
So, you've written some Go. You've got a main.go that's slowly turning into a Christmas tree of NewThing(NewOtherThing(NewLogger(), NewConfig())) calls. Someone on the team has started muttering about "dependency injection" and pointing at fx or wire. You're wondering whether you missed the day they handed out the framework.
Here's the secret: you didn't. Go doesn't have a dependency injection framework in the standard library, and most Go codebases don't need one. What they need is a clear understanding of what DI actually is, and a small set of habits (constructors, interfaces defined on the consumer side, and a single composition point) that get you 95% of the benefit with zero magic. The remaining 5% is where fx and wire start to earn their keep, and we'll talk honestly about when that line is.
This article is the long version. We're going to walk through:
- what dependency injection actually is, stripped of OOP folklore,
- why constructors do most of the work in Go,
- how interfaces in Go fit DI better than in any language with
implementskeywords, - wiring an entire app in
mainand not hating it, - functional options when constructors get crowded,
- the temptation to build your own "container", and why it usually backfires,
- what
fxandwiregive you, what they cost, and the size of project where each one starts to make sense, - testing as the real payoff,
- and the small handful of mistakes that turn DI from a clarity win into a tangle.
By the end you should be comfortable defending "we don't use a DI framework" in a design review, and equally comfortable saying "we should pull in wire for this one" when the situation calls for it.
What dependency injection actually is
Strip away the textbook definitions and dependency injection is one rule: a thing should not construct its own collaborators.
If your OrderService calls sql.Open(...) inside its constructor, it's constructing its own collaborator. If your OrderService receives a *sql.DB as an argument and uses it, it's been injected. That's it. That's the whole concept.
Everything else (interfaces, containers, lifecycles, scopes, providers) is how you make injection comfortable at scale. The underlying rule is the boring one.
Why does the rule matter? Two reasons. First, testing: if OrderService constructs its own database, you can't put a fake one in front of it without running an actual database during tests. Second, reuse: if OrderService constructs its own logger, you can't run two instances with different loggers. Both of these sound abstract until you've watched a 200-line test suite take three minutes to start because every test boots Postgres.
In Java or C# the cure for this is often a runtime container. In Go, the cure is almost always a parameter:
type OrderService struct {
db *sql.DB
logger *slog.Logger
clock Clock
}
func NewOrderService(db *sql.DB, logger *slog.Logger, clock Clock) *OrderService {
return &OrderService{db: db, logger: logger, clock: clock}
}The constructor takes its collaborators. The collaborators were built somewhere else. That "somewhere else" is the composition root, and in Go it's almost always main. We'll get back to that.
Constructors are 80% of DI in Go
Go doesn't have constructors as a language feature. What it has is a convention: a function named New<Type> that returns a <Type> (or *<Type>) and accepts whatever the type needs to function.
That's enough. The convention is the contract. When you read NewOrderService(db, logger, clock), you know exactly what OrderService depends on, in what order, with what types. There's no hidden init step, no @Autowired magic, no field-level surprise.
A few habits make constructors carry their weight:
1. Return concrete types, accept interfaces.
// Concrete returned, interface accepted.
func NewOrderService(repo OrderRepository, clock Clock) *OrderService {
return &OrderService{repo: repo, clock: clock}
}OrderRepository and Clock are interfaces: they describe what the service needs. *OrderService is concrete, so callers can see exactly what they're getting. This pairing is sometimes called the "Postel principle for APIs": be liberal in what you accept (interfaces), conservative in what you return (concrete types). It's the right default for ~90% of Go code.
2. Don't do work in the constructor.
A NewX function should assemble the struct, validate that the dependencies aren't nil if it matters, and return. It should not open files, make network calls, kick off goroutines, or talk to a database. If your type needs to do startup work, give it an explicit Start(ctx context.Context) error method.
This sounds pedantic until you've debugged a panic that happened during package initialization because a constructor decided to dial a Redis that wasn't up yet. Startup ordering should be explicit.
3. Validate the inputs.
If a dependency is required, check it:
func NewOrderService(repo OrderRepository, clock Clock) (*OrderService, error) {
if repo == nil {
return nil, errors.New("order_service: repo is required")
}
if clock == nil {
clock = realClock{}
}
return &OrderService{repo: repo, clock: clock}, nil
}Returning (*OrderService, error) instead of just *OrderService is a judgment call. For services with hard requirements, the explicit error reads cleaner than a panic. For services where defaults are reasonable (a clock, a logger), supplying a sensible default and returning a single value is often nicer.
4. Keep the parameter list short, but not at the cost of clarity.
If your constructor has eleven parameters and you're embarrassed every time you call it, the answer is rarely "let's add a DI framework." The answer is usually that your type is doing too much. Split it. If after splitting you still have a legitimate 6+ parameter constructor (an HTTP server type, for example, which really does need a logger, a config, a router, a tracer, a metrics registry, and a shutdown channel), reach for functional options, which we'll get to.
Interfaces on the consumer side
This is the Go-specific trick that makes hand-rolled DI feel natural, and it trips up engineers coming from Java or C# more than almost anything else.
In Java, an interface is a contract that an implementing class explicitly declares: class PostgresOrderRepo implements OrderRepository. The interface is defined near the implementation. Consumers find the interface, then pick an implementation that declares it.
In Go, interfaces are satisfied implicitly. A type satisfies OrderRepository if it has the right methods, regardless of where OrderRepository is declared or whether the type's author has ever heard of it. This sounds like a small detail. It changes everything.
The Go-idiomatic move is: define the interface in the package that uses it, not in the package that implements it.
package orders
// Interface lives with the consumer. It describes what THIS package needs.
type Repository interface {
Save(ctx context.Context, o Order) error
FindByID(ctx context.Context, id string) (Order, error)
}
type Service struct {
repo Repository
}
func NewService(repo Repository) *Service {
return &Service{repo: repo}
}package postgres
// No mention of orders.Repository here. It still satisfies the interface
// because the methods match.
type OrderRepo struct {
db *sql.DB
}
func NewOrderRepo(db *sql.DB) *OrderRepo {
return &OrderRepo{db: db}
}
func (r *OrderRepo) Save(ctx context.Context, o orders.Order) error { /* ... */ }
func (r *OrderRepo) FindByID(ctx context.Context, id string) (orders.Order, error) { /* ... */ }Three things fall out of this:
- The
orderspackage can be tested with a fake that lives inorders_test.go: no need to import the database package. - The interface lists only the methods
ordersactually uses, not every method the underlying repository exposes. This is what people mean by "interface segregation in Go is free." - The
postgrespackage doesn't have to know aboutorders(other than the data types it stores). It just exposes a concreteOrderRepo. Anyone whose interface matches can use it.
The mistake is putting the interface in the implementation package (postgres.OrderRepository) and then importing that in orders. The dependency arrow goes the wrong way. Now orders depends on postgres, and you've defeated the point of having a service package separate from a storage package.
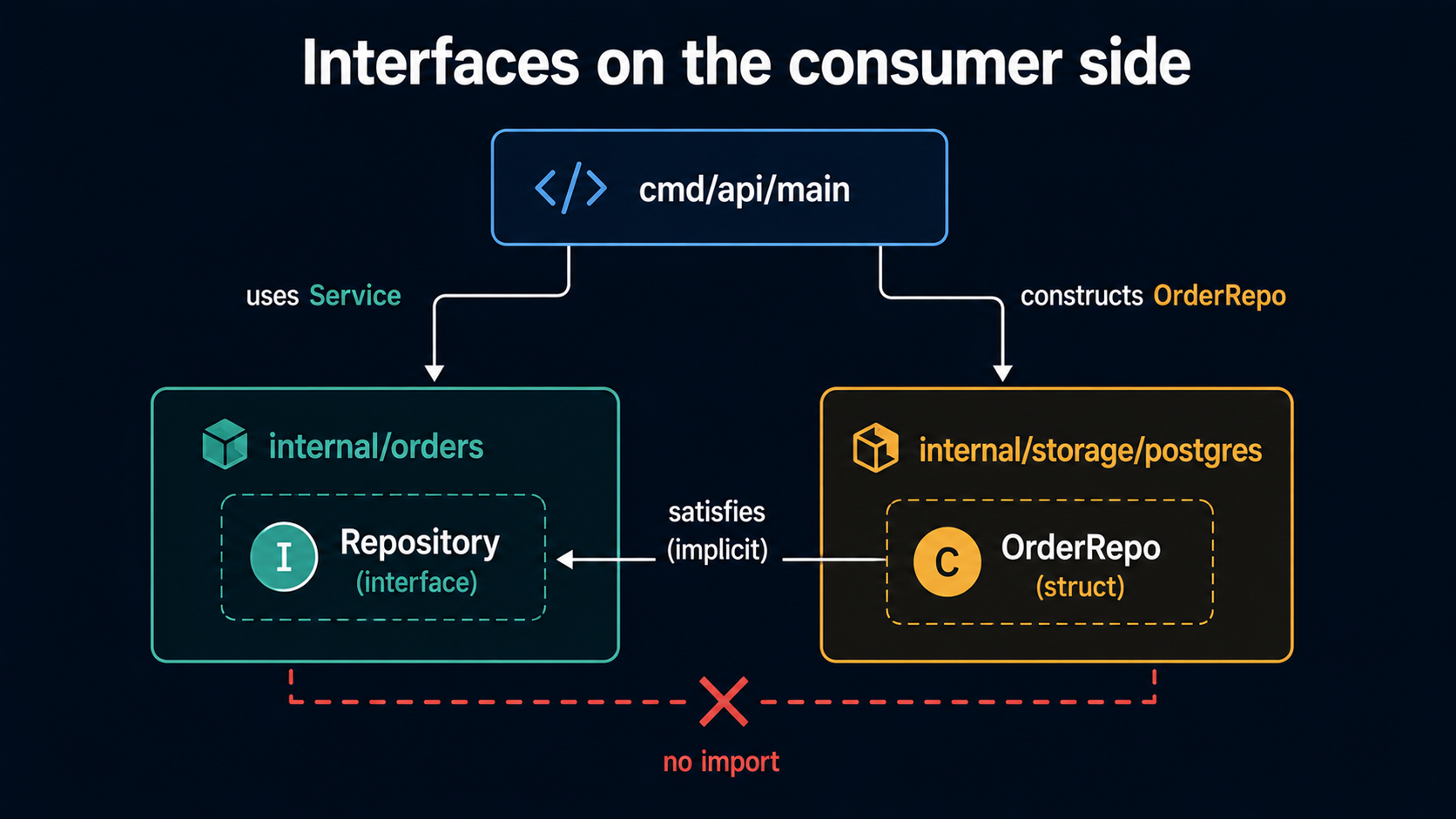
There's one more piece of folklore worth dismantling: "every struct should have an interface in front of it for testing." No. Most of your types don't need an interface. You only need an interface where there's a real seam: a thing you want to swap out (a different storage backend, a fake in tests, a different implementation per environment). A Coordinates value type doesn't need an interface. A password.Hasher does, because in tests you want a fast no-op hasher instead of bcrypt.
Interfaces have a cost: they're a layer of indirection in the reader's brain. Pay that cost only where you get value back.
Wiring everything in main
If constructors are 80% of the work, wiring is the last 20%, and main is where it happens.
The composition root is the one place in your app that knows about every concrete type. It builds the leaves of the dependency graph first (the database, the logger, the config), then builds the things that depend on those, and so on up to the HTTP server or the message consumer at the top.
Here's a realistic shape for a small service:
package main
import (
"context"
"log/slog"
"net/http"
"os"
"os/signal"
"syscall"
"time"
"github.com/jackc/pgx/v5/pgxpool"
"yourapp/internal/config"
"yourapp/internal/http/handlers"
"yourapp/internal/orders"
"yourapp/internal/storage/postgres"
)
func main() {
if err := run(); err != nil {
slog.Error("startup failed", "err", err)
os.Exit(1)
}
}
func run() error {
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer stop()
// 1. Leaves — config, logger, clock.
cfg, err := config.Load()
if err != nil {
return err
}
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
clock := orders.RealClock{}
// 2. Infrastructure — pool, repositories.
pool, err := pgxpool.New(ctx, cfg.DatabaseURL)
if err != nil {
return err
}
defer pool.Close()
orderRepo := postgres.NewOrderRepo(pool)
userRepo := postgres.NewUserRepo(pool)
// 3. Domain services.
orderService := orders.NewService(orderRepo, clock, logger)
userService := users.NewService(userRepo, logger)
// 4. HTTP layer.
handler := handlers.New(orderService, userService, logger)
server := &http.Server{
Addr: cfg.HTTPAddr,
Handler: handler,
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
}
// 5. Run with graceful shutdown.
return runServer(ctx, server, logger)
}Read that top to bottom. There's no magic. Every dependency is visible. If orders.NewService suddenly needs a new collaborator, you'll see exactly where to plumb it. If you want to know whether userRepo is shared or separate per service, you can see the variable. If you want to swap Postgres for an in-memory implementation for local development, you change two lines.
The argument against this approach is that it doesn't scale. The argument is partially right and mostly wrong. It stops being readable at around 30 to 50 dependencies, which is more than most services ever reach. Until you cross that threshold, the manual wiring is a feature: it's the documentation of your runtime topology, and the compiler keeps it honest.
A few tips that make the composition root pleasant to live with:
- Put it in
cmd/<app>/main.go, not in your library packages. Theinternal/packages should be unaware of the composition root; they just expose constructors. - Have a
run()function that returns an error.mainjust callsrun()and handles the exit code. This makes it possible to write integration tests that bring up your whole service in-process. - Group the calls by layer: leaves first, infrastructure, services, transports. Drop a comment line between groups. The visual grouping makes the graph readable at a glance.
- Pass
context.Contextthrough where startup is async. Pool dials, migrations, warm-up jobs. Everything that can hang should be context-aware so a slow startup doesn't leave you with a half-built app.
Functional options for crowded constructors
Sometimes a constructor genuinely needs many inputs and you can't (or shouldn't) split the type. The classic example is an HTTP server type, or a queue worker that needs a logger, a tracer, a metrics registry, a retry policy, a backoff config, and three timeouts.
The Go community settled on functional options as the idiomatic answer to this. The pattern is simple: the constructor takes the required dependencies as positional arguments, and everything optional becomes a variadic ...Option. Each option is a function that mutates the struct.
type Server struct {
handler http.Handler
logger *slog.Logger
tracer trace.Tracer
metrics *prometheus.Registry
readT time.Duration
writeT time.Duration
}
type Option func(*Server)
func WithLogger(l *slog.Logger) Option {
return func(s *Server) { s.logger = l }
}
func WithTracer(t trace.Tracer) Option {
return func(s *Server) { s.tracer = t }
}
func WithTimeouts(read, write time.Duration) Option {
return func(s *Server) {
s.readT = read
s.writeT = write
}
}
func NewServer(handler http.Handler, opts ...Option) *Server {
s := &Server{
handler: handler,
logger: slog.Default(), // sensible defaults
readT: 5 * time.Second,
writeT: 10 * time.Second,
}
for _, opt := range opts {
opt(s)
}
return s
}Now callers can do:
srv := NewServer(handler,
WithLogger(logger),
WithTracer(tracer),
WithTimeouts(3*time.Second, 8*time.Second),
)What you get:
- The required dependency (
handler) is positional, so the compiler enforces it. - Optional things have defaults, so calls in tests stay short.
- New options can be added without breaking existing callers.
- The reader at the call site can see what's customized and assume defaults for everything else.
What you don't get:
- Compile-time enforcement of which options were passed. If a user calls
NewServer(handler)without settingWithTracer, the server gets a nil tracer (or a default no-op one). You have to design for that explicitly. - A natural place to return errors. Options that can fail (parsing, validation) need to either panic, store the error and surface it on
Build()/Start(), or use the slightly more elaboratefunc(*Server) errorshape.
The error-returning version is worth seeing:
type Option func(*Server) error
func WithDatabaseURL(url string) Option {
return func(s *Server) error {
pool, err := pgxpool.New(context.Background(), url)
if err != nil {
return fmt.Errorf("with database url: %w", err)
}
s.pool = pool
return nil
}
}
func NewServer(handler http.Handler, opts ...Option) (*Server, error) {
s := &Server{handler: handler /* defaults */}
for _, opt := range opts {
if err := opt(s); err != nil {
return nil, err
}
}
return s, nil
}The functional-options pattern shines for library code: types like Server, Client, Pool that ship with a stable API. For internal application code where the call site is one place (main), plain struct fields with a config struct are usually plenty:
type Config struct {
Logger *slog.Logger
Tracer trace.Tracer
ReadT time.Duration
WriteT time.Duration
}
func NewServer(handler http.Handler, cfg Config) *Server { /* ... */ }Pick the shape that fits the audience. Functional options for things many people will call. Config structs for things only main calls.
The "container" temptation
Once a Go codebase gets big enough, someone always proposes building a "service container": a struct that holds every dependency in the app and gets passed everywhere.
// Don't do this.
type Container struct {
DB *sql.DB
Logger *slog.Logger
OrderService *orders.Service
UserService *users.Service
Mailer Mailer
Cache Cache
// ... 40 more fields
}
func (c *Container) HandleCreateOrder(w http.ResponseWriter, r *http.Request) {
o, err := c.OrderService.Create(r.Context(), /* ... */)
// ...
}It looks tempting. You've got "DI": everything is injected through the container. You've got a single global place to add new dependencies. You don't have to thread arguments through five layers of constructors. It feels like progress.
It's not. It's the service locator anti-pattern wearing a Go hat.
Three things go wrong:
1. You lose the visibility you had.
With per-service constructors, the signature of NewOrderService tells you exactly what OrderService depends on. With a container, every handler can reach into every dependency. The relationships are no longer encoded in the types. To know what a function actually uses, you have to read the body.
2. Cyclic dependencies become invisible.
When a service grabs its dependencies from the container at method-call time instead of constructor time, you can end up with services that depend on each other through the container. The compiler doesn't catch it because the references are looked up at runtime.
3. Testing gets worse, not better.
The whole point of DI is that you can hand-build a service with fake collaborators in a test. With a container, every test has to construct or stub a partial container, which is more code than just calling the constructor directly.
The cure is to use the composition root for composition and let the components hold only what they need. If you find yourself wanting a container so badly that you can't bear the wiring, it's a strong hint that one of two things is true: either your main is genuinely getting too big (in which case look at wire or fx), or your types are too coarse and a few well-placed splits would fix it.
fx and wire: what they are and when they earn their keep
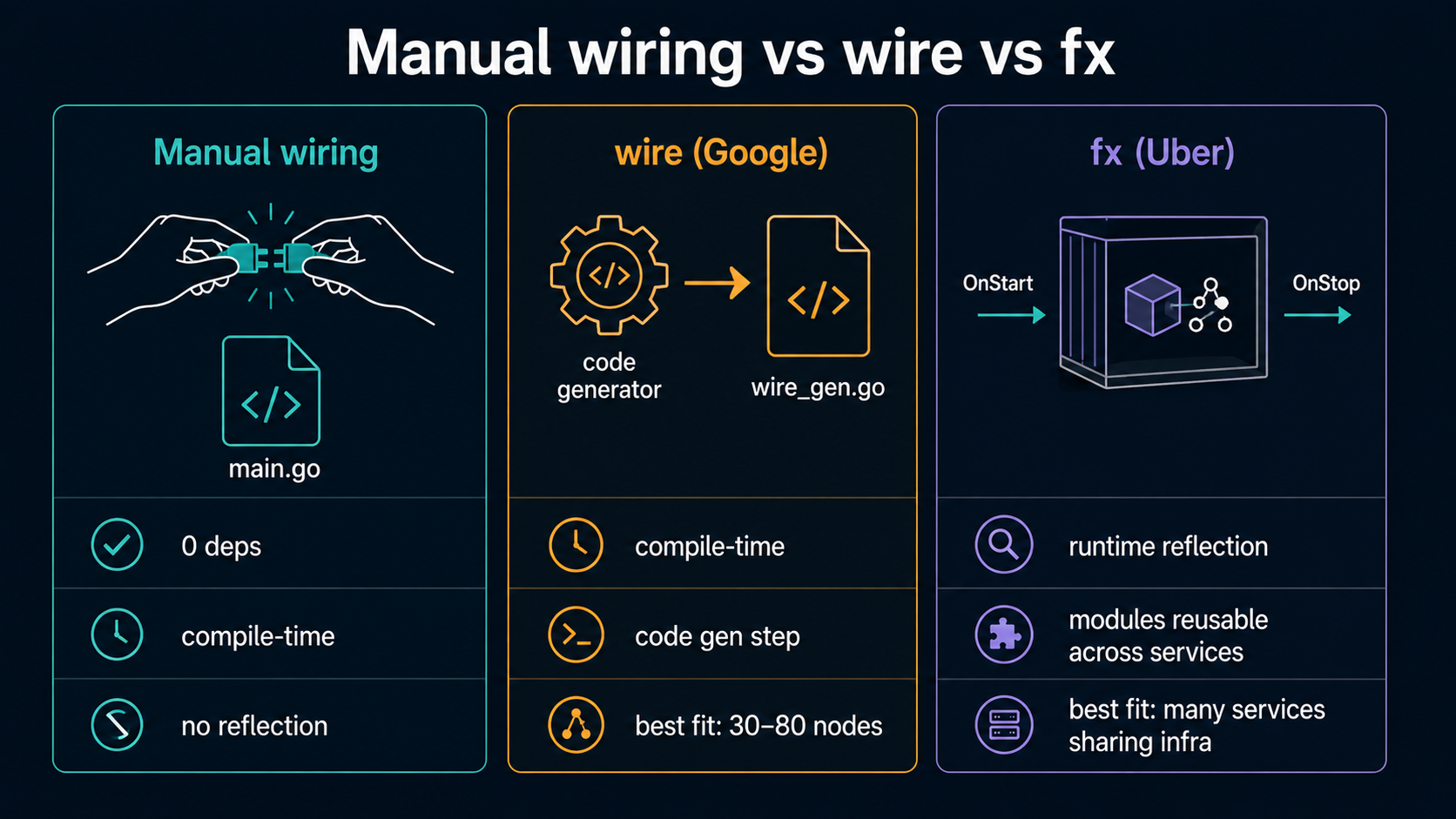
So when do you reach for a framework? Two of them are mature and worth knowing.
wire (Google)
wire is a compile-time dependency-injection code generator. You write providers (regular constructors) and injectors (function stubs marked with a build tag), and the wire command-line tool reads the providers and generates the wiring code for you.
//go:build wireinject
// +build wireinject
package main
import "github.com/google/wire"
func InitializeApp(cfg config.Config) (*App, func(), error) {
wire.Build(
provideLogger,
provideDB,
postgres.NewOrderRepo,
wire.Bind(new(orders.Repository), new(*postgres.OrderRepo)),
orders.NewService,
handlers.New,
newApp,
)
return nil, nil, nil // wire fills this in
}You run wire ./... and it generates a wire_gen.go file that contains the actual wiring: the same code you'd have written by hand, just generated.
What you get:
- Compile-time correctness. If a provider is missing or a type is unsatisfied,
wirefails to generate. There's no runtime "dependency not found" error. - No reflection at runtime. The generated code is plain Go. It performs as well as hand-written wiring.
- Readable output. You can read
wire_gen.goand see exactly what was built, in what order.
What it costs:
- A build step. Every time you add or remove a dependency, you re-run
wire. CI has to know to do this and check that the file is up to date. - A learning curve.
wire.Bind,wire.Struct, provider sets, and the difference between injectors and providers all take a day to internalize. - Modest scale benefit at small sizes. For a 10-dependency app, you'll write more code in
wire.gothan you would have inmain.go. The break-even is somewhere around 30 to 50 nodes in your dependency graph, and the curve gets steeper after that.
fx (Uber)
fx is a runtime DI framework with a lifecycle manager. You register providers and invokers with an fx.App, and fx figures out the order, calls the constructors, and manages startup and shutdown hooks.
func main() {
fx.New(
fx.Provide(
config.Load,
provideLogger,
provideDB,
postgres.NewOrderRepo,
fx.Annotate(
postgres.NewOrderRepo,
fx.As(new(orders.Repository)),
),
orders.NewService,
handlers.New,
newServer,
),
fx.Invoke(registerHooks),
).Run()
}What you get:
- Lifecycle management. Things that need to start (HTTP servers, queue consumers, background jobs) and stop (close pools, flush logs) can register
OnStartandOnStophooks andfxorchestrates them in the right order. - Module composition. You can package related providers into reusable
fx.Modules (a logging module, a database module, an observability module) and compose them across services. This is Uber's actual reason for using it: hundreds of services sharing a common infra module. - Less boilerplate at scale. Once your graph is big, the
fx.Provide(...)list is shorter than the manual equivalent.
What it costs:
- Runtime reflection.
fxfigures out the graph at startup. A misconfiguration that compiles fine can blow up your service three seconds into startup. You learn to test the build of thefx.Appitself. - Stack traces lose their shape. When something fails inside a provider, the trace winds through
fxinternals. Debugging unfamiliarfxerrors takes a beat. - Type erasure via
interface{}.fx.Annotateand friends work but they're not as clean as plain Go. You're in a parallel type system that overlaps imperfectly with the language. - It encourages module-ization that's hard to walk back. Once a team has
module-logger,module-db,module-tracing, the dependency graph is hidden behindfx.Modulecalls and you've signed up for the framework long-term.
Choosing between them, and choosing neither
Here's the honest decision tree:
- Single service, <30 nodes, one developer or a small team. Manual wiring. Don't even open the
fxdocs. - Single service, 30 to 80 nodes, growing team. Still manual, but be disciplined: one
mainper binary, group calls by layer, factor outsetup*helper functions ifrun()gets long. Considerwireif the boilerplate starts to hurt; it's the lower-cost option. - Multiple services sharing infrastructure (logging, DB, tracing setup), with a platform team that owns the shared modules.
fxstarts to make sense. The lifecycle management andfx.Modulereusability pay off when you're standardizing across N services. - Anywhere
wirewould work andfxwould also work. Preferwire. Compile-time wins beat runtime convenience when you have the choice.
Don't pick a framework because you've heard of it. Pick it because manual wiring has started to hurt in a way that the framework genuinely fixes. If you can't articulate that hurt, you don't need the framework yet.
Testing: the actual payoff
If you do nothing else from this article, do this: make orders.NewService accept its dependencies as parameters, and you'll be able to write tests that look like this:
func TestService_CancelOrder_AlreadyShipped(t *testing.T) {
repo := &fakeRepo{
orders: map[string]Order{
"abc": {ID: "abc", Status: StatusShipped},
},
}
clock := fakeClock{now: time.Date(2026, 1, 1, 12, 0, 0, 0, time.UTC)}
svc := NewService(repo, clock, slog.Default())
err := svc.Cancel(context.Background(), "abc")
if !errors.Is(err, ErrAlreadyShipped) {
t.Fatalf("want ErrAlreadyShipped, got %v", err)
}
}
type fakeRepo struct {
orders map[string]Order
}
func (f *fakeRepo) FindByID(_ context.Context, id string) (Order, error) {
o, ok := f.orders[id]
if !ok {
return Order{}, ErrNotFound
}
return o, nil
}
func (f *fakeRepo) Save(_ context.Context, o Order) error {
f.orders[o.ID] = o
return nil
}
type fakeClock struct{ now time.Time }
func (f fakeClock) Now() time.Time { return f.now }No database. No mocks library. No DI framework. Two small fakes that satisfy interfaces defined in the same package. The test boots in microseconds and tests exactly the logic of Cancel without booting any infrastructure.
This is what people mean when they say "testability is a design property, not a tooling problem." Every choice we've made up to this point (constructors that take parameters, interfaces on the consumer side, no hidden state, no service locator) was for this moment.
A few testing habits worth noting:
- Prefer hand-rolled fakes over mock libraries. A 10-line fake in your test file reads better than a
gomock-generated mock with method-call expectations. Use mocks when you genuinely need to assert on calls in order; use fakes when you need a working-but-fake implementation. - Keep fakes in
*_test.gofiles. They aren't part of your production API. If multiple test files in the same package need the same fake, put it inhelpers_test.go. If multiple packages need it, that's a sign you want to export an interface and provide a real-but-cheap reference implementation (an in-memory store), not a fake. - For integration tests, use real implementations of as much as possible. Spin up Postgres in a Docker container, use a real HTTP server bound to
127.0.0.1:0. The fakes are for unit tests, where you want to test one type's logic in isolation. Don't fake your way through integration tests; that defeats the point.
The small mistakes that turn DI into a tangle
Most of the pain people associate with DI in Go isn't actually a DI problem; it's one of a handful of recurring small mistakes. Recognise them and you'll stay out of trouble.
Putting interfaces in the implementation package.
We covered this earlier. The interface should live with the consumer. If it lives in the implementation package, your consumer depends on the implementation, and you've lost the layering you were trying to build.
Using package-level globals as "easy" injection.
// Don't.
var DB *sql.DB
func init() {
DB, _ = sql.Open(...)
}
func GetOrder(id string) (Order, error) {
return queryOne(DB, "...")
}This is what people do when constructors feel like too much ceremony. It works on day one. On day 30 you'll be trying to write a test that uses a different database and finding out that the global is set in init() and there's no clean way to override it. Pay the small cost of a constructor up front.
Building a service that takes 11 dependencies because it does 11 things.
DI doesn't make a god class okay. If a service has a logger, a database, a cache, a mailer, an HTTP client, a queue publisher, a metrics registry, a feature flag client, a clock, a UUID generator, and a config, it's not one service. Split it.
Forcing every concrete type behind an interface.
// Probably unnecessary.
type DB interface {
Exec(...) (...)
Query(...) (...)
QueryRow(...) (...)
// ...
}*sql.DB is already a concrete type with a stable API. Wrapping it in your own DB interface so you can "mock it" almost always produces a test that's worse than just using a real database via a test container. The seam exists where you cross a real boundary: a repository, an HTTP client, an external service. Inside those boundaries, use concrete types and trust the standard library.
Treating "no framework" as a moral position.
If a codebase honestly is at the scale where wire or fx would help (hundreds of providers, a shared platform layer across services, real pain in main.go), then refusing the framework on principle is just stubbornness. The point isn't to avoid frameworks. The point is to use them when they earn their cost and not before.
What this looks like a year in
A Go codebase that's followed these habits for a year looks like this:
- Every package exposes one or two
New*constructors that take what they need. - Interfaces live in consumer packages and have between one and five methods each.
- There's a
cmd/<app>/main.goper binary, each with arun()function that builds the graph from leaves to root. - A handful of types in widely-used packages (an HTTP client, a server, maybe a worker pool) use functional options. Everything else uses plain struct fields or config structs.
- Tests in
internal/*packages use hand-rolled fakes and run in milliseconds. - Integration tests spin up real Postgres and real HTTP servers.
- No DI framework. Or, if there is one, it's
wireand it's used only at the top ofmain, and there's a written-down reason for it.
That's it. No magic. No annotations. No container god-objects. Just constructors, interfaces in the right places, and one composition root per binary. Go's whole approach to dependency injection is a refusal to abstract over something that was already pretty clear, and once you've lived inside that refusal for a few months, the frameworks of other languages start to feel like they're solving a problem you don't have.
If you came here hoping for a clever trick that makes wiring disappear, the trick is that wiring isn't the problem. The thing that makes a service easy to change isn't fewer lines in main; it's the discipline upstream of main, in how the types are shaped. Get those right and the wiring is the easy part. Get those wrong and no framework will save you.





