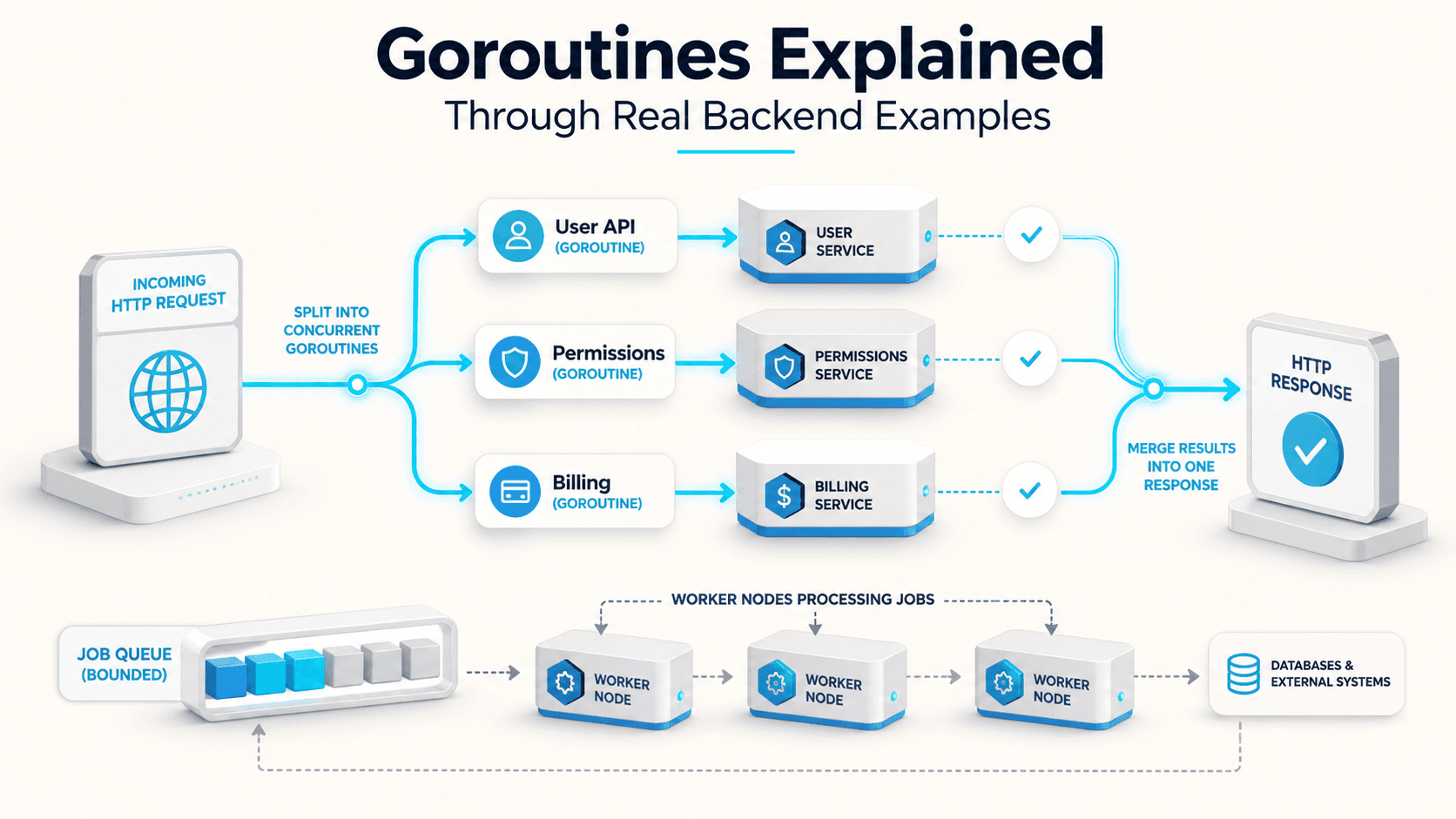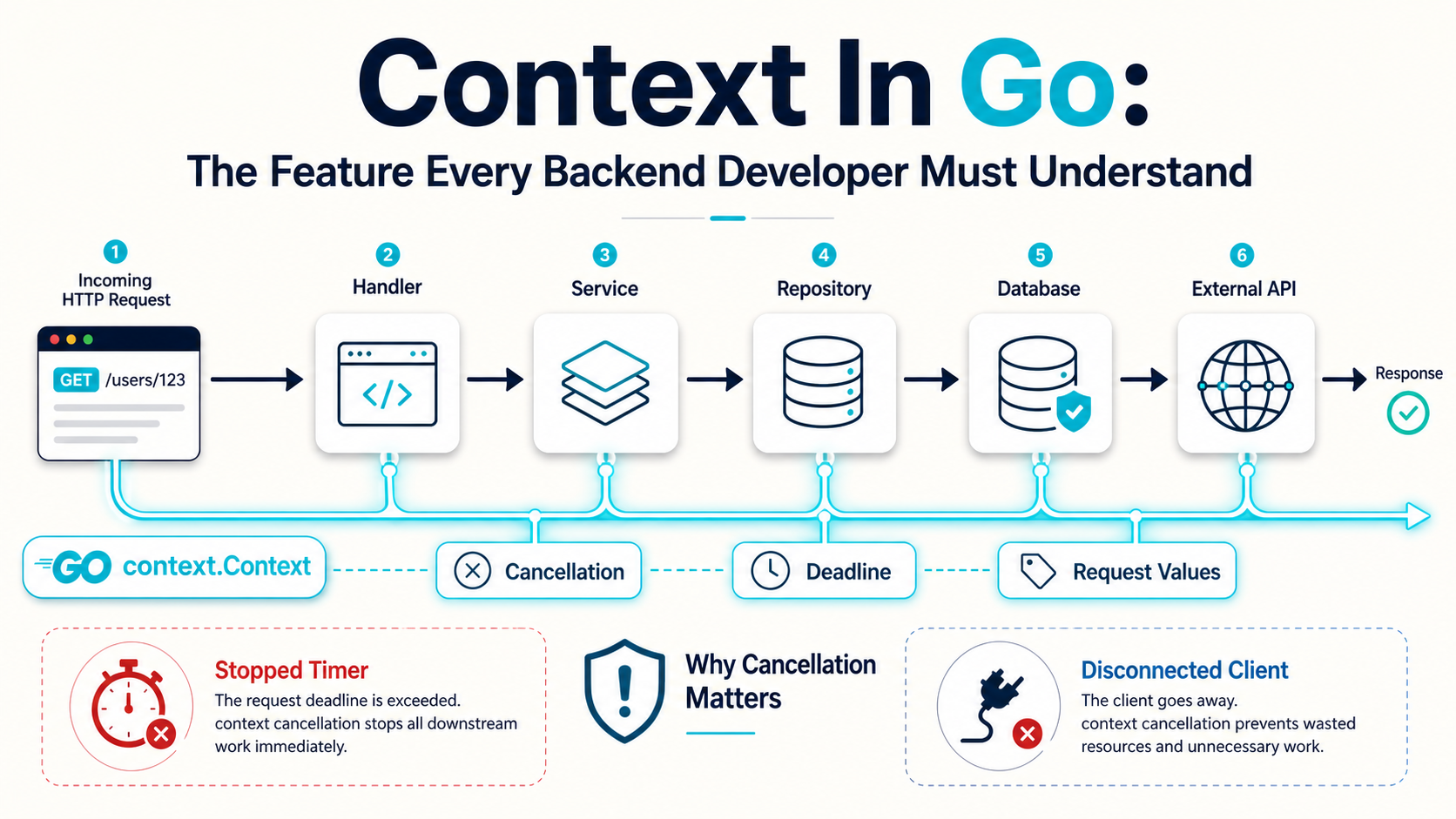
You see it on every Go function signature in the backend:
func GetUser(ctx context.Context, id int64) (*User, error)The first time you read that, ctx looks like noise. A parameter you have to accept and pass along because everyone else does. Some kind of Go convention I'll figure out later.
Then a request hangs. A goroutine quietly stays alive after the user closed the tab. A database connection sits there for 30 seconds because nothing told it to give up. You stare at the production graph and realise: nobody on this code path actually cared whether the work was still wanted.
That's context. It's the answer to a question you didn't realise the codebase was asking on every line:
Is this work still needed?
This article is the version of that answer I wish someone had handed me earlier. We'll look at what context actually does (and what it doesn't), how to wire it through a backend service without going crazy, the timeouts that save your service at 2am, and the small mistakes that turn into goroutine leaks. Plus the newer Go 1.20 / 1.21 APIs that nobody told you about.
By the end, ctx should stop feeling like ceremony and start feeling like the most useful parameter in your function signature.
What context actually is (and isn't)
context.Context carries three things across API boundaries:
- a cancellation signal,
- a deadline,
- request-scoped values (carefully — see below).
That's it. Three jobs. Everything else you'll read about context is just plumbing those three things through your codebase.
What it is not: a thread killer. Context doesn't interrupt goroutines, doesn't unwind your stack, doesn't free memory, doesn't pull a query out of the database engine. It's a piece of paper that says "hey, by the way, nobody wants this anymore." Your code still has to read the paper.
The way you read it is ctx.Done() — a channel that closes when the context is canceled — and ctx.Err(), which tells you the reason:
select {
case <-ctx.Done():
return ctx.Err() // context.Canceled or context.DeadlineExceeded
case result := <-resultCh:
return result, nil
}If your code never selects on ctx.Done() and never passes ctx to a function that does, then context is just an extra parameter doing nothing for you. That's the most common context bug in real codebases — not misuse, just non-use.
Where context comes from in a backend service
In an HTTP server, you don't create the context. The standard library hands it to you.
r.Context() returns a context that's tied to the lifetime of the HTTP request. It cancels automatically when:
- the client closes the connection,
- the HTTP/2 stream is canceled,
ServeHTTPreturns.
So your handler always starts the same way:
func (h *Handler) GetUser(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
user, err := h.users.GetByID(ctx, 42)
if err != nil {
http.Error(w, "failed to get user", http.StatusInternalServerError)
return
}
writeJSON(w, user)
}Notice what's not happening here: no context.Background(), no context.WithTimeout at the top of the handler. The HTTP request already has a lifetime, and that lifetime is the right one to start with. We add timeouts later, around specific slow operations.
Pro Tip: the moment you write
context.Background()inside a request-scoped function, ask yourself why. There are valid reasons (we'll cover one), but the default answer should be "no, use the parent context."
Propagating context through your layers
Context is passed, never stored. Every function that does request-scoped work takes it as the first parameter, conventionally named ctx. Yes, every one. Yes, even the small ones.
Here's the same lookup carried from handler down to the database:
type UserService struct {
repo *UserRepository
}
func (s *UserService) GetByID(ctx context.Context, id int64) (*User, error) {
if id <= 0 {
return nil, errors.New("invalid user id")
}
return s.repo.FindByID(ctx, id)
}
type UserRepository struct {
db *sql.DB
}
func (r *UserRepository) FindByID(ctx context.Context, id int64) (*User, error) {
const query = `SELECT id, email, name FROM users WHERE id = $1`
var user User
err := r.db.QueryRowContext(ctx, query, id).Scan(&user.ID, &user.Email, &user.Name)
if err != nil {
return nil, err
}
return &user, nil
}Three layers, one context, one consistent rule: if the call can do I/O, it takes a context, and that context goes all the way to the I/O boundary.
QueryRowContext is the one that actually matters here. The plain QueryRow doesn't know about cancellation. If you use the non-context version, all the work you did wiring ctx from the handler down was for nothing — your database call won't notice the request being canceled.
This is the trap most teams fall into: you accept ctx everywhere, you pass it around faithfully, and then at the bottom of the stack somebody calls db.Query(...) instead of db.QueryContext(...). Now you have what looks like a context-aware codebase that isn't actually cancelling anything.
Adding timeouts where they belong
The HTTP request might give you 5 seconds. The database lookup deserves 500ms. Those are different budgets, and context lets you express both:
func (r *UserRepository) FindByEmail(ctx context.Context, email string) (*User, error) {
ctx, cancel := context.WithTimeout(ctx, 500*time.Millisecond)
defer cancel()
const query = `SELECT id, email, name FROM users WHERE email = $1`
var user User
err := r.db.QueryRowContext(ctx, query, email).Scan(&user.ID, &user.Email, &user.Name)
if err != nil {
return nil, err
}
return &user, nil
}WithTimeout returns a derived context. It inherits cancellation from its parent (so the HTTP request being canceled still kills the query) AND it adds its own 500ms ceiling. Both signals work; whichever fires first wins.
The defer cancel() line trips a lot of people up. "Why do I cancel a thing that already timed out?" Because the cancel function does more than fire cancellation — it releases the timer and removes the parent's reference to the child. Forget it, and you have a slow leak that compounds under traffic.
A simple rule that's never let me down:
Every
WithTimeout/WithDeadline/WithCancelis followed immediately bydefer cancel(). No exceptions, no "I'll add it later."
Where to put your timeouts
Don't try to slap one big timeout at the top of the handler:
ctx, cancel := context.WithTimeout(ctx, 30*time.Second)
defer cancel()
// database query
// external API call
// cache lookup
// another external API callIt works, but it's blunt. Now if the cache is slow, you blame the database. If the API is hung, you don't know whether to retry or wait. Each boundary deserves its own budget — usually databases, external HTTP calls, and queue publishes:
func (h *Handler) findUser(ctx context.Context, id int64) (*User, error) {
ctx, cancel := context.WithTimeout(ctx, 500*time.Millisecond)
defer cancel()
return h.users.FindByID(ctx, id)
}
func (h *Handler) fetchProfile(ctx context.Context, id int64) (*Profile, error) {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
return h.profiles.Fetch(ctx, id)
}Now the production trace tells you exactly who blew their budget. That's worth the four extra lines.
Outgoing HTTP calls: the one that actually saves your bacon
If your service calls another service, and that service has a bad day, your service has a bad day. Without context, "bad day" can mean "every connection in your pool is stuck waiting on a request that will never return."
http.NewRequestWithContext is how you stop that:
func FetchProfile(ctx context.Context, client *http.Client, userID int64) (*Profile, error) {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
url := fmt.Sprintf("https://profiles.example.com/users/%d", userID)
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
return nil, err
}
resp, err := client.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("profile service returned status %d", resp.StatusCode)
}
var profile Profile
if err := json.NewDecoder(resp.Body).Decode(&profile); err != nil {
return nil, err
}
return &profile, nil
}The context covers the entire request lifecycle: dialing, sending, reading headers, reading the body. Cancel at any point and the connection comes back to your pool instead of being stuck in some half-read state.
Pro Tip:
http.Client.Timeoutand a context timeout aren't the same thing. The client timeout is "every request through me dies after N seconds." The context timeout is "this specific request flow has its own budget." Use both —Client.Timeoutas a backstop, context as the per-call budget. Never rely onhttp.DefaultClient; it has no timeout at all.
Cancellation in goroutines (where most leaks come from)
This is the part where most production leaks live. You spawn a goroutine, the request ends, and the goroutine just... keeps going. Every request adds another one. Memory grows. Eventually somebody pages you.
This worker, for example, is a leak generator:
func StartWorker(ctx context.Context, jobs <-chan Job) {
go func() {
for job := range jobs {
process(job)
}
}()
}It accepts ctx. It even has a parameter named ctx. But the goroutine never reads it. The only way out is for someone, somewhere, to close jobs. If that doesn't happen — and in practice it usually doesn't — the goroutine is immortal.
The fix is select:
func StartWorker(ctx context.Context, jobs <-chan Job) {
go func() {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok {
return
}
if err := process(ctx, job); err != nil {
// log or send to a dead-letter — your call
return
}
}
}
}()
}Two ways out: the channel closes, or the context cancels. Either is fine. Same applies to background loops — every cache refresher, every poller, every "every 30 seconds do X" goroutine should look like that.
If a goroutine is alive when nobody is reading its output, it's a leak even if it's "doing useful work." Useful work nobody asked for is just CPU you're paying for.
select + context = the cancellation pattern
You're going to write this shape a lot:
select {
case <-ctx.Done():
return ctx.Err()
case result := <-resultCh:
return result, nil
}It's the universal "wait for the thing or give up" pattern. Get comfortable with it. Once you internalize that every blocking operation in a goroutine deserves a <-ctx.Done() case in its select, you've solved 80% of the goroutine-leak class of bugs.
The error you return matters too. Don't swallow it:
// good — the caller can errors.Is() this
return Result{}, ctx.Err()
// good — wrap if you want to add context
return Result{}, fmt.Errorf("wait for fraud check: %w", ctx.Err())
// bad — caller can't tell timeout from cancellation
return Result{}, errors.New("operation failed")context.DeadlineExceeded and context.Canceled mean different things. A timeout might warrant a retry; a cancellation usually doesn't. Throwing the difference away leaves your retry layer guessing.
Request-scoped values: the part to be careful with
context.WithValue lets you tuck data into the context. This is genuinely useful for things that cross every layer of your stack — request IDs, trace IDs, the authenticated user. It's also genuinely dangerous if you treat it as a "globals through the back door" mechanism.
The right way looks like this:
type requestIDKey struct{}
func WithRequestID(ctx context.Context, requestID string) context.Context {
return context.WithValue(ctx, requestIDKey{}, requestID)
}
func RequestIDFromContext(ctx context.Context) (string, bool) {
requestID, ok := ctx.Value(requestIDKey{}).(string)
return requestID, ok
}A custom key type means no other package can collide with you. The exported helpers mean callers don't depend on the key type at all — they call WithRequestID and RequestIDFromContext.
The wrong way:
ctx = context.WithValue(ctx, "user_id", userID) // string keys collide
ctx = context.WithValue(ctx, "limit", 100) // not request metadata, just a parameter
ctx = context.WithValue(ctx, "db", db) // hides a dependencyThe litmus test: would this value naturally appear in the function signature? If yes, it's a parameter, not a context value. If it's a thing every layer needs to know about (trace ID, tenant, request ID), context is fine. If it's an argument to one specific operation, it goes in the argument list.
Go 1.20+: cancellation with a cause
Go 1.20 added context.WithCancelCause and context.Cause. The motivation is simple: ctx.Err() only tells you "canceled" or "deadline exceeded." That's often not enough — you want to know why it was canceled.
func RunFraudCheck(ctx context.Context) error {
ctx, cancel := context.WithCancelCause(ctx)
defer cancel(nil)
errCh := make(chan error, 1)
go func() {
errCh <- callFraudService(ctx)
}()
select {
case <-ctx.Done():
return context.Cause(ctx)
case err := <-errCh:
if err != nil {
cancel(fmt.Errorf("fraud check failed: %w", err))
return context.Cause(ctx)
}
return nil
}
}ctx.Err() still gives you the broad category. context.Cause(ctx) gives you the specific error you (or anyone upstream) supplied to cancel(...). It's the right tool when "canceled" alone is not actionable enough — for instance, when one of several parallel operations failed and you want the others to know which one.
You don't need WithCancelCause everywhere. Use it when the extra information genuinely changes how you handle the failure. For routine cancellation, plain WithCancel is still fine.
Go 1.21+: detaching work from the request
Sometimes you want work to outlive the request that started it. The classic case: the user's main operation succeeded, you want to write an audit log entry, and you don't want the audit write to be canceled if the client disconnects right after seeing the response.
context.WithoutCancel (Go 1.21+) gives you a context that copies the values from the parent but detaches from the parent's cancellation:
func (h *Handler) UpdateEmail(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
if err := h.service.UpdateEmail(ctx, 42, "new@example.com"); err != nil {
http.Error(w, "failed to update email", http.StatusInternalServerError)
return
}
auditCtx := context.WithoutCancel(ctx)
go func() {
ctx, cancel := context.WithTimeout(auditCtx, time.Second)
defer cancel()
_ = h.auditLog.Record(ctx, "email_updated", 42)
}()
w.WriteHeader(http.StatusNoContent)
}The thing nobody mentions about WithoutCancel is the part that matters: detached work needs its own lifecycle. If you detach without adding a new timeout, you've created a goroutine that can run forever. The context.WithTimeout(auditCtx, time.Second) line isn't optional — it's the whole point of doing this safely.
And honestly? In most production systems, audit-style work belongs in a real queue, not in a fire-and-forget goroutine off an HTTP handler. WithoutCancel is a good escape hatch, not a default pattern.
The mistakes that bite (and how to spot them)
After enough reviews, the same handful of context bugs shows up over and over.
1. context.Background() halfway down the stack
func (s *UserService) GetByID(id int64) (*User, error) {
ctx := context.Background() // <-- breaks the chain
return s.repo.FindByID(ctx, id)
}Symptom: cancellation works in the handler but never reaches the database. Fix: accept ctx as the first parameter and pass it down. Use context.Background() only at the actual root — main, top-level commands, tests, or genuinely-detached background work.
2. Storing context in a struct
type UserService struct {
ctx context.Context // <-- whose lifetime is this?
repo *UserRepository
}A service usually outlives one request. A request context lives for one request. They don't match. Pass context to the methods, not the constructor.
3. Forgetting defer cancel()
ctx, cancel := context.WithTimeout(parentCtx, time.Second)
return doWork(ctx) // cancel never called → small leak per requestThis is the number one cause of slow context-tree growth in long-running services. Always pair WithTimeout / WithCancel with defer cancel() on the next line. If you're tempted to skip it because "the timeout will fire anyway," you've also kept a timer alive longer than needed.
4. String keys for values
ctx = context.WithValue(ctx, "request_id", id) // collision waiting to happenDefine a private key type. Three lines of boilerplate, zero collisions, and your IDE can find every reader.
5. Passing a nil context
user, err := service.GetUser(nil, 42) // panic cityIf you don't have a context yet — for example, you're calling backend code from a place that didn't pass one — use context.TODO(). It behaves the same as Background() but signals to readers (and to go vet and staticcheck) that this is unfinished. Treat every TODO() as design debt to clean up.
6. Treating context as a dependency container
ctx = context.WithValue(ctx, "db", db)
ctx = context.WithValue(ctx, "logger", logger)Don't. That's what struct fields and constructors are for. Context is for lifetime and request-scoped metadata, not for hiding wiring.
7. Not checking cancellation in long loops
If you're processing a big batch, sprinkle a non-blocking context check at the top of the iteration:
for _, item := range items {
select {
case <-ctx.Done():
return ctx.Err()
default:
}
if err := process(ctx, item); err != nil {
return err
}
}You don't need this around every single line of code — it's overkill for tight CPU loops. It earns its keep around loops that do I/O, retries, sleeps, or anything that takes meaningful time per iteration.
Putting it all together
Here's what a clean request flow looks like end-to-end. This is small on purpose — the value is in the lifetime story, not the volume of code:
type Handler struct {
users *UserRepository
profiles *ProfileClient
}
func (h *Handler) GetUserProfile(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
userID := int64(42) // simplified — parse from path in real code
user, err := h.findUser(ctx, userID)
if err != nil {
http.Error(w, "failed to load user", http.StatusInternalServerError)
return
}
profile, err := h.fetchProfile(ctx, user.ID)
if err != nil {
http.Error(w, "failed to load profile", http.StatusBadGateway)
return
}
writeJSON(w, struct {
User *User `json:"user"`
Profile *Profile `json:"profile"`
}{user, profile})
}
func (h *Handler) findUser(ctx context.Context, id int64) (*User, error) {
ctx, cancel := context.WithTimeout(ctx, 500*time.Millisecond)
defer cancel()
return h.users.FindByID(ctx, id)
}
func (h *Handler) fetchProfile(ctx context.Context, id int64) (*Profile, error) {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
return h.profiles.Fetch(ctx, id)
}r.Context() ties the work to the HTTP request. Each slow boundary gets its own derived timeout. Every cancel function has a defer. No layer creates an unrelated context.Background(). If the client disconnects, every downstream call notices at the same moment.
That's it. That's the whole pattern. It's not flashy. It's just the version that doesn't page you on Saturday.
Wrapping it all up
Context isn't ceremony. It's the answer to "is this work still wanted?" threaded through every layer of a Go backend, and once you internalize that question, the API stops feeling weird and starts feeling necessary.
Quick rules to keep close:
- Pass
r.Context()from the handler. Takectx context.Contextas the first parameter on any function that does I/O. - Use context-aware APIs at every I/O boundary —
QueryRowContext,NewRequestWithContext, anything ending inContext. WithTimeout/WithCancelalways come withdefer cancel()on the next line.- Goroutines that block must
selecton<-ctx.Done(). No exceptions. - Custom key types for values. No string keys, no dependency container hacks.
- Use
WithCancelCausewhen "canceled" isn't enough information. - Use
WithoutCancelfor genuinely detached work — and always give that work a fresh timeout.
Read context as a piece of plumbing, sure, but plumbing has a job: it carries the signal that says "stop working." A backend service that handles that signal cleanly almost never has the kinds of bugs that wake you up. One that doesn't, almost always does.
Pick one service this week, grep for context.Background(), and audit each hit. I'd bet a coffee at least one of them is the start of a quiet leak. Fix it before it finds you. 👊