Code review isn't one thing. A good review checks many layers at once:
- Does the code solve the problem?
- Does it preserve existing behavior?
- Is it secure?
- Is authorization correct?
- Are database queries safe?
- Are migrations deployable?
- Are tests meaningful?
- Is the pull request easy to understand?
Human reviewers are still essential. But AI can help as an additional review layer, especially in CI/CD. Claude can read a pull request diff, look at risky files, summarize behavior changes, detect suspicious patterns, and leave advisory comments for reviewers.
The key word there is advisory. At least at the beginning, AI review should help humans review faster — not block merges automatically, not replace senior judgment, and definitely not be the only security layer.
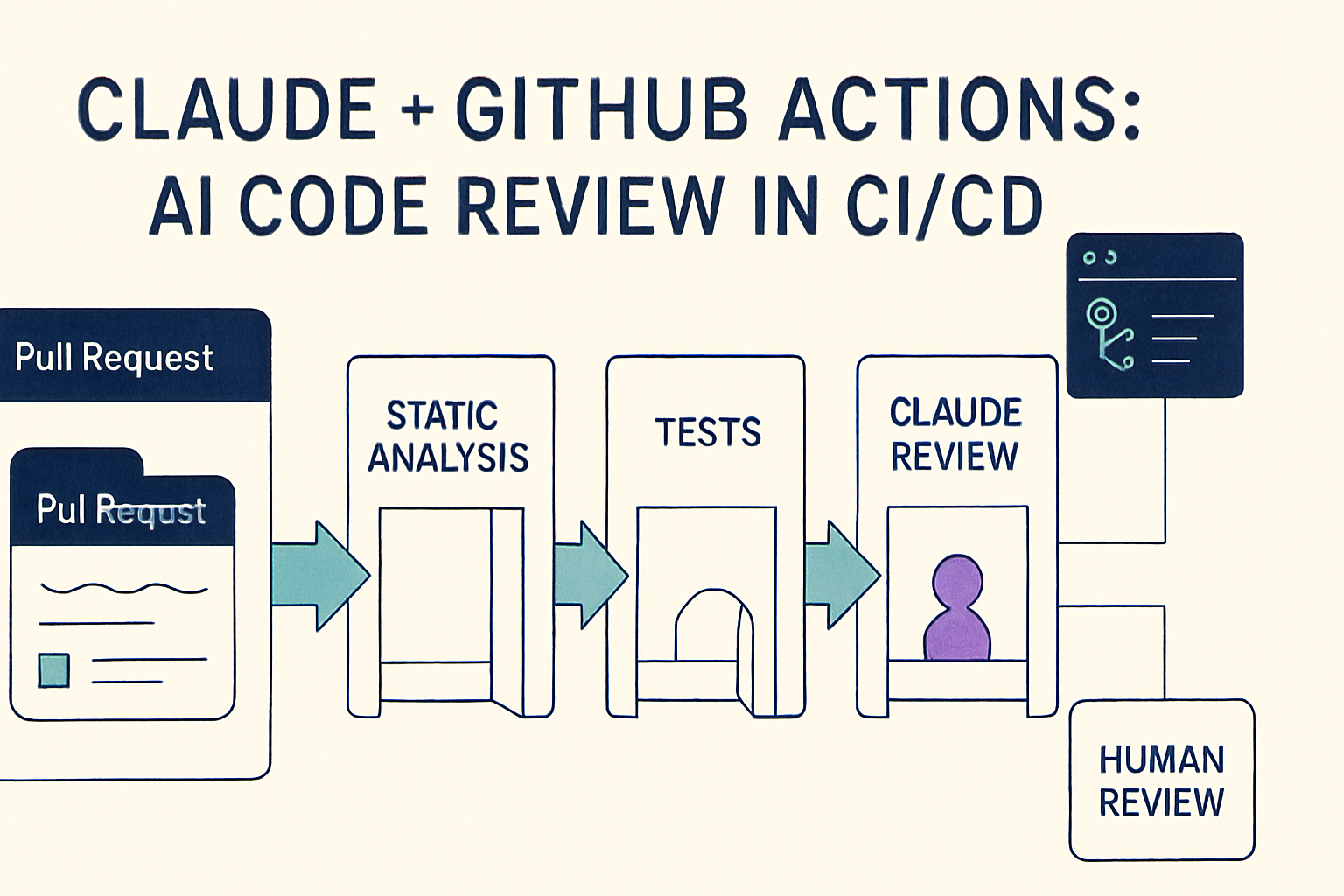
A good first version looks like this:
Pull request opened
↓
GitHub Actions runs tests and static analysis
↓
Claude reviews changed files and diff
↓
Claude posts an advisory PR comment
↓
Human reviewer makes final decisionThat's practical, safe, and useful.

Why Add AI Review To CI/CD?
Developers already use AI locally, but CI/CD has one big advantage: consistency. A local AI review depends on whether someone remembers to ask. A GitHub Actions workflow runs every time, on every pull request.
That means you can check every PR for common risks:
- unsafe input handling,
- missing authorization,
- SQL injection patterns,
- N+1 queries,
- risky migrations,
- payment logic changes,
- auth middleware changes,
- missing tests,
- unclear behavior changes.
Claude won't catch everything. But it can catch enough to be useful — especially when paired with deterministic tools like unit tests, integration tests, static analysis, linters, dependency scanning, secret scanning, and migration checks.
Think of Claude as the reviewer that asks:
Did we think about this risk?Not as the reviewer that says:
This is definitely safe.Start With A Pull Request Workflow
A GitHub Actions workflow can run on pull requests. Here's a minimal example:
name: AI Code Review
on:
pull_request:
types: [opened, synchronize, reopened]
branches:
- main
permissions:
contents: read
pull-requests: write
jobs:
claude-review:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Collect pull request diff
run: |
git diff origin/main...HEAD > pr.diff
- name: Run Claude review
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.pull_request.number }}
REPOSITORY: ${{ github.repository }}
run: |
python scripts/claude_pr_review.pyThe important detail is the permissions block:
permissions:
contents: read
pull-requests: writeThe workflow needs read access to repository content, plus write access if it's going to post pull request comments. Don't give broader permissions than needed — least-privilege defaults make later mistakes much less expensive.
Collect Changed Files
Your review script needs the diff and, ideally, the changed file list. A simple shell step does the job:
git diff --name-only origin/main...HEAD > changed-files.txt
git diff origin/main...HEAD > pr.diffYou can also use the GitHub API, but a local git diff is simple enough for most repositories.
Example changed-files.txt:
app/Http/Controllers/AuthController.php
app/Services/PaymentRetryService.php
database/migrations/2026_05_03_add_payment_attempts_table.php
tests/Feature/PaymentRetryTest.phpThat list alone is already useful — you can classify risk before you ever ask Claude.
Classify Risky Files
Not all files deserve the same review depth. A README change is usually low risk; an auth middleware change is high risk. A simple Python classifier captures that distinction:
from pathlib import Path
HIGH_RISK_PATTERNS = [
"auth",
"permission",
"policy",
"payment",
"billing",
"checkout",
"migration",
"webhook",
"token",
"password",
]
CRITICAL_PATH_PREFIXES = [
"database/migrations/",
"app/Http/Middleware/",
"app/Policies/",
"app/Payments/",
"app/Billing/",
".github/workflows/",
]
def classify_file(path: str) -> str:
normalized = path.lower()
if any(normalized.startswith(prefix.lower()) for prefix in CRITICAL_PATH_PREFIXES):
return "high"
if any(pattern in normalized for pattern in HIGH_RISK_PATTERNS):
return "high"
if path.endswith((".md", ".txt")):
return "low"
return "medium"
def classify_changed_files(paths: list[str]) -> dict[str, str]:
return {path: classify_file(path) for path in paths}This deterministic classification matters. AI shouldn't be the only thing deciding risk — use simple rules first, then ask Claude to review with more context.

Build The Claude Review Prompt
The prompt should be specific. A bad prompt looks like this:
Review this pull request.A better one tells Claude exactly what to focus on, what rules to follow, and how to structure the output:
You are an additional AI code reviewer for a production software team.
Review the pull request diff below.
Focus on:
- security bugs,
- authorization mistakes,
- unsafe input handling,
- SQL injection risks,
- missing validation,
- N+1 queries,
- risky database migrations,
- payment and billing behavior,
- API compatibility,
- missing tests,
- behavior changes.
Rules:
- Be advisory, not authoritative.
- Do not claim certainty when context is missing.
- Do not request style-only changes unless they affect maintainability.
- Prioritize high-signal issues.
- Group findings by severity.
- Include specific file references when possible.
- If no important issue is found, say that clearly.
Return:
## Summary
## High Risk Findings
## Medium Risk Findings
## Missing Tests
## Questions For Human ReviewerThat structure makes the output easier to drop straight into a PR comment.
Example Review Script
Here's a simplified Python script that ties it all together:
import os
from pathlib import Path
from anthropic import Anthropic
def read_text(path: str, max_chars: int = 60000) -> str:
content = Path(path).read_text(errors="replace")
return content[:max_chars]
def main() -> None:
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
diff = read_text("pr.diff")
changed_files = read_text("changed-files.txt")
prompt = f"""
You are an additional AI code reviewer for a production software team.
Changed files:
{changed_files}
Pull request diff:
{diff}
Review focus:
- security
- authorization
- validation
- SQL injection
- N+1 queries
- migration safety
- payment/billing risks
- API compatibility
- missing tests
Rules:
- Be advisory, not blocking.
- Do not overstate certainty.
- If context is missing, ask a question.
- Prefer high-signal findings.
- Avoid style-only comments.
Output format:
## Summary
## High Risk Findings
## Medium Risk Findings
## Missing Tests
## Questions For Human Reviewer
"""
message = client.messages.create(
model=os.environ.get("CLAUDE_MODEL", "claude-sonnet-4-6"),
max_tokens=3000,
messages=[
{
"role": "user",
"content": prompt,
}
],
)
review = message.content[0].text
Path("claude-review.md").write_text(review)
if __name__ == "__main__":
main()Model names and SDK details change over time, so always check the latest Anthropic documentation when implementing this for your team. The architectural idea stays the same:
Collect diff → build focused prompt → ask Claude → post advisory result.Post A Pull Request Comment
After generating claude-review.md, post it to the pull request. The simplest approach is the GitHub CLI:
- name: Post Claude review comment
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.pull_request.number }}
run: |
gh pr comment "$PR_NUMBER" --body-file claude-review.mdThat posts one general PR comment, which is a perfectly fine first version. Inline comments are more complex because you have to compute diff positions — start with a single summary comment and add inline ones later if you actually need them.
Combine Claude With Static Analysis
AI review shouldn't replace deterministic checks. Use both. Here's a workflow that runs static analysis and AI review side by side:
name: Pull Request Checks
on:
pull_request:
permissions:
contents: read
pull-requests: write
jobs:
static-analysis:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: composer install
- run: vendor/bin/phpstan analyse
- run: vendor/bin/phpunit
ai-review:
runs-on: ubuntu-latest
needs: static-analysis
if: always()
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- run: git diff origin/main...HEAD > pr.diff
- run: git diff --name-only origin/main...HEAD > changed-files.txt
- run: python scripts/claude_pr_review.py
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
- run: gh pr comment "$PR_NUMBER" --body-file claude-review.md
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.pull_request.number }}The interesting line is if: always(). It allows AI review to run even if static analysis fails, which can be useful because Claude can summarize the failure for reviewers. You may prefer the opposite — AI review only after basic checks pass — and that's a team decision.
Review Migrations Carefully
Database migrations deserve special attention. Ask Claude specific migration questions:
For database migration changes, check:
- Does the migration lock a large table?
- Is the change backward compatible?
- Is there a backfill?
- Is the column nullable or does it have a default?
- Could old application code run against the new schema?
- Could new application code run against the old schema during deployment?
- Is rollback safe?
- Is an index needed?Take an innocent-looking migration:
Schema::table('orders', function (Blueprint $table) {
$table->string('status')->default('pending')->change();
});That may be fine on a small table, and risky on a huge production one. AI can flag the question without claiming certainty:
How large is the orders table?
Could this ALTER lock writes?
Is this safe for your MySQL version and deployment strategy?That's exactly the kind of nudge that helps reviewers slow down at the right moment.
Review Auth And Authorization Changes
Auth bugs are often subtle, so add special instructions for those files:
For auth-related files, check:
- Can unauthenticated users access protected data?
- Can regular users access admin behavior?
- Are policies/middleware still applied?
- Are tokens validated correctly?
- Are password/session flows changed?
- Are error messages leaking sensitive information?Now consider this code:
public function show(Request $request, int $id): JsonResponse
{
$invoice = Invoice::findOrFail($id);
return response()->json($invoice);
}Claude should ask:
Should this check that the authenticated user owns the invoice or has admin permission?That's a high-signal review — exactly the question a tired reviewer might miss at 6pm on a Friday.
Review Payment Code
Payment code needs careful review. The prompt section can be very specific:
For payment and billing files, check:
- idempotency keys,
- retry behavior,
- duplicate charges,
- webhook verification,
- currency and amount handling,
- gateway error handling,
- partial failures,
- customer communication side effects.A typical risky example:
public function retryPayment(Invoice $invoice): void
{
$this->gateway->charge($invoice->payment_method_id, $invoice->amount);
$invoice->markAsPaid();
}Questions Claude should raise:
What prevents duplicate charges if this method is retried?
Is there an idempotency key?
What happens if the gateway succeeds but markAsPaid fails?These are exactly the kinds of questions that help reviewers — concrete, scoped, and grounded in the actual diff.

Make AI Review Advisory First
Don't make AI review blocking on day one. Start with the simplest possible contract:
AI review posts a comment.
Humans decide what matters.After your team trusts it, you can add blocking behavior — but only for deterministic conditions, not subjective AI opinions. Good blocking checks include:
- tests failed,
- static analysis failed,
- migration file changed without migration check,
- high-risk file changed without required reviewer,
- secret detected,
- dependency vulnerability detected.
Risky blocking checks — the ones that quickly become annoying — look like this:
- AI says code is bad,
- AI thinks tests are missing,
- AI is uncertain,
- AI dislikes architecture.
The rule is simple: AI should inform; deterministic systems should enforce.
Avoid Comment Noise
AI review can become annoying fast if it posts too much. A few rules to keep the signal-to-noise ratio high:
- Only post high-signal findings.
- Do not comment on formatting.
- Do not repeat static analysis output unless explaining impact.
- Limit total findings.
- Group minor issues into one section.
- Say “No high-risk findings” when appropriate.You can enforce this in the prompt:
Limit the review to at most:
- 3 high-risk findings,
- 5 medium-risk findings,
- 5 missing test suggestions.
If there are more, include only the most important.Hard caps like that keep comments useful instead of letting Claude bury reviewers in twenty things to consider.
Add A Team-Specific Review Policy
Generic review is good. Team-specific review is better. Create a small policy file that captures your team's actual risk areas:
.ai-review-policy.mdSomething like this:
# AI Review Policy
High-risk areas:
- app/Billing
- app/Payments
- app/Auth
- app/Http/Middleware
- database/migrations
- .github/workflows
Rules:
- Payment changes must mention idempotency.
- Webhook changes must verify signatures.
- API changes must preserve response shape unless documented.
- Migrations on large tables must mention lock/backfill strategy.
- Auth changes must mention middleware/policy coverage.
- Queue payload changes must consider rolling deploy compatibility.Then include it in the prompt:
policy = Path(".ai-review-policy.md").read_text()
prompt = f"""
Team review policy:
{policy}
Changed files:
{changed_files}
Diff:
{diff}
Review using the team policy.
"""Now Claude reviews against your standards, not generic ones — and when the policy changes, the review updates automatically.
Security Notes
Be careful with secrets. Don't print them into prompts, don't send production data, and don't include .env files. Don't let the AI workflow run on untrusted pull requests with powerful secrets.
For open-source repositories, be especially careful with pull_request_target. It runs in the context of the base repo with access to secrets, and if you check out the PR head code on top of that, you've handed an attacker the keys to your repository. A safe first version for private repositories is much easier; for public repos, design the workflow more carefully and don't check out untrusted PR head code in any job that holds secrets.
Final Workflow
A practical first version looks like this:
1. Run on pull_request.
2. Checkout code with read permissions.
3. Collect changed files and diff.
4. Classify risky files deterministically.
5. Run tests and static analysis.
6. Ask Claude for an advisory review.
7. Post one PR comment.
8. Humans make the merge decision.That's enough to start. Later you can add inline comments, team policy files, risk-based prompts, summaries of failed tests, required human reviewers for high-risk files, and separate review modes for auth, payments, migrations, and APIs.
Final Thought
Claude in CI/CD isn't a replacement for code review — it's a review assistant. Use it to catch suspicious patterns, ask better questions, summarize risk, and help humans focus.
The best setup combines:
deterministic checks + AI review + human judgmentTests and static analysis tell you what's mechanically wrong. Claude helps you ask what might be behaviorally risky. Senior engineers decide what should merge. That's the right balance.






