So, you've written go func() { ... }() once or twice and the program did exactly what you expected. Good news: the syntax really is that easy. Bad news: the syntax is the easy part.
Goroutines are one of those features that look like a free win in the tutorial and stop looking free the first time you ship them. You start a goroutine to "make this faster." A week later, it's eating connection pool slots. A month later, you're chasing a goroutine leak through pprof and learning more about scheduler behavior than you wanted to.
Here's the thing nobody puts on the front of the docs: goroutines aren't really a performance feature. They're a structure feature. They let you express "these things can happen at the same time" cleanly. Whether that translates into faster code depends entirely on what your program actually spends its time doing — and most backend code spends its time waiting.
This article is a tour of goroutines through the patterns I actually use in real services:
- concurrent API calls inside one HTTP handler,
- bounded worker pools for batch jobs,
- background loops that shut down cleanly,
- the five mistakes I keep finding in code reviews.
We'll favor errgroup over raw channels where it makes sense, treat context as a first-class citizen, and finish each section with a sentence about why the pattern looks that way. By the end, you should be able to look at goroutine code and predict its production behavior without running it.
What a goroutine actually solves
A goroutine is useful when work can happen independently of other work. In a backend, that usually means one of:
- calling several downstream APIs that don't depend on each other,
- processing many jobs from a queue-shaped source,
- running periodic background tasks,
- handling network connections,
- doing cleanup or scheduled maintenance.
A goroutine isn't "make this faster." It's "let these things overlap." If the operations have to happen in sequence anyway, goroutines can't help. If they really are independent and they spend time waiting on the network or disk, goroutines can be a huge win — because the wait gets shared instead of stacked.
The smallest possible goroutine is also the most useless one:
go func() {
fmt.Println("running in another goroutine")
}()That starts the function concurrently with the rest of main. But there's nothing waiting for it, no cancellation, no error path. Run that in production and the goroutine either never runs (program exits first) or quietly disappears into the void (its output gets lost). Real backend goroutines need at least one of:
- a
context.Contextto know when to stop, - a
sync.WaitGrouporerrgroup.Groupto be waited on, - a channel to communicate,
- a limit, so you don't spawn a million of them.
Most of the patterns in this article are just careful combinations of those four things.
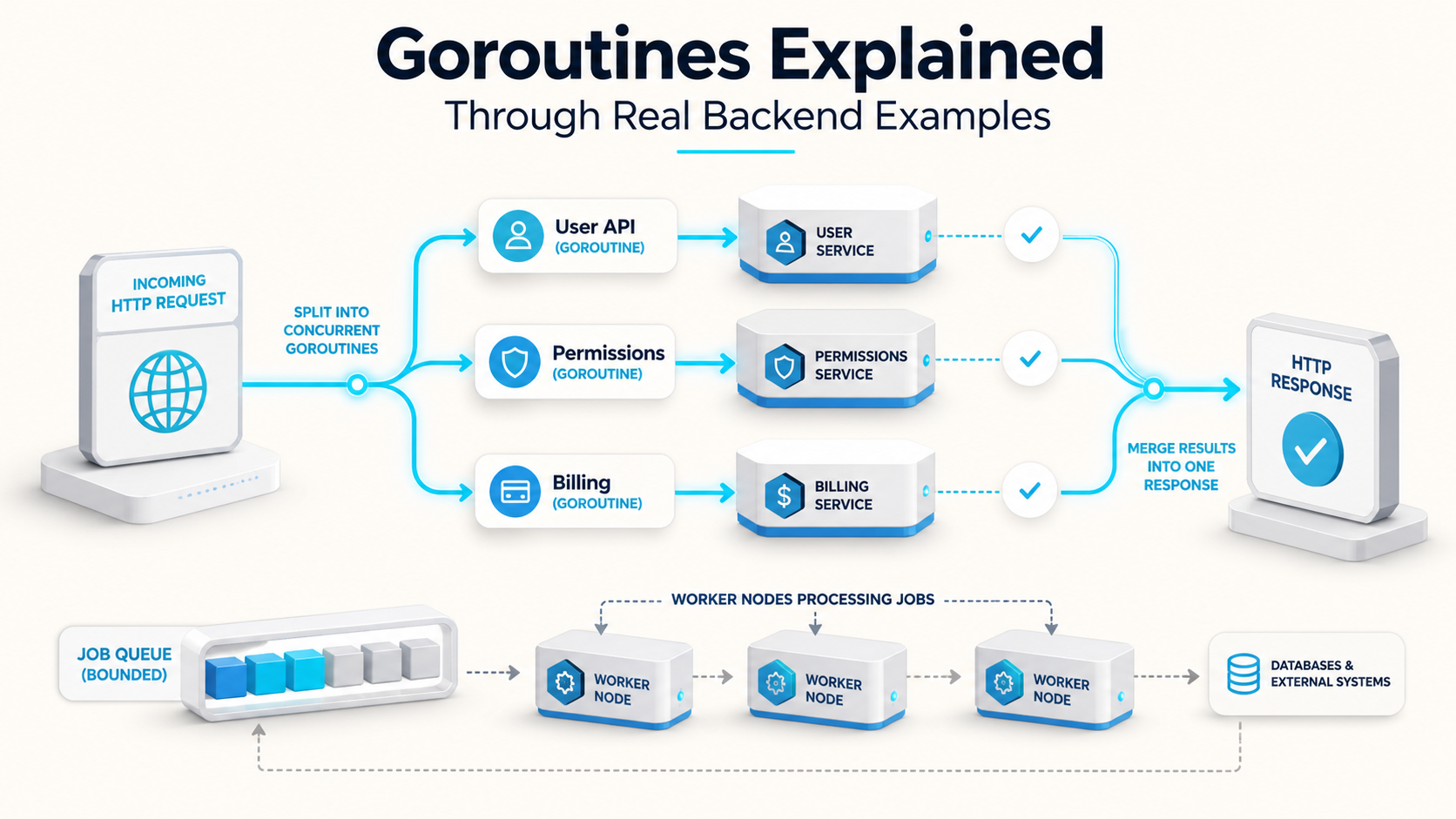
Pattern 1: concurrent API calls with errgroup
The classic case. You have an endpoint:
GET /users/{id}/summaryBuilding the response needs three independent calls — user profile, permissions, billing status. Done sequentially, your latency is the sum of all three. Done concurrently, your latency is the slowest one. That's the kind of free win goroutines were designed for.
You could do it with raw sync.WaitGroup, channels, and manual error tracking. Don't. For request-scoped parallel work, golang.org/x/sync/errgroup is the right tool — it handles the waiting, the first-error propagation, and the cancellation in one tidy API:
package userapi
import (
"context"
"encoding/json"
"fmt"
"net/http"
"golang.org/x/sync/errgroup"
)
type User struct {
ID string `json:"id"`
Name string `json:"name"`
}
type Permissions struct {
CanPurchase bool `json:"can_purchase"`
}
type BillingStatus struct {
Active bool `json:"active"`
}
type Summary struct {
User User `json:"user"`
Permissions Permissions `json:"permissions"`
Billing BillingStatus `json:"billing"`
}
type Client struct {
httpClient *http.Client
baseURL string
}
func (c *Client) FetchSummary(ctx context.Context, userID string) (Summary, error) {
g, ctx := errgroup.WithContext(ctx)
var user User
var permissions Permissions
var billing BillingStatus
g.Go(func() error {
result, err := fetchJSON[User](ctx, c.httpClient, c.baseURL+"/users/"+userID)
if err != nil {
return fmt.Errorf("fetch user: %w", err)
}
user = result
return nil
})
g.Go(func() error {
result, err := fetchJSON[Permissions](ctx, c.httpClient, c.baseURL+"/users/"+userID+"/permissions")
if err != nil {
return fmt.Errorf("fetch permissions: %w", err)
}
permissions = result
return nil
})
g.Go(func() error {
result, err := fetchJSON[BillingStatus](ctx, c.httpClient, c.baseURL+"/users/"+userID+"/billing")
if err != nil {
return fmt.Errorf("fetch billing status: %w", err)
}
billing = result
return nil
})
if err := g.Wait(); err != nil {
return Summary{}, err
}
return Summary{User: user, Permissions: permissions, Billing: billing}, nil
}
func fetchJSON[T any](ctx context.Context, client *http.Client, url string) (T, error) {
var zero T
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
return zero, err
}
resp, err := client.Do(req)
if err != nil {
return zero, err
}
defer resp.Body.Close()
if resp.StatusCode < 200 || resp.StatusCode >= 300 {
return zero, fmt.Errorf("unexpected status code: %d", resp.StatusCode)
}
var result T
if err := json.NewDecoder(resp.Body).Decode(&result); err != nil {
return zero, err
}
return result, nil
}There's a lot to like in this small example.
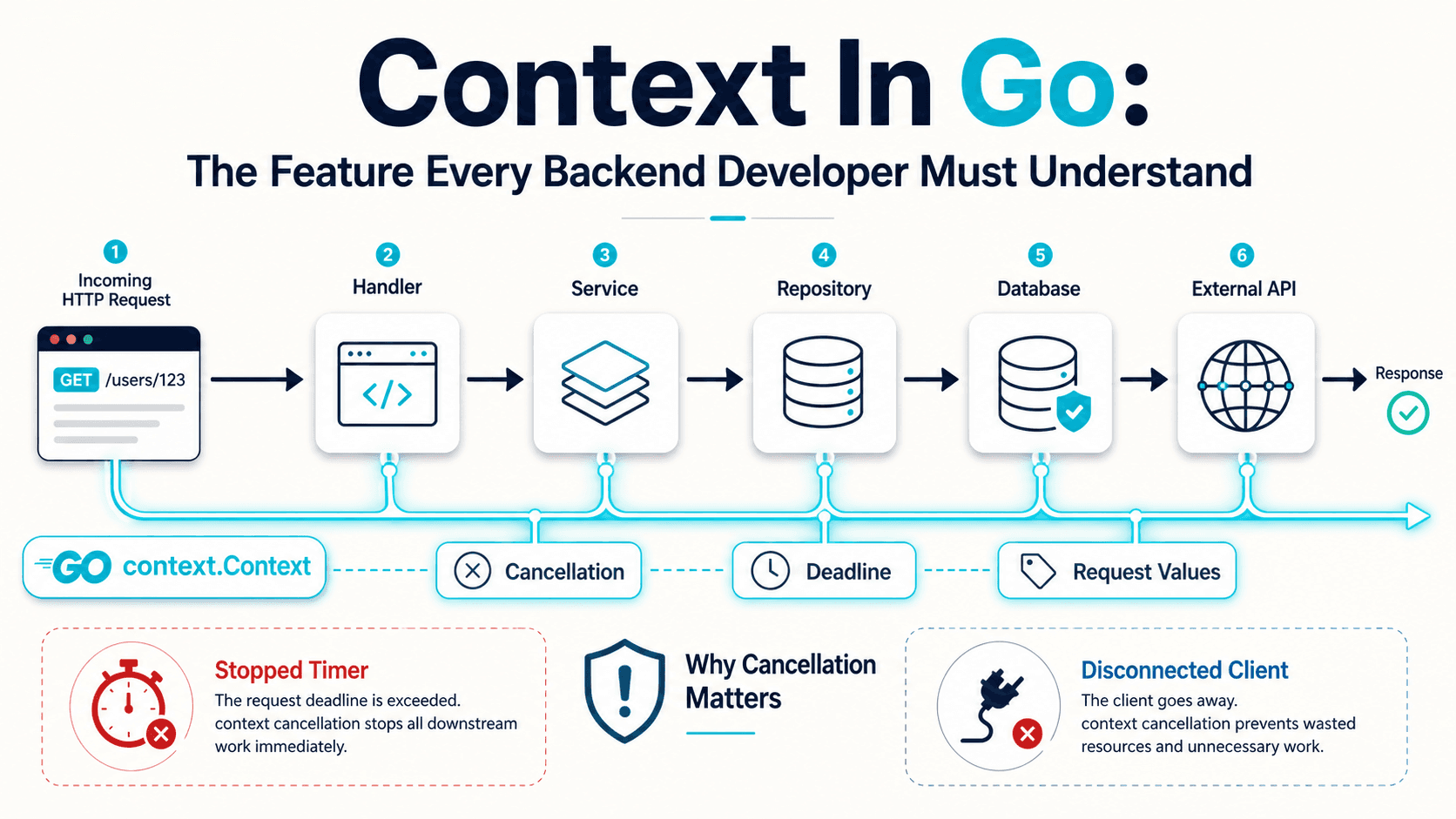
errgroup.WithContext(ctx) returns a group AND a derived context. The moment any one of the three calls returns an error, that derived context cancels — which means the other two in-flight HTTP requests get told to give up too. No partial work running on a request that's already failed.
Each goroutine writes to a different variable. That's the rule that makes this safe without a mutex: one writer per memory location, and we only read those variables after g.Wait() returns. Touch that rule and you've introduced a data race; respect it and you don't need synchronization.
http.NewRequestWithContext is the unsung hero. It ties each HTTP call to the (now possibly-canceled) errgroup context. If the user closes their tab, the r.Context() cancels, the errgroup context cancels, and every in-flight HTTP request gets canceled with it. Connections come back to the pool instead of getting stuck.
Pro Tip: the
defer resp.Body.Close()line on every response isn't optional. If you skip it, the underlying connection stays in some half-finished state and the HTTP transport can't reuse it. The first time you debug "why is my service running out of file descriptors" you'll never forget this rule again.
fetchJSON[T] uses generics (Go 1.18+). Before generics, you'd write the same thing three times. Now you write it once and let the compiler do its job.
Pattern 2: bounded worker pool
Different problem now. You have 10,000 user IDs. For each one you need to call a service or update a row. The naive version:
for _, userID := range userIDs {
go processUser(ctx, userID)
}That spawns 10,000 goroutines. Each one tries to grab a database connection from your pool of, say, 20. Most of them stall waiting for connections. Your downstream service sees a request spike that looks like a small DDoS. Your own process scheduler gets unhappy. The number of goroutines isn't the problem — the lack of a limit is.
A worker pool fixes it:
package jobs
import (
"context"
"fmt"
"sync"
)
type Job struct {
UserID string
}
type Processor interface {
ProcessUser(ctx context.Context, userID string) error
}
func ProcessUsers(ctx context.Context, processor Processor, userIDs []string, workerCount int) error {
if workerCount <= 0 {
return fmt.Errorf("workerCount must be greater than zero")
}
jobs := make(chan Job)
errs := make(chan error, 1)
var wg sync.WaitGroup
for i := 0; i < workerCount; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for job := range jobs {
if err := processor.ProcessUser(ctx, job.UserID); err != nil {
select {
case errs <- err:
default:
}
return
}
}
}()
}
go func() {
defer close(jobs)
for _, userID := range userIDs {
select {
case <-ctx.Done():
return
case jobs <- Job{UserID: userID}:
}
}
}()
done := make(chan struct{})
go func() {
wg.Wait()
close(done)
}()
select {
case <-ctx.Done():
return ctx.Err()
case err := <-errs:
return err
case <-done:
return nil
}
}This looks like a lot of moving parts the first time you read it. Let's break it down:
workerCountis the limit. Pass10and at most 10 things are processing at once, regardless of input size.- The
jobschannel is the dispatch lane. Workersrangeover it; the producer goroutine closes it when the input is exhausted. - The
errschannel has capacity 1 because we only care about the first error. The non-blockingselectsend means a worker doesn't block trying to report an error if another worker already did. - The
donechannel + the third goroutine give us a signal that "all workers exited" without making the main goroutine try to wait on aWaitGroupdirectly. - The final
selectis the supervisor: cancellation wins, first error wins, or the whole thing finishes cleanly.
There's a simpler version using errgroup.SetLimit:
g, ctx := errgroup.WithContext(ctx)
g.SetLimit(10)
for _, userID := range userIDs {
userID := userID // pre-Go 1.22 capture; not needed on 1.22+
g.Go(func() error {
return processUser(ctx, userID)
})
}
if err := g.Wait(); err != nil {
return err
}SetLimit(n) caps the number of goroutines actively running in the group at n. The g.Go(...) call blocks if the group is at capacity, so this is automatic backpressure on a per-iteration basis — no manual channel plumbing.
When do you reach for the manual version vs errgroup.SetLimit? Honestly, for most "process this list with N workers" cases, SetLimit wins on simplicity. The manual version pays off when you want different behavior — say, the workers should keep going past the first error (instead of stopping the group), or you want different error semantics, or you need to reuse the same worker pool across multiple producers.
Important caveat: this is an in-process worker pool. If your process dies, every job in flight dies with it. That's fine for fan-out within a single request, terrible for "ship this email to 10,000 users overnight." Long-running batch jobs belong in a real durable queue (Redis Streams, RabbitMQ, SQS, etc.), not in your service's RAM.
Pattern 3: long-running background loops
Cache refreshers. Metrics flushers. Periodic cleanup. Polling. Every backend service eventually grows a few of these.
The wrong version:
func Start() {
go func() {
for {
doWork()
time.Sleep(time.Minute)
}
}()
}There's no way to stop this. It runs forever. When your service is shutting down, this goroutine is still running. When doWork panics, the whole process panics. When traffic moves to a new pod, this one keeps refreshing its cache until SIGKILL eventually catches up.
The right version takes a context, uses a ticker, and selects:
package background
import (
"context"
"log/slog"
"time"
)
type Refresher interface {
Refresh(ctx context.Context) error
}
func RunCacheRefresher(ctx context.Context, logger *slog.Logger, refresher Refresher, interval time.Duration) {
ticker := time.NewTicker(interval)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
logger.Info("cache refresher stopped", "reason", ctx.Err())
return
case <-ticker.C:
if err := refresher.Refresh(ctx); err != nil {
logger.Error("cache refresh failed", "error", err)
}
}
}
}And the wiring in main (or your server setup):
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
go RunCacheRefresher(ctx, logger, refresher, 5*time.Minute)
// ... server starts ...
// During graceful shutdown:
cancel()Now everything works the way you'd hope. The goroutine stops when the parent context cancels. Each refresh inherits the same context, so individual operations can be canceled mid-flight. Failed refreshes get logged with structured fields instead of swallowed. The ticker is stopped via defer, releasing its resources.
The trick I see most often missed: the inner refresher.Refresh(ctx) call uses the same context the outer loop watches. That means cancel() doesn't just stop future iterations — it interrupts the currently-running refresh too, if Refresh is well-behaved. Without that, your shutdown blocks for up to one full refresh duration on every restart. Multiply by every background loop in your service and you've got a slow deploy.
Pro Tip: any goroutine that's alive longer than one HTTP request needs a
selectwith<-ctx.Done()somewhere in its main loop. No exceptions. The "I'll add cancellation later" goroutine is the one you'll find leaking memory at 3am.
The five mistakes I keep finding in production
Different codebase, different team, same five bugs. Here they are, ranked roughly by how often they show up.
1. Starting goroutines without a stop path
func Start() {
go func() {
for {
doWork()
time.Sleep(time.Minute)
}
}()
}If there's no way to stop the goroutine from outside, it's not a feature, it's a leak. Always accept a context. Always select on <-ctx.Done(). You saw the fix above.
2. Errors that disappear into a goroutine
go func() {
_ = sendEmail(ctx, userID)
}()That underscore is doing a lot of moral weight. Sometimes "best effort" is genuinely fine. Often it's hiding a real failure that nobody will notice until customer support escalates a "my receipt never arrived" ticket.
A goroutine should never be a place where errors quietly evaporate. Pick one:
- return the error through
errgroupso the caller sees it, - log it with enough context that someone could investigate,
- send the failed job to a durable queue for retry,
- record a failure metric so dashboards notice the trend.
If you genuinely don't care about the error, write a comment explaining why. The comment is the contract that says "yes, this is best-effort, here's why we accept that."
3. Unbounded concurrency
for _, item := range items {
go process(item)
}The go keyword is fine. The unbounded for around it is not.
Use errgroup.SetLimit, a worker pool with a fixed worker count, or a semaphore channel. Whatever you do, the answer to "how many goroutines could this start?" should never be "depends on the input." Inputs grow. Sometimes inputs come from users.
4. Shared state without synchronization
var processed []string
for _, userID := range userIDs {
go func() {
processed = append(processed, userID)
}()
}Multiple goroutines, one slice, append. That's a classic data race, and go test -race will scream the moment it sees a real workload exercise it.
Two clean options. Mutex around the shared state:
var (
mu sync.Mutex
processed []string
)
g, ctx := errgroup.WithContext(ctx)
for _, userID := range userIDs {
userID := userID
g.Go(func() error {
if err := processUser(ctx, userID); err != nil {
return err
}
mu.Lock()
processed = append(processed, userID)
mu.Unlock()
return nil
})
}Or the no-shared-state version: have each goroutine send its result on a channel and let one collector goroutine append. Either is fine. The rule is just: if more than one goroutine writes to the same memory, protect it or redesign so they don't.
The
userID := userIDshadow at the top of the loop body is legacy. It's needed on Go versions before 1.22, where loop variables were shared across iterations. On 1.22+ each iteration gets its own variable and the shadow is unnecessary. If your project supports both, keep the shadow; if you've moved on, you can drop it.
5. Treating goroutines as a job queue
A goroutine is in-process. If your service crashes, every goroutine in flight dies. Their state is in your service's RAM, which is now no longer running.
That's a deal-breaker for anything you actually need to retry across restarts:
- email sending,
- payment retries,
- background data sync,
- anything you'd put in a "background jobs" admin page.
Use goroutines for in-request fan-out, short-lived background work, internal service loops. Use a real durable queue for everything that has to survive a deploy. The signs you've outgrown goroutines and need a queue:
- you're building retry logic in goroutines,
- you want to schedule work for "in 24 hours,"
- you want to see failed jobs and replay them,
- multiple service instances should split the work,
- jobs should keep running if the original requester goes away.
A goroutine is a concurrency primitive. It's not a storage system.
When to use goroutines (and when not to)
The strongest signal you should be using goroutines:
The operation spends time waiting, and other useful work could happen during that wait.
That's it. Network I/O, disk I/O, sleeping, anything that doesn't burn CPU — goroutines turn the wait time into shared time.
The signs you shouldn't be reaching for them:
- the work is sequential anyway (output of A feeds into B),
- the work is CPU-bound and you're already saturating cores,
- you'd be hiding slowness instead of making it observable,
- you're spawning unbounded goroutines from user input,
- you're using them to avoid building proper job persistence,
- you're sharing mutable state without protecting it.
Concurrency has a cost: more states to reason about, more failure paths, more tests, more ways to leak. The cost is worth it when concurrency genuinely matches the problem. It's never worth it as a stylistic choice.
A short code-review checklist
When I review Go code that uses goroutines, I run through five questions, fast:
- Where does this goroutine end? Cancel, channel close, completion — there should be exactly one obvious answer.
- What's the limit? Worker count,
SetLimit, semaphore — the answer can't be "however many the input has." - Where do errors go?
errgroup, log line, queue, metric — pick one explicitly. - Is the context propagated? Every blocking I/O operation should accept it. Every long-running select should listen on
<-ctx.Done(). - Is shared state protected? Mutex, channel, or "each goroutine writes to a different variable I only read after
Wait" — declare which one and stick to it.
If any of those answers is fuzzy, the code isn't done. That's the line.
Wrapping it all up
Goroutines are one of Go's best features and one of its easiest features to misuse. The reason they look free in tutorials and feel expensive in production is the same reason: the language gives you concurrency cheaply, but cheap concurrency is more concurrency to think about, not less.
The patterns that hold up:
errgroup.WithContextfor parallel work inside one request,- bounded worker pools (or
SetLimit) for batch jobs, - context-aware background loops with
selecton<-ctx.Done(), - a durable queue, not a goroutine, for anything that has to survive a deploy.
The mistakes that bite:
- goroutines you can't stop,
- errors that get dropped on the floor,
- unbounded concurrency on user input,
- shared state without protection,
- using a goroutine where you actually needed a queue.
Or, condensed to one sentence:
Start goroutines deliberately, limit them explicitly, cancel them properly, and never let errors disappear.
That's how goroutines stay one of Go's superpowers instead of one of its production gotchas. Go write something concurrent — and may your race detector stay quiet. 👊