An AI code analysis pipeline should not replace your existing checks — it should connect them. Good code review already has many layers (linters, static analysis, tests, dependency scanning, secret scanning, security checks, migration review, human review), and AI can add one more on top: explaining diffs, summarizing risks, suggesting missing tests, reviewing suspicious code paths, and writing pull request summaries.
The strongest setup is not "AI reviews code instead of tools." It's:
Deterministic tools check what they can.
AI explains what needs judgment.
Humans make the final decision.That's the architecture we want. Each layer has a different job, and none of them are trying to do the others' work.
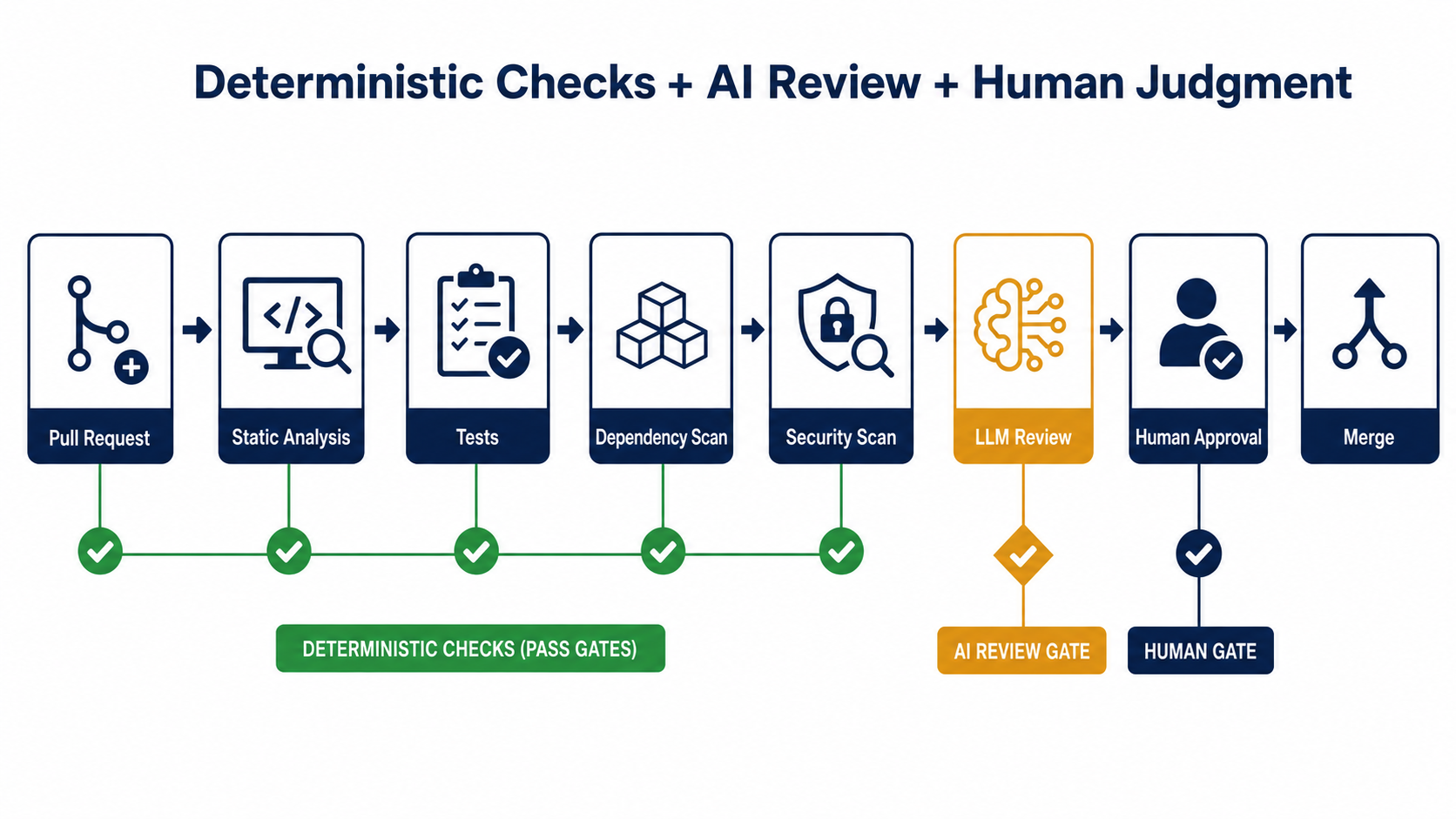
Start With Deterministic Checks
Before adding AI, run the boring checks. For a PHP project that's PHPStan and PHPUnit:
name: Pull Request Checks
on:
pull_request:
jobs:
php-checks:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install dependencies
run: composer install --no-interaction --prefer-dist
- name: Run PHPStan
run: vendor/bin/phpstan analyse
- name: Run PHPUnit
run: vendor/bin/phpunitFor a JavaScript/TypeScript project, the same shape with different tools:
name: Frontend Checks
on:
pull_request:
jobs:
frontend-checks:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: npm run lint
- run: npm test
- run: npm run typecheckThese checks are not glamorous — they're reliable. AI should not be used to replace type checking, tests, or static analysis. It can read their output, but it shouldn't produce it.
Add Dependency Scanning
Dependency vulnerabilities are not usually a model problem — use deterministic scanners and let AI summarize the result. The simple version:
- name: Run npm audit
run: npm audit --audit-level=highFor PHP:
- name: Run composer audit
run: composer auditIn larger teams, you may use Dependabot, Snyk, GitHub Advanced Security, or other scanners. AI can summarize scanner output, but the scanner should detect the issue. A useful prompt for the summarization step:
Summarize this dependency scan result for a pull request reviewer.
Include:
- vulnerable package,
- severity,
- affected version,
- recommended upgrade,
- whether this PR introduced the issue,
- whether merge should wait.That's the right division of labor — deterministic detection, AI explanation.
Add Secret Scanning
LLMs are not the right first line of defense for secrets. Use scanners. AI can help explain what a secret-looking value might affect, but it should not be the detection layer.
gitleaks detect --source .In CI:
- name: Secret scan
run: gitleaks detect --source . --no-gitIf a scanner finds a secret, block the merge. That's deterministic, and it's exactly the kind of thing that should not depend on a probabilistic model.
Add LLM Review After Basic Context Collection
The LLM should receive useful context — changed files, diff, test results, static analysis output, dependency scan summary, project rules, and risk policy. The bare-bones context builder:
from pathlib import Path
def read_file(path: str, max_chars: int = 60000) -> str:
content = Path(path).read_text(errors="replace")
return content[:max_chars]
changed_files = read_file("changed-files.txt")
diff = read_file("pr.diff")
phpstan = read_file("phpstan-output.txt")
tests = read_file("phpunit-output.txt")
policy = read_file(".ai-review-policy.md")And the prompt that keeps AI in an advisory role:
You are an advisory AI code reviewer.
Review this pull request using:
- changed files,
- diff,
- static analysis output,
- test output,
- team review policy.
Focus on:
- security,
- authorization,
- validation,
- database performance,
- missing tests,
- migration safety,
- backward compatibility.
Do not approve or reject the PR.
Return advisory findings grouped by severity.The "do not approve or reject" line is the load-bearing one — it stops the model from acting like a gatekeeper for decisions it doesn't have enough context to make.
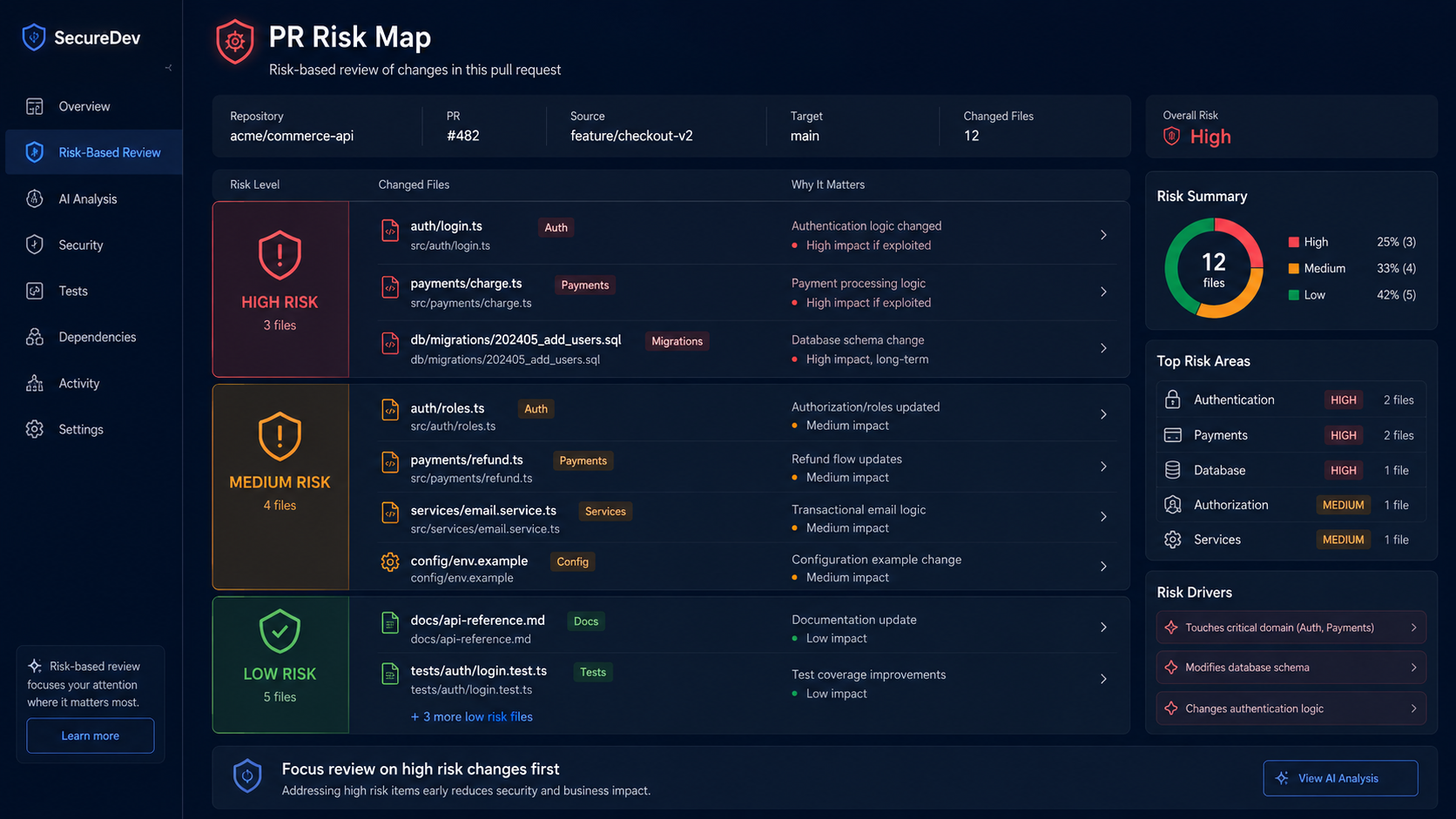
Risk-Based Review
Not every file needs the same level of review. A small classifier helps both the AI and the human reviewer focus their attention:
HIGH_RISK_PATTERNS = [
"auth",
"permission",
"policy",
"payment",
"billing",
"checkout",
"webhook",
"migration",
".github/workflows",
]
def classify_risk(path: str) -> str:
normalized = path.lower()
if any(pattern in normalized for pattern in HIGH_RISK_PATTERNS):
return "high"
if path.endswith((".md", ".txt")):
return "low"
return "medium"Include the risk map in the prompt:
Changed files risk map:
- app/Services/PaymentRetryService.php: high
- tests/Feature/PaymentRetryTest.php: medium
- docs/payments.md: lowThis helps the model focus, and it helps reviewers too — the high-risk files deserve a longer look, the docs change can ride along.
LLM Review Should Be Advisory First
Don't block merges because the model "feels concerned." Use AI comments as advisory input. The split that works in practice:
Good blocking checks:
- tests failed
- static analysis failed
- secret scanner failed
- dependency scanner found critical vulnerability
- required reviewer missing
- migration policy violated
Bad blocking checks:
- LLM thinks the code is risky
- LLM says tests may be missing
- LLM is uncertain
- LLM dislikes the designThe model can raise questions. Humans decide. The moment the model starts hard-blocking merges, your team will route around it within a week — and you'll have lost the value it could've provided as advisory input.
Test Generation As A Pipeline Step
AI can suggest tests. It should not silently commit them without review.
Based on this pull request diff, suggest missing tests.
For each test, include:
- test name,
- behavior protected,
- setup,
- expected assertion,
- why it matters.
Do not generate large test files unless needed.
Prioritize high-risk behavior.A useful output looks like this:
## Suggested Tests
### test_non_admin_cannot_refund_order
Behavior protected:
Regular users cannot call refund endpoint.
Setup:
Create paid order owned by another user.
Assertion:
POST /refund returns 403 and no refund record is created.
Why it matters:
The PR changes refund authorization logic.This is useful for reviewers. A later version of the pipeline may generate a draft patch, but keep that behind explicit human approval.
Security Review Prompts
Security review should be specific. The generic "find security issues" prompt produces vague findings; the targeted version produces issues you can act on:
Review this diff for security issues.
Focus on:
- authentication,
- authorization,
- unsafe input,
- SQL injection,
- XSS,
- SSRF,
- path traversal,
- insecure deserialization,
- secret exposure,
- missing rate limits,
- unsafe file uploads,
- insecure tool calls.
Return only high-signal findings.
If context is missing, ask questions instead of guessing.For a PHP/Laravel codebase, add framework-specific items:
Pay special attention to:
- request validation,
- policies/gates,
- middleware,
- mass assignment,
- raw SQL,
- file storage paths,
- signed URLs,
- queue payloads,
- webhook signature validation.Same idea for any other framework — name the things that are uniquely yours and the model will look for them.
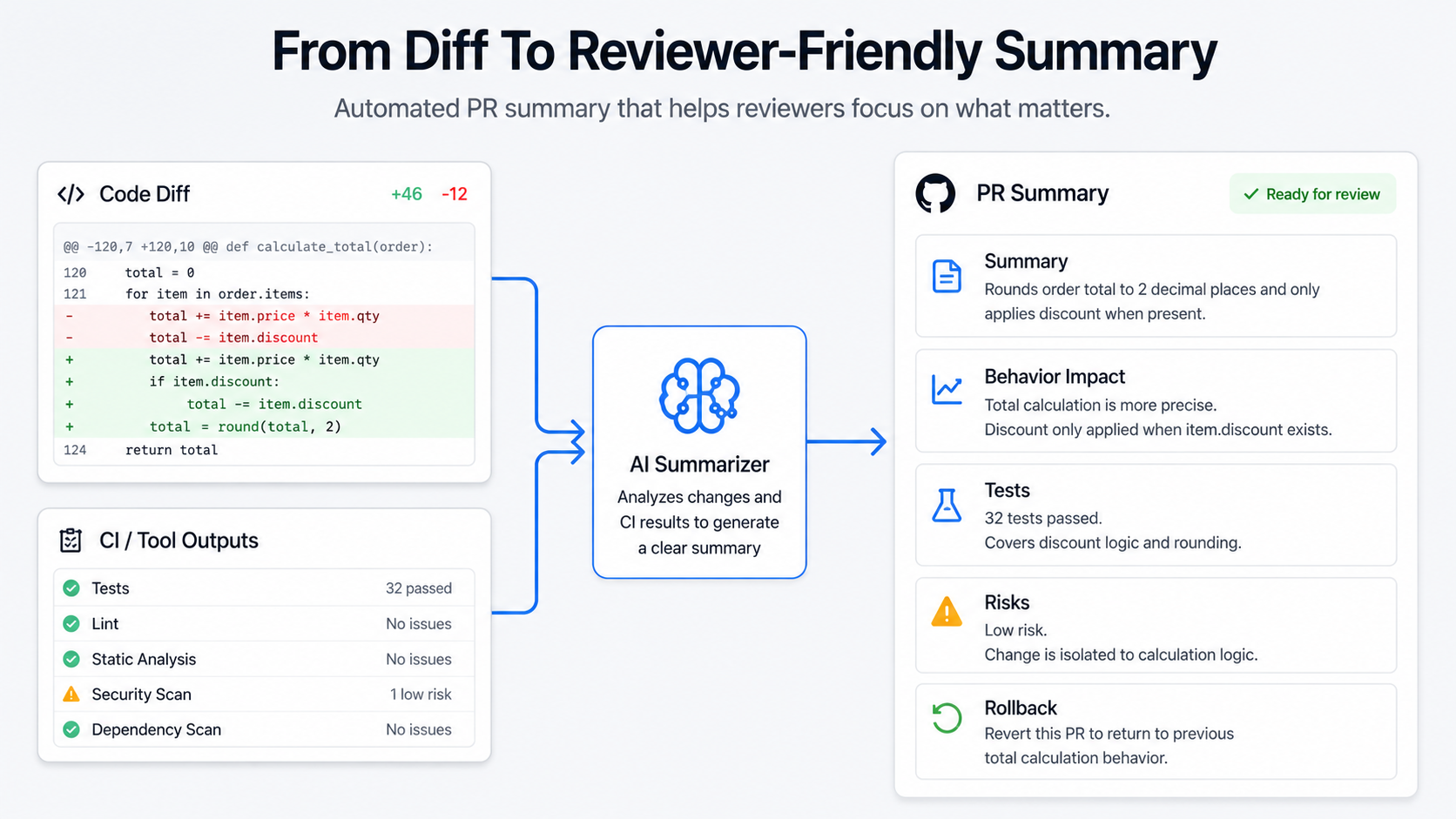
PR Summaries
AI is excellent at PR summaries — this is probably the highest ROI use of the pipeline.
Create a pull request summary from this diff.
Include:
- what changed,
- why it changed,
- behavior impact,
- tests added or missing,
- security/performance considerations,
- deployment notes,
- rollback notes.
Keep it clear and honest.
Do not exaggerate.A typical output:
## Summary
This PR centralizes payment retry eligibility into PaymentRetryService and updates
the retry command to use the shared logic.
## Behavior Impact
Failed payments are retried only after the cooldown period and only while under
the retry limit.
## Tests
Adds coverage for retry limit, cooldown window, and non-failed payment attempts.
## Risk
Billing behavior is customer-facing. Review idempotency and duplicate charge
protection carefully.That's the kind of summary a reviewer can read in 30 seconds and immediately know where to look in the diff.
Human Approval Layer
Human approval is the final layer. The pipeline should help humans answer "is this change safe enough to merge?" — not "can AI decide for us?".
A strong pipeline produces failed/passed checks, security scan results, dependency scan results, AI risk summary, suggested tests, PR summary, and required reviewers — and then humans review the actual code with all of that as context. The AI didn't replace the review; it sharpened it.
Full Pipeline Example
A workable starting template, with deterministic checks first and AI review reading their output:
name: AI-Assisted Code Analysis
on:
pull_request:
permissions:
contents: read
pull-requests: write
jobs:
deterministic-checks:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: composer install --no-interaction --prefer-dist
- run: vendor/bin/phpstan analyse | tee phpstan-output.txt
- run: vendor/bin/phpunit | tee phpunit-output.txt
- run: composer audit | tee dependency-audit.txt
- uses: actions/upload-artifact@v4
with:
name: check-outputs
path: |
phpstan-output.txt
phpunit-output.txt
dependency-audit.txt
ai-review:
runs-on: ubuntu-latest
needs: deterministic-checks
if: always()
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- run: git diff origin/main...HEAD > pr.diff
- run: git diff --name-only origin/main...HEAD > changed-files.txt
- uses: actions/download-artifact@v4
with:
name: check-outputs
- name: Run AI review
env:
AI_API_KEY: ${{ secrets.AI_API_KEY }}
run: python scripts/ai_code_review.py
- name: Post PR comment
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.pull_request.number }}
run: gh pr comment "$PR_NUMBER" --body-file ai-review.mdThis is only a template — adjust it to your stack and security policy. The key shapes (deterministic-first, AI reads their artifacts, AI comments are advisory) carry over no matter what tools you use.
Final Thoughts
An AI code analysis pipeline should make review stronger, not lazier. Use deterministic tools for deterministic problems, use AI for explanation, risk discovery, missing test suggestions, and PR summaries, use humans for final judgment.
The best pipeline looks like this:
Static analysis catches mechanical issues.
Security scanners catch known risks.
Tests protect behavior.
AI explains what changed and what may be missing.
Humans decide.That's a realistic and safe way to bring AI into engineering workflows.