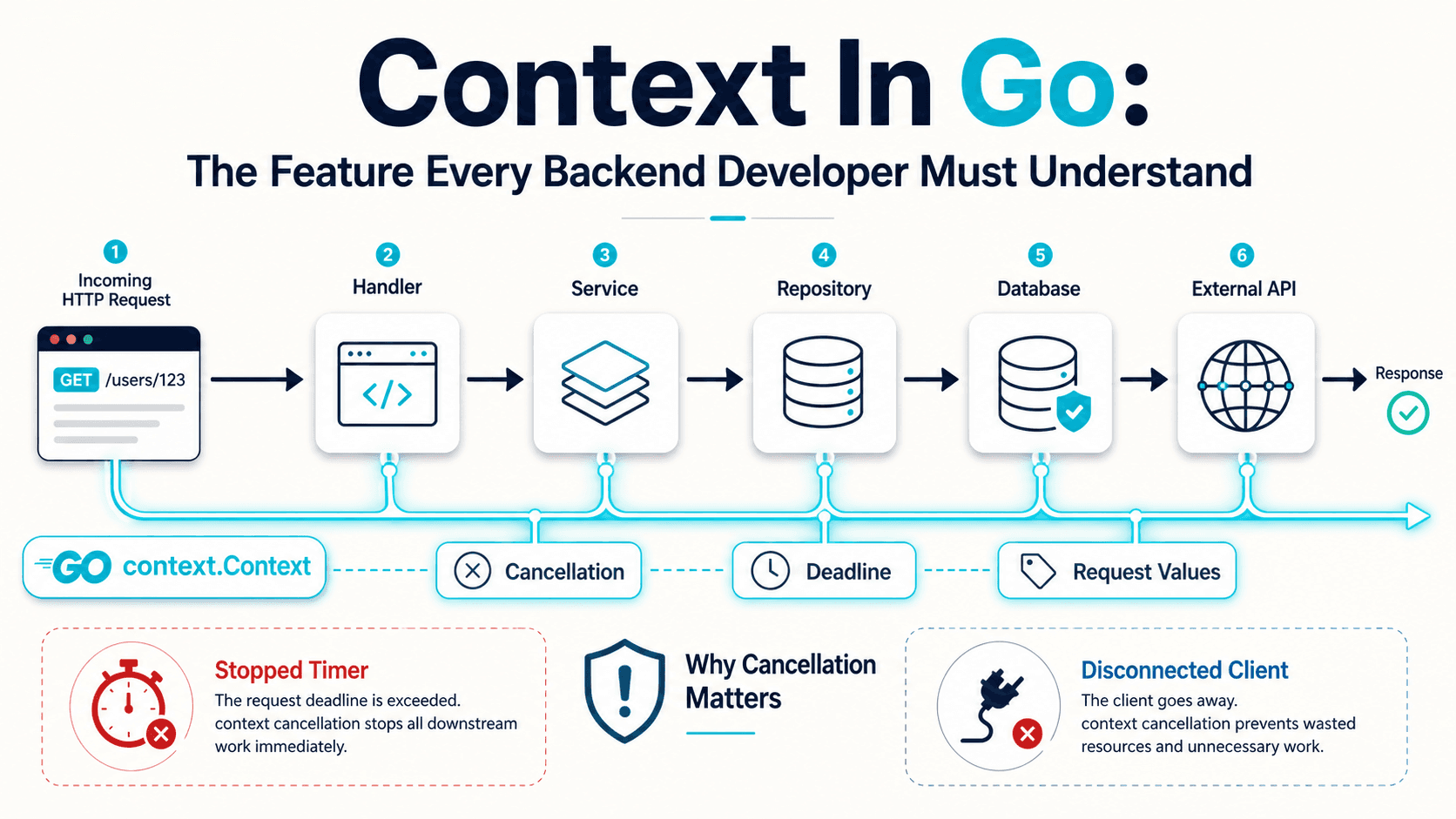
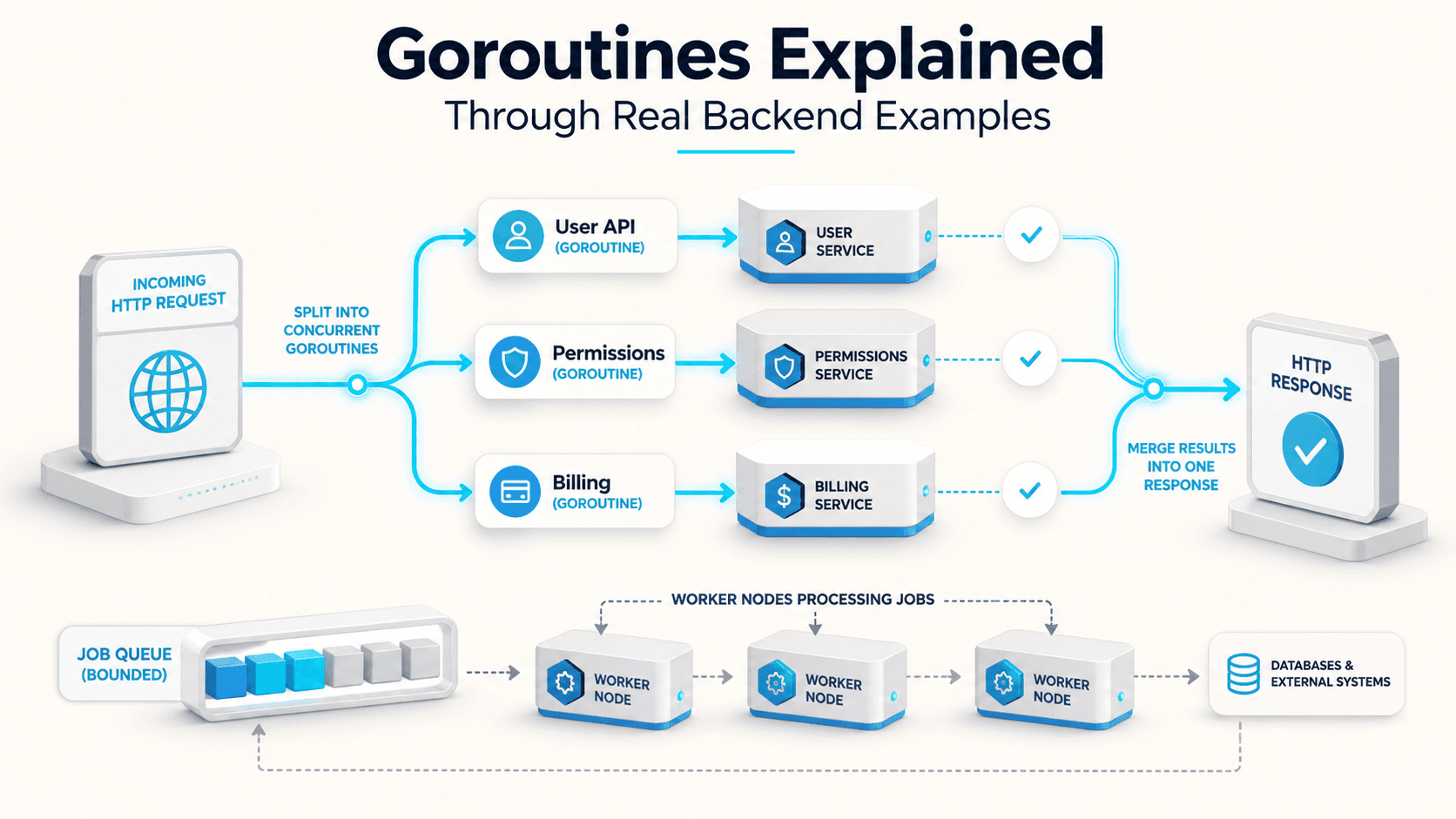
So, you've got an HTTP handler that does a little too much. It charges a card, sends a receipt email, syncs the order to a warehouse, regenerates a thumbnail, and pings an analytics endpoint. The user clicks "Pay" and waits. And waits. And then your p99 latency chart starts looking like the side of a mountain.
The first instinct is the right one: get that work off the request path. Push it into the background, return 202 Accepted, and let some worker process do it later. In Go, this feels almost too easy. You write go func() { ... }(), the work runs, and the handler returns in 4ms. Beautiful.
Then the box restarts and you discover that fire-and-forget really does mean fire-and-forget. The card was charged, the receipt was not sent, and a customer is now writing a polite but pointed email.
Background workers aren't really about concurrency. They're about durability, backpressure, retries, and shutdown. Goroutines are a great tool for running a worker, but they aren't the worker by themselves. This article is a deep walk through what it actually takes to build a background worker system in Go that you can trust at 3am, covering goroutines and pools, queue choices, retry strategy, dead-letter handling, and a graceful shutdown that drains instead of dropping.
We'll stay in Go the whole way, because this is a Go-specific topic and switching languages mid-article would be useless. Code is plain go with the standard library plus a few common third-party imports where they help (go-redis, sync/errgroup).
What we actually mean by "background worker"
It's worth being precise, because "worker" is one of those words that means five different things depending on who's saying it.
When I say background worker in this article, I mean: a long-running process (or set of goroutines inside a process) that consumes jobs from somewhere outside the HTTP request path and runs them to completion, with retries and shutdown semantics that survive a deploy.
That definition has a few load-bearing pieces:
- long-running -> the worker doesn't die between jobs
- consumes jobs -> there's a queue, somewhere, that produces them
- outside the HTTP -> the request that enqueues is decoupled from the run
- retries -> a single failure doesn't lose the job
- survives deploy -> rolling restarts don't kill in-flight workNotice what's not in the definition: "goroutine," "Redis," "channels," "Kubernetes." Those are implementation choices. The contract is what matters.
If your background work is just a fire-and-forget goroutine inside the HTTP handler, you don't have a worker. You have a goroutine. The difference shows up the first time the process gets SIGTERM halfway through.
The naive version, and why it's not enough
Let's start where most teams start, because it's a useful baseline for what we'll fix.
func PayHandler(w http.ResponseWriter, r *http.Request) {
orderID := r.URL.Query().Get("order_id")
if err := chargeCard(r.Context(), orderID); err != nil {
http.Error(w, err.Error(), http.StatusBadGateway)
return
}
go func() {
// these don't block the response
sendReceiptEmail(orderID)
syncToWarehouse(orderID)
regenerateThumbnail(orderID)
}()
w.WriteHeader(http.StatusAccepted)
}This compiles. It runs. The handler returns in milliseconds. And it's wrong in at least four ways.
First, the goroutine inherits no context. r.Context() is canceled the moment the HTTP response is written, so passing it down would cancel the work you just started. So you don't pass it. So the work has no deadline, no cancellation, no shutdown signal. It'll happily run during a deploy and get killed mid-send.
Second, there's no backpressure. If 5000 requests hit at once, you spawn 15,000 goroutines, each holding a database connection and a chunk of memory. Goroutines are cheap, but they're not free, and your downstream services definitely aren't.
Third, there's no retry. sendReceiptEmail fails because Mailgun is having a bad ten seconds. The error is logged (best case) and the email is just... gone.
Fourth, there's no visibility. You can't list pending work. You can't see how long a job has been running. You can't replay a failed job. You can't even tell that you have a problem until someone complains.
Go gives you the building blocks, but it doesn't hand you a worker for free. Let's build one.
The shape of a real worker
Before any code, the picture. Almost every production worker system, in any language, looks like this:
+--------------+ +--------+ +-----------+
| Producer(s) | -----> | Queue | -----> | Workers |
+--------------+ +--------+ +-----------+
^ |
| retry v
+--------------+ +--------+
| | DLQ |
| +--------+
|
shutdown
drains poolFour moving parts: producers (your HTTP handlers, schedulers, cron jobs), a queue that buffers work, a pool of workers that consume from it, and a side channel for jobs that never succeed (the dead-letter queue, or DLQ). Plus the lifecycle wiring that lets the whole thing start and stop cleanly.
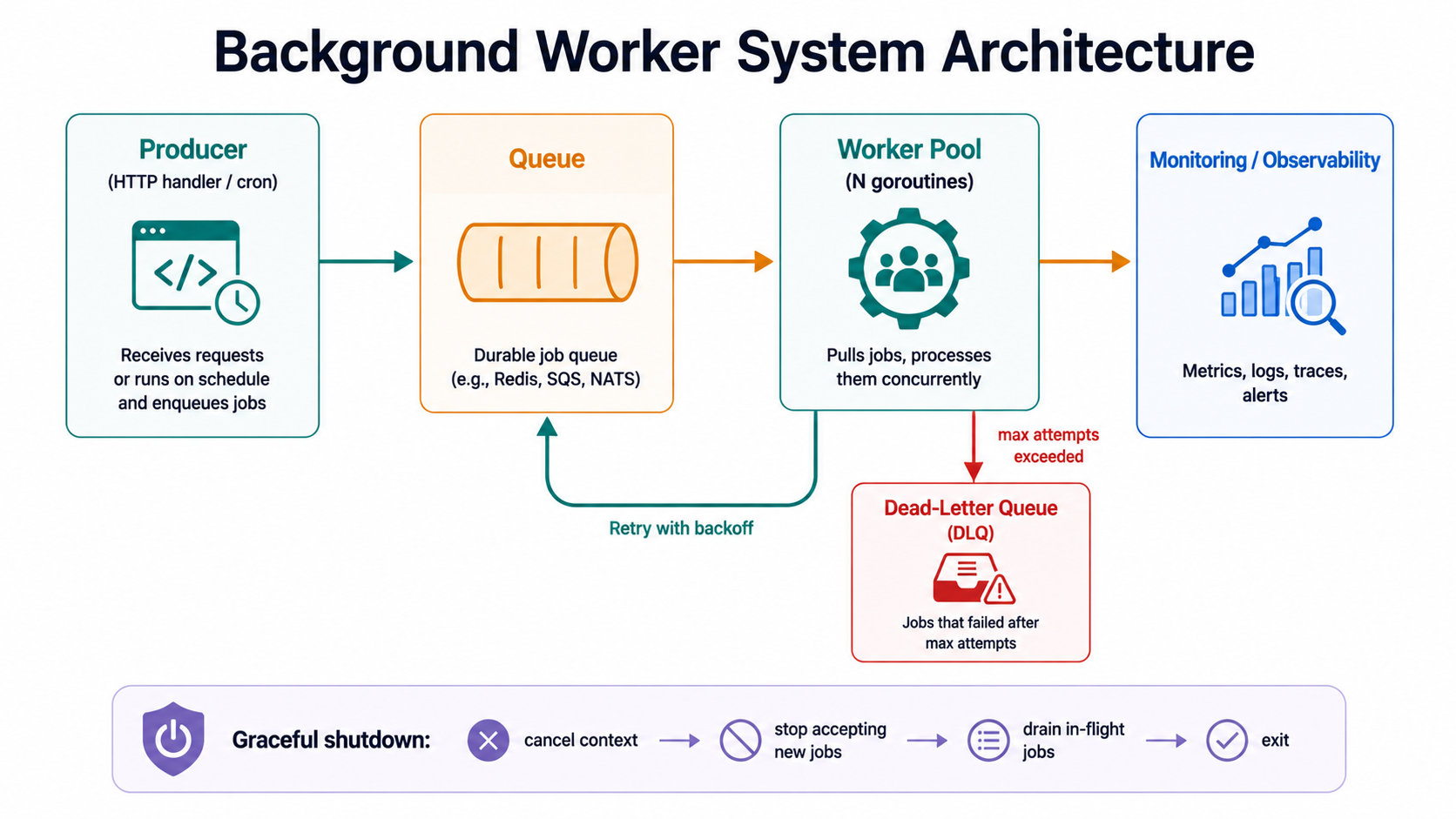
That picture is the same whether your queue is an in-memory channel or AWS SQS, whether your workers are 4 goroutines or 4000 pods. The names of the boxes stay; only their implementation swaps. Get that shape right in your head and the rest of the article is mostly filling in details.
Building the pool with goroutines and channels
The worker pool is the part Go is famously good at, so let's build one. We'll use a buffered channel as the in-process queue, a sync.WaitGroup to track in-flight work, and a context for shutdown.
package worker
import (
"context"
"log/slog"
"sync"
)
type Job struct {
ID string
Payload []byte
Attempt int
}
type Handler func(ctx context.Context, j Job) error
type Pool struct {
handler Handler
jobs chan Job
workers int
wg sync.WaitGroup
}
func NewPool(workers, buffer int, handler Handler) *Pool {
return &Pool{
handler: handler,
jobs: make(chan Job, buffer),
workers: workers,
}
}
func (p *Pool) Start(ctx context.Context) {
for i := 0; i < p.workers; i++ {
p.wg.Add(1)
go p.run(ctx, i)
}
}
func (p *Pool) Submit(j Job) {
p.jobs <- j
}
func (p *Pool) Stop() {
close(p.jobs) // tell workers no more jobs are coming
p.wg.Wait() // wait for in-flight to finish
}
func (p *Pool) run(ctx context.Context, id int) {
defer p.wg.Done()
for {
select {
case <-ctx.Done():
return
case j, ok := <-p.jobs:
if !ok {
return // channel closed, drain done
}
if err := p.handler(ctx, j); err != nil {
slog.Error("job failed",
"worker", id,
"job_id", j.ID,
"attempt", j.Attempt,
"err", err,
)
}
}
}
}A few things in this 50-line snippet are doing real work, so let's unpack them.
The select inside run is the whole reason this pool can be stopped cleanly. If a worker is sitting idle and the context is canceled, it exits without waiting for a job. If a job is delivered, the worker handles it and loops. That's the standard Go pattern for cancelable consumers.
Stop() closes the channel first, then waits. Closing a channel is how you say "no more sends are coming" to a range or a receive. Every worker eventually reads the zero value with ok == false and returns. The WaitGroup blocks until all of them have actually finished. This is the drain behavior: in-flight jobs run to completion, then the pool returns.
Look closely at one thing the snippet does not do: it doesn't try to handle ctx.Done() by abandoning the current job. If you want shutdown to cancel running jobs, the handler itself must respect ctx, which is exactly the contract the standard library expects. If you want shutdown to drain instead, leave ctx alone and rely on Stop(). Most real workers do both: pass ctx to the handler so the handler can stop early on critical signals, then call Stop() so the pool drains what it has accepted.
Bounding submission
p.Submit(j) will block when the channel buffer is full. That's the feature, not a bug, in the in-process case: it's natural backpressure. If the producer is faster than the workers, the producer waits. But "the producer waits" can also be exactly what you don't want, because your producer might be an HTTP handler.
So Submit usually has a friend with a timeout:
func (p *Pool) SubmitWithin(ctx context.Context, j Job) error {
select {
case p.jobs <- j:
return nil
case <-ctx.Done():
return ctx.Err()
}
}Now your handler can do:
ctx, cancel := context.WithTimeout(r.Context(), 50*time.Millisecond)
defer cancel()
if err := pool.SubmitWithin(ctx, job); err != nil {
http.Error(w, "queue full, try again", http.StatusServiceUnavailable)
return
}A 503 with a Retry-After is a much better failure mode than an HTTP handler that hangs for 30 seconds because the worker pool is saturated.
Picking the worker count
People ask "how many workers?" expecting a number. The honest answer is "measure," but there are reasonable defaults:
- CPU-bound work (image processing, hashing): start with
runtime.NumCPU(). - IO-bound work (HTTP calls, database queries): start much higher, often 50 to 500, because workers spend most of their time blocked.
- Anything that hits a downstream service with a connection limit: bound by that limit and leave headroom. A pool of 200 workers hammering a database with
max_connections=100is just a creative way to write a denial-of-service tool.
The worker count is also your unit of parallelism per process. If you run 10 replicas of the same service with a pool size of 50, you're authorizing up to 500 concurrent jobs at the queue level. That's worth saying out loud when you're sizing downstreams.
Picking your queue
So far the "queue" has been an in-process channel. That's fine for some workloads, and a disaster for others. Let's separate the cases.
In-memory channels
Channels are the right queue when:
- The work is small, fast, and recreated trivially if lost (e.g., recomputing a derived value).
- You don't care if a process restart drops in-flight jobs.
- You don't need cross-process consumers.
They're the wrong queue when any of those is false. A receipt email that vanishes because a pod restarted is not a small problem to a customer.
The seductive trap with channels is that they look like queues. They aren't, quite. A channel has no persistence, no inspect-with-cli, no replay, no dead-letter. It has a buffer of fixed size and that's it. If you find yourself reaching for a []Job slice "for retries" or a separate chan Job "for failures," that's the signal to graduate to a real queue.
Redis-backed queues
Redis is the practical default for app-level queues in Go. You get persistence (if you configure it), atomic operations, sub-millisecond latency, and redis-cli for inspection. The most common patterns are LPUSH/BRPOP for simple FIFO queues, sorted sets (ZADD/ZRANGEBYSCORE) for delayed jobs, and Redis Streams for stronger consumer-group semantics.
A minimal consumer with go-redis/v9:
package worker
import (
"context"
"encoding/json"
"time"
"github.com/redis/go-redis/v9"
)
type RedisConsumer struct {
client *redis.Client
queue string
pool *Pool
}
func (c *RedisConsumer) Run(ctx context.Context) error {
for {
// BRPOP blocks up to 5s waiting for a job
res, err := c.client.BRPop(ctx, 5*time.Second, c.queue).Result()
if err == redis.Nil {
continue // timeout, no job
}
if err != nil {
if ctx.Err() != nil {
return ctx.Err()
}
// network blip; back off briefly and try again
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(500 * time.Millisecond):
continue
}
}
var j Job
if err := json.Unmarshal([]byte(res[1]), &j); err != nil {
continue // skip malformed jobs
}
c.pool.Submit(j)
}
}The detail worth pausing on: BRPOP with a timeout is what makes this loop cooperative. If you used a blocking call with no timeout and the context got canceled, you'd be stuck in the Redis call until the connection's deadline kicked in. The 5-second timeout means the loop checks ctx at least every 5 seconds, which is fast enough for graceful shutdown.
For more serious workloads, look at Redis Streams (XADD/XREADGROUP), which give you consumer groups with explicit acknowledgement and pending-list inspection. That's also what libraries like asynq and river build on (asynq on Redis, river on Postgres).
Postgres-backed queues
If you already have Postgres, you may not need a separate queue. SELECT ... FOR UPDATE SKIP LOCKED gives you safe multi-consumer dequeue, and libraries like river wrap that pattern with retries, scheduling, and a nice API.
The argument for "use the database you already have" is real: one fewer system to operate, one transaction covering both the business write and the job enqueue, no consistency window between them. The argument against is that Postgres is good at many things, and being a high-throughput queue is not the one it was designed for. At thousands of jobs per second, you'll feel it.
NATS, SQS, RabbitMQ, Kafka
The hosted-or-broker tier covers different shapes:
- NATS JetStream is great if you want a Go-native, lightweight broker with persistence and consumer groups, and you don't mind running it.
- SQS is the lazy-correct choice on AWS: managed, visibility timeouts handle most retry logic for you, and the cost is reasonable. The throughput per queue and ordering semantics are the usual gotchas.
- RabbitMQ is a mature broker if you need rich routing topologies (fanout, topic, headers exchanges).
- Kafka is overkill as a job queue and exactly right as an event log. If you're tempted to use Kafka for jobs because you also have streaming work, separate them. A job that gets retried five times shouldn't be cluttering up your event log.
The point of listing these isn't "pick one." It's that the choice has consequences for retry semantics, ordering, and operational burden, and you should pick on purpose, not by inertia.
Retries that don't make things worse
Most jobs are going to fail at least once over their lifetime. Networks blip, downstreams hiccup, certificates expire on Sundays. A worker without retries is just a slightly more reliable way to drop work on the floor. But naive retries are worse than no retries, because they turn a transient downstream issue into a thundering herd.
Three things determine whether your retry strategy is healthy.
Exponential backoff with jitter
If you retry every job at exactly 1 second after failure, and 10,000 jobs failed in the same outage, you've just scheduled a synchronized retry storm. Backoff spreads them out; jitter scrambles them so the retries don't synchronize again.
package worker
import (
"math"
"math/rand"
"time"
)
// Backoff returns a delay for the given attempt number (1-based).
// Base 250ms, exponential, capped at 2 minutes, with full jitter.
func Backoff(attempt int) time.Duration {
const (
base = 250 * time.Millisecond
cap_ = 2 * time.Minute
)
if attempt < 1 {
attempt = 1
}
// exponential: base * 2^(attempt-1)
d := float64(base) * math.Pow(2, float64(attempt-1))
if d > float64(cap_) {
d = float64(cap_)
}
// full jitter: random in [0, d)
return time.Duration(rand.Int63n(int64(d)))
}That gives you a delay sequence that grows but never exceeds the cap, and is randomized inside the window so 1000 retries scheduled at the same moment land across two minutes instead of all at once. The "full jitter" variant (returning a random value in [0, d)) is generally a better default than "equal jitter" or "decorrelated jitter" for queue workers, because it maximally desynchronizes failures without sacrificing the ceiling.
Max attempts and dead-letter
A job that has failed 50 times isn't going to succeed on the 51st. After some bounded number of attempts (5 is a common starting point, 10 is the upper end for most workloads), the job goes to a dead-letter queue and stops consuming worker time. A DLQ isn't a graveyard. It's a triage bin. Someone (probably you, on Monday morning) reads it, fixes the underlying bug, and replays the jobs.
package worker
import (
"context"
"errors"
)
const MaxAttempts = 5
// ErrPermanent is returned by handlers that know the job will never succeed
// (e.g., invalid payload). Skips retries; goes straight to DLQ.
var ErrPermanent = errors.New("permanent failure")
type RetryingHandler struct {
Run Handler
Queue Enqueuer // re-enqueues with delay
DLQ DeadLetter // moves a job out of the retry loop
}
func (h *RetryingHandler) Handle(ctx context.Context, j Job) error {
err := h.Run(ctx, j)
if err == nil {
return nil
}
if errors.Is(err, ErrPermanent) {
return h.DLQ.Send(ctx, j, err)
}
if j.Attempt >= MaxAttempts {
return h.DLQ.Send(ctx, j, err)
}
j.Attempt++
return h.Queue.EnqueueAfter(ctx, j, Backoff(j.Attempt))
}ErrPermanent is the small but important escape hatch. Some failures (malformed JSON, deleted resource, user revoked permission) will never succeed no matter how many times you try. Wrapping the error in ErrPermanent tells the retry layer to skip the backoff dance and DLQ immediately. It saves you from watching the same hopeless job fail 5 times in slow motion.
Classifying errors
Not every error deserves a retry. Roughly:
- Transient -- network timeouts, 5xx from upstream, "lock not acquired," "connection reset." Retry with backoff.
- Permanent -- 4xx from upstream where the body says "user not found," validation errors, deserialization failures. Don't retry; go to DLQ.
- Ambiguous -- the response timed out but the upstream might have processed it. This is the one that requires idempotency, which is a whole post of its own. The short answer: dedupe on a stable job key at the consumer side, or make the operation idempotent (PUT-style, not POST-style).
If your handler returns one undifferentiated error for everything, you're stuck with a single retry policy for every failure mode. Tagging errors (with errors.Is / sentinel values, or with a small custom error type) is one of the cheapest improvements you can make to a worker.
Graceful shutdown is mostly context propagation
Here's the rule that takes most teams a year to internalize: the kernel sends SIGTERM first and SIGKILL later, and what you do in between is the entire definition of "graceful."
Kubernetes gives you about 30 seconds by default (terminationGracePeriodSeconds). systemd gives you whatever TimeoutStopSec says. AWS ECS gives you a stop timeout you can configure. The number doesn't matter; the shape of the work does. You have a finite window to stop accepting new jobs, finish the ones in flight, and exit cleanly.
Go's standard library makes this clean once you wire it correctly. The pattern is one root context derived from the OS signals, propagated to everything that does work.
package main
import (
"context"
"errors"
"log/slog"
"net/http"
"os/signal"
"syscall"
"time"
)
func main() {
ctx, stop := signal.NotifyContext(context.Background(),
syscall.SIGINT, syscall.SIGTERM)
defer stop()
pool := worker.NewPool(50, 1000, processJob)
pool.Start(ctx)
srv := &http.Server{
Addr: ":8080",
Handler: newRouter(pool),
}
// serve in a goroutine so we can wait on shutdown
serverErr := make(chan error, 1)
go func() {
if err := srv.ListenAndServe(); err != nil &&
!errors.Is(err, http.ErrServerClosed) {
serverErr <- err
}
close(serverErr)
}()
select {
case <-ctx.Done():
slog.Info("shutdown signal received, draining")
case err := <-serverErr:
slog.Error("server crashed", "err", err)
}
// give the world 25 seconds to wind down
shutdownCtx, cancel := context.WithTimeout(context.Background(),
25*time.Second)
defer cancel()
// 1. stop the HTTP server so no new jobs get submitted
if err := srv.Shutdown(shutdownCtx); err != nil {
slog.Error("http shutdown error", "err", err)
}
// 2. close the pool's input channel and wait for drain
done := make(chan struct{})
go func() {
pool.Stop()
close(done)
}()
select {
case <-done:
slog.Info("workers drained")
case <-shutdownCtx.Done():
slog.Warn("drain timeout exceeded, exiting anyway")
}
}That's the canonical shape. Read it slowly, because every line is there for a reason.
signal.NotifyContext (added in Go 1.16) is the right way to turn signals into a cancellation. It cancels the returned context when the first listed signal arrives. No make(chan os.Signal) plumbing; no leaking goroutines.
The order of shutdown matters. HTTP server first, then pool. If you stopped the pool first, your HTTP handlers would still be accepting requests, calling Submit, and blocking on a closed channel (which panics). Stop the producers, then stop the consumers.
The drain has a timeout. pool.Stop() blocks until all workers exit, which can be forever if a handler is stuck. The shutdownCtx is your insurance: if we can't drain in 25 seconds, we log a warning and exit anyway. The handlers should themselves respect that context, so "exit anyway" doesn't actually mean "abandon mid-write," but the timeout is your floor.
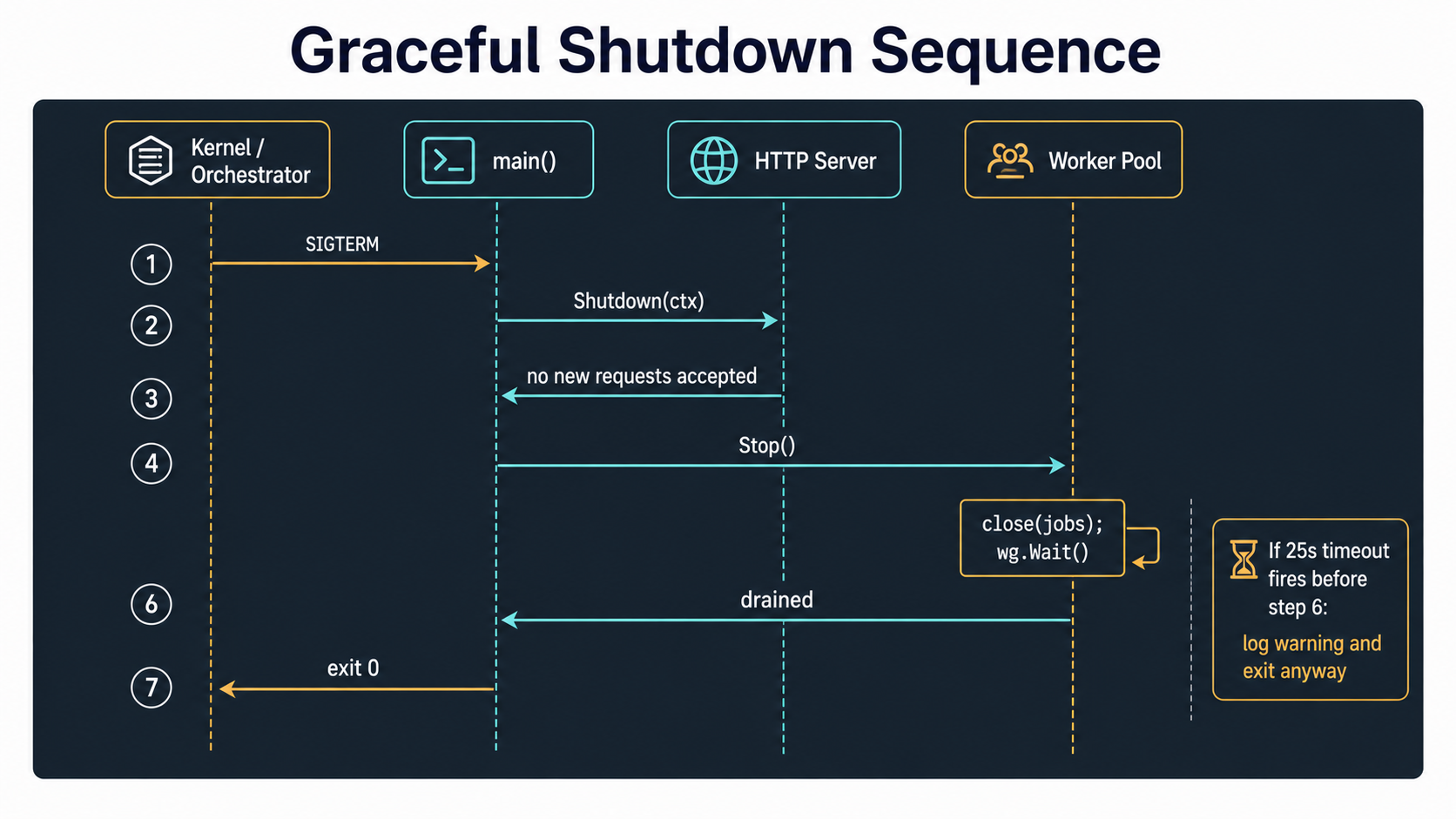
A few subtle traps in this pattern:
SIGKILL is not catchable. If Kubernetes decides your grace period is up, you don't get a chance to drain. Make sure your jobs are recoverable: either idempotent or written so the queue redelivers them when the process comes back. A graceful shutdown is the happy path. It is not a guarantee.
Don't share the same context between "is the app running?" and "is shutdown taking too long?" The first cancels on SIGTERM. The second cancels on a separate timer. Mixing them turns "drain politely" into "abandon immediately."
Watch your iterators. Loops that pull jobs from a queue (the Redis consumer above, a Kafka subscriber, an SQS poller) all need to be cooperative on context cancellation, or shutdown will hang waiting for the next poll to time out on its own.
Distributed-queue acknowledgement
If you're using a real queue (Redis Streams with XACK, SQS with DeleteMessage, RabbitMQ with Ack), shutdown gets one more wrinkle: acknowledge after the handler succeeds, not before. If you ack on receive, then crash, the job is gone. If you ack only after the handler returns nil, then crash, the queue redelivers and your retry/idempotency logic handles it.
The visibility-timeout dance with SQS is the classic example: SQS hides the message for N seconds after delivery, you have to ack (delete) before the timeout, or the message becomes visible again and another consumer picks it up. Set the visibility timeout to be longer than your slowest job by a comfortable margin, and call ChangeMessageVisibility if a job runs long.
Observability you actually need
A worker that runs jobs without telling you what's happening is a worker you'll only hear about during incidents. You need three categories of signal.
Queue depth. How many jobs are waiting? If this number grows unboundedly, your producers are outpacing your consumers and something is broken. Expose it as a gauge:
var queueDepth = promauto.NewGaugeVec(
prometheus.GaugeOpts{
Name: "worker_queue_depth",
Help: "Number of jobs currently buffered.",
},
[]string{"queue"},
)For an in-memory channel, len(p.jobs) gives you the answer. For Redis, LLEN or XLEN. Whatever the backend, sample it once a second.
Job duration. Histograms by job type and outcome:
var jobDuration = promauto.NewHistogramVec(
prometheus.HistogramOpts{
Name: "worker_job_duration_seconds",
Help: "Time spent processing a job.",
Buckets: prometheus.DefBuckets,
},
[]string{"job_type", "result"}, // result = success | error | dlq
)A worker whose p99 doubles over a week is telling you something. Without this metric, you'll find out from a Slack message instead.
Retry rate and DLQ rate. A small bump in retries is the early-warning system for a downstream incident. A spike in DLQ is the late-warning system for a bug you shipped.
var retries = promauto.NewCounterVec(
prometheus.CounterOpts{Name: "worker_retries_total"},
[]string{"job_type"},
)
var dlq = promauto.NewCounterVec(
prometheus.CounterOpts{Name: "worker_dlq_total"},
[]string{"job_type", "reason"},
)Alert on the rate of worker_dlq_total faster than you alert on anything else. A job hitting the DLQ is an unambiguous bad event; a job retrying once is noise.
On the logging side, the bare minimum per job is: a job ID, a job type, an attempt number, the start and end timestamps, and the error (if any). With log/slog that's nearly free:
func processJob(ctx context.Context, j Job) error {
log := slog.With("job_id", j.ID, "job_type", j.Type, "attempt", j.Attempt)
start := time.Now()
log.Info("job start")
defer func() {
log.Info("job end", "duration", time.Since(start))
}()
// ... actual work
return nil
}If you've got distributed tracing already, propagate the trace through the job payload (encode the trace context as part of the job, decode at the consumer). That's the single biggest jump in worker observability you can make if you have OpenTelemetry running. A trace that starts at the HTTP request, jumps the queue, and continues in the worker is the difference between "we don't know" and "here's the slow span."
A few mistakes that show up in code review
After enough Go worker reviews, a handful of the same problems show up. Naming them tends to short-circuit the next round.
Holding a connection across a job. A handler grabs a database connection at the top, runs a 30-second job, returns. That connection was held the whole time. With a connection pool of 100 and 50 workers, you've capped your throughput at 100 long-running jobs in flight. Scope the connection narrower: open near the query, close after.
Catching panic only at the goroutine boundary. A panic in a worker goroutine that isn't recovered crashes the whole process. A recovered panic in the wrong place silently eats the job. The right pattern is to recover per-job, log the panic with full stack, treat it as a job failure (retry or DLQ as appropriate), and let the worker continue.
func (p *Pool) safeHandle(ctx context.Context, j Job) (err error) {
defer func() {
if r := recover(); r != nil {
err = fmt.Errorf("panic: %v\n%s", r, debug.Stack())
}
}()
return p.handler(ctx, j)
}Treating "the queue restarted" as a normal error. It's not. If your worker's connection to Redis or SQS drops, the next handler call should reconnect; the in-flight job should not be retried as if it failed on the application's terms. Often the right move is to log the infra failure separately, refuse to ack the job, and let redelivery handle it.
Sharing mutable state between workers without protection. Each goroutine in a pool is reading from the same jobs channel, but if they share, say, a cache or counter, you need synchronization. Channels make the cross-goroutine handoff safe; they don't make whatever the handler touches safe.
Tuning workers up before profiling. "It's slow, let's add more workers" is almost never the right first move. Usually the bottleneck is a downstream service, a hot lock, or a misplaced time.Sleep. More workers on top of those just amplifies the original problem. Profile, then tune.
Forgetting that "drain" only works if the producer stops first. The order in the shutdown snippet (HTTP server, then pool) isn't aesthetic; it's correctness. If you stop them in the other order, your pool's channel is closed and the handler still calling Submit will panic. This is the single most common bug I see in shutdown code.
A closing thought
The headline features of Go (goroutines, channels, context) are what make all of this easy to write. The features that make it correct (sync.WaitGroup, signal.NotifyContext, the contract of select on a canceled context) are also there, just slightly quieter.
The worker you end up with isn't fancy. It's a goroutine pool plus a queue plus a retry policy plus a graceful shutdown plus enough metrics to know when something's off. None of those pieces is hard on its own. The interesting part is that they have to fit together correctly. Get the lifecycle right, classify your errors, drain on shutdown, and your background system stops being the thing you worry about during deploys.
Then you can go back to worrying about the hard part: the business logic inside the handler.