Here's a fun thing you can do tomorrow morning. Open any Node service that's been in production for more than a year, grep for as any, and see what you find. Then grep for as unknown as. Then grep for // @ts-expect-error. Then look at how many JSON.parse calls are followed by a comforting type assertion that nobody has actually verified.
That's where types end and reality begins.
TypeScript on a Node project is doing real work. It's catching typos, helping refactors, and giving your editor enough context to be useful. But there's a quieter trap most teams fall into: they treat the type system as the whole safety story. They add : User to function signatures, sprinkle in a few generics, ship it, and assume the compiler has their back. It doesn't. The compiler is a brilliant intern who only reads the code you wrote, never the JSON that comes in over the wire, the env var that wasn't set, or the row that came back from the database with a column you didn't expect.
The real value of TypeScript in a backend isn't the types. It's the discipline of treating "what can happen at runtime" as a design question. The types are how you write that discipline down.
Let's walk through what that actually looks like.
The Lie In The Middle Of Every Type Annotation
Here's the move that's burned more services than any other. Some code somewhere does this:
const data = JSON.parse(rawBody) as CreateOrderRequest;That cast does nothing at runtime. It's a comment that the compiler treats as a promise. If the client sends { items: "five" } instead of { items: 5 }, the cast doesn't care. Two function calls deeper, you'll be calling .toFixed(2) on a string and seeing it in your error tracker an hour later.
The same shape shows up everywhere. process.env.STRIPE_KEY!: the bang says "trust me, this is defined." Until it isn't, and you get a cryptic error from the Stripe SDK at 3am. redis.get('user:123') returns string | null, until you as User it and forget that Redis can also return a value that was set by a previous version of your schema. The DB driver returns any[] or a loose row shape, and you map it into a typed result without checking that the column you're reading even exists.
The pattern is identical every time: data crosses a boundary, you tell the compiler what to believe, and you don't tell the runtime anything. The compiler shrugs and trusts you. The runtime doesn't have that luxury.
The fix isn't "more types." The fix is to move the trust line. The inside of your service should be aggressively typed and the boundaries should be aggressively validated. Types describe what's true after you've checked. Schemas do the checking.
Validation At The Perimeter, Types In The Core
Pick any runtime input. Every one of them is a place where untrusted bytes become "data we'll use." That's the perimeter. There aren't that many of them, and they fit on your fingers:
- HTTP request bodies and query strings
- Environment variables
- Queue messages (SQS, BullMQ, Kafka, whatever)
- External API responses
- Database rows (yes, your migration ran, but the staging DB might still have the old shape)
- Files you read off disk or out of S3
Each one of these needs a schema, and the type that flows into the rest of your code should come from that schema, not from a separate interface you wrote nearby and hope still matches.
The shape with Zod looks like this:
import { z } from 'zod';
export const CreateOrderSchema = z.object({
customerId: z.string().uuid(),
items: z.array(
z.object({
sku: z.string().min(1),
quantity: z.number().int().positive(),
})
).min(1),
couponCode: z.string().optional(),
});
export type CreateOrder = z.infer<typeof CreateOrderSchema>;One definition. The runtime gets a parser. The compiler gets a type. They can't drift, because they're the same artifact. Now the handler looks like this:
app.post('/orders', async (req, res) => {
const parsed = CreateOrderSchema.safeParse(req.body);
if (!parsed.success) {
return res.status(400).json({ errors: parsed.error.issues });
}
const order = await createOrder(parsed.data); // parsed.data is CreateOrder
res.json(order);
});createOrder can be brutally strict in its signature. It accepts CreateOrder and nothing else. There's no path into it that doesn't go through the schema first, so the type isn't aspirational. It's enforced.
Do the same thing for env vars. The trick that prevents a thousand startup bugs is parsing the env at boot, once:
import { z } from 'zod';
const EnvSchema = z.object({
NODE_ENV: z.enum(['development', 'test', 'production']),
DATABASE_URL: z.string().url(),
REDIS_URL: z.string().url(),
STRIPE_KEY: z.string().min(1),
PORT: z.coerce.number().int().positive().default(3000),
});
export const env = EnvSchema.parse(process.env);That .parse throws at startup if anything is missing. Your service refuses to boot in a broken state, which is exactly what you want, because the alternative is booting fine and crashing two hours later on the first request that hits the unset variable. Anywhere else in the codebase, you import { env } from './env' and get a fully-typed object. No process.env.X!. No defensive checks.
Queue messages get the same treatment. Database rows get it if you don't trust your ORM's generated types (or if your ORM is "we wrote raw SQL and you trust us"). External API responses absolutely get it: those APIs change, and you'd rather find out at the boundary than three function calls deeper.
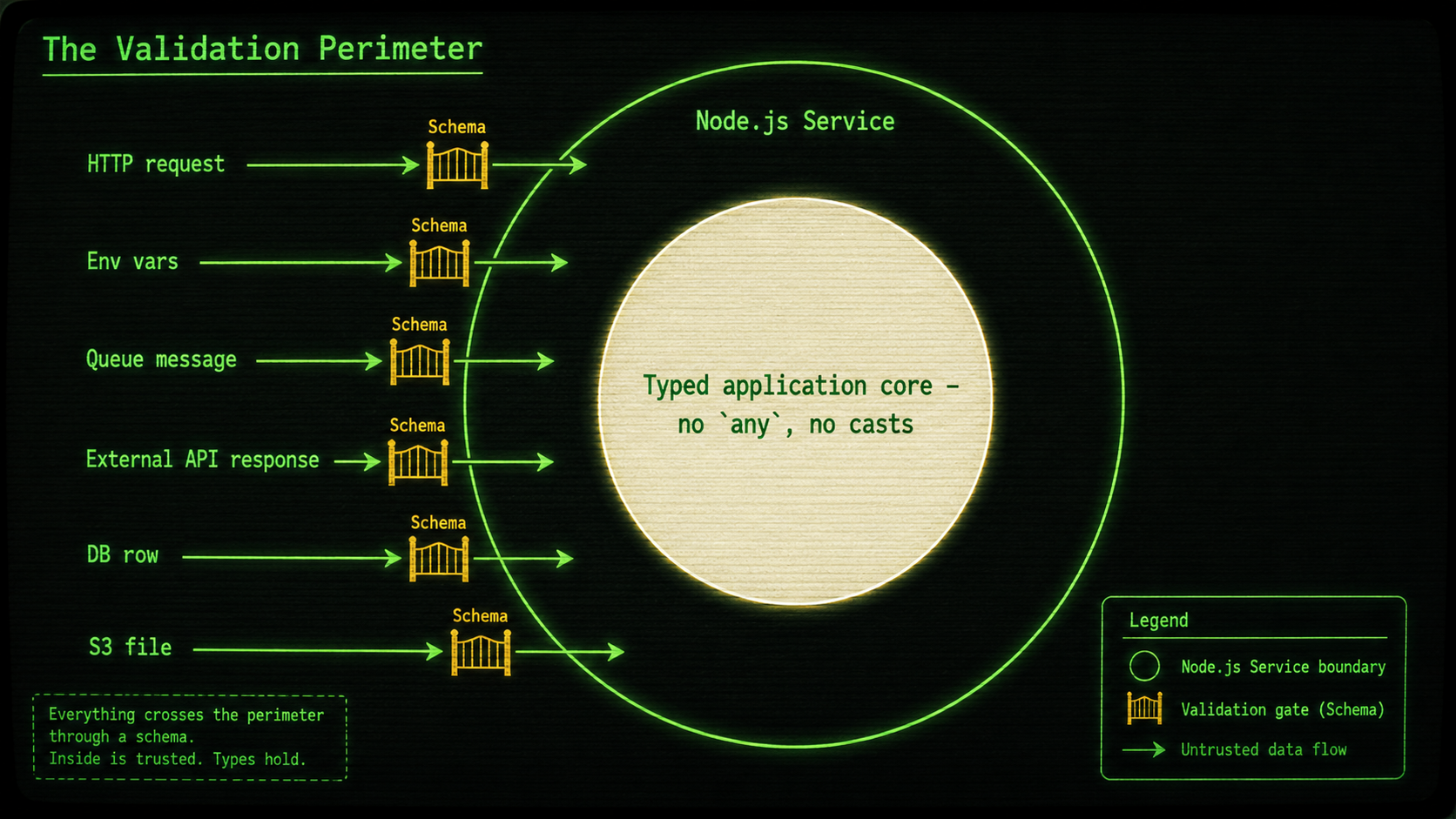
The mental model is a security perimeter. Inside, everything is trusted because you checked it on the way in. Outside, you assume nothing. Once you organize a codebase that way, you stop reading req.body.something with your fingers crossed.
Branded Types For Things That Are All Strings But Aren't The Same Thing
A userId is a string. A orderId is a string. A stripeCustomerId is a string. A raw email address is a string. They are all string to TypeScript, which means you can pass any of them to any function that takes a string, and the compiler will smile politely while you swap a user ID for an order ID and corrupt a row.
Branding fixes this without runtime cost:
type Brand<T, B extends string> = T & { readonly __brand: B };
export type UserId = Brand<string, 'UserId'>;
export type OrderId = Brand<string, 'OrderId'>;
export type Email = Brand<string, 'Email'>;Now UserId and OrderId are not assignable to each other, even though both are string at runtime. You get them by parsing, typically inside the schema layer:
const UserIdSchema = z.string().uuid().transform((s) => s as UserId);You can do this with branded primitives, branded numbers (type Cents = Brand<number, 'Cents'>; is great for money), or any value that has rules attached but doesn't deserve a full class. The compiler now refuses to let you do transferMoney(amountDollars, recipientUserId) if transferMoney wants Cents and the function before it returned number.
This sounds fussy. It is, for a week. After that it stops being fussy and starts catching bugs you'd never have spotted in review. The category of bug it catches, "we passed the wrong-shaped string in," is the kind that survives unit tests and dies in production.
Discriminated Unions Instead Of Optional-Field Soup
Here's a type you'll find in roughly every codebase that's been around for a while:
interface PaymentResult {
success: boolean;
transactionId?: string;
failureReason?: string;
retryable?: boolean;
pendingUrl?: string;
}The implicit rule is "if success is true, you have a transactionId; if not, you have a failureReason; sometimes there's a pendingUrl for 3DS." Every caller has to remember those rules. The compiler can't enforce them. Someone, eventually, reads transactionId from a failed payment, gets undefined, and writes a defensive check that papers over the bug instead of preventing it.
A discriminated union encodes the rules directly:
export type PaymentResult =
| { status: 'succeeded'; transactionId: string }
| { status: 'failed'; reason: string; retryable: boolean }
| { status: 'pending'; redirectUrl: string };Now this just works:
function handle(result: PaymentResult) {
switch (result.status) {
case 'succeeded':
return logSuccess(result.transactionId); // typed as string
case 'failed':
return result.retryable ? retry(result) : giveUp(result.reason);
case 'pending':
return res.redirect(result.redirectUrl);
}
}Inside each branch, the compiler narrows the type. You can't read transactionId from a failed result because it isn't there to read. And if you add a fourth status next quarter ('requires_review' for fraud holds), every switch over PaymentResult becomes a compile error until you handle it.
That last property is gold. It's how you turn "we forgot to update the dashboard when we added the new state" from a bug into a compile failure. Pair it with an exhaustiveness check to make it loud:
function assertNever(x: never): never {
throw new Error(`Unhandled case: ${JSON.stringify(x)}`);
}
function handle(result: PaymentResult) {
switch (result.status) {
case 'succeeded': return /* ... */;
case 'failed': return /* ... */;
case 'pending': return /* ... */;
default: return assertNever(result);
}
}The default arm types result as never. If you add a new variant and forget a case, that line stops compiling. You get a forced TODO list every time the domain grows.

The bigger lesson here is general: any time you find yourself writing a comment like "only set when X is true", that's a type talking. Listen to it.
Errors Are Data, Sometimes
JavaScript's default error handling is "throw and catch upstream." That's fine for genuinely exceptional situations: out-of-memory, missing config, can't-reach-the-DB-at-all. It's a bad fit for the expected failures that happen on every shift: this user already exists, this coupon expired, this payment was declined.
When you throw on expected failures, three things go wrong. Callers can't see in the type system that the call might fail. Errors lose their shape. By the time they reach the handler, you have an Error with a string message and no structured fields. And handling becomes try/catch ladders that are hard to refactor.
A small pattern that fixes this is Result<T, E>. You can write it in five lines or pull neverthrow. The idea:
export type Result<T, E> = { ok: true; value: T } | { ok: false; error: E };
export const ok = <T,>(value: T): Result<T, never> => ({ ok: true, value });
export const err = <E,>(error: E): Result<never, E> => ({ ok: false, error });Now createUser doesn't throw on duplicate email; it returns:
type CreateUserError =
| { kind: 'email_taken' }
| { kind: 'invalid_password'; rules: string[] };
async function createUser(input: NewUser): Promise<Result<User, CreateUserError>> {
const existing = await db.users.findByEmail(input.email);
if (existing) return err({ kind: 'email_taken' });
// ...
return ok(user);
}The caller sees, right there in the signature, that this can fail and the failure has shape. Handling it is a switch over error.kind. Adding a new failure mode is a compile error in every caller. The HTTP layer can map each kind to an HTTP status without inspecting English-language error messages.
This isn't a religion. Genuinely-unexpected things should still throw, it's how process knows to crash, and it's how middleware can do its job. But the expected failures, the ones your product manager already has a wireframe for? Those are domain data. Treat them like it.
Strictness Flags Are Not All Created Equal
People talk about "strict mode" like it's one switch, but "strict": true is actually a bundle of several flags, and there's another set of options outside that bundle that pull more weight than half of strict mode does. The ones that earn their keep on a backend:
strict: truecoversstrictNullChecks,noImplicitAny, and a handful of others. Non-negotiable. If your project doesn't have this on, that's the first migration.noUncheckedIndexedAccess: truemakesarr[i]returnT | undefined. The first week is painful. After that, you stop seeing "cannot read property of undefined" in production because you can't write code that ignores the possibility anymore.exactOptionalPropertyTypes: truedistinguishes{ name?: string }from{ name: string | undefined }. Subtle but real: it stops you from explicitly setting a property toundefinedwhen the type says "this field might not exist." Saves a category of bugs in PATCH endpoints where omitting a field and clearing a field are different operations.noFallthroughCasesInSwitch: truekills the most commonswitchbug.
One more worth knowing about, even though you don't turn it on separately: useUnknownInCatchVariables ships inside strict (it joined the bundle in TypeScript 4.4), so if strict is on you already have it. It types catch (e) as unknown instead of any, which forces you to narrow the error before using it. That's what you should have been doing anyway, so it's a free win you get the moment strict is enabled.
The migration path on an old project is to turn the standalone flags on one at a time, fix the resulting errors, and don't ship the flag flip until the errors are zero. Don't do them all in one PR, the noise is too high and the team will start @ts-expect-erroring their way through.
A worthwhile lint to add on top: ban as casts except for as const and inside schema parsers. ESLint's @typescript-eslint/consistent-type-assertions does this with assertionStyle: 'never'. The grep for as any you did at the top of this article? It stops growing.
Maintainability Is What "Beyond Types" Means In Year Three
A type system that's tight on day one and drifty by year three isn't a type system. It's a fossil. The maintainability part of TypeScript is the stuff that keeps your types worth trusting as the codebase moves.
Co-locate types with the code that owns them. A Types.ts file at the root of every domain folder is fine. A single src/types/everything.ts that 200 files import from is a circular-dependency hazard and a refactor pain.
Don't barrel export everything. A barrel (index.ts that re-exports the whole folder) sounds clean and silently doubles your build's incremental rebuild time, because changing one file invalidates the whole barrel's typecheck graph. Keep barrels for stable public APIs, not internal modules.
Use project references for monorepos. If you have packages/api, packages/worker, and packages/shared, configure them as TypeScript project references. The build cache becomes per-package, and you stop watching the compiler re-typecheck shared every time someone touches api.
Write type tests for the tricky bits. When you write a generic helper (a builder, a request validator, a Result.map), write a test that asserts the inferred types are what you expect. expect-type or tsd work for this:
import { expectTypeOf } from 'expect-type';
import { ok, err } from './result';
expectTypeOf(ok(42)).toEqualTypeOf<{ ok: true; value: number }>();
expectTypeOf(err('nope')).toEqualTypeOf<{ ok: false; error: string }>();A test like this never runs at runtime, but it fails the build if someone "simplifies" your generic and accidentally widens the return type to unknown. It's a fence around the part of the codebase where types matter most.
Treat type definitions as part of the public API. If you export a type, changing it is a breaking change to your callers, including other teams' code if you're in a monorepo. Renaming User.id to User.userId because it reads nicer might be a one-line refactor in the editor and a five-team migration in reality.
Keep the strictness bar from drifting. It's surprisingly easy for a codebase to gain as anys and @ts-expect-errors over time, each one with a sensible reason at the moment it was added. A CI step that counts them and fails when the count goes up keeps the bar honest without forcing heroic refactors.
What Changes In Practice
Pull all of this together and your service looks different from the inside. The handlers are thin: they parse the request, call a domain function, format a response. The domain functions take fully-typed inputs and return Results or discriminated unions. IDs aren't strings, they're branded. The env is parsed at boot. The DB layer either returns parsed-and-validated data or raw rows that you parse before doing anything with them. The catch blocks treat errors as unknown and narrow them explicitly.
None of this requires a framework switch. None of it requires a rewrite. You can do it in the order it's described: schemas at the perimeter first, branded types when the domain confusions start hurting, discriminated unions when state grows past three booleans, Result when error-handling code starts smelling, strictness flags one at a time, maintainability when the team grows past four people.
The compiler is still doing the autocomplete job. But now it's also doing the harder job, the one where the type is a thing that's still true after the request hits the database. That's what "beyond types" means. Types stop being something you sprinkle on after the code is written, and start being how you draw the boundaries between trust and not-trust in your service.
If your codebase has more as casts than schema definitions, you have the ratio backwards. Flip it.