
You've worked on a pipeline that nobody trusts. You know the shape of it. People stop reading the test output and skim for the red square. They re-run the job two or three times hoping it'll go green. They merge with the build still spinning because, well, "the integration tests are flaky anyway." At some point someone in the team chat asks if they can just turn that one job off "for now," and a senior engineer types back "lol that one's been broken since March." Everyone laughs because the alternative is crying.
That pipeline isn't broken because the YAML is wrong. It's broken because nobody believes it. And once a pipeline loses the team's trust, every signal it produces (failures, warnings, security alerts, performance regressions) gets filtered through "ehhh, probably nothing." Which is the worst place a CI/CD system can be, because the whole point is to catch the actual nothings before they ship.
Designing a pipeline developers trust isn't really a tooling problem. It's a UX problem dressed up in YAML. The same way good APIs feel obvious and bad APIs feel like sandpaper, good pipelines feel like a teammate watching your back and bad ones feel like a passive-aggressive coworker who reports you to HR every time you change a variable name. Let's walk through what actually moves the needle: fast feedback, stable tests, security gates that don't punish people, clear failure messages, and a few smaller things nobody talks about until they're missing.
What "Trust" Actually Means In A Pipeline
Before optimising anything, it's worth being precise about what you're optimising for. Engineers trust a pipeline when three things are simultaneously true.
First, when it says you're broken, you actually are. False positives (flaky tests, infrastructure hiccups, transient network errors masquerading as real failures) destroy trust faster than slowness, faster than awkward UX, faster than anything else. A test suite that fails 1 in 50 runs for reasons unrelated to your change trains the entire team to ignore failures by default. And once the default is "ignore," the suite is no longer a safety net, just decorative red lights.
Second, when it says you're fine, you actually are. This sounds obvious until you see a team that has 92% test coverage on the wrong things. The pipeline tells everyone everything is green, but production keeps catching fire because the tests cover trivial getters and the actual money paths are checked by a single happy-path integration test that hasn't been updated since the company pivoted. Trust here is about what the pipeline is checking, not just whether the checks pass.
Third, it gets out of your way fast enough that you don't develop bad habits around it. A pipeline that takes 40 minutes for the first signal trains people to push three commits and check Slack an hour later. A pipeline that takes 90 seconds trains them to fix things as they go. Both pipelines run the same tests. They produce different engineers.
Hit all three and the pipeline becomes invisible in the best way: present, fast, honest. Miss any one and the rituals start: re-running jobs, merging on a hunch, ignoring security warnings, asking around in Slack whether this particular failure is real. None of those rituals show up in a metrics dashboard, but they're where trust quietly leaks out.
Fast Feedback Is The Foundation
If you only fix one thing about your pipeline, fix the latency on the first failure signal. Not the total runtime. It's the time until the developer hears "no, don't bother going to lunch yet, your branch is broken."
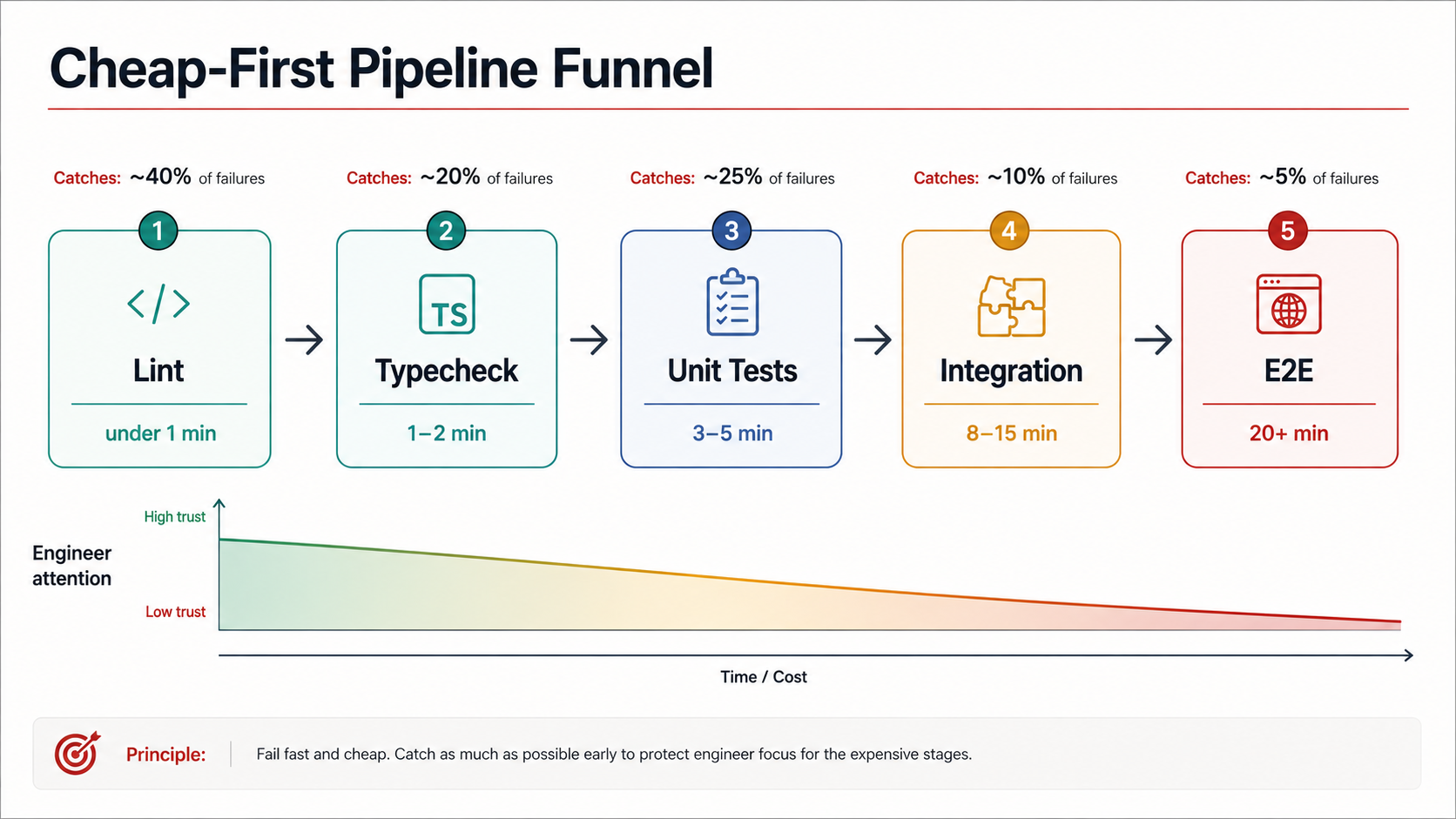
Most pipelines that feel slow aren't slow because of total wall time. They're slow because they put their slowest checks at the front, or because they run everything sequentially, or because they cache nothing. You can have a 30-minute pipeline that feels fast because the lint job finishes in 12 seconds and the type-check finishes in 45 and 90% of failures get caught in the first two minutes. You can also have a 12-minute pipeline that feels glacial because no one knows whether they're broken until minute 9.
The mental model that works: think of stages as a funnel of cost. Cheap checks first, expensive checks last. Each stage should only run if the cheaper stages passed.
name: CI
on: [pull_request]
jobs:
lint:
runs-on: ubuntu-latest
timeout-minutes: 3
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- run: npm ci
- run: npm run lint
typecheck:
runs-on: ubuntu-latest
needs: lint
timeout-minutes: 5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- run: npm ci
- run: npm run typecheck
unit:
runs-on: ubuntu-latest
needs: typecheck
timeout-minutes: 8
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- run: npm ci
- run: npm test -- --runInBand=false
integration:
runs-on: ubuntu-latest
needs: unit
timeout-minutes: 15
services:
postgres:
image: postgres:16
env:
POSTGRES_PASSWORD: test
options: >-
--health-cmd "pg_isready -U postgres"
--health-interval 10s
redis:
image: redis:7
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- run: npm ci
- run: npm run test:integrationThat's nothing fancy. The point is the ordering. A broken import statement fails in lint at minute 1. A bad type fails in typecheck at minute 2. A logic bug fails in unit at minute 4. Only the changes that actually look correct on the surface burn the 15 minutes of integration tests. The fastest failure path is short because most failures are shallow.
The other big win is parallelism. Anything that doesn't depend on something else should run alongside it, not after. In the example above, lint blocks typecheck, which blocks unit, which blocks integration. That's a defensive choice. Each later stage costs more, so you don't pay for it on hopeless branches. But you can split within a stage. A monorepo with five services can run five lint jobs in parallel and finish in the time of the slowest one. A test suite of 2000 tests can shard into 8 jobs that each run 250 tests and finish in roughly one-eighth the time, minus overhead.
unit:
runs-on: ubuntu-latest
strategy:
matrix:
shard: [1, 2, 3, 4, 5, 6, 7, 8]
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- run: npm ci
- run: npx jest --shard=${{ matrix.shard }}/8Shard count is a knob: too few and you don't save time, too many and the per-shard overhead (boot, install, restore cache) starts dominating. Watch the per-shard runtime and aim for each shard to do at least 30 seconds of real test work. If a shard spends 90% of its time on npm ci and 10% on tests, you've sharded past the useful point.
The third pillar is caching. Every CI run reinstalls dependencies, recompiles type definitions, and rebuilds containers, unless you tell it not to. Good caching is the difference between a 9-minute pipeline and a 90-second one. Cache your package manager's downloaded packages, your compiled output, your Docker layers, your build artifacts between stages. Most CI platforms have a cache action that takes a key derived from your lockfile.
- uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- uses: actions/cache@v4
with:
path: |
.next/cache
node_modules/.cache
key: build-${{ runner.os }}-${{ hashFiles('package-lock.json') }}-${{ hashFiles('src/**/*.ts', 'src/**/*.tsx') }}
restore-keys: |
build-${{ runner.os }}-${{ hashFiles('package-lock.json') }}-The two-level key matters. The exact key hits when nothing changed at all (rare). The restore-keys fallback hits when the source changed but the dependencies didn't, which is the common case, and it means each build starts from the previous build's cache rather than from zero. This is the single highest-leverage CI optimisation in most JavaScript and TypeScript projects, and most teams set it up once badly and never revisit it.
One last thing about feedback speed: failure detection isn't only about CI runtime. Where does the failure appear? If it shows up in a buried log file inside a CI tab that nobody has open, you've added five minutes of human latency on top of the machine latency. The best pipelines push failure notifications directly to the developer: a PR comment, a chat ping on the channel they're in, a status check that flips red on the GitHub PR page. The signal has to travel to where the developer already is, not the other way around.
Stable Tests, Or Why Flake Is The Trust-Killer
Here's the brutal truth about test flake: a 2% flake rate destroys trust faster than a 30-minute build. Slowness is annoying but predictable. Flake is gaslighting at scale.
Picture this. You push a PR. Tests fail. You read the failure, scratch your head, can't reproduce it locally. You re-run the job. It passes. You merge. Three days later someone else hits the same failure for real and now you can't tell whether their test is flaky or actually broken. You re-run theirs. It passes too. You merge again. The bug ships. By the time you find out, the failure has been ignored 14 times across 5 PRs and you've fully trained yourself to treat that one test as a slot machine.
This is the failure mode that quietly destroys pipelines. Each individual re-run feels reasonable. The cumulative effect is a team that no longer reads test output. So the question worth obsessing over is: what are you doing about flake, structurally? Not "do you fix flakes when they happen" (every team says yes to that and most teams are lying) but "what does your pipeline do when it detects flake."
A few patterns that work.
Quarantine the flake. When a test fails on main after passing on its PR, mark it as quarantined automatically. Quarantined tests still run, but they don't block the build. Instead, they post to a dashboard the platform team watches. The test stays quarantined until someone fixes the actual root cause, not until someone gets sick of seeing it and removes it. The discipline here is that the pipeline decides what's quarantined, not the engineer-of-the-day under deadline pressure.
# A pseudo-config showing the structural idea — your actual implementation
# will live in your test runner's plugins or a custom reporter.
quarantine:
enabled: true
threshold:
failures_in_last_n_runs: 3
out_of: 50
on_quarantine:
notify: "#platform-flake"
block_merge: false
label_pr: "quarantine-active"
expire_after_days: 14 # forces someone to look at itMeasure flake rate as a first-class metric. Most CI platforms can tell you which tests have flipped between passing and failing in the last N runs without any code change in between. If you don't have a dashboard showing the top 20 flakiest tests in your suite, you don't really know where flake lives. The minute you have that list, prioritisation gets easy. The top 5 tests are causing 80% of the pain.
Treat retry as a debugging tool, not a feature. Many teams add --retries 2 to their test runner and then forget about it for two years. That config quietly hides 5-10% of real bugs while pretending to "fix flake." If you must retry, retry with explicit logging, and every retried test should produce a record that goes somewhere visible. Bonus points if a retried-and-passed test still appears as a yellow warning in the PR, not a green check. The pipeline shouldn't lie about how confident it is.
Hit the root causes, not the symptoms. Most flake is structural. Time-based assertions (expect(eventCount).toBe(5) after a 200ms timeout), unmocked external services, tests that share state through a database that doesn't get cleaned between runs, race conditions in setup teardown order. These are the usual suspects. They're not unfixable, they're just unsexy, and they almost never get prioritised over feature work unless someone in the leadership chain has felt the pain personally.
Different language ecosystems have different default flake traps. JavaScript test suites flake on real timers and async leakage. Go tests flake on shared globals and goroutine ordering. Python tests flake on import-time side effects and tmpdir collisions between parallel workers. The fix isn't a universal pattern, but the posture is: a flaky test is a bug in the test, not an act of God.

Security Gates That Don't Punish People For Working
This one's the most common place I see pipelines lose the team. Security tooling shows up as a vendor mandate or a compliance requirement, gets bolted into the build, and starts blocking merges on issues nobody can act on. SAST tools flag thousands of "warnings," dependency scanners block PRs for CVEs in dev dependencies, secret scanners catch a base64 string that turns out to be a unit test fixture. The pipeline starts saying no a lot, and engineers learn to bypass it.
The instinct that ruins these pipelines is "if it's a security check, it must block." That's how you get teams routing around security entirely, building tribal knowledge about "which secrets manager rule you have to disable to push your PR," and developing genuine resentment for the security team. The pipeline becomes an adversary instead of an ally.
The pattern that actually works is advisory before blocking, blocking only for the things you'd actually revert for.
| Check | Advisory | Blocking |
|---|---|---|
| SAST findings on existing code | yes | only if new finding introduced by this PR |
| New dependency vulnerability (CVE) | yes | only critical CVE in runtime dependency |
| Secret in git history | yes (notify) | yes (block + rotate) |
| Misconfigured IAM/Terraform plan | yes | yes, if change touches production accounts |
| License compliance issue | yes | only if license is on org's denylist |
Two-layer triage like this saves the relationship. Advisory checks teach the team what exists. Blocking checks stop the things that genuinely should not ship. If your blocking-rules list is more than five or six items long, you've probably crossed into "punishes people for working" territory. Trim it.
The other piece is who fixes what. If a SAST scanner flags an issue in a file the PR didn't touch, blaming the PR author is a non-starter: they didn't write it, they don't own it, and they can't reasonably fix it before their feature ships. Modern scanners support "diff-only" or "delta" mode, where they only report on findings introduced by the current change. Turn that on. Reserve the full-repo scan for a nightly job that opens its own tickets routed to the actual owners.
Here's a small example of what this looks like in practice. A Dependabot-style auto-merge for low-risk dependency updates, paired with a stricter blocking rule for runtime deps:
version: 2
updates:
- package-ecosystem: "npm"
directory: "/"
schedule:
interval: "weekly"
groups:
dev-deps:
dependency-type: "development"
update-types: ["patch", "minor"]
prod-deps:
dependency-type: "production"
update-types: ["patch"]
open-pull-requests-limit: 10And a CI rule that only blocks on critical CVEs in production dependencies:
- name: Audit production dependencies
run: |
npm audit --omit=dev --audit-level=critical
- name: Audit all dependencies (advisory)
run: |
npm audit --audit-level=high || true
continue-on-error: trueThe first command fails the build. The second runs but its || true and continue-on-error: true make it informational only. Its output is visible in the logs and (ideally) summarised in a PR comment, but it doesn't stop the merge. This is the kind of small, deliberate choice that separates "security tooling people actively use" from "security tooling people circumvent."
Secret scanning is the one place I'd push the other direction. A leaked secret in a commit is not a "you can fix it later" situation: once it's pushed, it's effectively public, and the right move is to block the push, rotate the secret, and force-purge it from history. Most platforms (GitHub, GitLab, pre-commit hooks via gitleaks or trufflehog) can do this at push-time, before CI even runs. That gate is worth being strict on.
Failure Messages That Respect Your Time
This is the most underrated trust factor and almost nobody talks about it. The difference between a pipeline you trust and a pipeline you fight is usually the quality of its failure output.
Picture two test failures.
Failure A:
FAIL src/lib/billing/charge.test.ts
● expected behavior
Error: AssertionError
at Object.<anonymous> (charge.test.ts:42:18)
at processTicksAndRejections (node:internal/process/task_queues:96:5)Failure B:
FAIL src/lib/billing/charge.test.ts > applies coupon discount before tax
Expected order subtotal after coupon:
$90.00
Received:
$94.50
This test calls Cart.calculate() with one $100 item and a 10% coupon.
Tax is applied last in pricing rules. The 4.50 delta matches the tax
being applied before the coupon — check `applyCoupon` ordering in
src/lib/billing/charge.ts:18.
Compared against: db/fixtures/coupons/v3.json
Last passing commit on this test: a1b2c3d (2 days ago)Both report the same bug. One sends you on a 25-minute hunt through git log and unit test internals. The other tells you what's broken and where to start looking. Same pipeline, same tooling, dramatically different developer experience, and dramatically different trust over time.
You can get most of the second style by being deliberate about three things.
Use descriptive test names. "applies coupon discount before tax" is a better name than "expected behavior" even if you're the only person who'll ever read it. Future-you, mid-debug at 2am, will love past-you for writing the boring descriptive name.
Use rich assertion messages. Most testing libraries (Jest, Vitest, pytest, Go's testify, JUnit) let you pass a custom message to your assertions. Use it. "Expected order subtotal after coupon" is better than "Expected".
Print the context. If the test loads fixtures, print which fixture. If it depends on a seed, print the seed. If it's the kind of test that compares against a snapshot, point at the snapshot file. None of this is free (it costs a line or two of code per assertion), but it's the difference between "I can fix this in 90 seconds" and "ugh, I'll come back to it after lunch."
And for the pipeline itself: when a job fails, the top of the log output should tell you what failed and where. Not the bottom. Not in the middle of 4000 lines of npm download chatter. Most CI platforms support custom failure summaries (GitHub Actions has GITHUB_STEP_SUMMARY, GitLab has artifacts:reports, Jenkins has Blue Ocean). Use them. A pipeline that opens the PR comment with "3 unit tests failed, all in billing/charge.test.ts. First failure: applies coupon discount before tax. See log section 'Unit (shard 4)' for details." makes triage trivial.
- name: Report test results
if: failure()
run: |
echo "### Test failures" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
jq -r '.testResults[] | select(.status=="failed") |
"- **\(.name | sub(".*/"; ""))** — \(.assertionResults | map(select(.status=="failed")) | length) failed"' \
test-results.json >> $GITHUB_STEP_SUMMARYTiny change. Big difference. The first thing a developer sees is which file and which test, not "Job failed with exit code 1, scroll up 8000 lines to find out why."
Someone Has To Own It
A pipeline without an owner rots. Not slowly, either. Within months, you'll have orphaned jobs that haven't worked since the last team migration, security scanners that nobody updates, deprecated runner images, plugins pinned to versions that no longer publish. Whenever the build breaks for a reason that isn't a code change, the response is "anyone know how to fix this?" and the answer is silence.
This is the structural version of the flake problem. Individual breakages get patched. Nobody owns the system. So the system trends downward.
The pattern that breaks the rot: pick one team (often called Platform, DevEx, Build, or just the people who actually read the CI dashboards) and give them explicit ownership of the pipeline's reliability. Their job isn't to fix every test failure (that's still the PR author's job). It's to fix the meta failures: the runner that's been failing to start for two days, the secret that expired, the cache key that nobody understood and finally bit-rotted.
Ownership shows up in a few concrete ways.
A status page or dashboard for the pipeline itself. Build success rate over the last 24 hours, p95 build duration, flake rate per suite, top 5 slowest jobs. If nobody can see the trend, nobody can fix it. If the platform team has the dashboard on the wall, they catch the slow degradation before the team starts circumventing the pipeline.
Service-level objectives, even informal ones. A common starting set: 99% of builds succeed for non-flaky reasons, p95 build time under 12 minutes, no security gate adds more than 60 seconds of latency. Numbers are arbitrary; the discipline of writing them down isn't.
A "who do I tag?" answer. When the build is broken and you can't tell why, you should know who to tag in chat. If the answer is "uh, I'll figure it out" or "let me find someone who knows," ownership isn't real. A pinned message in the platform channel, a CODEOWNERS entry for the .github/workflows/ directory, or even just a rotating on-call sticker on someone's desk solves this.
Permission to break things to fix things. The platform team needs the authority to disable a flaky test, revert a bad workflow change, or temporarily switch to a smaller runner without a six-engineer meeting. If every change to the pipeline needs five approvals, nothing changes. The pipeline ossifies, then it loses trust, then people work around it, then it's effectively retired even though it's still running.
A Few Smaller Things That Matter More Than They Look
These don't deserve a section each, but they show up in every pipeline I've seen earn the team's respect.
Pin everything. Pin your runner image versions (ubuntu-22.04, not ubuntu-latest). Pin your action versions to a SHA, not a tag. Pin your tool versions in the CI config, not the Dockerfile, so an outsider can read your workflow and know what runs. The day a major version of actions/checkout ships a breaking change and your CI breaks for everyone simultaneously is the day you wish you'd pinned. (Renovate or Dependabot can keep the pins moving on a controlled schedule.)
Make local reproducible. If a developer can't run the same test locally that CI runs, you've split your reality in two. The fix can be as simple as a make ci target that runs every check the pipeline runs, in the same order, with the same versions. Bonus: a Docker Compose file or a Nix flake that spins up the same database, the same Redis, the same fixtures. The phrase "it passes locally, fails in CI" is a sign of an unhealthy pipeline: it should be exceedingly rare.
Run the pipeline on the default branch too. A surprising number of teams only run CI on PRs, then merge, then discover post-merge that the integration tests broke because the main branch picked up a new commit between PRs and the combination is broken. Run the same workflow on push-to-main and notify a channel when it goes red. That channel becomes the team's heartbeat.
Measure what you optimise. Wall time, p95 wait time, queue depth, success rate, flake rate, top 10 slowest jobs. Pick three of these and put them in a dashboard the platform team looks at every Monday. Without measurement, optimisations are vibes-based and tend to chase the most recent complaint instead of the biggest leverage point.
Be willing to remove tests. Tests are an asset until they're a liability. A test that hasn't found a bug in two years, takes 90 seconds to run, and tests behaviour that's also covered by three other tests is a candidate for deletion. The bar for adding a test is low. The bar for removing one is high. That's backwards. Both decisions should be deliberate.
Your Pipeline Is A Teammate
Strip away the YAML and the runners and the matrix configs, and what a CI/CD pipeline really is, is a teammate. It reviews every change. It catches your typos and your bad assumptions. It tells you when you're about to ship something dangerous. It speaks up when something's wrong and stays quiet when everything's fine. You spend more time with it than with most of the humans on your team.
The question isn't "is the YAML correct." The question is: would you want this teammate on your team? Are they fast? Are they honest? Do they tell you what's wrong instead of just frowning at you? Do they pick their battles, or do they complain about every line of every diff? When they make a mistake, does someone fix it, or does it just sit there for six months until the next migration?
Build the teammate you'd want to work with. The pipeline will earn the team's trust the same way a person does: by being fast, by being honest, by being clear, by being the kind of presence that makes everyone around them better at their job. Get that right and the YAML almost writes itself.





