queries{db: db}
}
// WithTx returns a Queries bound to a transaction.
func (q *Queries) WithTx(tx pgx.Tx) *Queries {
return &Queries{db: tx}
}DBTX is an interface satisfied by both *pgxpool.Pool and pgx.Tx, which is how you get transactions: open one with the pool, call q.WithTx(tx), and every method on the returned *Queries runs inside that transaction. Same code path, different db. No global state, no context magic, no "ambient" transaction problem.
The schema is the source of truth, not the Go code
Most ORMs in Go ask you to describe the schema twice: once in migration files for the database to know about, once in Go struct tags for the ORM to know about. The two drift, and the drift causes bugs that don't surface until production.
sqlc inverts this. The schema is only declared in SQL, and the Go code is generated from it. If you add a column to users, you change one place: the migration. Next sqlc generate run, the User struct grows the field. You can't forget to update the Go side, because the Go side isn't written by hand.
This has a knock-on effect that's worth pausing on. If you delete a column, every query that referenced it stops generating, and your build breaks at the spot in your Go code that used that field. The compiler becomes the migration auditor. You can't "accidentally still be reading legacy_status" three months after the column was dropped. Your service won't compile.
Try doing that with an ORM that uses runtime tag scanning.
Migrations live elsewhere, and that's a feature
The first question every team asks about sqlc, usually within an hour, is "how do I run migrations?" The answer is: you don't, not with sqlc. sqlc reads migration files to understand the schema. It does not apply them.
That's a feature, not a missing piece. Migrations are an operational concern: they touch CI, they touch deploy hooks, they need rollback strategies. A code generator should not be in that loop. So you pick a real migration tool and pair it with sqlc:
- goose: Go-native, embedded migrations, simple.
- golang-migrate: CLI-first, polyglot, good for non-Go teams.
- Atlas: schema-first, declarative, integrates well if you want diff-based migrations.
- dbmate: language-agnostic, single binary, friendly to ops.
Pick one. Point sqlc at the same migration directory, and the schema sqlc sees is exactly the schema your migration tool applies. A typical layout:
db/
migrations/
20240101000000_create_users.up.sql
20240101000000_create_users.down.sql
20240105000000_create_posts.up.sql
20240105000000_create_posts.down.sql
queries/
users.sql
posts.sql
sqlc.yamlThen sqlc.yaml points at the migrations directory:
schema: "db/migrations"
queries: "db/queries"sqlc parses the migrations in order, ignoring down files by default, and that gives it a complete picture of the schema. Add a migration, run it with goose, then run sqlc generate. The generated code now sees the new column.
The reason this matters is that you stop having two source-of-truth files for the schema. The migrations are it. Your ORM struct tags aren't telling a second, slightly-different story.
Query ownership
Here's the part that takes the longest to appreciate.
When queries live inside a Go file as a chain of builder calls, nobody owns them. They're scattered through the service layer, mixed in with business logic, half-built dynamically. You can't grep for a query. You can't run one against staging. You can't have your DBA look at the slow ones. You can't review them as a unit, because there's no unit to review.
When queries live in .sql files, they become files. Real files. Files that:
- show up in
git blame, so you can ask why a query was written that way two years ago, - get reviewed in a PR like any other change to the system,
- can be pasted directly into
psqlorEXPLAIN ANALYZEbecause they are the SQL that ships, - can be searched, refactored, batch-renamed,
- become a thing the database engineer on your team can read without learning Go.
That last point matters more than people give it credit for. SQL is a portable, ancient, well-understood language. It outlasts your ORM. If a DBA joins your team and asks "show me the queries this service runs against the orders table", the answer with sqlc is "grep -r 'FROM orders' db/queries/". With most ORMs, the answer is "well, let me show you the part of the codebase that builds them..."
And because every query has a name in a -- name: comment, you can talk about them by name. ListRecentUsers is a thing. It has a definition. It has a test. It shows up in the same place every time. The query becomes a first-class object in your codebase, the same way a function is, because it's now backed by a generated function.
Where the ORM was helping you, and what you give up
It would be dishonest to pretend you give up nothing.
sqlc does not do dynamic queries well. If you have a list endpoint with eight optional filters that should each compose into a WHERE clause when present, you have three choices: write one query per combination (combinatorial explosion), use a single query with CASE/COALESCE tricks (fragile), or accept that this specific endpoint is going to use database/sql or squirrel for query building and bypass sqlc. The third is usually the right call. sqlc isn't trying to be a builder. It's trying to be a generator for the queries you can spell out in advance.
It does not give you a relations API. If you want "give me a user and their last 10 posts", you write the query. There's no Include('Posts') shortcut. For most cases this is fine, sometimes faster than what the ORM would have produced. For aggressively nested reads, you'll write more SQL.
It does not save you from understanding your database. The errors it catches at generation time are real type errors: wrong column name, wrong number of placeholders, scalar where an array is needed. It can't catch a missing index, an accidental sequential scan, a query that's correct but slow. You still need to read EXPLAIN plans. Nobody is saving you from that, with or without sqlc.
It also has rough edges. Postgres support is the best by a wide margin; MySQL works but lags; SQLite is supported and usable. Postgres-specific features (UUID, JSONB, arrays, RETURNING, CTEs) are first-class. If your stack is MySQL-first, the experience is good but not as polished, so check the docs for which features your engine supports before you commit.
Wiring it into a real service
Once you have the generated code, the rest of the service barely needs to know sqlc exists. Open a connection pool, hand it to db.New, and you have a typed handle to every query:
package main
import (
"context"
"log"
"os"
"github.com/jackc/pgx/v5/pgxpool"
"example.com/myapp/internal/db"
)
func main() {
ctx := context.Background()
pool, err := pgxpool.New(ctx, os.Getenv("DATABASE_URL"))
if err != nil {
log.Fatal(err)
}
defer pool.Close()
queries := db.New(pool)
user, err := queries.CreateUser(ctx, db.CreateUserParams{
Email: "ada@example.com",
FullName: "Ada Lovelace",
})
if err != nil {
log.Fatal(err)
}
log.Printf("created user %d", user.ID)
}For transactions, you start one and use WithTx:
tx, err := pool.Begin(ctx)
if err != nil {
return err
}
defer tx.Rollback(ctx)
qtx := queries.WithTx(tx)
user, err := qtx.CreateUser(ctx, db.CreateUserParams{...})
if err != nil {
return err
}
if err := qtx.CreatePost(ctx, db.CreatePostParams{AuthorID: user.ID, ...}); err != nil {
return err
}
return tx.Commit(ctx)That's the whole transaction story. No middleware, no WithTransaction(func(tx)) callback layer unless you decide you want one, no ambient context that secretly carries the transaction. The transaction is the tx variable. It dies when the function returns.
When sqlc is the right call
Reach for sqlc when:
- Your team is comfortable in SQL and treats queries as serious code.
- The schema is yours to define and version with migrations.
- You want one source of truth for the schema (the migrations), not two (migrations + ORM tags).
- You care about being able to read the queries your service is running without a debugger.
- You're using PostgreSQL (or MySQL, with the caveat above).
Skip it when:
- The endpoint shape is dominated by ad-hoc dynamic filtering you can't enumerate.
- You don't control the schema; a query builder over an external warehouse is a different problem.
- The team prefers an active-record / relation-graph mental model and won't enjoy hand-writing joins.
There's no shame in either choice. sqlc is one bet about where you want the abstraction to sit: as low as possible, with the generator doing the boring work of mapping rows into structs, and you doing the interesting work of writing the SQL.
The thing it gives you, more than types, is a database layer that reads like English to whoever joins the team next. The queries are right there, named, in version control, runnable. That's a quieter kind of magic than an ORM, but it's the kind you can debug.





