
So, your monolith just split into seven services. Or you're the unlucky engineer who joined the team the week after it split. Either way, something has changed: those services now need to talk to each other, and HTTP calls are starting to feel like glue made of dry spaghetti. One service is down, three others fall over with it. A spike in checkout traffic backs up half the stack. The "synchronous" architecture diagram on the wall now reads more like a bus pileup diagram.
This is where event-driven systems show up. Instead of service A calling service B and waiting, service A drops a message on a broker, and service B picks it up when it's ready. The broker absorbs the spikes. Failures become local. Retries become trivial. The part of your code that used to be a brittle network call is now just another consumer reading messages.
Go is great at this. The standard library, the goroutine model, the obsession with explicit errors - all of it lines up nicely with how brokers actually behave. The hard part is picking which broker, and then writing the consumer the way that broker wants you to.
This post walks through the three you'll most likely meet on the job: Apache Kafka, NATS (with JetStream), and RabbitMQ. We'll cover what each one is good at, what producing and consuming actually look like in Go, how to handle retries without setting your inbox on fire, and how to pick the right one for a given job.
A note up front: none of these libraries are interchangeable, and there's no canonical "the Go client" the way there is for some brokers in Java. We'll use:
github.com/segmentio/kafka-gofor Kafka,github.com/nats-io/nats.gofor NATS,github.com/rabbitmq/amqp091-gofor RabbitMQ.
All three are popular, actively maintained, pure Go (or near enough), and don't need cgo.
The three brokers, side by side
Before any code, get the mental model right. The three brokers solve overlapping problems in very different ways, and the differences leak everywhere - into your producer code, into your retry strategy, into how you reason about ordering and durability.
Kafka is a distributed log. Messages are appended to partitions and live there for days, weeks, or forever depending on retention. Consumers read by offset and can replay from anywhere in the log. Ordering is per-partition. Consumers join consumer groups and Kafka itself handles assigning partitions across the group. Once you commit an offset, that's your bookmark.
NATS Core is a fire-and-forget pub/sub bus - tiny, blazing fast, no persistence. Subjects look like orders.created.user.42 and consumers subscribe with wildcards (orders.*, orders.>). If nobody's listening when you publish, the message is gone. NATS JetStream is the persistence layer added on top: streams hold messages, durable consumers track delivery, and you get acks, redelivery, and replay - all without leaving NATS.
RabbitMQ is an exchange-and-queue router. Producers publish to an exchange with a routing key. The exchange decides which queues the message lands in, based on bindings. Consumers read from queues. Messages are removed from the queue once acked. Ordering is per-queue and depends on prefetch.
Picture the shapes side by side:
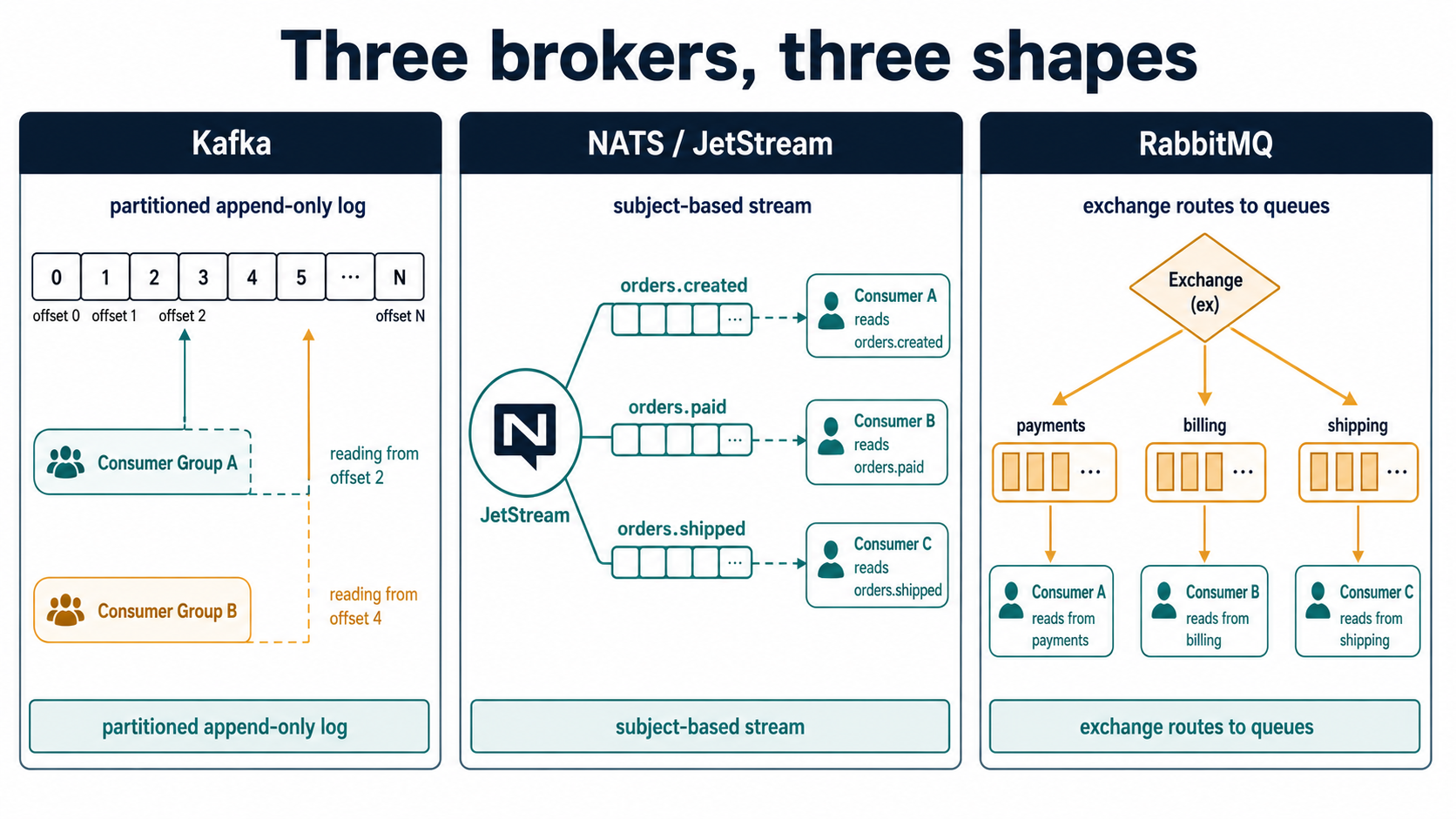
Different shapes, different superpowers:
| Property | Kafka | NATS (JetStream) | RabbitMQ |
|---|---|---|---|
| Mental model | Append-only log | Subject-based stream | Exchange + queues |
| Persistence | Always, with retention | Optional (Core: no, JetStream: yes) | Configurable per queue |
| Ordering | Per partition | Per stream | Per queue |
| Replay | First-class | First-class (JetStream) | Not really |
| Throughput | Huge | Huge | Solid |
| Routing | By partition key | By subject pattern | By exchange (direct/topic/fanout/headers) |
| Best for | Event sourcing, audit logs, analytics streams | Microservice fan-out, ephemeral signals, request/reply | Task queues, RPC over messaging, complex routing |
You don't always get to pick - the broker is often a platform decision made before you joined. But knowing why each one looks the way it does makes the API choices less surprising when you hit them.
Producing in Go
Producers are the easy half. Connect, publish, handle the error. The interesting stuff happens on the consumer side. But there are a few details in producing that bite you later if you skip them, so let's get them right.
Kafka
With kafka-go, a Writer is a long-lived, goroutine-safe handle. You create one per topic, or one shared writer and let the library route by topic from the message itself.
package main
import (
"context"
"log"
"time"
"github.com/segmentio/kafka-go"
)
func main() {
w := &kafka.Writer{
Addr: kafka.TCP("kafka:9092"),
Topic: "orders.created",
Balancer: &kafka.Hash{}, // partition by Key
RequiredAcks: kafka.RequireAll, // wait for all in-sync replicas
Async: false,
WriteTimeout: 10 * time.Second,
}
defer w.Close()
err := w.WriteMessages(context.Background(),
kafka.Message{
Key: []byte("user-42"), // same key -> same partition -> ordered
Value: []byte(`{"order_id":"ord_123","amount":4900}`),
Time: time.Now(),
},
)
if err != nil {
log.Fatalf("write: %v", err)
}
}Three knobs that matter:
Balancerdecides which partition each message lands in.&kafka.Hash{}hashes theKey, so all messages with the same key ("user-42") land in the same partition and stay ordered.&kafka.RoundRobin{}spreads load but loses per-key ordering. Pick by what you need: per-entity ordering, or maximum throughput.RequiredAckscontrols the durability tradeoff.RequireAllwaits for every in-sync replica to write. Slower, durable.RequireOnewaits for the leader only.RequireNoneis fire-and-forget. For anything you care about, useRequireAll.Async: falsekeeps the call synchronous. WithAsync: truethe writer batches in the background and returns immediately - fast, but a process kill mid-batch is bytes gone. Keep it false unless you can absorb that loss window.
NATS
NATS publishing is famously minimal:
package main
import (
"log"
"time"
"github.com/nats-io/nats.go"
)
func main() {
nc, err := nats.Connect("nats://localhost:4222",
nats.Name("orders-producer"),
nats.ReconnectWait(2*time.Second),
nats.MaxReconnects(-1),
)
if err != nil {
log.Fatal(err)
}
defer nc.Drain()
if err := nc.Publish("orders.created", []byte(`{"order_id":"ord_123"}`)); err != nil {
log.Fatal(err)
}
}That's Core NATS. The message goes out, anyone subscribed to orders.created or orders.* or orders.> at this exact moment gets it. Nobody listening? Message is gone. That's the contract.
For anything you want to persist, switch to JetStream:
js, err := nc.JetStream()
if err != nil {
log.Fatal(err)
}
// Idempotent: AddStream is safe to call every boot.
_, _ = js.AddStream(&nats.StreamConfig{
Name: "ORDERS",
Subjects: []string{"orders.>"},
Storage: nats.FileStorage,
Replicas: 3,
})
ack, err := js.Publish("orders.created", []byte(`{"order_id":"ord_123"}`))
if err != nil {
log.Fatal(err)
}
log.Printf("stored at stream %s seq %d", ack.Stream, ack.Sequence)js.Publish returns an ack with the stored sequence number. That's your bookmark, like a Kafka offset, except it's per-stream and managed by JetStream.
RabbitMQ
RabbitMQ publish needs a channel, an exchange, and a routing key. The amqp091-go API is verbose but transparent:
package main
import (
"context"
"log"
"time"
amqp "github.com/rabbitmq/amqp091-go"
)
func main() {
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
log.Fatal(err)
}
defer conn.Close()
ch, err := conn.Channel()
if err != nil {
log.Fatal(err)
}
defer ch.Close()
// Topic exchange routes by routing-key pattern. Idempotent declare.
err = ch.ExchangeDeclare(
"orders", // name
"topic", // type
true, // durable
false, // auto-delete
false, // internal
false, // no-wait
nil, // args
)
if err != nil {
log.Fatal(err)
}
err = ch.PublishWithContext(context.Background(),
"orders", // exchange
"orders.created", // routing key
true, // mandatory: error if no queue is bound
false, // immediate (deprecated)
amqp.Publishing{
ContentType: "application/json",
DeliveryMode: amqp.Persistent, // survive broker restart
Body: []byte(`{"order_id":"ord_123"}`),
MessageId: "ord_123", // for idempotency on the consumer side
Timestamp: time.Now(),
},
)
if err != nil {
log.Fatal(err)
}
}Two pieces matter most here:
DeliveryMode: amqp.Persistentis the difference between "this message exists" and "this message exists if no node restarts." Without it, the broker won't fsync to disk.- Publisher confirms. The snippet above does not wait for broker confirmation. For production, enable confirms with
ch.Confirm(false)and read fromch.NotifyPublish(...)to know which messages actually landed. Assuming publishes always succeed is one of the most common ways to lose data in a RabbitMQ pipeline.
Consuming: where the brokers diverge
Producing is mostly the same shape across brokers. Consuming is where they really show their personalities, and where most production bugs live.
Kafka: offsets and consumer groups
A Kafka consumer is fundamentally a reader of partitions. You join a consumer group, the broker assigns you some partitions, you read messages, you commit offsets when you're done with them. That's the whole loop.
package main
import (
"context"
"log"
"github.com/segmentio/kafka-go"
)
func main() {
r := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{"kafka:9092"},
Topic: "orders.created",
GroupID: "billing-service", // joining a group => Kafka manages partition assignment
MinBytes: 1,
MaxBytes: 10e6,
CommitInterval: 0, // manual commits
StartOffset: kafka.FirstOffset, // only used the first time a new group connects
})
defer r.Close()
ctx := context.Background()
for {
msg, err := r.FetchMessage(ctx)
if err != nil {
log.Printf("fetch: %v", err)
continue
}
if err := handleOrder(ctx, msg.Value); err != nil {
log.Printf("handler failed for offset %d: %v", msg.Offset, err)
// Don't commit. The message will be redelivered after rebalance or restart.
continue
}
if err := r.CommitMessages(ctx, msg); err != nil {
log.Printf("commit: %v", err)
}
}
}Pay close attention to the FetchMessage / CommitMessages split. ReadMessage exists too, but it auto-commits as soon as it returns the message, before your handler runs. That's the classic at-most-once footgun: your handler crashes, the offset is already committed, the message is lost forever. FetchMessage lets you commit after processing, which is the at-least-once guarantee you almost always want.
Two consequences flow from this:
- At-least-once means duplicates exist. A crash between handling and committing means the next consumer instance gets the same message again. Your handler must be idempotent. We'll come back to this.
- Slow handlers stall the partition. Kafka delivers messages in order within a partition. If you spend 30 seconds on each one, you've capped that partition at two messages per minute. Either parallelise per-partition with care (you'll need to track offsets manually) or add partitions and scale consumers horizontally.
NATS JetStream: pull consumers and acks
JetStream's durable pull consumer is the canonical pattern for backend services. The consumer is a server-side resource that tracks where you are in the stream and which messages you've acked.
js, _ := nc.JetStream()
// Idempotent consumer creation. AckExplicit means we ack each message ourselves.
_, _ = js.AddConsumer("ORDERS", &nats.ConsumerConfig{
Durable: "billing",
AckPolicy: nats.AckExplicitPolicy,
AckWait: 30 * time.Second,
MaxDeliver: 5,
FilterSubject: "orders.created",
})
sub, err := js.PullSubscribe("orders.created", "billing", nats.BindStream("ORDERS"))
if err != nil {
log.Fatal(err)
}
for {
msgs, err := sub.Fetch(10, nats.MaxWait(5*time.Second))
if err != nil {
if err == nats.ErrTimeout {
continue
}
log.Printf("fetch: %v", err)
continue
}
for _, m := range msgs {
if err := handleOrder(context.Background(), m.Data); err != nil {
// NakWithDelay schedules redelivery with backoff. Better than a blind Nak.
_ = m.NakWithDelay(backoffFor(m))
continue
}
_ = m.Ack()
}
}Three things to notice:
AckWaitis your dead-man switch. If you don't ack within that window, JetStream redelivers, assuming you crashed. If your handler legitimately takes longer thanAckWaitsometimes, callm.InProgress()periodically to extend the lease.MaxDeliver: 5caps the redelivery count. After five tries, JetStream stops trying. Without this cap, a poison message will loop forever and eat your consumer pool.NakWithDelayis the difference between a sane retry policy and a tight CPU-burning loop. We'll dig into the backoff math in the next section.
RabbitMQ: deliveries and ack/nack
RabbitMQ is the chattiest of the three to consume from. You declare a queue, bind it to an exchange, set prefetch, then range over a channel of deliveries.
ch, _ := conn.Channel()
// Prefetch: how many unacked messages this consumer can hold. Critical for fairness.
_ = ch.Qos(10, 0, false)
q, err := ch.QueueDeclare("billing.orders.created", true, false, false, false, nil)
if err != nil {
log.Fatal(err)
}
_ = ch.QueueBind(q.Name, "orders.created", "orders", false, nil)
deliveries, err := ch.Consume(
q.Name,
"billing-consumer",
false, // auto-ack OFF - we ack ourselves
false, // exclusive
false, // no-local
false, // no-wait
nil,
)
if err != nil {
log.Fatal(err)
}
for d := range deliveries {
if err := handleOrder(context.Background(), d.Body); err != nil {
// requeue:true would put it back at the queue head and immediately retry.
// For a real failure that's a busy loop - use requeue:false plus a DLX (see below).
_ = d.Nack(false, false)
continue
}
_ = d.Ack(false)
}The two settings that actually matter:
Qos(prefetch, 0, false)is the most important one-liner in the whole snippet. Without it, RabbitMQ may push hundreds of messages into one consumer's buffer while others sit idle. A low prefetch (5to50) gives RabbitMQ a chance to balance work across consumers.- Auto-ack must be false for any handler you care about. Auto-ack means RabbitMQ removes the message the moment it's delivered, before your code touches it. Same at-most-once trap as Kafka's auto-commit.
Retries: the part nobody gets right on the first try
Retries are where every event-driven system either becomes elegant or descends into a screaming feedback loop. The hard rules are simple. Their implementation in each broker is not.
The hard rules:
- Don't retry forever. Cap attempts. A poison message will eat your consumer pool.
- Don't retry without backoff. A failing handler retried every 10ms will hammer whatever's broken (your DB, your downstream API, your own logs).
- Don't retry on the original topic, subject, or queue. A failing message at the front of the queue blocks every healthy message behind it. That's head-of-line blocking, and it's how a single bad event takes down a whole service.
- Eventually move to a dead-letter destination. Five failures in a row isn't transient - that's broken, and you need a human (or a separate worker) to look at it.
Here's how each broker offers retries natively.
Retries in Kafka
Kafka has no built-in retry semantics. The community pattern is a tiered retry topic chain:
orders.created
-> orders.created.retry.5s
-> orders.created.retry.30s
-> orders.created.retry.5m
-> orders.created.dlqEach retry topic has a consumer that waits until the message is old enough (using its timestamp), then republishes to the next stage. Your main consumer, on failure, publishes to the first retry topic instead of the original.
A minimal version:
type retryStage struct {
Topic string
Delay time.Duration
}
var chain = []retryStage{
{"orders.created.retry.5s", 5 * time.Second},
{"orders.created.retry.30s", 30 * time.Second},
{"orders.created.retry.5m", 5 * time.Minute},
}
func sendToRetry(ctx context.Context, w *kafka.Writer, msg kafka.Message, attempt int) error {
if attempt >= len(chain) {
// Out of retries -> DLQ.
return w.WriteMessages(ctx, kafka.Message{
Topic: "orders.created.dlq",
Key: msg.Key,
Value: msg.Value,
Headers: append(msg.Headers, kafka.Header{
Key: "x-attempts", Value: []byte(strconv.Itoa(attempt)),
}),
})
}
next := chain[attempt]
return w.WriteMessages(ctx, kafka.Message{
Topic: next.Topic,
Key: msg.Key,
Value: msg.Value,
Headers: append(msg.Headers,
kafka.Header{Key: "x-attempts", Value: []byte(strconv.Itoa(attempt + 1))},
kafka.Header{Key: "x-retry-after", Value: []byte(time.Now().Add(next.Delay).UTC().Format(time.RFC3339))},
),
})
}The retry consumer for each tier waits until x-retry-after passes, then forwards the message back to orders.created (or to the next tier on another failure). It's a lot of plumbing for what NATS and RabbitMQ give you in one config line. The upside: you get explicit topics you can inspect, replay, and reason about in your monitoring.
Retries in NATS JetStream
JetStream gives you redelivery as a consumer property. Set MaxDeliver and AckWait, and NakWithDelay failed messages with a backoff. That's the whole pattern.
func backoffFor(m *nats.Msg) time.Duration {
meta, _ := m.Metadata()
n := meta.NumDelivered
base := 5 * time.Second
// 5s, 25s, 2m5s, 10m25s ... exponential with a cap.
d := base * time.Duration(math.Pow(5, float64(n-1)))
if d > 30*time.Minute {
d = 30 * time.Minute
}
return d
}
for _, m := range msgs {
err := handleOrder(ctx, m.Data)
if err == nil {
_ = m.Ack()
continue
}
meta, _ := m.Metadata()
if meta.NumDelivered >= 5 {
// Out of retries. Publish to DLQ stream and ack the original to remove it.
_, _ = js.Publish("orders.created.dlq", m.Data)
_ = m.Ack()
continue
}
_ = m.NakWithDelay(backoffFor(m))
}NumDelivered is the redelivery counter JetStream tracks in the message metadata. You compute the next backoff from real state, not from a header you have to maintain yourself.
Retries in RabbitMQ
RabbitMQ's pattern is dead-letter exchanges (DLX) combined with TTL queues. The trick is that a message that expires from a queue can be routed elsewhere, and that "elsewhere" can be the next retry tier.
The shape:
queue: billing.orders (consumed by the worker)
on nack(requeue=false) -> exchange: orders.dlx
exchange: orders.dlx (fanout or direct)
routes to queue: billing.orders.retry.30s
(TTL = 30s, dead-letters back to "orders" exchange)
routes to queue: billing.orders.dlq
(terminal, manual inspection)In Go:
// Main queue: nacks go to the DLX.
mainArgs := amqp.Table{
"x-dead-letter-exchange": "orders.dlx",
}
_, _ = ch.QueueDeclare("billing.orders", true, false, false, false, mainArgs)
// Retry queue: holds messages for 30s, then routes back to the main exchange.
retryArgs := amqp.Table{
"x-message-ttl": int64(30000), // 30s
"x-dead-letter-exchange": "orders", // back to main exchange
"x-dead-letter-routing-key": "orders.created",
}
_, _ = ch.QueueDeclare("billing.orders.retry.30s", true, false, false, false, retryArgs)Your handler, on failure, increments an x-attempts header and republishes to a specific retry queue (or nacks with a routing key chosen by current attempt count). Tedious to wire up the first time, but once it's in place you never have to write retry-loop code in your service again - the broker does it.
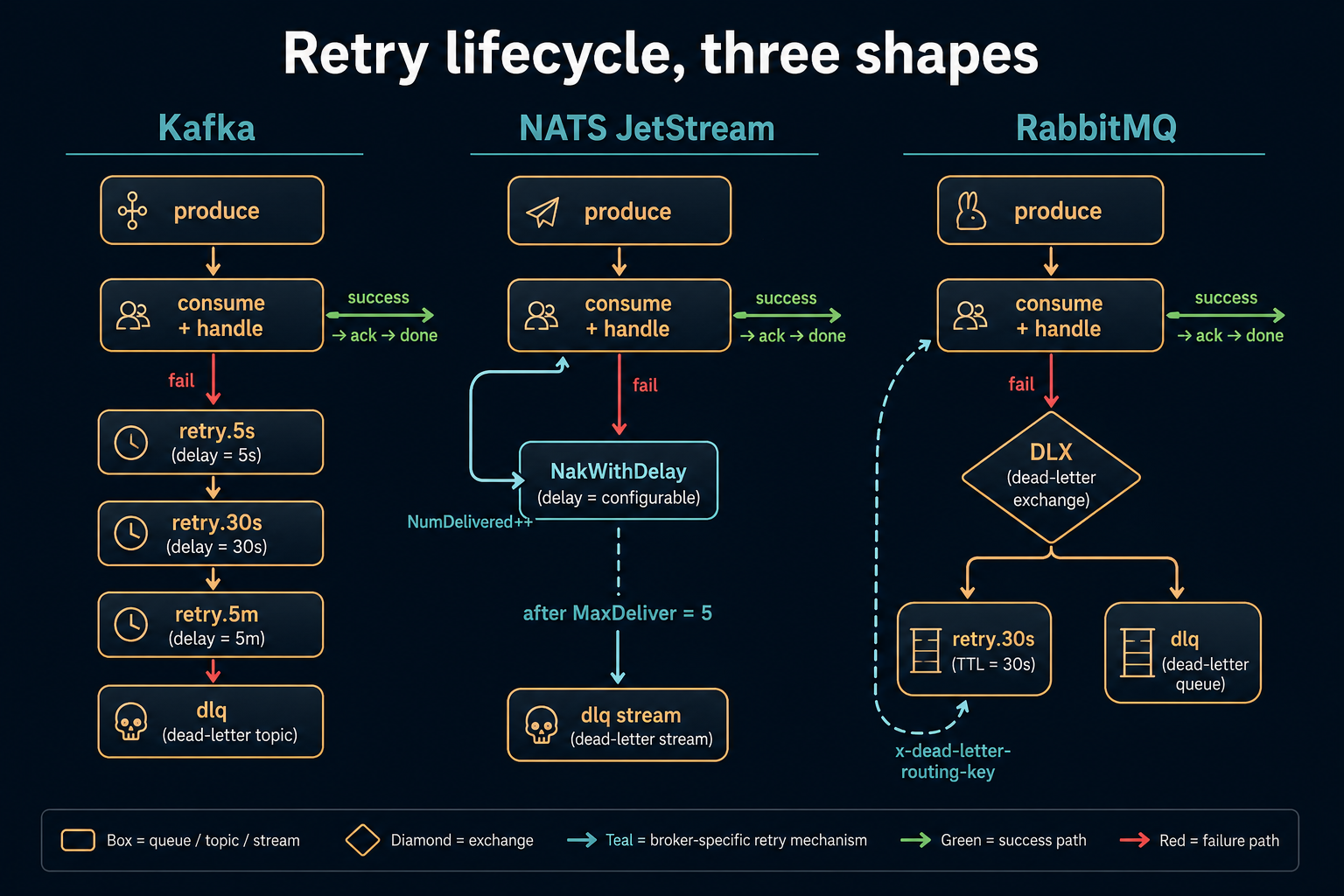
Idempotency, or: why retries don't have to be scary
The reason a long discussion about retries doesn't end with "but what if we double-bill the customer" is that consumer code should already be idempotent. Every event-driven system worth shipping treats duplicate delivery as a question of when, not if.
There are two practical patterns.
Pattern 1: Dedup by message ID. Producer assigns a unique ID (UUID, business key, or a hash of payload plus timestamp). Consumer keeps a table or cache of "seen" IDs. Before processing, check if seen; if yes, skip. After processing, record. The check and the write should be in the same transaction as the business work, if you can swing it.
func handleOrder(ctx context.Context, db *sql.DB, msgID string, body []byte) error {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return err
}
defer tx.Rollback()
// PRIMARY KEY on inbox.msg_id -> duplicate inserts are a no-op for us.
res, err := tx.ExecContext(ctx,
"INSERT INTO inbox (msg_id, processed_at) VALUES ($1, now()) ON CONFLICT DO NOTHING",
msgID,
)
if err != nil {
return err
}
n, _ := res.RowsAffected()
if n == 0 {
// We've seen this message before. Skip the business work, still commit + ack.
return tx.Commit()
}
if err := doBusinessWork(ctx, tx, body); err != nil {
return err
}
return tx.Commit()
}Pattern 2: Make the business work itself idempotent. "Set order state to PAID for order X" is idempotent - running it twice produces the same result. "Charge the user 49 dollars" is not - running it twice doubles the charge. When you can, design the work so the second execution is a no-op. When you can't, fall back to pattern 1.
The producer side gets a similar treatment. If your service emits "order created" and the publish errors, you'd retry, but you'd retry with the same message ID so consumers can dedup. This is the outbox pattern: write the event to an outbox table in the same DB transaction as the business change, then a separate worker publishes to the broker. The broker is eventually consistent with the DB, but you never get a publish without the underlying change, and never the change without an eventual publish.
Choosing a broker for a given job
This is the part where you'd love a flow chart and reality refuses to give you one. The honest answer is that all three brokers can do most of what most teams need, and the choice is usually decided by what your platform team already runs, what your team already knows, and what the surrounding ecosystem expects.
That said, the natural fit for each:
Pick Kafka when:
- You need replay - tomorrow's analytics job will reprocess yesterday's events.
- You're building event sourcing or change-data-capture (CDC with Debezium, for instance).
- Throughput is in the hundreds of thousands to millions of messages per second.
- Downstream consumers want to subscribe to a stream (continuous, ordered log) rather than a queue.
Pick NATS (JetStream) when:
- You want a single broker that does ephemeral pub/sub and durable streaming.
- Latency matters in microseconds, not milliseconds.
- You're connecting microservices that fan out via subject patterns (
orders.*,payments.>.eu). - You want a smaller operational footprint than Kafka: a single Go binary, no ZooKeeper, no JVM.
Pick RabbitMQ when:
- You need rich routing - topic exchanges, header exchanges, fanout, direct.
- You're doing classic background-job queues (
tasks.image_resize,tasks.email_send). - Per-message routing decisions matter more than throughput.
- You want RPC over messaging with reply-to queues, or priority queues.
You'll notice none of these are "best." They're "good fit." A backend job queue can live happily on Kafka with a partition count tuned for parallelism. A high-volume event stream can live on RabbitMQ if you set up the right exchanges. NATS can simulate either with enough thought. The friction shows up at the edges - replay, routing flexibility, operational cost - not in the happy path.
A few habits worth stealing
Three things that aren't broker-specific but make all of them less painful in production:
- Make your consumers crash-safe. Long handlers should be cancellable through
context.Context, and your consumer loop should check for shutdown signals between messages, not in the middle of one. A clean shutdown means finish the current message, ack it, then exit. Half-processed messages will be redelivered, and your idempotency layer will catch them - but a clean exit is still cheaper than a redelivery storm on every deploy. - Treat headers as the message envelope.
x-attempts,x-correlation-id,x-trace-id,x-origin-service- put them on every message you publish, regardless of broker. Future-you, debugging an incident at 3am, will thank present-you. Kafka, NATS, and RabbitMQ all support custom headers; use them. - Don't share a connection blindly across goroutines.
kafka.Writerand*nats.Connare safe to share. RabbitMQ's*amqp.Channelis not - one channel per publisher goroutine, or pool them. Read the docs for whatever client you're using; you don't want to discover this concurrency rule with a production deadlock.
Five years from now, the names of the brokers will probably look a little different. There'll be a new contender that bills itself as "Kafka but actually simple," a NATS fork, a RabbitMQ release that finally settles its streams story. What won't change is the shape of the problem: a producer drops a message, a consumer picks it up, sometimes it fails, sometimes it duplicates, and your job is to keep the system honest through all of that. Get the shape right and the broker is mostly an implementation detail.





