You used to write a function in fifteen minutes and review it in two.
Now the AI writes it in fifteen seconds, and you spend the next thirty minutes deciding whether it does what it says it does. The ratio flipped, and nobody updated the playbook. Half the teams I talk to have responded by reviewing AI code the same way they reviewed human code, sometimes less carefully, because the diff "looks clean", and the other half have responded by trusting the AI more once it stops making obvious mistakes. Both of these are wrong, and both of them are how AI-shaped bugs end up in production.
The shift is simple to say and uncomfortable to act on. When the cost of writing code drops to near zero, the cost of verifying code does not. If anything, it goes up. The volume of code you have to read, reason about, and trust per week is larger. The variance in correctness is wider. The failure modes are subtler. And the person on the hook when something breaks is still you, the senior engineer who approved the merge.
This piece is about what changes in the testing and reviewing job when most of the keystrokes aren't yours anymore. It isn't a checklist. It's an argument that "AI writes the code, you write the tests" is the new minimum, not the new ceiling, and that the teams treating AI output as if it deserved less scrutiny are quietly building up technical debt they can't see yet.
The New Economics Of Writing Versus Verifying
For most of software history, writing code was the expensive part of the job. You spent two hours thinking about a problem, one hour typing the solution, and ten minutes reviewing it. The author bore most of the cognitive load, because the author had to construct the thing from nothing.
AI inverted that ratio. Now the construction is cheap. You describe the function, the AI hands you something plausible, and you're left holding a 40-line diff you didn't write. The bottleneck isn't typing anymore. It's the question: is this actually right?
That question is harder than it sounds, because the AI is good. Not perfect, but good. It produces code that compiles, passes lint, often passes the test you would have written first. It uses idiomatic patterns. It picks reasonable variable names. It handles the obvious edge cases. By every surface signal, the code looks fine.
The problems live underneath the surface signals. The AI confidently uses an API method that does exist but has different semantics in the version your project pins. It writes an off-by-one in a slicing operation that only fires on inputs of length 1. It assumes a config value is always present because most examples on the internet treat it that way, and your codebase happens to be the one that doesn't. It silently changes the order of operations in a way that doesn't matter mathematically but matters for floating-point precision in a billing calculation.
These bugs are not the kind a casual review catches. Casual review catches typos and missing null checks. AI bugs are usually one layer deeper, assumptions about the environment, the data, or the contract that the AI couldn't verify and you didn't think to.
"Looks Right" Is The Most Dangerous State
There's a specific failure mode that didn't exist before AI got this good, and it doesn't have a great name yet. The closest one I can think of is plausibility bias. The AI's output looks so close to what a correct solution would look like that your brain stops checking.
You've probably felt this. You skim a 30-line AI diff. The function name is good. The control flow is reasonable. The early return looks like an early return you would have written. The variables are named the way you'd name them. Your brain pattern-matches to "looks like working code" and you hit approve, because what's the alternative, staring at every line as if you were debugging it?
Compare that to reviewing a junior engineer's code. The names are slightly off. The structure is unconventional. The style isn't quite the team's style. Every visual cue prompts you to slow down. You read each line because each line looks like somebody's attempt and you can feel where attempts go wrong.
AI doesn't trigger those cues. The output is too smooth. It's been trained on the median of competent code, which is exactly what experienced eyes scan past without engaging. The signal that something is off, the small awkwardness that makes a senior engineer pause, has been sanded out of the diff before you see it.
This is why "looks right" is the most dangerous state in an AI review. When the code looks unfamiliar, you slow down. When it looks wrong, you fix it. When it looks right, you merge it. And "looks right" is now the default state of every AI diff you see.
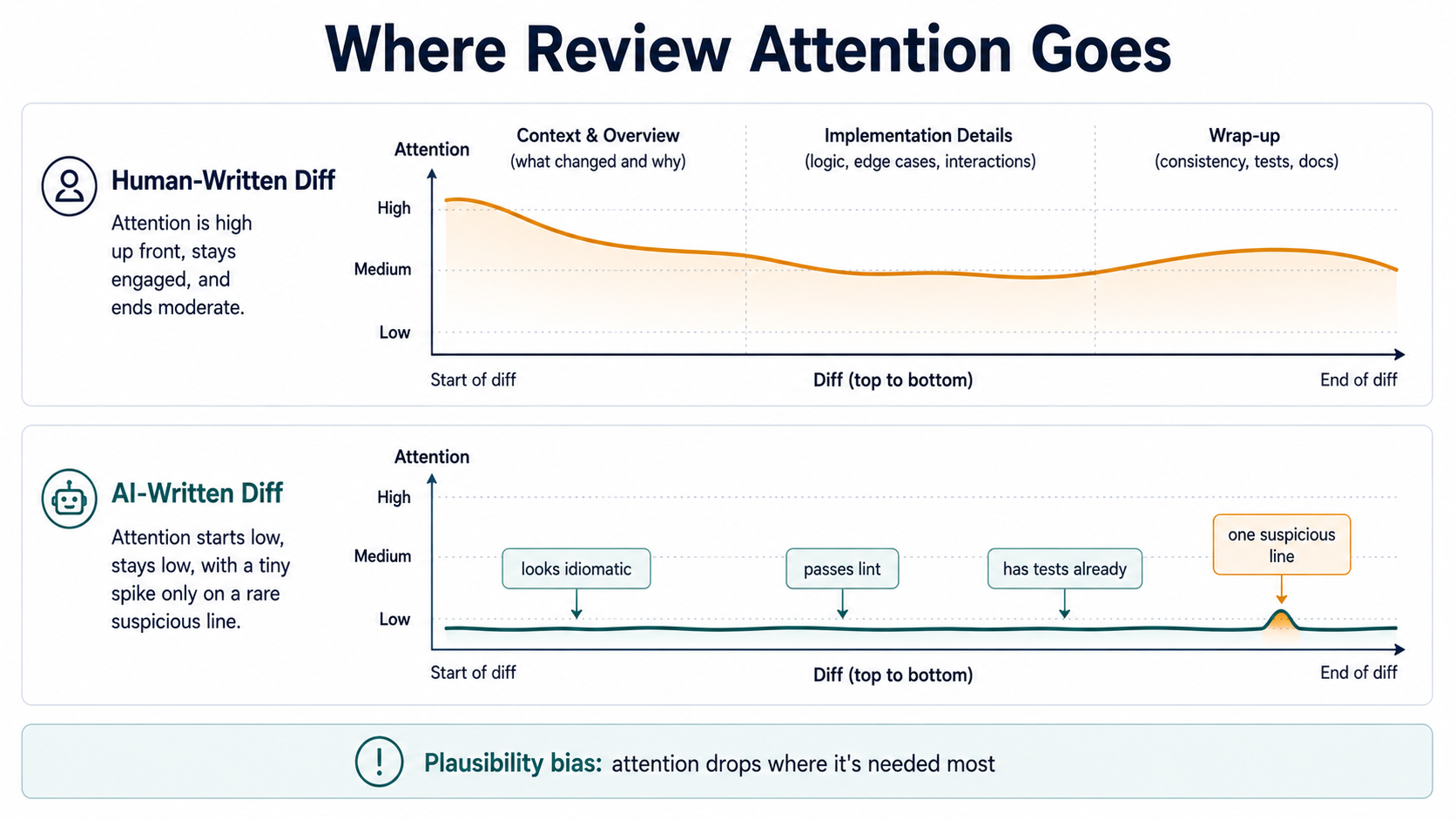
The fix is not "review every line harder", because attention is finite and willpower doesn't scale. The fix is to put verification outside the part of the workflow that runs on tired human attention. Which brings us to tests.
Why "The AI Wrote The Tests Too" Is A Trap
The first response a team usually has to AI-generated code is "great, let's have the AI write the tests too." This is fast, productive-feeling, and almost completely useless as verification.
The problem is circular. If the AI wrote the implementation under the assumption that X is true, and you ask the same AI to write tests for that implementation, it will write tests that also assume X is true. The tests pass. Everything looks fine. The hidden assumption, the one that the AI got wrong, the one that's going to break in production, sits unverified inside both the code and the tests, agreeing with itself.
A real example of how this plays out. Imagine you ask the AI to write a function that validates an email address, and it writes a regex-based validator. You then ask it for tests. It will give you:
describe('isValidEmail', () => {
test('accepts a normal email', () => {
expect(isValidEmail('user@example.com')).toBe(true);
});
test('rejects missing @', () => {
expect(isValidEmail('userexample.com')).toBe(false);
});
test('rejects empty string', () => {
expect(isValidEmail('')).toBe(false);
});
test('accepts an email with a subdomain', () => {
expect(isValidEmail('user@mail.example.com')).toBe(true);
});
});Every one of those tests passes. The function is "tested". But the AI wrote a regex that, like a thousand examples on Stack Overflow, doesn't actually match RFC 5321, it rejects valid plus-addressing in some forms, accepts addresses with trailing dots, and silently truncates at 254 characters when it should reject at 320. None of that is exercised, because the same model decided what the function did and what to test.
The tests aren't lying. They're proving the wrong thing. They prove the function does what the AI thinks it should do. That's not what tests are for.
The way out is not to ban AI-written tests, that would be silly, they're useful as a starting point. The way out is to be deliberate about which tests the human writes and which the AI writes. The split that holds up in practice:
- The human writes the contract. What this function must do at its boundaries. What inputs it must reject. What invariants it must preserve. What side effects are allowed and which are not. This is a specification, not implementation. The AI shouldn't be involved.
- The AI writes the enumeration. Once the human-defined contract exists as a list of cases, the AI can generate the test bodies, the fixtures, the assertion plumbing. This part is mechanical and the AI is excellent at it.
- The human writes the adversarial test. The case the AI didn't think of. The edge that breaks the assumption. The malformed input. The race condition. The thing that's supposed to fail and confirms the function handles it.
If you do nothing else from this article, do this: every time you accept an AI-generated function, write at least one adversarial test by hand. Not "an extra test". An adversarial one, designed to find the case the AI would have missed. You won't always succeed. The point is the habit, because it's the only check that breaks the circle.
What Verification Actually Needs To Catch Now
The bugs that survive AI-assisted development are different from the bugs that survive human-written code. Listing them out helps decide where to invest tests.
Hidden assumptions about the environment. The AI writes code that works on its version of Node, your team uses an older one, and Array.prototype.toSorted doesn't exist on it. Or: the AI assumes Postgres, your team uses MySQL, and RETURNING doesn't work the way the generated query expects.
Silent semantic differences in API choice. Two methods do "almost the same thing", and the AI picks the more common one. parseInt('08') returning 0 in old Node versions. Object.keys versus Reflect.ownKeys. == versus is in Python. .equals() versus == in Java for boxed types. These mistakes used to come from junior developers who didn't know better. Now they come from AI that knows better but defaulted to the more popular pattern.
Off-by-ones in slicing, dating, and pagination. AI is shockingly bad at boundary conditions. It will write a pagination query that returns 11 rows instead of 10, an end-exclusive slice where the codebase uses end-inclusive, or a date range that misses the last second of the day.
Mutation versus copy. A function the AI claims is pure quietly mutates its input. The caller doesn't notice because the mutation matches what the caller would have done anyway. Three months later, the function gets reused in a context where the mutation breaks something five layers up.
Side effects that don't appear in the function name. A method called getUser that also touches the audit log. A validate function that also normalises. A parse function that also logs. The AI is happy to bundle responsibilities the human reviewer would have rejected on sight if a person had written it.
Dependency hallucination, fixed. Early AI tools made up package names. Modern ones rarely do. But they do something subtler: they import a package that exists, with a function that exists, with a signature that used to exist in version 2 but changed in version 3. Your package.json is on v3, the AI's training data leaned on v2 examples, and the call shape is wrong in a way that compiles but throws at runtime on a specific code path.
Security-shaped failures. Input that should have been escaped wasn't. A SQL query that almost uses a parameterised binding but interpolates one variable. An auth check that runs but doesn't actually block on failure because the early return came from the wrong branch. These are the most expensive bugs to catch in review and the most expensive to leave to production.
The pattern across all of these: the failure is small, the surface code looks right, and it survives default tests. None of them get caught by "did you write a test for this?", they get caught by which test, written by whom, with which mindset.
Reviewing AI Code Is A Different Job From Reviewing Human Code
Once you've internalised the failure modes, the way you read a pull request has to change. Reviewing a human's code is mostly about checking judgement, did they pick the right approach, structure it well, name things sensibly? Reviewing AI code is mostly about checking grounding, does this code's mental model of the world match reality?
A few shifts that have worked for teams I've watched do this well:
Read the diff against the spec, not against your taste. A human reviewer's instinct is to compare new code against a Platonic ideal of how it "should" look. With AI code, that ideal is irrelevant, the AI's output is always going to look reasonable. Compare against the contract the function is supposed to fulfill instead. If the contract isn't written down, write it down before you approve.
Insist on small diffs, even more than before. A 400-line human-written PR is reviewable because the human wrote it linearly and you can follow the train of thought. A 400-line AI-generated PR is six unrelated decisions stitched together by a model that doesn't share your priorities. Limit AI agents to scopes you can read in fifteen minutes. Bigger scopes will get rubber-stamped, not because reviewers are lazy, but because attention isn't elastic.
Ask "what would have to be true for this to be wrong?" This is the most useful question in an AI review and the least useful in a human one. With a human, you trust their reasoning unless you see a specific problem. With AI, you start from "this is probably right but might be confidently wrong in one place" and explicitly hunt for the place. Look at boundary conditions. Look at the place where the function meets the rest of the system. Look at the assumption no test exercises.
Insist on seeing the prompt that produced the code. I'm aware this sounds bureaucratic. It's not, in practice, it takes ten seconds to paste in. The prompt is the closest thing to a spec the AI was given. Reading it tells you what the human asking thought they were asking for, which is often subtly different from what the AI produced, which is the gap where bugs hide.
Treat passing tests as a hypothesis, not a conclusion. If the AI wrote the tests, they prove the AI is internally consistent. They don't prove the code works. Before approving, ask: what's the simplest test I could write right now that, if it failed, would reveal a real bug? If you can't think of one, you don't understand the code well enough yet.
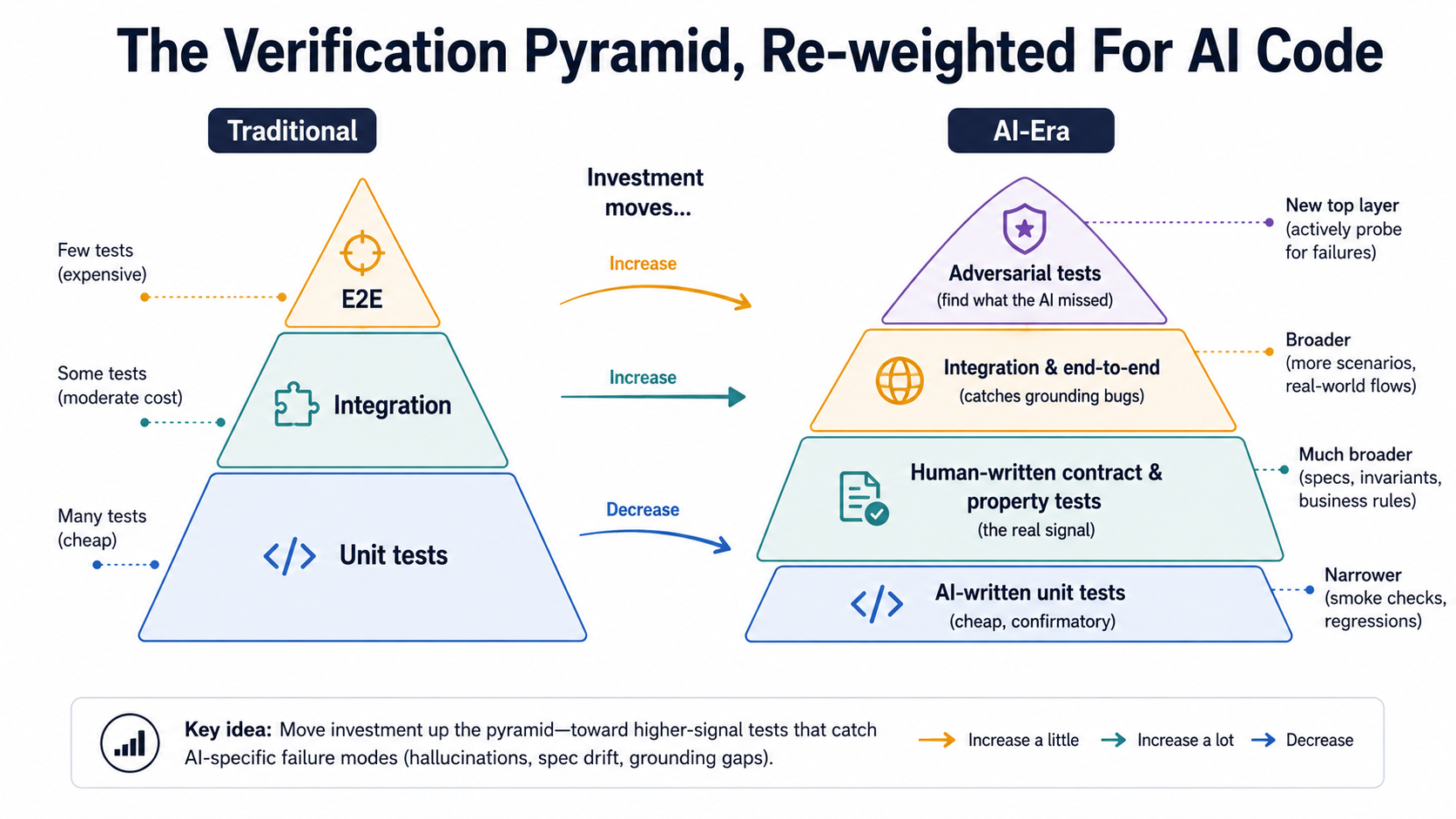
The pattern is consistent: the kind of attention shifts. Human review is depth-first on judgement. AI review is breadth-first on grounding, with depth where the grounding looks shaky.
The Tests That Earn Their Keep In An AI Workflow
Not every test pulls equal weight in an AI-heavy codebase. Some tests are basically free verification, the AI can write them, they catch occasional bugs, they don't slow anyone down. Others are where the real signal lives. The ones below are the ones I'd push a team to invest in if they were going AI-heavy.
Contract tests at the boundary. For every external-facing function (API endpoint, queue consumer, public library method), pin the contract, the exact shape of input it accepts, the exact shape of output it returns, the errors it raises. These are not unit tests. They're a specification that survives refactors. When the AI refactors the implementation, the contract test catches any drift. Write these by hand. Never let the AI generate them, because the whole point is that they encode your intention, not the AI's interpretation.
Property-based tests for anything mathematical or transformational. Anything that takes data in and gives data out, parsers, serializers, normalizers, validators, calculators, benefits enormously from property tests. "For any valid input, the output is also valid." "Parsing then serializing is identity." "The function is idempotent." These are the tests that catch AI's boundary-condition mistakes, because they generate boundaries you wouldn't have thought to enumerate. Tools like fast-check (JavaScript), hypothesis (Python), quickcheck (Haskell, Rust, others) make this approachable.
from hypothesis import given, strategies as st
from billing import calculate_late_penalty
@given(
amount=st.decimals(min_value=0, max_value=100_000, places=2),
days_late=st.integers(min_value=0, max_value=365),
)
def test_penalty_never_exceeds_principal(amount, days_late):
penalty = calculate_late_penalty(amount, days_late)
assert penalty <= amount, "penalty must never exceed the unpaid amount"
@given(amount=st.decimals(min_value=0, max_value=100_000, places=2))
def test_zero_days_late_yields_zero_penalty(amount):
assert calculate_late_penalty(amount, 0) == 0The AI might write the function correctly. Or it might calculate a penalty that exceeds the unpaid amount when the input rounds in a specific way. The property test catches the second case without you having to imagine it.
Characterization tests before any AI refactor. If you're letting an AI agent modify existing code, capture the current behavior first, feed real inputs, record the outputs, assert that the refactored version matches. This was originally a legacy-code technique, and it's exactly the right tool here. The AI's job is to refactor without changing observable behavior. Characterization tests make that requirement enforceable. (If you want the long version of this idea applied to legacy code, the legacy codebases piece on this blog walks through the same loop.)
Integration tests for the unglamorous seams. Where your code meets a database, a queue, an HTTP API, a filesystem, that's where AI's confident-but-wrong mental model causes the most damage. The AI thinks the database is Postgres 14. It's actually 11. The AI thinks the queue has at-least-once delivery semantics. It's actually exactly-once. Integration tests against a real-shaped environment catch those mismatches because they hit the real interface. Mocks won't.
One end-to-end smoke test per critical user journey. Not a hundred. One that walks through a real path: log in, do the thing, see the thing. If the AI broke something significant, this test fails. It's the cheap insurance policy that pays for itself the first time it catches a regression.
Everything else, unit tests for trivial getters, exhaustive enumeration tests, tests that only assert the AI did what the AI claimed to do, those can be AI-written and AI-maintained. They're confirmatory, not investigative. The investigative work is the human's.
What This Looks Like In Practice
A normal AI-assisted feature might go like this. You decide what you want, say, a new endpoint that returns paginated audit log entries filtered by user and date range. Before writing a line of code, you draft the contract:
GET /api/audit-logs
Required query params:
user_id (uuid)
start_date (ISO 8601 date, inclusive)
end_date (ISO 8601 date, inclusive)
Optional:
page (integer >= 1, default 1)
page_size (integer 1..100, default 25)
Returns:
200 with { items: AuditEntry[], total: integer, page, page_size }
400 if any required param missing or malformed
403 if caller lacks audit:read on user_id's tenant
404 if user_id does not exist
Invariants:
- items are ordered by created_at DESC, ties broken by id ASC
- total reflects the full filtered count, not just this page
- date range is inclusive on both ends
- page_size > 100 is a 400, not silently cappedThat contract is what you'd hand to a colleague. Now you ask the AI to write the implementation. It returns 80 lines of plausible code. You read it for grounding, does it use your project's auth middleware? Does it handle the date inclusivity correctly? Does it actually validate page_size > 100?
Then you write the tests yourself, against the contract, three of them by hand, the adversarial ones (date ranges that span DST, a user_id that exists but is in a tenant you don't own, a page_size of 101). You let the AI fill in the rest of the enumeration, the happy paths, the missing-param cases, the empty-result case.
You run the suite. The hand-written adversarial test fails, because the AI's pagination capped silently at 100 instead of returning a 400. You fix that in five minutes. The other tests pass.
The whole thing took an hour. Without the AI, it would have been an hour and a half of typing. With the AI but without the contract-first discipline, it would have been twenty minutes, and a silent bug shipping to production once a year, the way silent bugs do.
That's the actual time math of AI-assisted development. The savings are real, but they live on the writing side, not the verifying side. Treating verification as the same job it always was, or worse, as a job that needs less attention now, is how you give the savings back, plus interest.
The teams that come out ahead on AI tooling aren't the ones writing the most AI code per week. They're the ones who matched the speed of code generation with a real, deliberate upgrade to how they verify it. Tests sharper. Reviews more focused. Contracts written down. Adversarial cases written by humans. The slow part of the work moved earlier, where it can actually catch something, instead of later, where it can only apologise.