You merged a one-line fix on a Tuesday and broke billing on Wednesday.
The diff looked clean. The AI suggested it. You glanced, you approved, you moved on. It was a === swapped for a == in a discount calculation. Twelve hours later, the support inbox was full of customers being charged twice. The model didn't lie to you. It just didn't know what you knew - that a particular comparison in that file was load-bearing because of a quirk in how legacy promo codes were stored as strings.
That's the new shape of bugs. Not "the AI is wrong." The AI is mostly right. It's right ninety-something percent of the time, which is exactly the percentage that lulls you into trusting the other few. And the volume of code flowing through your repo has gone up five, ten, twenty times in the last year, depending on how aggressive your team has been with agents. The number of human eyeballs on each line has gone down by the same factor.
Guardrails are how you survive that math.
Not gates. Not roadblocks. Not a six-person review board for every PR. Guardrails are automated checks that catch the specific kinds of mistakes AI tends to make, run cheaply on every change, and fail loud enough that nobody - human or agent - can ignore them. They give you back the safety net that used to come for free when every line was hand-typed and re-read three times before commit.
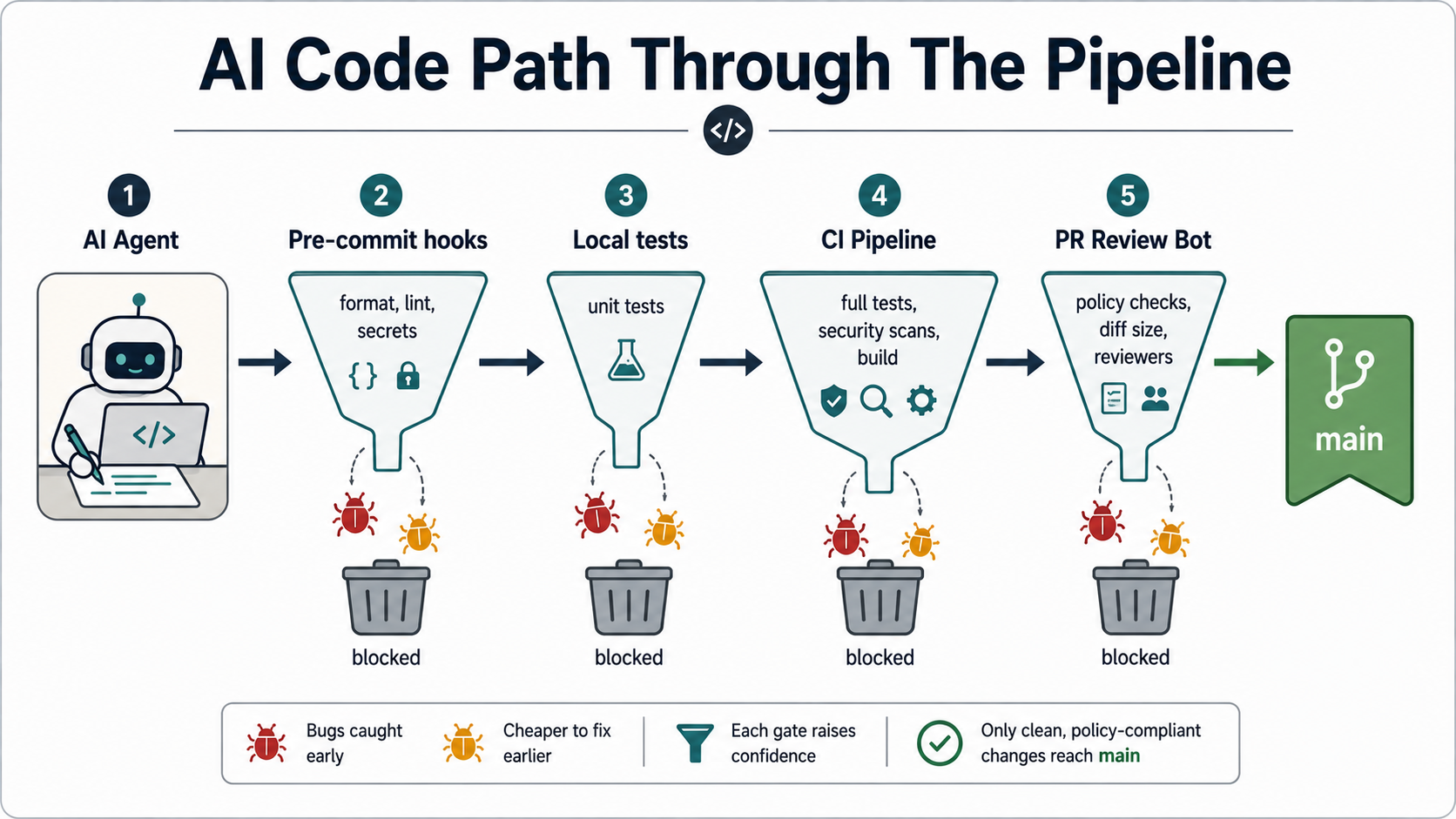
This piece walks the four layers I'd build into any serious workflow that lets AI write code: tests, linters, security scans, and pull-request checks. Each layer catches a different category of mistake. Together they cover most of what slips through when a model is generating faster than you can read.
Why The Old Process Doesn't Scale
Before we get to the layers, it's worth being honest about what changed.
In the pre-AI world, your safety net was the act of writing the code itself. You'd think through edge cases as you typed. You'd remember the weird thing about that one column. You'd notice the function signature already had a timeout parameter and reuse it instead of adding a second one. Code review caught the rest, and the rest was usually small, because the author had already filtered out most of the obvious mistakes.
In the AI-assisted world, the author - the thing producing the keystrokes - has no memory of the weird column, no opinion about the existing timeout parameter, and no incentive to keep the diff small. The model produces a plausible answer. You, the reviewer, are now the first line of defense against everything the model didn't know.
And you are not a great first line of defense. You are tired. You have nine other PRs to review. The diff is forty files. The model wrote a unit test that "covers" the change, and the test passes, and the test is testing the wrong thing, and you're not going to catch it because you trust passing tests the same way you used to trust hand-typed code.
The fix isn't to slow down. The fix is to push the safety net off the human and into the pipeline. Make the checks run before review, not during. Make them block merge, not warn. Make them produce evidence the AI itself can read and respond to, so the agent fixes its own mistakes before a person even sees the PR.
That's what each of the next four sections is about.

Layer One: Tests Are The First Guardrail
Tests are the only layer that knows what your code is supposed to do. Every other layer reasons about the code's shape. Tests reason about its behavior. That makes them the most important guardrail and the easiest one for AI to fake.
The shift you need to make is this: stop treating tests as something the author writes after the code, and start treating them as the spec the AI must satisfy. Tests come first, not last.
When an AI agent is making a change, the workflow should be:
- Human or agent writes a failing test that captures the desired behavior.
- The test runs and fails for the right reason.
- Only then does the agent write or modify code.
- The test runs and passes.
- The full test suite runs and still passes.
If you skip step 1, you get tests that exist to make the diff look complete. Those tests will pass on day one and they will keep passing forever, because they were written to match whatever the code happens to do. They are not guardrails. They are decoration.
A real test forces an honest question: if I changed this function to do nothing at all, would the test fail? If the answer is no, the test is not testing the thing you care about.
Here's the same idea expressed in three languages, because this discipline isn't language-specific - it's process-specific.
import { describe, it, expect } from "vitest";
import { applyDiscount } from "./discount";
describe("applyDiscount", () => {
it("applies a percentage off the subtotal", () => {
expect(applyDiscount(100, { type: "percent", value: 10 })).toBe(90);
});
it("never reduces below zero", () => {
expect(applyDiscount(50, { type: "fixed", value: 80 })).toBe(0);
});
it("treats legacy string promo codes the same as numeric ones", () => {
// the bug that bit us in production - keep this test forever
expect(applyDiscount(100, { type: "percent", value: "10" as any })).toBe(90);
});
});import pytest
from billing.discount import apply_discount
def test_percentage_off_subtotal():
assert apply_discount(100, {"type": "percent", "value": 10}) == 90
def test_never_reduces_below_zero():
assert apply_discount(50, {"type": "fixed", "value": 80}) == 0
def test_legacy_string_promo_codes_match_numeric():
# production incident regression test - do not remove
assert apply_discount(100, {"type": "percent", "value": "10"}) == 90package billing
import "testing"
func TestApplyDiscount(t *testing.T) {
cases := []struct {
name string
subtotal float64
promo Promo
want float64
}{
{"percent off subtotal", 100, Promo{Type: "percent", Value: 10}, 90},
{"never below zero", 50, Promo{Type: "fixed", Value: 80}, 0},
{"legacy string promo same as numeric", 100, Promo{Type: "percent", ValueStr: "10"}, 90},
}
for _, c := range cases {
t.Run(c.name, func(t *testing.T) {
if got := ApplyDiscount(c.subtotal, c.promo); got != c.want {
t.Errorf("ApplyDiscount = %v, want %v", got, c.want)
}
});
}
}Three things make these tests guardrails instead of decoration:
- Each test states the rule it protects, not just the input and output. The "legacy string promo codes" test exists because something broke. Future-you will see that and not delete it.
- The assertions are specific.
toBe(90), nottoBeGreaterThan(0). Loose assertions are how AI-written tests stay green while the implementation drifts. - The boundary cases are explicit. "Never reduces below zero" is the kind of invariant a model is most likely to forget. Encoding it means the next agent that touches the function can't accidentally remove it.
The other test-layer rule worth enforcing in your pipeline: mutation testing on the critical paths. Tools like Stryker (JS/TS), mutmut (Python), or go-mutesting (Go) modify your source code in small ways and re-run your tests - if the tests still pass when a > becomes a >=, you've found a test that isn't really testing. You don't run this on every commit. You run it weekly on the modules where a bug would cost real money, and you treat surviving mutants as bugs in your test suite.
Layer Two: Linters Catch The Boring Stuff Loudly
Linters are the cheapest layer you'll ever run, and they catch the highest volume of small AI mistakes. They should be the loudest part of your pipeline.
The model is going to do things like:
- Import a function it doesn't end up using.
- Define a variable, never read it, never delete it.
- Use
anybecause it didn't want to think about the type. - Reach for
console.login code that runs in production. - Mix tabs and spaces because it got distracted halfway through.
- Write a function with a cyclomatic complexity of 30 because it concatenated three approaches it saw in training data.
A human author would notice. An AI author won't, because none of that breaks anything in isolation. It just slowly turns your codebase into a junk drawer.
The right linter setup is opinionated, fast, and runs on every save in the editor as well as every commit in CI. The "fast" part matters. If your linter takes 90 seconds, your agents will route around it. If it takes 2 seconds, every commit gets the full check and your codebase stays honest.
Modern tooling has converged on a small number of fast, batteries-included linters per language:
name: lint
on: [pull_request]
jobs:
js:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: "20" }
- run: npx biome ci .
python:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with: { python-version: "3.12" }
- run: pip install ruff
- run: ruff check .
- run: ruff format --check .
go:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-go@v5
with: { go-version: "1.22" }
- uses: golangci/golangci-lint-action@v6
with: { version: latest }Biome, Ruff, and golangci-lint are all blazing fast - measured in seconds for repos most of us work in. That speed means you can also run them as a pre-commit hook on the developer's machine, so problems get caught before they even reach a PR.
repos:
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.6.9
hooks:
- id: ruff
- id: ruff-format
- repo: https://github.com/biomejs/pre-commit
rev: v0.4.0
hooks:
- id: biome-checkThe other half of the linter story is custom rules for your codebase's specific bad habits. Off-the-shelf linters catch generic problems. Your team has team-specific problems - a deprecated helper everyone keeps reaching for, a particular import path that was supposed to die two refactors ago, a pattern that always means somebody forgot to call withTransaction. ESLint, Ruff, and golangci-lint all support custom rules; tools like Semgrep let you write codebase-specific patterns in a YAML-friendly syntax without needing to learn an AST library.
A Semgrep rule that catches one of the most common AI mistakes - using a deprecated helper:
rules:
- id: no-deprecated-fetch-user
pattern: fetchUser($X)
message: |
fetchUser was deprecated in 2025-Q3. Use loadUser(id, { tenant })
instead - the new helper enforces tenant scoping.
languages: [typescript, javascript]
severity: ERRORTwo lines of YAML, and every PR that reintroduces the deprecated helper fails CI with a useful message. An AI agent reading that message in the failed-check log knows exactly what to fix.
That last point matters more than it sounds. A linter error that says "no-unused-vars: 'foo' is assigned but never used" is a great message for a human and an even better one for an agent - it's specific, it's actionable, and it tells the agent exactly which edit to make. Loud, specific guardrails are the ones AI agents can actually fix without human intervention.
Layer Three: Security Scans Are Non-Negotiable
This is the layer that takes the longest to convince a team to invest in, and the one that pays back the most when an AI agent commits something it shouldn't.
The categories of mistakes you're guarding against here are specific:
- Hardcoded secrets - API keys, database passwords, JWT signing secrets pasted into source. AI agents do this with depressing regularity, especially when they're trying to make an example "work end-to-end."
- Vulnerable dependencies - outdated packages with known CVEs, or new packages with shady provenance. Models cheerfully pull in whatever they saw in training data.
- Unsafe code patterns - SQL string concatenation,
eval, command injection, unchecked file path joins, missing CSRF tokens, raw HTML interpolation. - Supply-chain risks - typo-squatted package names, packages that suddenly started running install scripts, packages whose maintainer just changed.
Each one has dedicated tooling. None of them are optional in 2026.
Secret Scanning
Two layers: scan the working tree before commit, and scan the git history continuously.
- repo: https://github.com/gitleaks/gitleaks
rev: v8.18.4
hooks:
- id: gitleaksGitleaks and TruffleHog both work well. Pick one, run it as a pre-commit hook and in CI, and configure GitHub's built-in secret scanning (or your platform's equivalent) on the repo. Belt and braces - the local hook prevents commits, the CI run catches anything that slipped through, and the platform scan watches the history forever, including for credentials that get rotated after the leak.
If a secret does land in your history, the only safe response is: revoke the secret, then clean the history with git filter-repo or BFG, then force-push and rotate every dependent system. Don't just delete the file - the secret is in the reflog, in old packs, and in every clone anyone has. Pretending it isn't is how breaches happen.
Dependency Scanning
name: security
on:
pull_request:
schedule:
- cron: "0 6 * * *" # nightly
jobs:
audit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Trivy filesystem scan
uses: aquasecurity/trivy-action@master
with:
scan-type: fs
severity: CRITICAL,HIGH
exit-code: "1"
ignore-unfixed: trueTrivy scans your lockfile against known vulnerability databases. Run it on every PR (to block new CVEs from being introduced) and nightly (to catch CVEs that get disclosed against dependencies you already have). Combine with Dependabot or Renovate for the actual upgrade PRs.
The ignore-unfixed: true flag is the difference between a useful security check and a Slack channel everyone mutes. If there's no patched version available, there's nothing you can do today - surfacing it as a blocking error just teaches the team to wave checks through.
Static Application Security Testing (SAST)
This is where Semgrep or CodeQL earn their keep. Both ship large rulesets that catch language-level security issues - SQL injection, command injection, deserialization bugs, path traversal, weak crypto. They work by pattern-matching against your AST, not by running the code, so they're fast enough to put on every PR.
A minimal CodeQL setup on GitHub Actions is one workflow file generated by the platform; for Semgrep:
name: semgrep
on: [pull_request]
jobs:
semgrep:
runs-on: ubuntu-latest
container:
image: returntocorp/semgrep
steps:
- uses: actions/checkout@v4
- run: semgrep ci --config p/owasp-top-ten --config p/security-audit --config .semgrep/That single line pulls in the OWASP Top Ten ruleset, a general security audit ruleset, and any local rules you've defined. It will catch most of the unsafe patterns AI agents introduce, and it will catch them as PR comments your agent can read and fix.
Supply Chain
The harder problem. A package can pass every check the day you install it and become malicious the next time it auto-updates. The defenses here are layered: pin exact versions in your lockfile, require code review on dependency updates (Dependabot PRs go through the same gauntlet as feature PRs), prefer well-maintained packages with multiple maintainers, and consider tools like Socket or Snyk that score packages on health and behavior.
For your most sensitive repos, also consider vendoring critical dependencies or running them through an internal proxy that caches a known-good copy. It's more friction. It's appropriate friction when an AI agent is the one suggesting npm install some-random-thing.
Layer Four: PR Checks Are Where Policy Lives
The first three layers are about the code itself - does it work, is it clean, is it safe. The fourth layer is about the change - is this PR safe to merge?
A PR check is a policy enforcer. It looks at the PR as an artifact - the diff, the title, the description, the linked issue, the reviewers, the labels - and asks questions the code-level layers can't:
- Is the diff small enough that a human can actually review it?
- Does the description explain why, not just what?
- Are there tests for the changed code?
- Did somebody who isn't the author look at it?
- Are the right code-owners on it?
- Is the commit message useful?
- Is this PR touching something that requires extra sign-off (database migrations, auth code, billing logic)?
These are the questions that used to live in someone's head as "good engineering judgment." When an AI agent is opening the PR, you need them encoded, because the agent has none of that judgment by default.
Diff Size Limits
The single highest-leverage PR check you can add. AI agents will happily produce 2,000-line refactors. Humans cannot review 2,000-line refactors. Cap the diff size and force the agent to split.
name: pr-checks
on: [pull_request]
jobs:
size:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with: { fetch-depth: 0 }
- name: Check diff size
run: |
ADDED=$(git diff --shortstat origin/${{ github.base_ref }}...HEAD | grep -oE '[0-9]+ insertion' | grep -oE '[0-9]+' || echo 0)
DELETED=$(git diff --shortstat origin/${{ github.base_ref }}...HEAD | grep -oE '[0-9]+ deletion' | grep -oE '[0-9]+' || echo 0)
TOTAL=$((ADDED + DELETED))
echo "Total changed lines: $TOTAL"
if [ "$TOTAL" -gt 500 ]; then
echo "::error::Diff is too large ($TOTAL lines). Split this PR into smaller pieces."
exit 1
fi500 lines is a starting point - pick whatever your team can actually review with care. Add an override label like large-pr-approved for the genuine cases that can't be split, and require a second maintainer to apply it. Friction by design.
Required Tests For Touched Code
This one's harder to enforce perfectly, but the simple heuristic catches the most obvious gaps: if a PR changes files under src/, it should also change files under tests/ (or whatever your test layout is). A check that fails when source code changed without test changes is rough, but it's a useful default - and the override is easy when it's wrong ("docs-only", "config-only", "test-only refactor").
A Danger.js rule does this in a few lines:
const { danger, warn, fail } = require("danger");
const sourceChanged = danger.git.modified_files.some(f => f.startsWith("src/"));
const testsChanged = [...danger.git.modified_files, ...danger.git.created_files]
.some(f => f.includes(".test.") || f.startsWith("tests/"));
if (sourceChanged && !testsChanged) {
fail("Source code changed but no test files were added or modified. Add tests, or add the 'no-tests-needed' label with an explanation.");
}
if (!danger.github.pr.body || danger.github.pr.body.length < 50) {
fail("PR description is missing or too short. Explain *why* this change exists, not just what it does.");
}Danger runs as a CI step and posts comments back on the PR. It's the cheap way to enforce conventions that aren't quite worth a custom GitHub App.
Path-Scoped Reviewers
CODEOWNERS is the most underused file in most repos. Put one in, list the people or teams responsible for each part of the codebase, and GitHub will automatically request review from the right humans when those paths change.
# Billing code requires a billing team reviewer
/src/billing/ @company/billing-team
# Auth code requires security team sign-off
/src/auth/ @company/security-team
# Database migrations require a senior engineer
/migrations/ @company/senior-engineers
# Anything in infra needs the platform team
/infra/ @company/platform-teamCombined with branch protection rules that require reviews from code owners before merge, this single file enforces "the right people look at the right changes" without anyone having to remember to add reviewers manually. When an AI agent opens a PR that touches /src/billing/, the billing team is automatically pulled in - no chance the agent quietly merges without sign-off.
Commit Message Discipline
The boring one that pays off six months later when you're trying to figure out why a line changed. Conventional Commits is the lowest-friction format: feat:, fix:, chore:, with an optional scope and a short imperative subject. Enforce it with a check.
name: commitlint
on: [pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with: { fetch-depth: 0 }
- uses: wagoid/commitlint-github-action@v6This won't make AI commit messages good, but it'll prevent the worst of them - the ones that just say "fix" or "updates" or, my favorite, an exact copy of the diff in the commit body.
How The Four Layers Compose
Each layer catches a different category of mistake, but the real power is in their overlap. A hardcoded API key gets caught by secret scanning (layer 3), but the unused variable next to it gets caught by the linter (layer 2). A logic bug in a function gets caught by the test (layer 1), but the fact that the PR ships 1,400 lines of changes with no description gets caught by the PR checks (layer 4).
When you build them right, every change passes through all four:
- Local pre-commit hooks - format, lint, secret scan, fast unit tests. Failures here never even leave the developer's laptop.
- CI on push - full test suite, security scans, full lint, build verification. Failures here never reach review.
- PR-level checks - diff size, test coverage, description quality, required reviewers, commit message format. Failures here force the change to be reshaped before a human spends time on it.
- Branch protection - main is protected, requires all checks to pass, requires code-owner approval, requires the branch to be up to date. Failures here are the absolute backstop.
The order matters because of cost. Pre-commit is fastest and cheapest. CI is slower but still cheap. PR checks involve a little human time. Branch protection is the most expensive because by the time you hit it, somebody is waiting on the merge. Push as much of the filtering as you can to the earliest layer, so the later layers have less to do.
Make Failures Readable
A theme that runs through all of this: the value of a guardrail is proportional to how clearly it tells you what went wrong.
A linter error that says "'user_id' is defined but never used" is fixable. A linter error that says "Configuration violation in rule 4231" is not. A test that fails with "expected 90, got 80 - discount calculation returned wrong value for legacy string promo codes" tells the next agent what to fix. A test that fails with "AssertionError" makes the agent guess.
When you set up these layers, spend the extra ten minutes on the error messages. Custom Semgrep rules with explanatory message: fields. Danger rules with full sentences and links to docs. Test names that read like specifications. The work pays off every single time a check fires, and the more AI agents you have opening PRs, the more often it fires.
What This Doesn't Replace
Guardrails are not a substitute for code review. They are a substitute for trivial code review - the kind where most of your attention goes to formatting, naming, missing tests, and obvious bugs. Once the trivial stuff is automated, the human review can focus on what matters: does this change make sense, is the architecture right, are we taking on debt we can pay back, will future-us understand why we did this.
Guardrails also don't replace understanding the code you ship. If the AI writes a payment integration and every layer passes, that doesn't mean someone on your team understands how it works. It just means it isn't visibly broken. Maintain the habit of reading critical code yourself. The pipeline catches mistakes; only humans catch misunderstandings.
And guardrails don't replace incident response, observability, or the slow work of paying down complexity. They protect the inbound flow of changes. They don't fix anything that's already in the codebase.
What they do is buy back the trust you used to have in your own diff. They make it safe to let the AI move fast - because the slow, careful, irreplaceable part of engineering judgment now lives in a pipeline that runs in seconds, on every change, on every branch, every time. The model is fast and forgetful. The pipeline is fast and remembers everything. That combination is what makes AI-assisted development actually work at scale.
You don't need all four layers in production on day one. Start with the cheapest, loudest one - a fast linter and a secret scanner - and add layers as the volume of AI-generated code in your repo grows. By the time you're letting agents merge their own PRs, all four layers should be load-bearing.
Build the guardrails first. Then let the AI run.