
So, you've been told microservices are how grown-up systems work.
Split everything. Event-driven everywhere. Service mesh on day one. Each team owns its own database, its own deploy pipeline, its own observability stack, its own opinions about Kubernetes.
Then you actually build it. And the first time a customer says "the order didn't arrive", you spend three hours opening browser tabs.
That's the gap this article wants to close.
Go is a wonderful language for microservices. It compiles to a single binary, starts in milliseconds, has a real standard library, and doesn't bury you under runtime ceremony. But the language being good doesn't make the architecture good. Most "Go microservice" tutorials ship you a HelloService talking to a GoodbyeService over gRPC, slap a Kubernetes manifest on the side, and call it production-grade. It is not.
Let's walk through what actually matters: APIs, messaging, observability, deployment. Then look at the patterns that hold up after a few quarters in production. Not the hype version. The boring version that lets you sleep.
When not to split
Before any code, the most useful microservices pattern is don't.
Most teams reach for microservices because the monolith got painful. But "painful" is rarely about runtime. It's usually about deploys, ownership, or test runs that take 40 minutes. None of those are solved by HTTP between processes. They're solved by modularizing the monolith, splitting CI, and giving teams clear ownership of packages.
Go makes a modular monolith especially nice. Internal packages with internal/ are genuinely private, the standard library is enough for routing and HTTP, and a single binary deploys in seconds. A 50k-line Go monolith with clean package boundaries is faster, easier to debug, and cheaper to operate than five tiny services.
Split when one of these is true:
- A subsystem has a fundamentally different runtime profile (long-running, GPU-heavy,
needs much more memory, needs much faster scaling).
- A subsystem must be deployable independently for compliance or release-cadence reasons.
- A subsystem is owned by a different team that needs full autonomy on the wire.
- The subsystem genuinely needs a different language (rare, but real).If none of those is true, you are paying the cost of microservices to look modern.
When you do split, split along transactional boundaries. A service should own a coherent set of writes that succeed or fail together. "Payments" is a service. "Orders" is a service. "PaymentValidationButOnlyForCardsExceptAmex" is not. That is a function inside Payments.
The number of services is not a quality signal. The clarity of their boundaries is.
API patterns: pick HTTP, reach for gRPC when it earns it
Go has the rare property that the standard library's net/http is good enough to ship serious services on. Add a router with middleware, a JSON encoder, and you are 80% of the way there. The popular choices for the router are chi and gorilla/mux (still used in many shops despite the upstream being archived; chi is the safer pick for new code).
Here is the boring shape of a real HTTP service:
package main
import (
"context"
"errors"
"log/slog"
"net/http"
"os"
"os/signal"
"syscall"
"time"
"github.com/go-chi/chi/v5"
"github.com/go-chi/chi/v5/middleware"
)
func main() {
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
r := chi.NewRouter()
r.Use(middleware.RequestID)
r.Use(middleware.RealIP)
r.Use(loggingMiddleware(logger))
r.Use(middleware.Recoverer)
r.Use(middleware.Timeout(15 * time.Second))
r.Get("/healthz", healthz)
r.Get("/readyz", readyz)
r.Mount("/v1/orders", ordersRouter())
srv := &http.Server{
Addr: ":8080",
Handler: r,
ReadHeaderTimeout: 5 * time.Second,
WriteTimeout: 30 * time.Second,
IdleTimeout: 120 * time.Second,
}
go func() {
if err := srv.ListenAndServe(); err != nil && !errors.Is(err, http.ErrServerClosed) {
logger.Error("server failed", "err", err)
os.Exit(1)
}
}()
stop := make(chan os.Signal, 1)
signal.Notify(stop, syscall.SIGINT, syscall.SIGTERM)
<-stop
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel()
_ = srv.Shutdown(ctx)
}Notice what's not there. No framework. No magic dependency injection. No code generation. The whole thing reads top to bottom and a junior engineer can debug it on day two.
A few non-obvious things this snippet gets right:
ReadHeaderTimeoutis set. The Go default is no timeout, which means a slow-loris client can keep a goroutine pinned forever. This is the single most common Go HTTP server bug in production, and it does not show up in load tests.- Graceful shutdown. SIGTERM tells the server to stop accepting new connections and finish in-flight requests inside 30 seconds. Without this, every deploy 502s a handful of users.
- Health and readiness are separate.
/healthzsays "the process is alive" (return 200 if you can answer at all)./readyzsays "I'm ready to serve traffic": only 200 once your DB pool is warm and any required downstream is reachable. Kubernetes uses these very differently; conflating them causes restart loops.
When to reach for gRPC
gRPC is genuinely useful, but for narrower reasons than the marketing implies. Reach for it when:
- The service-to-service contract changes often and the schema needs to be enforced at compile time, not at runtime.
- You need bidirectional streaming or server-side streaming (think real-time price updates, log shipping, telemetry).
- The latency budget for an internal hop is tight enough that protobuf's smaller payloads and binary framing actually matter.
For a service that mostly serves browser clients and a few internal callers, JSON over HTTP is fine. Don't introduce gRPC just to look serious.
A small gRPC service in Go looks like this:
package main
import (
"context"
"net"
"google.golang.org/grpc"
"google.golang.org/grpc/health"
healthpb "google.golang.org/grpc/health/grpc_health_v1"
pb "example.com/inventory/proto"
)
type server struct {
pb.UnimplementedInventoryServer
}
func (s *server) Reserve(ctx context.Context, req *pb.ReserveRequest) (*pb.ReserveResponse, error) {
// real reservation logic, with idempotency key from req
return &pb.ReserveResponse{Reservation: &pb.Reservation{Id: "r_123"}}, nil
}
func main() {
lis, err := net.Listen("tcp", ":50051")
if err != nil {
panic(err)
}
s := grpc.NewServer()
pb.RegisterInventoryServer(s, &server{})
hs := health.NewServer()
hs.SetServingStatus("", healthpb.HealthCheckResponse_SERVING)
healthpb.RegisterHealthServer(s, hs)
if err := s.Serve(lis); err != nil {
panic(err)
}
}The patterns that age well: every RPC takes a context.Context (always; propagate it down to your DB calls), every request carries an idempotency key for any non-read operation, the health protocol is registered as a separate service so your platform can ping it, and UnimplementedInventoryServer is embedded so adding RPCs later doesn't break old servers.
Versioning
API versioning is one of those topics where everyone has a strong opinion and most of the opinions are wrong because they generalise from a system they ran once.
The version that holds up across both HTTP and gRPC services is:
- Never break an existing field. Once
OrderResponse.statusreturns the strings"pending" | "shipped" | "cancelled", those strings are forever. New states get new strings and clients learn to ignore unknown values. - Add fields, don't repurpose them. Adding
OrderResponse.estimated_delivery_atis free. ChangingOrderResponse.delivery_atfrom "promised" to "actual" silently breaks every consumer. - Prefix the URL when the contract genuinely breaks.
/v1/ordersand/v2/orderscan coexist for a year while clients migrate. Don't do this casually. Every parallel version is a tax on every future change.
In gRPC, the same rule expressed differently: never reuse a protobuf field number, never change a field's type, and let the wire format do the additive work for you.
Inter-service calls: the boring rules
When service A calls service B over the network, treat that call like the unreliable, high-variance thing it is. The defaults that prevent 90% of incidents:
package httpclient
import (
"net"
"net/http"
"time"
)
func New() *http.Client {
return &http.Client{
Timeout: 5 * time.Second,
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: 2 * time.Second,
KeepAlive: 30 * time.Second,
}).DialContext,
MaxIdleConns: 100,
MaxIdleConnsPerHost: 20,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 3 * time.Second,
ResponseHeaderTimeout: 5 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
},
}
}The default http.Client in Go has no timeout and a MaxIdleConnsPerHost of 2. Both of those defaults are catastrophic for service-to-service traffic. The first makes you hang forever when a downstream is slow. The second silently funnels all your traffic through two connections and looks like the downstream is the bottleneck when it's actually you.
Wrap the client in a small retry helper for idempotent calls only, with capped exponential backoff and jitter. Don't retry POSTs unless they carry an idempotency key, or you'll create duplicate orders.
Messaging: the part most teams get wrong twice
Messaging is the area where microservices either become an asset or quietly turn into a debugging nightmare. The hype version is "events everywhere, choreography over orchestration, no coupling". The version that actually works is more careful.
A handful of patterns matter more than the broker you pick.
Pick a broker, not a religion
Go has decent client libraries for everything that matters: NATS (nats.go), Kafka (segmentio/kafka-go, franz-go, or sarama), RabbitMQ (amqp091-go), AWS SQS via the official SDK, Google Pub/Sub via the official SDK. Pick based on what your platform team already runs and what your delivery semantics need:
- At-most-once is rarely what you want. Lost messages mean lost orders.
- At-least-once is what most systems need, combined with idempotent consumers (more on that below).
- Exactly-once exists in some brokers under some conditions. Treat marketing claims about it with deep suspicion. Build for at-least-once and you'll be right.
The framework choice matters less than how you write the consumer.
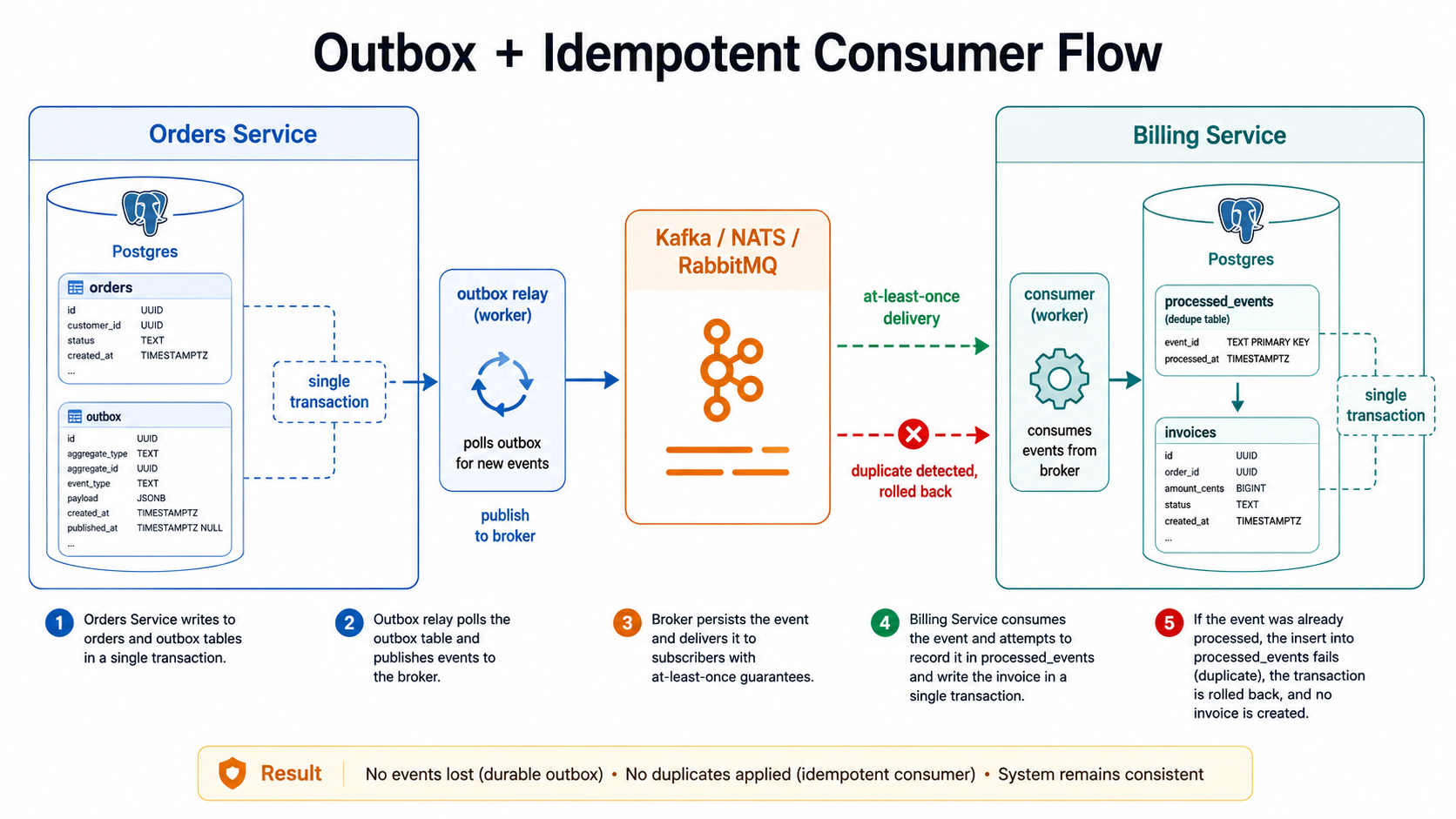
The two patterns you must implement: outbox and idempotent consumer
Here is the bug that bites every team building event-driven systems and skipping these two patterns. Service A writes to its database, then publishes an event. The DB write succeeds, the publish fails (or the process crashes). Now the world believes something that isn't true. Or the inverse: the publish succeeds, the DB write rolls back, and now the world believes something that didn't happen.
The fix is the transactional outbox. Don't publish directly. Write the event to an outbox table inside the same transaction as your domain change. A separate worker reads the outbox and publishes to the broker.
package orders
import (
"context"
"database/sql"
"encoding/json"
"time"
"github.com/google/uuid"
)
type OrderPlaced struct {
OrderID string `json:"order_id"`
CustomerID string `json:"customer_id"`
TotalCents int64 `json:"total_cents"`
PlacedAt time.Time `json:"placed_at"`
}
func PlaceOrder(ctx context.Context, db *sql.DB, customerID string, totalCents int64) error {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return err
}
defer tx.Rollback() //nolint:errcheck // safe to call after Commit
orderID := uuid.NewString()
if _, err := tx.ExecContext(ctx,
`INSERT INTO orders (id, customer_id, total_cents, status) VALUES ($1, $2, $3, 'placed')`,
orderID, customerID, totalCents,
); err != nil {
return err
}
payload, _ := json.Marshal(OrderPlaced{
OrderID: orderID,
CustomerID: customerID,
TotalCents: totalCents,
PlacedAt: time.Now().UTC(),
})
if _, err := tx.ExecContext(ctx,
`INSERT INTO outbox (id, topic, payload, created_at) VALUES ($1, $2, $3, NOW())`,
uuid.NewString(), "orders.placed", payload,
); err != nil {
return err
}
return tx.Commit()
}Then a tiny relay does the publishing:
package main
import (
"context"
"database/sql"
"time"
)
func relay(ctx context.Context, db *sql.DB, publish func(ctx context.Context, topic string, payload []byte) error) {
t := time.NewTicker(500 * time.Millisecond)
defer t.Stop()
for {
select {
case <-ctx.Done():
return
case <-t.C:
rows, err := db.QueryContext(ctx,
`SELECT id, topic, payload FROM outbox WHERE published_at IS NULL ORDER BY created_at LIMIT 100 FOR UPDATE SKIP LOCKED`)
if err != nil {
continue
}
// publish each row, then UPDATE outbox SET published_at = NOW() WHERE id = ...
_ = rows
}
}
}FOR UPDATE SKIP LOCKED lets you run several relay instances safely without them stepping on each other. The cost of this pattern is one extra table and one tiny worker. The benefit is that your domain events stop lying.
The other half of the story is the idempotent consumer. Every message can be delivered more than once. Always. Your consumer needs to detect duplicates and no-op them.
package billing
import (
"context"
"database/sql"
"errors"
)
func HandleOrderPlaced(ctx context.Context, db *sql.DB, msg OrderPlaced) error {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return err
}
defer tx.Rollback() //nolint:errcheck
// dedupe table keyed by event id (carried as a message header in real code)
_, err = tx.ExecContext(ctx,
`INSERT INTO processed_events (event_id) VALUES ($1)`,
msg.OrderID,
)
if err != nil {
if isUniqueViolation(err) {
return nil // already processed
}
return err
}
if _, err := tx.ExecContext(ctx,
`INSERT INTO invoices (order_id, amount_cents) VALUES ($1, $2)`,
msg.OrderID, msg.TotalCents,
); err != nil {
return err
}
return tx.Commit()
}
func isUniqueViolation(err error) bool {
// pg error code 23505 (example shape); check your driver's error type
var pgErr interface{ SQLState() string }
return errors.As(err, &pgErr) && pgErr.SQLState() == "23505"
}The dedupe row and the side effect live in the same transaction. If the side effect fails, the dedupe row rolls back too, so the next delivery will retry properly. This is the pattern that makes "at-least-once" feel like "exactly-once" from the outside.
Dead-letter queues and replay
Even with idempotency and outbox in place, some messages will fail handling forever: bad data, schema drift, downstream that's been removed. Don't let those poison the queue.
Every consumer needs a dead-letter queue (DLQ). After N failed retries (3 to 5 is sane for most systems), move the message to a DLQ topic with the original headers, the failure reason, and a timestamp. Then alert on DLQ depth. Most days the alert is silent; the days it isn't, you'll be glad you have it.
A simple consumer skeleton:
package messaging
import (
"context"
"errors"
"log/slog"
"time"
)
type Handler func(ctx context.Context, msg Message) error
type Message struct {
ID string
Topic string
Payload []byte
Headers map[string]string
Retries int
}
func Consume(ctx context.Context, msgs <-chan Message, handle Handler, dlq func(ctx context.Context, m Message, err error) error, log *slog.Logger) {
const maxRetries = 5
for {
select {
case <-ctx.Done():
return
case m, ok := <-msgs:
if !ok {
return
}
err := handle(ctx, m)
if err == nil {
continue
}
if errors.Is(err, ErrPermanent) || m.Retries >= maxRetries {
if dlqErr := dlq(ctx, m, err); dlqErr != nil {
log.Error("dlq failed", "id", m.ID, "err", dlqErr)
}
continue
}
// requeue with backoff (broker-specific in real code)
time.Sleep(backoff(m.Retries))
}
}
}
var ErrPermanent = errors.New("permanent failure, do not retry")
func backoff(retries int) time.Duration {
return time.Duration(1<<retries) * 100 * time.Millisecond
}The ErrPermanent sentinel lets your handler short-circuit retries when it knows the message is hopeless (e.g., the customer was deleted). No point waiting through five retries to discover it.
Choreography vs orchestration
The buzzword crowd will tell you choreography (services react to each others' events) is "more decoupled" than orchestration (a central workflow tells services what to do).
Practically, the answer is:
- For a small number of well-understood event flows (placed → reserved → charged → shipped), choreography is fine. Each service subscribes to the events it cares about.
- For complex multi-step workflows with compensations (book flight → book hotel → book car → if any fails, undo the rest), use a real orchestration engine. Temporal, Cadence, or AWS Step Functions all have decent Go SDKs. Trying to choreograph a saga across six services with retries and compensations is a guaranteed source of incidents.
Pick orchestration when you find yourself drawing the workflow on a whiteboard and the arrows need numbered steps. Pick choreography when the diagram looks like a fan-out and there is no implied order.
Observability: the boring foundation
If APIs and messaging are how services talk, observability is how you find out what they actually said. This is the area where Go's ecosystem has matured a lot in the last few years, and the patterns that hold up have converged.
Three pillars: structured logs, metrics, traces. You need all three. They answer different questions.
Structured logs with log/slog
Since Go 1.21, log/slog is in the standard library, and it is excellent. Use it. Don't reach for logrus or zap unless you have a specific need for one of their features (zap is faster, logrus has wider middleware ecosystem, slog covers most real cases).
package logging
import (
"context"
"log/slog"
"os"
)
type ctxKey struct{}
func New() *slog.Logger {
return slog.New(slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{
Level: slog.LevelInfo,
AddSource: false,
}))
}
func With(ctx context.Context, l *slog.Logger) context.Context {
return context.WithValue(ctx, ctxKey{}, l)
}
func From(ctx context.Context) *slog.Logger {
if l, ok := ctx.Value(ctxKey{}).(*slog.Logger); ok {
return l
}
return slog.Default()
}A few rules that make logs actually useful:
- JSON in production, text in dev. JSON is what your log aggregator wants; text is what your eyeballs want.
- One log line per logical event. Not three. If you find yourself writing "starting X", "X succeeded", "X took 230ms", collapse them into one structured line at the end with the duration as a field.
- Always attach a
request_idandtrace_id. Bind them to the logger at the edge of the request and pass the logger through context. - Never log secrets or PII. Have a small allowlist of fields your logger emits and reject everything else, or use a pre-commit check. PII in logs is the kind of bug that ends up in a regulator's inbox.
- Don't log errors twice. Log at the boundary that handles the error, not at every layer it bubbles through. Otherwise one failure produces fifteen log lines and your alerting eats itself.
Metrics with Prometheus
The Prometheus client (github.com/prometheus/client_golang/prometheus) is the de facto standard. Counters, gauges, histograms, summaries: the four primitives are enough to instrument almost any system.
package metrics
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
)
var (
HTTPRequests = promauto.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Total HTTP requests",
},
[]string{"method", "route", "status"},
)
HTTPDuration = promauto.NewHistogramVec(
prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "HTTP request latency",
Buckets: prometheus.DefBuckets,
},
[]string{"method", "route"},
)
OutboxLag = promauto.NewGauge(
prometheus.GaugeOpts{
Name: "outbox_unpublished_messages",
Help: "Messages sitting in the outbox waiting to publish",
},
)
)Two pitfalls bite teams new to Prometheus in Go:
- Label cardinality. Don't put
user_idororder_idas a label. You'll create one time series per user. Prometheus will fall over. Use bounded sets: HTTP method (8 values), route (low hundreds), status code (a dozen). - Default histogram buckets are tuned for HTTP latency in the 100ms range. If you're measuring a queue consumer that takes seconds, define your own buckets. If you're measuring something microsecond-scale, define your own buckets. The
DefBucketsare not magic.
The four golden signals (latency, traffic, errors, saturation) are what your dashboards should focus on first. Add per-business metrics later (orders placed per minute, payment failures per minute, queue lag).
Distributed tracing with OpenTelemetry
This is the one most teams skip. Don't. The first time you debug "where did this request spend its 4 seconds" across five services, traces will save you a half-day.
OpenTelemetry is the standard. The Go SDK lives at go.opentelemetry.io/otel. The setup is a little ceremonious but you do it once:
package tracing
import (
"context"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/propagation"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.26.0"
)
func Init(ctx context.Context, serviceName string) (func(context.Context) error, error) {
exp, err := otlptracegrpc.New(ctx)
if err != nil {
return nil, err
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceName(serviceName),
),
)
if err != nil {
return nil, err
}
tp := sdktrace.NewTracerProvider(
sdktrace.WithBatcher(exp),
sdktrace.WithResource(res),
sdktrace.WithSampler(sdktrace.ParentBased(sdktrace.TraceIDRatioBased(0.1))),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{},
propagation.Baggage{},
))
return tp.Shutdown, nil
}A few points worth highlighting:
- Sample. 100% sampling will drown your storage and your wallet. 10% on the trace ID hash is a good starting point for high-traffic services. Always-on sampling for errors (tail sampling) is worth the extra moving parts.
- Propagate context across every hop. HTTP calls need the W3C
traceparentheader injected and extracted. gRPC calls need the OpenTelemetry interceptor (otelgrpc). Message headers need to carry the trace context too. Your messaging library probably has helpers; use them. - Span names are queries. Name them after what the code does (
orders.PlaceOrder,billing.ChargeCard), not after the function (handleHTTP). - Add attributes for the things you'll filter on.
customer.tier,payment.method,order.total_cents_bucket. Not the unbounded ones. Same cardinality lesson as Prometheus.
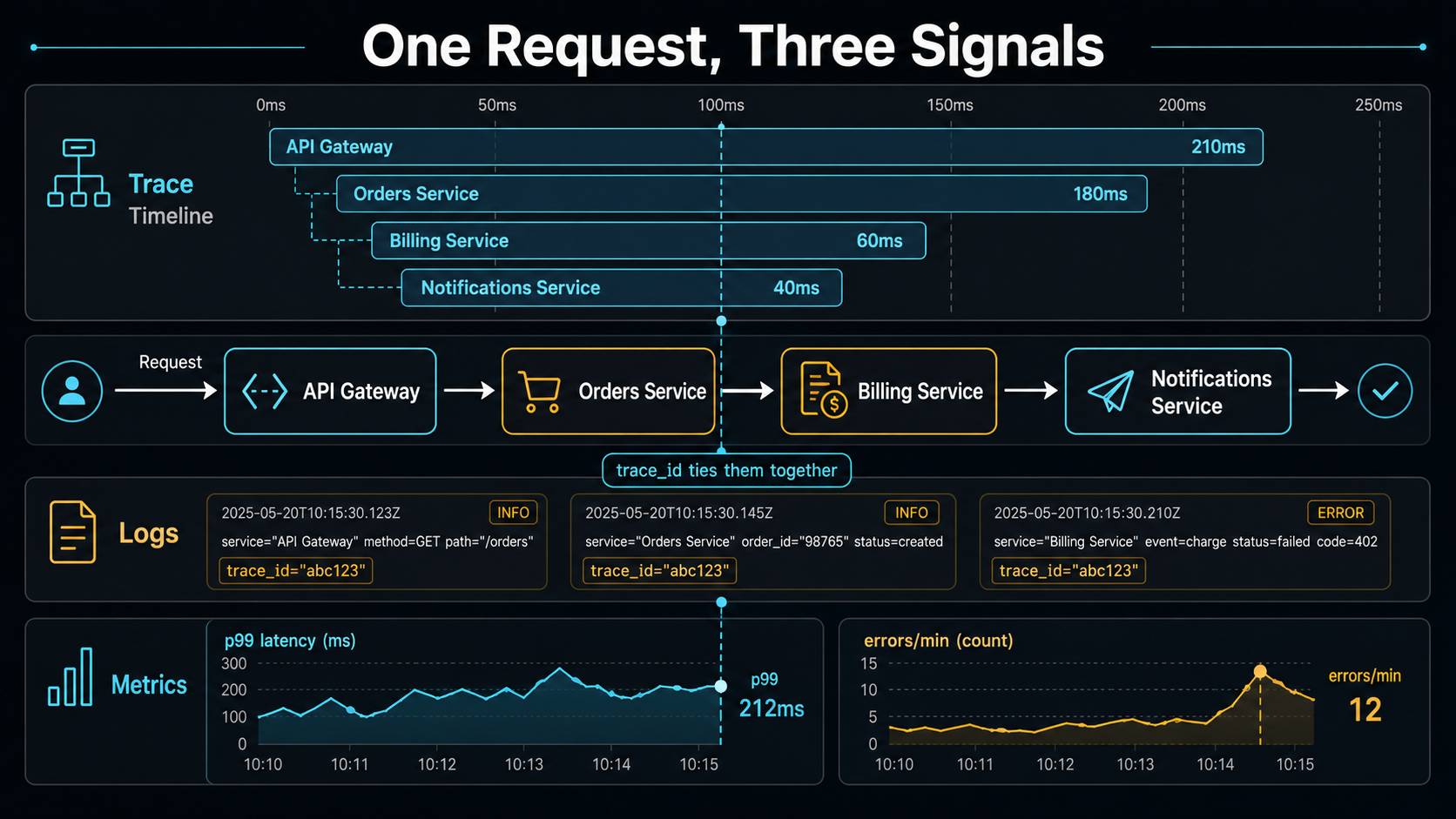
Once tracing is in place, the third dimension is correlation. Every log line should carry the active trace_id. Your dashboards should let you click from a slow trace to its logs in one jump. The unification of logs / metrics / traces around a trace_id is what turns "we have observability" into "we can actually find the bug".
What to alert on
Most teams alert on the wrong things. Symptoms are fewer than 10. Causes are infinite. Alert on symptoms.
Useful alerts:
- HTTP 5xx rate above N per minute on a customer-facing route.
- p99 latency on a critical route above its SLO for 5 consecutive minutes.
- Outbox depth above N for more than 10 minutes.
- DLQ depth nonzero for more than 15 minutes.
- Queue consumer lag above N for more than 5 minutes.
- A pod restarting more than 3 times in an hour.
Avoid: alerts on individual exceptions, alerts on CPU above 80%, alerts that page humans for things humans can't fix at 3am. If an alert isn't actionable, it's noise. Noise becomes ignored alerts. Ignored alerts become incidents.
Configuration: 12-factor or bust
Configuration in Go services should be boring: read from environment variables at startup, validate, fail fast if anything required is missing. No reading config files at runtime, no dynamic reloads, no surprise mutations.
A small wrapper using the standard library plus optional helpers like kelseyhightower/envconfig or caarlos0/env is enough:
package config
import (
"fmt"
"os"
"strconv"
"time"
)
type Config struct {
Port int
DatabaseURL string
BrokerURL string
ShutdownTimeout time.Duration
LogLevel string
}
func Load() (Config, error) {
c := Config{
Port: mustInt("PORT", 8080),
DatabaseURL: mustString("DATABASE_URL"),
BrokerURL: mustString("BROKER_URL"),
ShutdownTimeout: mustDuration("SHUTDOWN_TIMEOUT", 30*time.Second),
LogLevel: getEnv("LOG_LEVEL", "info"),
}
return c, nil
}
func mustString(key string) string {
v := os.Getenv(key)
if v == "" {
panic(fmt.Sprintf("required env var %s not set", key))
}
return v
}
func mustInt(key string, def int) int {
v := os.Getenv(key)
if v == "" {
return def
}
n, err := strconv.Atoi(v)
if err != nil {
panic(fmt.Sprintf("invalid int for %s: %v", key, err))
}
return n
}
func mustDuration(key string, def time.Duration) time.Duration {
v := os.Getenv(key)
if v == "" {
return def
}
d, err := time.ParseDuration(v)
if err != nil {
panic(fmt.Sprintf("invalid duration for %s: %v", key, err))
}
return d
}
func getEnv(key, def string) string {
if v := os.Getenv(key); v != "" {
return v
}
return def
}Crash on bad config. Don't fall back to a sensible default for DATABASE_URL. The container will be restarted by the orchestrator and someone will notice immediately. This is much better than silently running against the wrong database for two hours.
For secrets, never bake them into the image. Mount them from your secret manager (AWS Secrets Manager, GCP Secret Manager, HashiCorp Vault, sealed Kubernetes secrets) into the environment at runtime.
Deployment: containers, health, and the small things that bite
Most Go services in production today are containerized and deployed to Kubernetes, ECS, or a similar orchestrator. The patterns that age well aren't about the orchestrator. They're about the binary inside the container behaving correctly.
A small, correct Dockerfile
# syntax=docker/dockerfile:1.7
FROM golang:1.22-alpine AS build
WORKDIR /src
COPY go.mod go.sum ./
RUN go mod download
COPY . .
ARG VERSION=dev
RUN CGO_ENABLED=0 GOOS=linux \
go build -trimpath -ldflags="-s -w -X main.version=${VERSION}" -o /out/app ./cmd/orders
FROM gcr.io/distroless/static-debian12:nonroot
COPY --from=build /out/app /app
USER nonroot:nonroot
ENTRYPOINT ["/app"]What's worth pointing out:
- Distroless static image. No shell, no package manager, no surprises. The attack surface is essentially the binary plus the kernel.
- Non-root user. Most platforms reject root containers anyway. Bake it in.
CGO_ENABLED=0. A pure-Go static binary is much easier to deploy. Reach for CGO only if you genuinely need a C library (you usually don't).-trimpath -ldflags="-s -w". Smaller binary, no embedded local paths, no debug symbols.- Version baked in. A
--versionflag on your binary that prints the build SHA is invaluable when triaging incidents.
Graceful shutdown, again, properly
We touched on this in the HTTP section, but it deserves more weight. When Kubernetes wants to kill a pod, it sends SIGTERM, waits terminationGracePeriodSeconds, then sends SIGKILL. If your service doesn't handle SIGTERM, every deploy and every node-drain will drop in-flight requests.
The minimal correct shutdown for a service that does both HTTP and message consumption:
package main
import (
"context"
"errors"
"net/http"
"os/signal"
"sync"
"syscall"
"time"
)
func runUntilSignal(srv *http.Server, consumer Stoppable) error {
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer stop()
errCh := make(chan error, 2)
go func() {
if err := srv.ListenAndServe(); err != nil && !errors.Is(err, http.ErrServerClosed) {
errCh <- err
}
}()
go func() {
if err := consumer.Run(ctx); err != nil {
errCh <- err
}
}()
select {
case <-ctx.Done():
case err := <-errCh:
return err
}
shutdownCtx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel()
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
_ = srv.Shutdown(shutdownCtx)
}()
go func() {
defer wg.Done()
_ = consumer.Stop(shutdownCtx)
}()
wg.Wait()
return nil
}
type Stoppable interface {
Run(ctx context.Context) error
Stop(ctx context.Context) error
}Two subtle points:
- HTTP server stops accepting new requests immediately, but waits for in-flight ones up to the deadline.
- The consumer must commit/ack any in-flight message before exiting. Otherwise the broker re-delivers it on next start, which is fine if the consumer is idempotent. If you skipped the idempotency work earlier, this is when the bill comes due.
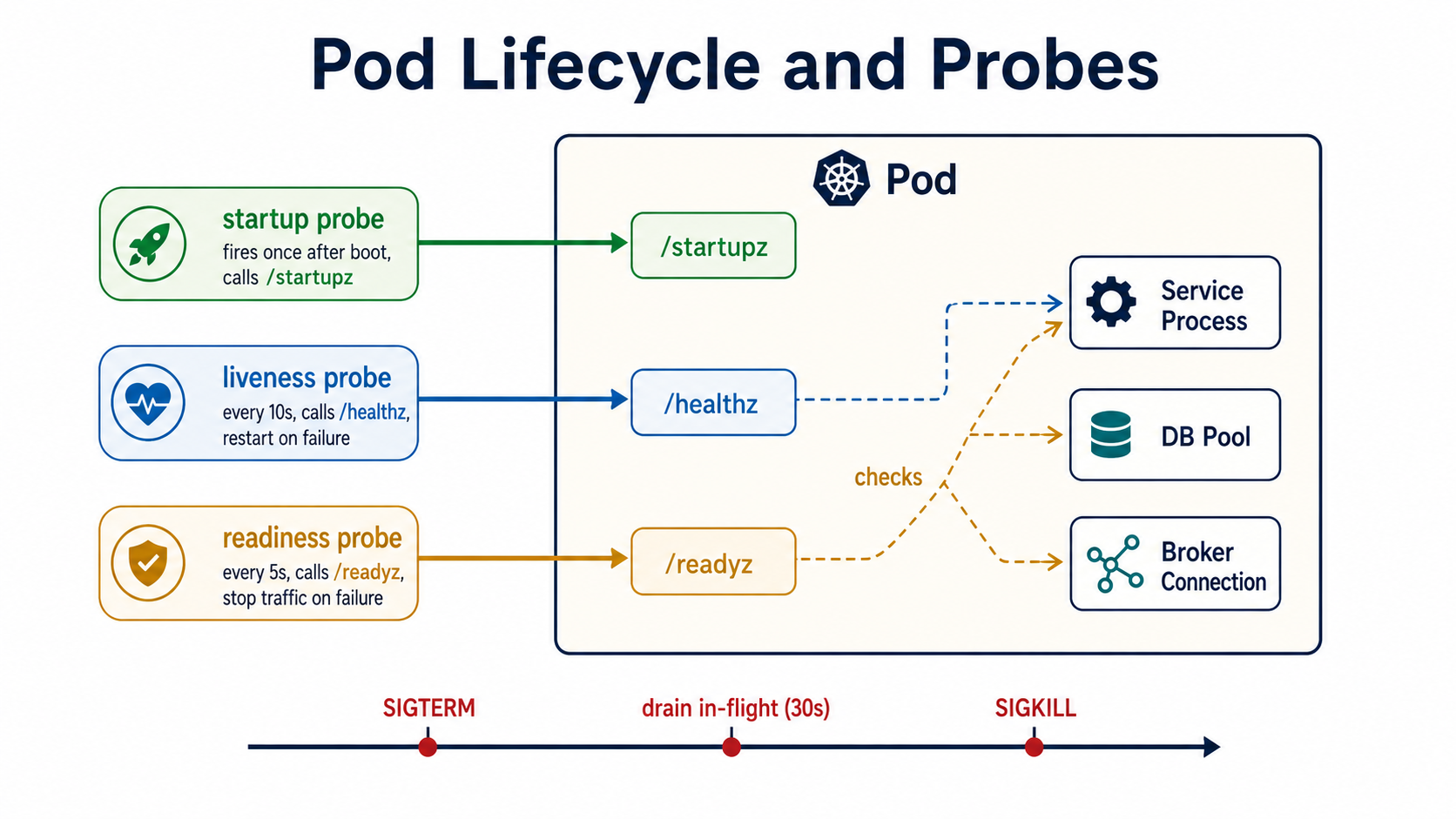
Health, readiness, and startup probes
If your platform supports them (Kubernetes does), use all three probes:
- Startup probe: "are you finished initializing?". High failure threshold, called once during boot. Useful for services that take a while to warm up. Returns 200 once init is done.
- Liveness probe (
/healthz): "are you alive?". Restart the pod if this fails repeatedly. Should only check that the process can answer at all. Don't ping the database here. If the DB is down for 30 seconds, you don't want every pod restart-looping into a thundering herd. - Readiness probe (
/readyz): "are you ready for traffic?". When this fails, the platform stops sending you traffic but doesn't restart the pod. This is where you check downstream dependencies, DB pool warm, broker connection alive.
A common mistake: putting DB connectivity checks in /healthz. When the DB hiccups, every pod gets restarted, which floods the DB with connection storms during recovery. Keep liveness dumb.
Configuration of the runtime itself
A few Go-specific runtime knobs worth setting in container deployments:
GOMAXPROCS. When running in a container with CPU limits, the Go runtime may see all the host's CPUs and spin up too many threads. Useautomaxprocsfrom Uber (go.uber.org/automaxprocs); import it for its side effect, and it setsGOMAXPROCSfrom the cgroup CPU quota.GOMEMLIMIT(Go 1.19+). Set this to about 90% of the container memory limit so the GC backs off before the OOM killer arrives. Hitting OOM is much worse than running a slightly more aggressive GC.GOGC. The default of 100 is fine for most services. Tune it after measuring, never before.
ENV GOMEMLIMIT=900MiBimport _ "go.uber.org/automaxprocs"Two lines of configuration that prevent two of the most annoying production behaviors.
One service per repo or monorepo?
A perennial question with no clean answer. The trade-offs that hold up:
- Monorepo wins when teams need shared libraries, when refactors cross service boundaries, when you want a single CI definition. The tooling cost is real but manageable (Bazel, Earthly, Nx for Go, or just clever Makefiles + GitHub Actions paths-filter).
- Polyrepo wins when teams have full autonomy and rarely share code, when CI complexity is a problem, when you need fine-grained access control per service.
Most of the Go shops I've seen do monorepos for a domain (all the payments services in one repo, all the order services in another) and only shard further when a team explicitly wants to. The "every service its own repo" pattern usually creates more pain than it relieves.
Testing across services
Testing microservices well is harder than testing a monolith, and most teams underinvest here. Three layers worth budgeting time for:
Unit tests inside each service. Standard go test. Aim for the parts of your code that have logic: pricing rules, validation, state machines. Don't chase 100% coverage; chase coverage of the things that would hurt to break.
Integration tests against real dependencies. testcontainers-go makes it trivial to spin up a real Postgres, Kafka, Redis, etc., for the duration of a test run. The ergonomics are very good now.
package orders_test
import (
"context"
"testing"
"github.com/testcontainers/testcontainers-go/modules/postgres"
)
func TestPlaceOrder_WritesOutboxRow(t *testing.T) {
ctx := context.Background()
pg, err := postgres.Run(ctx, "postgres:16-alpine",
postgres.WithDatabase("test"),
postgres.WithUsername("test"),
postgres.WithPassword("test"),
)
if err != nil {
t.Fatal(err)
}
t.Cleanup(func() { _ = pg.Terminate(ctx) })
// connect, run migrations, exercise PlaceOrder, assert outbox row exists
}Real DB tests catch the entire class of bugs that mock-DB tests will silently pass: column type mismatches, transaction semantics, constraint violations, migration compatibility.
Contract tests between services. When service A calls service B, both teams should agree on the contract via a checked-in schema (OpenAPI, protobuf, or a JSON Schema). A small contract test verifies that A's request and B's response actually match the schema. Tools like Pact exist, but a homemade approach using the schema as the source of truth and a few golden-file tests is often simpler.
End-to-end tests across the whole system are valuable but expensive. Keep the count small (a dozen at most) and treat them as smoke tests for critical user journeys, not as the place to find logic bugs.
A few things you can skip
To balance the "do this" advice, here are a few things the hype tells you to do that you can probably skip on day one:
- Service mesh. Istio, Linkerd, Consul Connect: all good products solving real problems for very large fleets. For the first 20 services, the same problems are better solved by good library code and a sensible reverse proxy. Adopt a mesh when you have a specific cross-cutting concern (mTLS everywhere, traffic shifting, fine-grained authorization) that is genuinely painful to solve any other way.
- GraphQL gateway in front of microservices. Sometimes useful for mobile clients, often a place complexity goes to hide. Be sure you'd benefit before adopting.
- CQRS and event sourcing. Powerful patterns for a small number of subdomains where the read and write models genuinely diverge. Catastrophic if applied universally because someone read a blog post.
- Polyglot persistence as a default. If every service picks its own database, your platform team will hate their life. Default to one or two well-understood databases and let teams justify exceptions.
- A new framework per service. Pick a small set of libraries (router, ORM if any, broker client, observability) and use them across services. The cost of a junior engineer being able to read any service in your fleet is much higher than the cost of using slightly-suboptimal libraries in some of them.
The thread through all of these: the cost of complexity is always higher than the brochure says, and the boring tools have boring failure modes you already know how to debug.
The shape of a service that ages well
If you stripped a Go microservice down to the patterns that actually matter, you'd find:
A small cmd/ directory per binary. Configuration loaded from the environment, validated, crashing on missing required values. An HTTP server with sensible timeouts, a chi router, structured logging via slog, Prometheus metrics on a separate port, OpenTelemetry traces propagating through every hop. A consumer worker that idempotently handles every message and writes outbox rows in the same transaction as domain changes. Health and readiness probes that mean different things. A distroless container image with a non-root user, GOMEMLIMIT set, automaxprocs imported. Graceful shutdown on SIGTERM. Integration tests against real dependencies via testcontainers.
None of that is exciting. None of it makes a good conference talk. All of it is what separates a service that runs quietly for two years from one that pages someone every other Saturday.
Microservices in Go are a great default when the problem actually calls for them. They're a terrible default when the problem doesn't. The patterns above don't care which side of that line you're on. They make whatever you build less likely to wake you up. That's the only metric that matters.





