So you've shipped a Node service that worked beautifully when it had one job. A POST /orders came in, you charged the card, stored the row, fired off the confirmation email, updated the inventory, pinged the warehouse, dropped a row in the analytics warehouse, refreshed the search index, and returned 201 Created. Maybe 600ms end-to-end. Customers were happy. Nobody asked questions.
Then a few more teams got involved. The fraud team wanted a hook before the email goes out. The loyalty team wanted points awarded - but only if the order wasn't cancelled within ten minutes. Marketing wanted every order routed to a campaign attribution engine. The CRM team wanted a daily summary. And finance wanted a guaranteed audit log that survives even if the rest of the request implodes. Suddenly that 600ms request handler is doing eleven things, half of which can fail in interesting ways, and every new feature adds another try/catch to the same function that does the actual order-taking.
That's the moment people start saying "event-driven." Usually before anyone agrees on what it means.
This piece walks through what event-driven architecture actually buys you in Node, the two brokers most teams end up choosing between (Kafka and RabbitMQ) and where each one earns its keep, the producer and consumer patterns that actually survive contact with production, the outbox pattern - which is the single most important thing nobody mentions in the "intro to events" articles - and the way async workflows behave when things go wrong, which is the only mode that ultimately matters.
What "Event-Driven" Actually Means In A Node Service
Before brokers and topics and queues, get the vocabulary straight, because half the confusion in design reviews comes from people using the same word for three different things.
An event is a statement of fact about something that already happened. OrderPlaced, PaymentCaptured, EmailBounced, UserDeleted. Past tense, on purpose - events are immutable. You don't get to retract them, you only get to publish a new event that describes the next thing.
A command is the opposite - it's a request to do something. SendWelcomeEmail, ChargeCard, RefundOrder. Present tense, addressed to a specific handler. Commands can be rejected. Events cannot.
A lot of "event-driven" systems are really command-driven systems with a queue in the middle. That's fine - it's still a useful pattern - but the design implications are different. An event has zero, one, or many subscribers, none of which the publisher knows about. A command has exactly one intended handler. If you build your topics as email.send.requested and your handler is a single email service, that's a command in event clothing. There's nothing wrong with it, but don't expect to bolt three more subscribers onto that topic later and have the system behave correctly.
The other thing to nail down is in-process events vs cross-process events. Node's built-in EventEmitter is event-driven, technically. So is EventTarget. So is anything built on RxJS. None of these survive a process restart, cross a network boundary, or coordinate work between two pods of your service. When people say "event-driven architecture" with capital letters, they almost always mean durable, cross-process events - events that live in a broker, can be replayed, and reach subscribers that weren't running when the event was originally produced.
This article is about the durable kind. In-process emitters are a great tool, but they don't change your architecture.
The Two Real Choices: Kafka vs RabbitMQ
There are dozens of brokers. NATS, Redis Streams, AWS SQS, Google Pub/Sub, Azure Service Bus, ActiveMQ, Pulsar. They all have legitimate use cases. But in the wild, in Node services, the choice almost always comes down to Kafka or RabbitMQ. So let's talk about why, and which one fits which problem.
Kafka is a distributed, partitioned, append-only log. That sentence sounds boring until you internalize it. A Kafka topic is a log file (well, a set of log files - one per partition). Producers append messages to the end. Consumers read forward from some offset and remember where they were. Nothing is ever "consumed" in the sense of being removed; the broker keeps messages around for a configured retention period (typically days to weeks) regardless of who has or hasn't read them.
This has consequences. You can replay every event from the last seven days by resetting a consumer group's offset to zero. You can have ten consumer groups reading the same topic independently - the loyalty service and the fraud service and the analytics pipeline all see every OrderPlaced, each at their own pace, none affecting the others. You can scale a single consumer group horizontally by adding instances and Kafka redistributes partitions to them. And because each partition is strictly ordered, you can guarantee that all events for the same order_id are processed in the order they were produced, as long as you partition by order_id.
RabbitMQ is a smart router with queues. Producers send messages to exchanges, which use bindings to decide which queues should receive a copy. Consumers pull from queues, and once a message is acknowledged it's gone from the queue forever. There's no built-in replay. There's no built-in partitioning by key. What you get instead is flexible routing - topic exchanges with wildcard bindings, fanout exchanges that broadcast to every bound queue, direct exchanges that route by exact key - and excellent support for per-message workflows like priority, TTL, dead-letter exchanges, and per-consumer prefetch.
The mental shift between them: Kafka is "stream of facts, read at your own pace, replay whenever you need to." RabbitMQ is "work item, route it intelligently, hand it to exactly one worker, retry on failure."
When does each fit? A rough cut:
Reach for Kafka when events have natural ordering you care about (per-user, per-order, per-account), when multiple independent consumers need the same events, when replay matters (rebuilding a read model, recovering from a bug in a consumer, onboarding a new service), when the volume is high enough that "every consumer keeps its own copy" would be expensive, or when you're building a CDC / event-sourcing / streaming-analytics setup.
Reach for RabbitMQ when each event has exactly one logical handler, when the routing logic is the interesting part (a single message needs to fan out to three different worker queues based on payload), when individual messages need per-item controls (priorities, TTLs, scheduled delivery, RPC patterns), when failure handling needs rich dead-letter behaviour with retry queues, or when the team operating it has way more experience with classic AMQP brokers than with Kafka.
And, the unsexy truth: pick the one your platform team is willing to run. Both are stable. Both are reasonable. The difference between a well-operated RabbitMQ and a half-operated Kafka, or vice versa, is enormous, and it dwarfs the difference between the two technologies themselves.
Producing Events: The Code That Looks Easy And Isn't
Here's a barebones Kafka producer using kafkajs, the standard library for Kafka in Node:
import { Kafka, Partitioners } from "kafkajs";
const kafka = new Kafka({
clientId: "orders-service",
brokers: ["kafka-1:9092", "kafka-2:9092", "kafka-3:9092"],
});
const producer = kafka.producer({
// The legacy partitioner uses Java-incompatible hashing; new code should pin this.
createPartitioner: Partitioners.DefaultPartitioner,
// Wait for all in-sync replicas to ack before considering a write successful.
// This is what "we won't lose your event" actually requires.
idempotent: true,
maxInFlightRequests: 1,
});
await producer.connect();
export async function publishOrderPlaced(order: { id: string; userId: string; total: number }) {
await producer.send({
topic: "orders.placed",
messages: [
{
// Key drives partitioning. Same key → same partition → ordered delivery.
key: order.id,
value: JSON.stringify({
event: "OrderPlaced",
version: 1,
orderId: order.id,
userId: order.userId,
total: order.total,
occurredAt: new Date().toISOString(),
}),
headers: {
"x-correlation-id": getCurrentCorrelationId(),
"x-source-service": "orders-service",
},
},
],
// acks: -1 (all) is the default with idempotent: true. Don't override it.
});
}And here's the equivalent in RabbitMQ using amqplib:
import amqp from "amqplib";
const connection = await amqp.connect("amqp://rabbitmq:5672");
const channel = await connection.createConfirmChannel();
// Topic exchange - routing key acts like a path, supports wildcard bindings.
await channel.assertExchange("orders", "topic", { durable: true });
export async function publishOrderPlaced(order: { id: string; userId: string; total: number }) {
const payload = Buffer.from(
JSON.stringify({
event: "OrderPlaced",
version: 1,
orderId: order.id,
userId: order.userId,
total: order.total,
occurredAt: new Date().toISOString(),
})
);
// publish() returns immediately; the confirm channel resolves the promise
// only after the broker has accepted the message into a durable queue.
await new Promise<void>((resolve, reject) => {
channel.publish(
"orders",
"orders.placed", // routing key
payload,
{
persistent: true, // write to disk before acking
contentType: "application/json",
messageId: order.id, // helps with idempotency downstream
headers: { "x-correlation-id": getCurrentCorrelationId() },
},
(err) => (err ? reject(err) : resolve())
);
});
}Both of these look fine. They're also both wrong if you stop here.
The thing that's wrong is invisible: each of these functions publishes to the broker, but the broker is a separate system from your database. If the database write that produced this order succeeds and the broker write fails - network blip, broker restart, your pod gets killed mid-call - the order exists, no event is published, and downstream services have no idea anything happened. If the broker write succeeds and the database write fails - different blip, different timing - there's an OrderPlaced event with no corresponding order. Downstream consumers process a phantom order. The customer never sees it, but the warehouse gets a pick ticket for it.
This is the dual-write problem, and it's the reason the outbox pattern exists. We'll get there in a minute. First, the consumer side.
Consuming Events: Where The Hard Problems Hide
Producing is the easy half. The consumer side is where every event-driven system either grows up or dies.
A starter Kafka consumer:
import { Kafka } from "kafkajs";
const kafka = new Kafka({ clientId: "loyalty-service", brokers });
const consumer = kafka.consumer({
groupId: "loyalty-service-v1",
// Don't auto-commit - we commit only after the message is fully handled.
// Otherwise a crash mid-processing means the message is silently lost.
});
await consumer.connect();
await consumer.subscribe({ topic: "orders.placed", fromBeginning: false });
await consumer.run({
// partitionsConsumedConcurrently controls per-partition parallelism.
// Inside a partition, messages are still processed strictly in order.
partitionsConsumedConcurrently: 4,
eachMessage: async ({ topic, partition, message, heartbeat }) => {
const event = JSON.parse(message.value!.toString());
try {
await awardPointsForOrder(event);
// Commit happens automatically after eachMessage resolves without throwing.
// If it throws, the offset isn't committed and the message is redelivered.
} catch (err) {
// Send heartbeats during long retries so the group doesn't think we died.
await heartbeat();
throw err;
}
},
});And the RabbitMQ side:
import amqp from "amqplib";
const connection = await amqp.connect("amqp://rabbitmq:5672");
const channel = await connection.createChannel();
// Limit how many unacked messages this consumer holds at once.
// Without prefetch, RabbitMQ will hand you the entire queue and your pod OOMs.
await channel.prefetch(20);
await channel.assertExchange("orders", "topic", { durable: true });
await channel.assertQueue("loyalty.orders.placed", { durable: true });
await channel.bindQueue("loyalty.orders.placed", "orders", "orders.placed");
await channel.consume("loyalty.orders.placed", async (msg) => {
if (!msg) return;
const event = JSON.parse(msg.content.toString());
try {
await awardPointsForOrder(event);
channel.ack(msg);
} catch (err) {
// requeue: false sends the message to the queue's dead-letter exchange
// (if configured) instead of bouncing back to head-of-queue forever.
channel.nack(msg, false, false);
}
});Both samples gloss over the four problems that will break your consumer in production. Let's name them.
Duplicate delivery. Both Kafka and RabbitMQ deliver at-least-once by default. Exactly-once is either a marketing claim or a very narrow technical feature behind transactional APIs that very few real systems actually use. Your consumer will see the same event twice. Sometimes minutes apart, sometimes weeks later when a consumer group rebalances after an outage and replays from the last committed offset.
Your handler has to be idempotent. The two cleanest ways: derive a unique key per event (event.orderId + event.event works for the order example) and check whether you've already processed it in the same DB transaction that does the work, or design the work itself so it's idempotent (upserts, set-based assignments, "ensure this row exists" rather than "insert this row"). A processed_events(event_id PRIMARY KEY, processed_at) table that you write to inside the same transaction as the business operation is the most boring, most reliable pattern, and it's what most production systems land on eventually.
Out-of-order delivery across partitions/queues. Within a single Kafka partition or a single RabbitMQ queue with a single consumer, ordering holds. The minute you add parallelism, ordering is best-effort. If your business logic requires OrderPlaced to be processed before OrderShipped, partition by orderId (Kafka) or design idempotent handlers that don't care about order (both). Don't try to fix this with timestamps - clocks lie.
Poison messages. Sooner or later, somebody publishes a malformed event, or your handler hits a bug that throws on a specific payload shape. With at-least-once delivery and naive retry, that one message blocks the entire partition or queue, forever, in a hot loop. Build a dead-letter destination on day one - Kafka via a separate "DLQ" topic you publish to from your error handler, RabbitMQ via a dead-letter exchange on the queue declaration - and move messages there after N retries. Then alert on DLQ depth.
Lag. Consumers fall behind. A burst of traffic, a deploy that slows the handler, an upstream broker hiccup - and now your loyalty service is twelve hours behind. Every event-driven system needs lag metrics surfaced and alerted. For Kafka, the consumer lag per partition is a built-in metric. For RabbitMQ, queue depth and oldest message age are the equivalents. Without these, you'll find out about a backed-up queue when a customer support ticket asks why their points took two days to appear.
The Outbox Pattern, Or: How To Stop Lying To Your Downstream Services
Back to the dual-write problem. Your POST /orders handler needs to do two things atomically: write the order to the database, and publish an OrderPlaced event. The database is one system. The broker is another system. There is no distributed transaction across them that's both practical and performant. Two-phase commit exists but nobody runs it in production for a reason.
The outbox pattern solves this with a humble insight: if you can't write to two systems atomically, then write to only one. Write to your database - both the business row and a row representing the event you wish you could publish - in the same transaction. Then have a separate process read those event rows and publish them to the broker, marking each one as published after the broker accepts it.
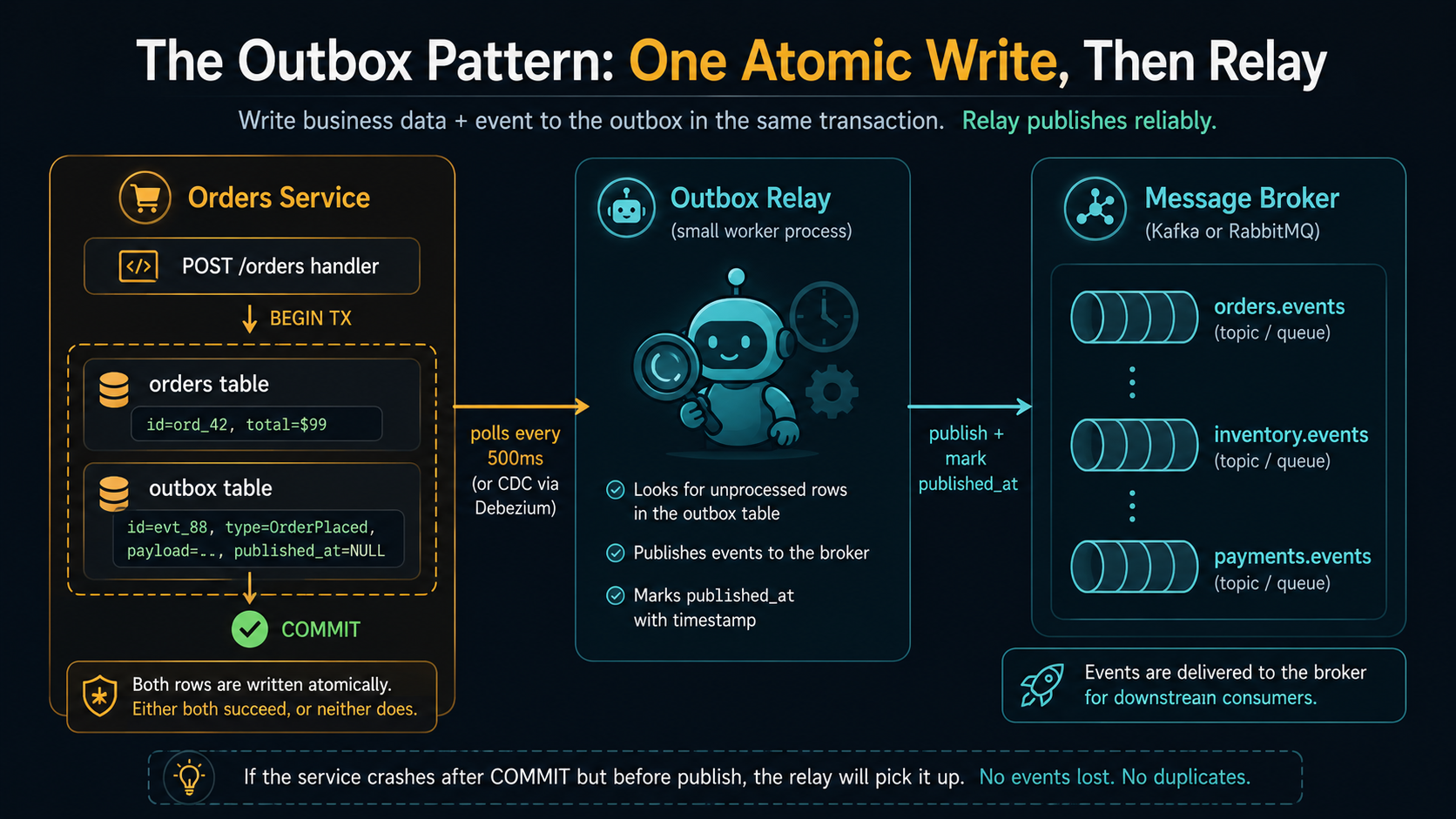
The flow looks like this:
import { db } from "./db";
import { randomUUID } from "node:crypto";
export async function placeOrder(input: PlaceOrderInput) {
return db.transaction(async (tx) => {
const orderId = randomUUID();
await tx.insert("orders").values({
id: orderId,
user_id: input.userId,
total: input.total,
status: "placed",
created_at: new Date(),
});
// The "event" never goes to a broker directly. It goes to a table.
await tx.insert("outbox").values({
id: randomUUID(),
aggregate_type: "order",
aggregate_id: orderId,
event_type: "OrderPlaced",
payload: {
orderId,
userId: input.userId,
total: input.total,
occurredAt: new Date().toISOString(),
},
created_at: new Date(),
published_at: null,
});
return { orderId };
// If anything throws, both inserts roll back. No phantom event, no missing event.
});
}Then a separate worker, often in the same Node process or a small companion service, polls the outbox table for unpublished rows, publishes them, and marks them as published:
import { db } from "./db";
import { publishToBroker } from "./publisher";
async function relayBatch() {
// SELECT ... FOR UPDATE SKIP LOCKED lets multiple relay instances run safely.
const batch = await db.query(
`SELECT id, aggregate_type, event_type, payload
FROM outbox
WHERE published_at IS NULL
ORDER BY created_at
LIMIT 100
FOR UPDATE SKIP LOCKED`
);
for (const row of batch) {
try {
await publishToBroker({
topic: `${row.aggregate_type}.${row.event_type.toLowerCase()}`,
key: row.payload.orderId,
value: row.payload,
});
await db.query(
`UPDATE outbox SET published_at = NOW() WHERE id = $1`,
[row.id]
);
} catch (err) {
// Leave the row unpublished. Next loop iteration retries it.
console.error("outbox publish failed", { id: row.id, err });
}
}
}
setInterval(() => relayBatch().catch(console.error), 500);Three things this gets you, for the price of one extra table:
It makes the system at-least-once correct end-to-end. Either the order exists and the event eventually goes out, or neither exists. There is no in-between state where downstream services hear about something that didn't happen, or don't hear about something that did.
It decouples your request latency from the broker's availability. If Kafka is having a bad day, your POST /orders still succeeds - it only depends on your database. The outbox fills up, the relay retries, and once the broker recovers, the backlog drains. Compare that to inline-publish, where a five-minute Kafka outage means five minutes of failed orders.
It gives you a natural audit trail and replay mechanism. The outbox table is a record of every event you've ever published, queryable in SQL, joinable to your business tables. If a downstream team asks "what events did you publish for order X?" the answer is one query away. If you ever need to re-publish a range of historical events to a new consumer that joined late, it's a worker that reads the outbox with a date filter.
The only real downside is the polling latency - your relay loop interval becomes the floor on how quickly events propagate. 500ms is fine for most order-flow use cases. If you need single-digit-millisecond propagation, you graduate to change data capture (CDC) - tools like Debezium that read your database's write-ahead log and stream changes directly to Kafka. CDC is the same pattern with the polling replaced by log-tailing. Same idea, more moving parts, much lower latency.
Async Workflows: Orchestration vs Choreography
Once you have events flowing reliably, the natural next question is: how do you compose a multi-step workflow out of them? Charge the card, then send the confirmation, then notify the warehouse, then schedule the loyalty calculation in ten minutes. There are two camps.
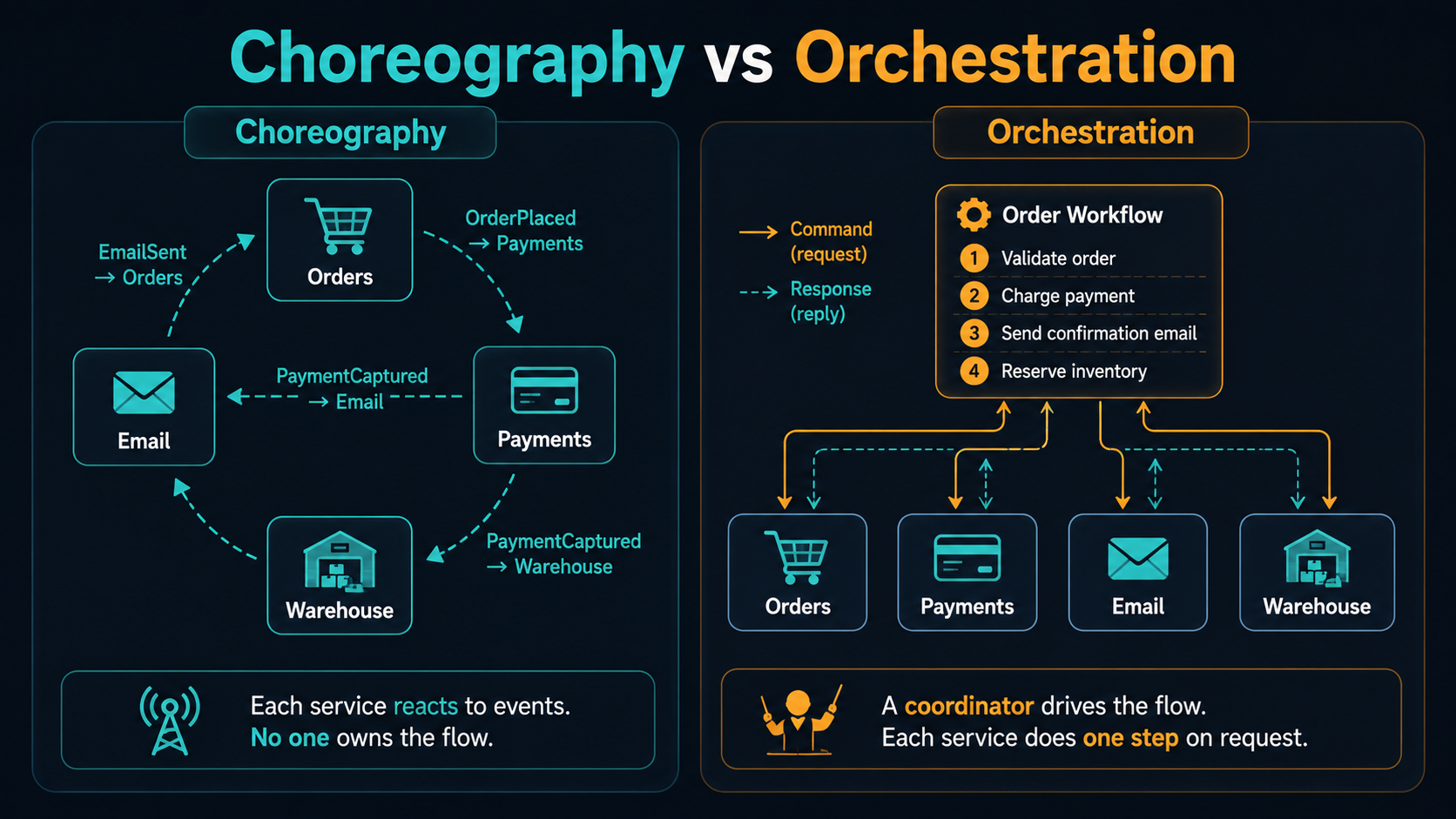
Choreography is the pure event-driven approach. Each service publishes events about what it did, and each service subscribes to the events it cares about. The orders service publishes OrderPlaced. The payments service subscribes to OrderPlaced, charges the card, publishes PaymentCaptured or PaymentFailed. The email service subscribes to PaymentCaptured and sends the confirmation. The warehouse service also subscribes to PaymentCaptured and queues a pick ticket. Nobody is in charge of the workflow. The workflow emerges from who subscribes to what.
This is elegant. It's also a nightmare to reason about once the workflow has more than three steps, because there is no single place where the flow is described. To answer "what happens after an order is placed?" you have to read the subscription configuration of every service.
Orchestration flips it. A dedicated workflow service (or a workflow framework - Temporal, AWS Step Functions, Camunda, or hand-rolled state machines in your own code) holds the flow. It calls payments and waits for the response. Then calls email and waits. Then calls warehouse. Each step is a command, not an event. The orchestrator owns retries, compensations, and the overall state of "is this order's workflow complete?"
This is much easier to reason about and debug - you can literally point at a workflow definition file and say "this is what happens." It's also tighter coupling: the orchestrator knows about every service it calls, which is the thing pure event-driven systems were trying to escape.
In practice, mature event-driven systems are hybrids. Inter-service notifications stay choreographed (loose coupling, easy to add subscribers), but anything that needs strong end-to-end consistency - like a multi-step order flow with compensations - runs through an orchestrator. The line tends to be: if you can describe the failure handling as "the next service will figure out what to do," choreography is fine. If you need to say "if step 3 fails, refund step 2 and cancel step 1," reach for an orchestrator.
A small example of a hand-rolled state machine for the order flow, kept deliberately simple:
type OrderState =
| { kind: "placed"; orderId: string }
| { kind: "payment_captured"; orderId: string; chargeId: string }
| { kind: "fulfilled"; orderId: string; trackingId: string }
| { kind: "failed"; orderId: string; reason: string };
async function advanceWorkflow(state: OrderState): Promise<OrderState> {
switch (state.kind) {
case "placed": {
const charge = await paymentsClient.charge(state.orderId);
if (!charge.ok) return { kind: "failed", orderId: state.orderId, reason: charge.error };
return { kind: "payment_captured", orderId: state.orderId, chargeId: charge.id };
}
case "payment_captured": {
const pick = await warehouseClient.schedulePick(state.orderId);
return { kind: "fulfilled", orderId: state.orderId, trackingId: pick.trackingId };
}
case "fulfilled":
case "failed":
return state;
}
}Persist the OrderState to a workflows table. A worker picks up unfinished workflows on a timer, calls advanceWorkflow, persists the result, and repeats until the state is terminal. Crashes mid-step are safe because the worker reads the last persisted state on restart. Real orchestration frameworks (Temporal especially) automate all of this and give you durable timers, signals, and human-task patterns on top, but a hand-rolled version covers the 80% case and is worth understanding before adopting a framework.
Schema, Versioning, And The Long Tail Of "Who Owns The Event"
One last thing that matters more than most people admit: events are an API. Once you publish OrderPlaced v1 and another team starts consuming it, you cannot change the shape of that event without breaking the consumer. Not "shouldn't" - cannot, in the sense that doing so will produce an outage.
A few patterns that help here:
Version every event in the payload itself: { event: "OrderPlaced", version: 1, ... }. When you need a v2, publish to orders.placed.v2 (or keep the same topic but include the version in the payload and let consumers handle both). Don't change v1's shape, ever.
Use a schema registry (Confluent Schema Registry, Apicurio, or even just a schemas/ folder in a shared repo) so producers and consumers agree on what fields exist and what they mean. JSON Schema or Protobuf are the common choices. Both work in Node - ajv for JSON Schema, protobufjs for Protobuf.
Decide on a backward-compatibility policy and write it down. The usual rule: producers can add fields freely, but cannot remove or rename fields without bumping the version. Consumers ignore unknown fields. This means new producer code can be deployed before consumer code is updated, which is what you want.
Document the meaning of each event in human language, not just schema. The schema tells you the shape; it doesn't tell you when the event is published, who publishes it, or what invariants hold at the moment of publication. That's the part that drifts and causes bugs three months later when a new consumer joins. A one-paragraph contract per event in a shared catalogue beats hundreds of lines of TypeScript types.
A Note On The Operational Reality
Event-driven systems are stronger than synchronous ones in most of the ways that matter - they handle partial failures gracefully, they scale individual components independently, and they let teams ship without coordinating deploys. They are also harder to debug, harder to test end-to-end, and have a steeper operational learning curve.
A request that used to be one stack trace in one log file is now three stack traces in three log files, plus a broker message you might or might not still have, possibly correlated by an x-correlation-id header if whoever set up the system remembered to propagate it. Build the correlation-id discipline from day one - every event carries it, every log line includes it, every consumer propagates it to anything it publishes downstream. Without that, debugging an async flow is archaeology.
And test the failure modes deliberately. Kill the broker mid-write and verify the outbox catches it. Kill a consumer mid-handle and verify the next consumer instance picks up cleanly. Publish a poison message and verify it ends up in the DLQ instead of looping forever. The default behaviour of every broker library is "happy path works." The interesting properties only show up under controlled chaos.
If there's one thing to take from all of this, it's that the broker is the easy part. The interesting work - the outbox, the idempotent handlers, the dead-letter handling, the schema discipline, the workflow modeling - happens in your application code. Choosing Kafka or RabbitMQ is a one-week decision. Building the surrounding patterns well is what determines whether your event-driven system saves your team a year from now or becomes the thing you're slowly rewriting back into a monolith.