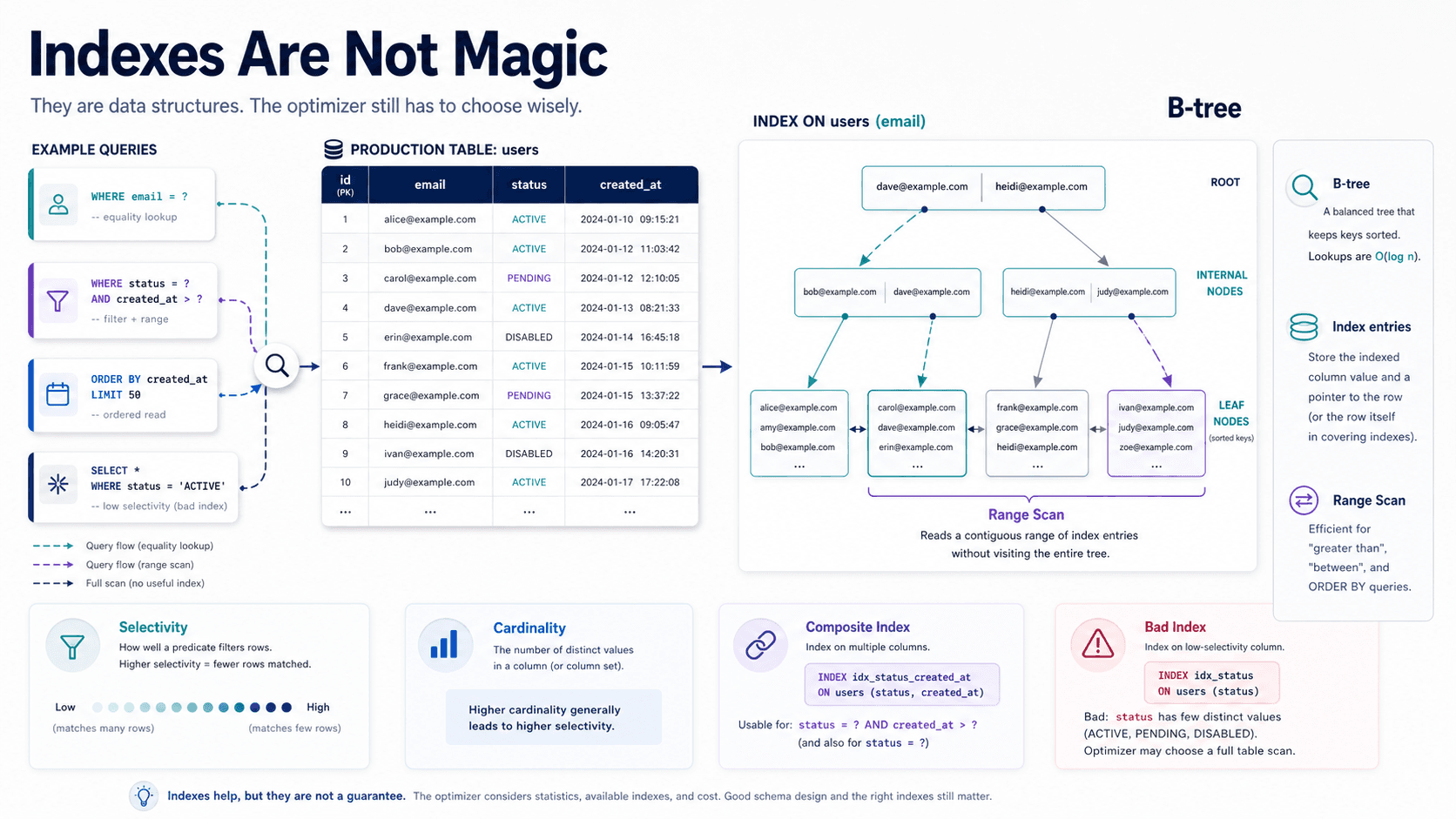
There's a category of system you build maybe twice in your career where event sourcing is the only honest answer. Ledgers. Order books. Audit-heavy domains where "what does the row say right now" is a much weaker question than "show me every change that led to this state, in order, with the actor and the reason."
For everything else - most CRUD, most dashboards, most internal tools - event sourcing is overkill. It's a powerful pattern with a non-trivial operational tax, and the tax shows up in places juniors won't see until production is full.
This piece is about both halves of that. What event sourcing actually buys you, what a small one looks like in Node, why projections feel like magic the first time they click, and what nobody mentions until you're three months in.
State Is A Lie We Tell The Database
The default way you store data in a Node service is a table of current state. users has a row per user with the current email. When the user changes their email, you UPDATE the row. The previous email is gone unless you remembered to write to an audit table.
Event sourcing flips the relationship. The source of truth is not the row - it's the sequence of changes that produced the row. You don't store the current email; you store UserRegistered, EmailChanged, EmailChanged again, and the current email is whatever the last EmailChanged says. State becomes a function of the event stream:
type Event =
| { type: 'UserRegistered'; userId: string; email: string; at: string }
| { type: 'EmailChanged'; userId: string; email: string; at: string };
function reduceUser(events: Event[]) {
let user: { id: string; email: string } | null = null;
for (const e of events) {
if (e.type === 'UserRegistered') user = { id: e.userId, email: e.email };
if (e.type === 'EmailChanged' && user) user.email = e.email;
}
return user;
}That reduceUser is the whole idea. State is the fold over the event log. The events are immutable facts; the current state is just a cached computation.
If you've used Redux or useReducer, this should feel familiar. The reducer is the same shape - (state, event) => state - except the events live in durable storage instead of memory, and they outlive the process.
Why Anyone Bothers
The shift from "store state" to "store changes" sounds academic until you see what falls out of it.
You get a perfect audit log for free. Not "we added an updated_at column" - every change, with every input, in order. Compliance teams love this. Investigators love this. Anyone who has ever had to answer "what did this account look like on November 3rd at 2pm" loves this.
You can rebuild any read model from scratch by replaying the log. New report? Just write a reducer over the existing events. Bug in your old projection? Throw the projection away, replay, get the corrected one. You can ship a feature that needs a historical view of data the original schema never captured, because the events have everything.
You get time travel. The state at any past moment is reduce(events.filter(e => e.at <= someTime)). For domains that ask "what was this on day X" - accounting, billing, regulatory - this is not a nice-to-have.
And debugging changes. When something is wrong, you don't reason backwards from a corrupted current row. You open the event log, scroll to where it went sideways, and the broken event is right there with the inputs that produced it.
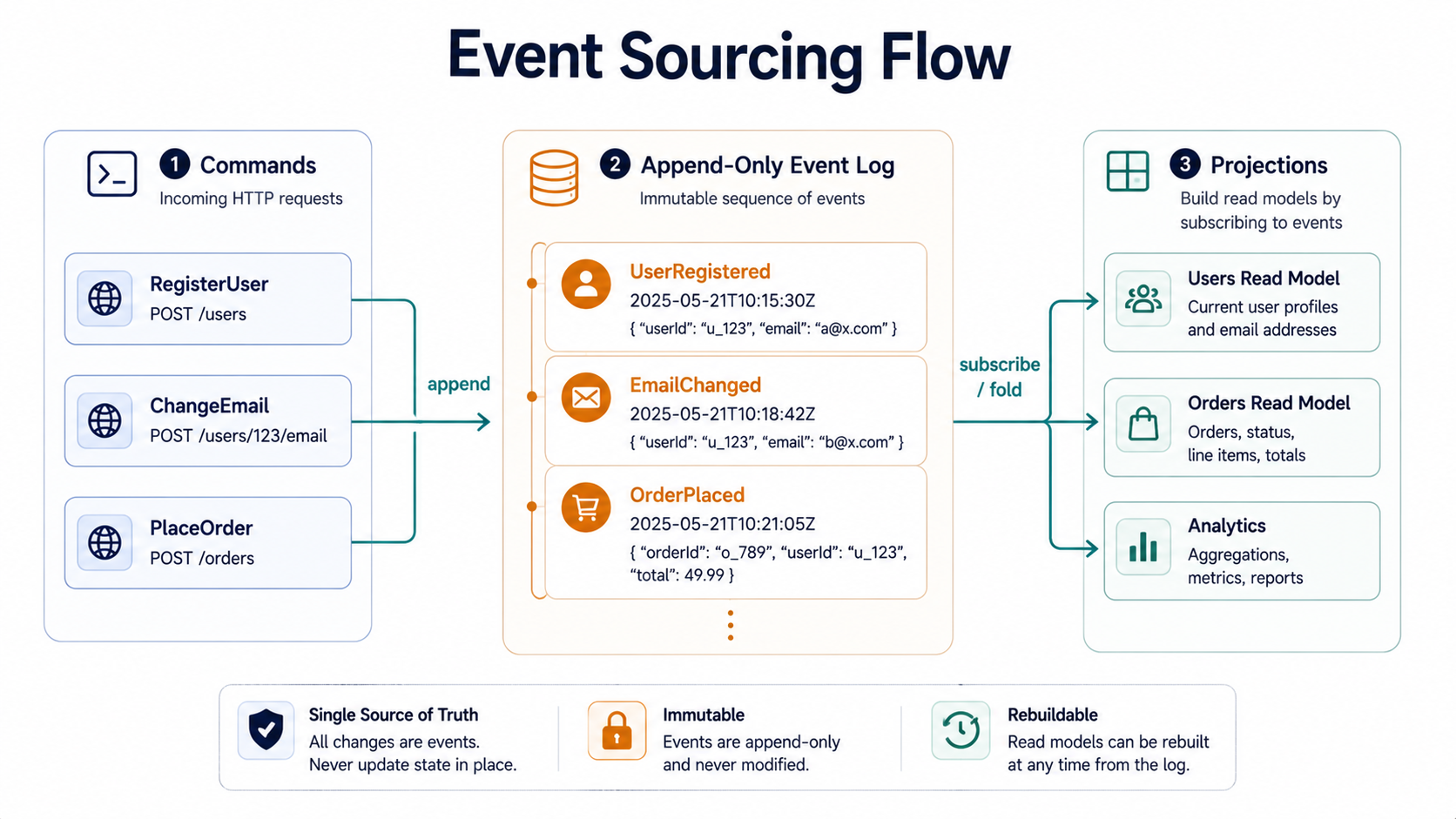
A Small Event Store In Node
The smallest possible event store is a table with three columns: a stream id, a version number, and the event payload. Postgres handles this beautifully because it gives you serializable transactions and jsonb for the payload.
CREATE TABLE events (
stream_id text NOT NULL,
version int NOT NULL,
type text NOT NULL,
data jsonb NOT NULL,
metadata jsonb NOT NULL,
recorded_at timestamptz NOT NULL DEFAULT now(),
PRIMARY KEY (stream_id, version)
);
CREATE INDEX events_by_recorded_at ON events (recorded_at);The primary key on (stream_id, version) is doing more work than it looks like. It guarantees that two writers can't both insert version 5 of the same stream - the database refuses. That's your optimistic concurrency control without writing a single line of locking code.
The Node side is a thin wrapper:
import { Pool } from 'pg';
type StoredEvent = {
streamId: string;
version: number;
type: string;
data: unknown;
metadata: { actor?: string; correlationId?: string };
};
export class EventStore {
constructor(private db: Pool) {}
async append(
streamId: string,
expectedVersion: number,
events: Array<{ type: string; data: unknown; metadata: StoredEvent['metadata'] }>,
) {
const client = await this.db.connect();
try {
await client.query('BEGIN');
let v = expectedVersion;
for (const e of events) {
v += 1;
await client.query(
`INSERT INTO events (stream_id, version, type, data, metadata)
VALUES ($1, $2, $3, $4, $5)`,
[streamId, v, e.type, e.data, e.metadata],
);
}
await client.query('COMMIT');
return v;
} catch (err) {
await client.query('ROLLBACK');
throw err;
} finally {
client.release();
}
}
async readStream(streamId: string): Promise<StoredEvent[]> {
const { rows } = await this.db.query(
`SELECT stream_id AS "streamId", version, type, data, metadata
FROM events WHERE stream_id = $1 ORDER BY version ASC`,
[streamId],
);
return rows;
}
}The expectedVersion parameter is how a writer says "I last saw this stream at version 4, so I expect my first new event to be version 5." If someone else slipped a write in between, the unique-key violation surfaces as an error and the caller retries by re-reading the stream and re-deciding what to do. This is the same pattern as HTTP If-Match headers, just at the storage layer.
That's the entire write path. Everything else - projections, snapshots, replay - is built on top of these two methods.
Commands, Events, And The Aggregate In The Middle
In an event-sourced system you don't UPDATE; you send a command, the domain code decides what events that command produces, and you append those events.
type OrderState = {
id: string;
version: number;
status: 'open' | 'placed' | 'cancelled';
items: Array<{ sku: string; qty: number }>;
};
type OrderEvent =
| { type: 'OrderOpened'; id: string }
| { type: 'ItemAdded'; sku: string; qty: number }
| { type: 'OrderPlaced'; placedAt: string }
| { type: 'OrderCancelled'; reason: string };
function reduceOrder(events: OrderEvent[]): OrderState {
const state: OrderState = { id: '', version: 0, status: 'open', items: [] };
for (const e of events) {
state.version += 1;
switch (e.type) {
case 'OrderOpened': state.id = e.id; break;
case 'ItemAdded': state.items.push({ sku: e.sku, qty: e.qty }); break;
case 'OrderPlaced': state.status = 'placed'; break;
case 'OrderCancelled': state.status = 'cancelled'; break;
}
}
return state;
}
function decideAddItem(state: OrderState, sku: string, qty: number): OrderEvent[] {
if (state.status !== 'open') {
throw new Error(`cannot add items to a ${state.status} order`);
}
if (qty <= 0) throw new Error('qty must be positive');
return [{ type: 'ItemAdded', sku, qty }];
}A command handler ties them together: read the stream, reduce it to current state, call decide*, append the resulting events with the expected version.
import { EventStore } from '../eventStore.js';
import { reduceOrder, decideAddItem } from '../order.js';
export async function addItem(
store: EventStore,
orderId: string,
sku: string,
qty: number,
actor: string,
) {
const events = await store.readStream(`order-${orderId}`);
const state = reduceOrder(events as any);
const newEvents = decideAddItem(state, sku, qty);
await store.append(
`order-${orderId}`,
state.version,
newEvents.map((e) => ({ type: e.type, data: e, metadata: { actor } })),
);
}You'll notice nothing here updates a row. The addItem call doesn't mutate anything except by appending events. The next time someone calls readStream, the new event is part of the fold.
This is the bit that takes a few hours to internalise. There is no "edit the order" code path. There is only "append an event that, when folded in, changes how the order looks."
Projections Are Where The Magic Lives
Reading a stream and folding to state works fine for a single aggregate. But your API endpoints need things like "list all open orders for customer X." Reducing every stream on every request is a non-starter.
That's where projections come in. A projection is a background reader that subscribes to the event log, watches new events flow by, and updates a regular read table you can SELECT from like any other database.
import { Pool } from 'pg';
export async function projectOpenOrders(db: Pool, event: any) {
switch (event.type) {
case 'OrderOpened':
await db.query(
`INSERT INTO open_orders (order_id, customer_id, opened_at)
VALUES ($1, $2, $3) ON CONFLICT DO NOTHING`,
[event.data.id, event.data.customerId, event.data.at],
);
break;
case 'OrderPlaced':
case 'OrderCancelled':
await db.query(`DELETE FROM open_orders WHERE order_id = $1`, [event.data.id]);
break;
}
}You hook it up to a poll loop or Postgres LISTEN/NOTIFY and let it run. The open_orders table is now a denormalised read model - your API queries it directly, no folding required.
Want a different view? Write another projection. Want to slice the same events by region? Write a third. Each projection is just code that turns events into rows it cares about. You can have ten projections fed by the same log, each shaped exactly for the queries it serves.
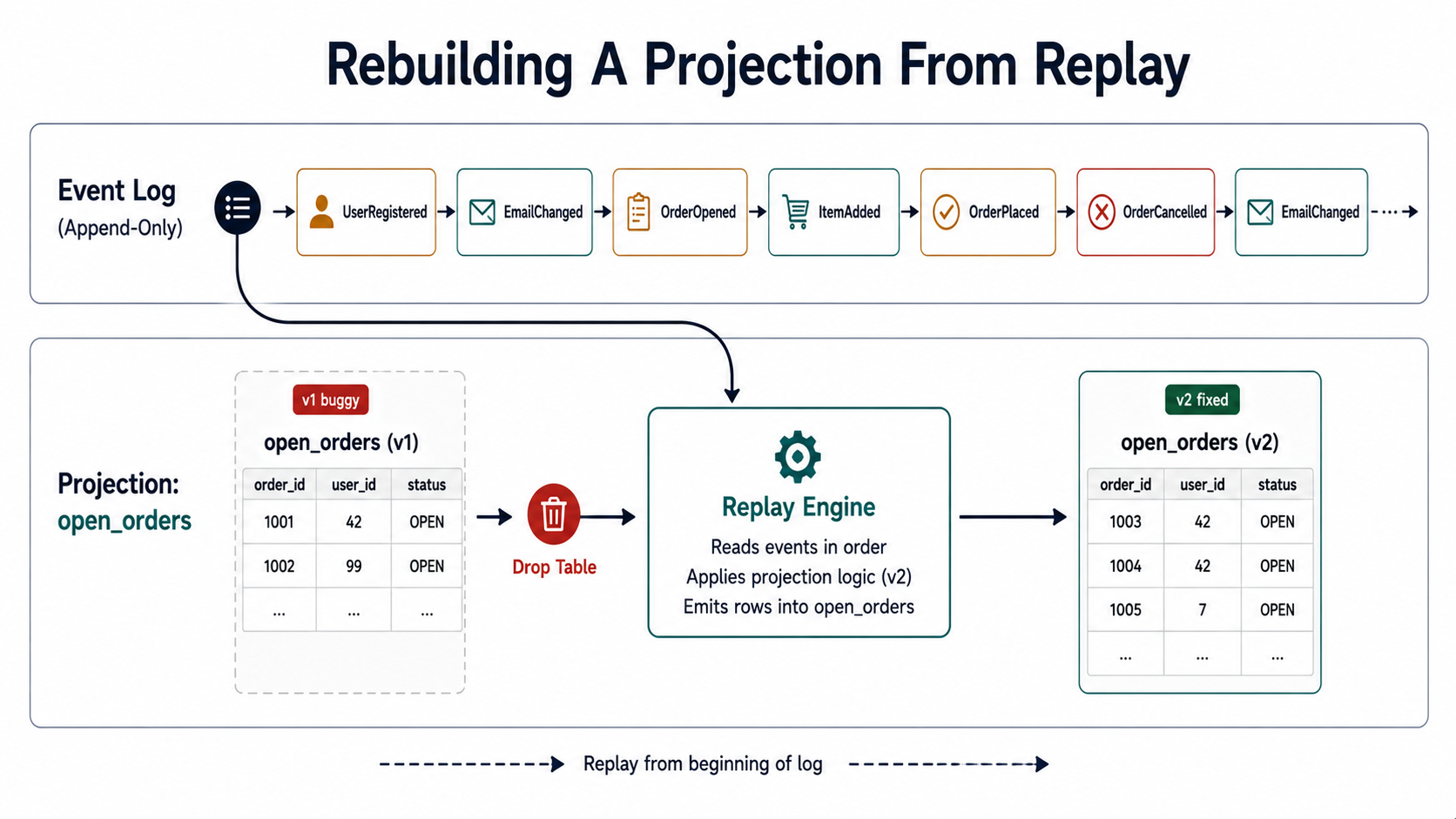
The mindset shift is that the read model is derived and disposable. You can drop the table, replay from event 1, and you're back. That makes the read schema something you can iterate on without migrations in the traditional sense - there's no data to migrate, just code to re-run.
Replay Is The Superpower
This is the part that sells the pattern.
Say you've been running an ecommerce service for two years. PM asks for a new report: "average time between ItemAdded and OrderPlaced per customer segment." In a state-store world, you don't have that data - you've been overwriting it for two years. You can start collecting it from today, and the answer ships in a quarter.
In an event-sourced world, you write a projection, point it at the start of the log, and let it chew through two years of events. By the time you've grabbed coffee it's caught up. The report ships this afternoon.
import { Pool } from 'pg';
export async function replayAll(db: Pool, handle: (event: any) => Promise<void>) {
const cursor = 'cur_replay';
await db.query('BEGIN');
await db.query(
`DECLARE ${cursor} CURSOR FOR
SELECT type, data, metadata, recorded_at
FROM events ORDER BY recorded_at ASC`,
);
for (;;) {
const { rows } = await db.query(`FETCH 1000 FROM ${cursor}`);
if (rows.length === 0) break;
for (const event of rows) await handle(event);
}
await db.query(`CLOSE ${cursor}`);
await db.query('COMMIT');
}Replay is also how you fix a buggy projection. Find the bug, drop the projection's table, run replay against the fixed projection function, and the read model is rebuilt correctly. No data migration, no backfill scripts, no "we'll fix it for new orders going forward."
Snapshots, Because Reducing 50,000 Events Per Request Is Slow
The naive command handler reduces the entire stream every time. For short-lived aggregates that's fine. For long-lived ones - a user account, a long-running order book - the stream grows without bound and the fold gets slow.
Snapshots are the fix. A snapshot is a saved copy of the reduced state at a specific version. When a command arrives, you load the latest snapshot, then fold only the events after it.
CREATE TABLE snapshots (
stream_id text NOT NULL,
version int NOT NULL,
state jsonb NOT NULL,
PRIMARY KEY (stream_id)
);async function loadState(store: EventStore, db: Pool, streamId: string) {
const { rows } = await db.query(
`SELECT version, state FROM snapshots WHERE stream_id = $1`,
[streamId],
);
const snapshot = rows[0];
const tail = (await store.readStream(streamId))
.filter((e) => e.version > (snapshot?.version ?? 0));
return reduceFrom(snapshot?.state, tail);
}In production you'd push that version filter into the SQL instead of slicing in Node - the point of the snippet is the shape, not the I/O profile.
Snapshots are optimisation, not truth. The events are still the source of truth. If a snapshot is corrupted or the reducer changes, drop the snapshot and rebuild from events. Don't ever let yourself reach for a snapshot when the underlying events disagree - that's a path to data that can't be reconciled.
A reasonable rule: snapshot every 100 events for hot streams, every 1000 for cold ones, never for short-lived ones.
What Nobody Tells You Before You Start
Here's the operational tax. Plan for it before you commit.
Events are forever. Once OrderPlacedV1 is in the log, you can't change its shape. You can write OrderPlacedV2 and teach the reducer to handle both, but V1 events from 2024 still exist, still need to be readable, still need to fold correctly. Schema evolution is a discipline. Treat events like a public API.
Eventual consistency is now your problem. After you append events, your read model lags by some amount - usually milliseconds, sometimes seconds under load. The user clicks "add item," gets 200 OK, and the page refresh shows the old basket because the projection hasn't caught up. You have to design around this - return optimistic UI state, read your own writes from the command side, or accept a tiny lag in the UX.
Idempotency matters everywhere. Projections will be re-run. Network blips will make subscribers re-deliver. Replays happen. Every projection handler should be safe to call twice with the same event - usually via ON CONFLICT DO NOTHING or a processed_events table that tracks the last applied position.
Debugging is different. When something looks wrong in the read model, you don't reach for the projection's table - you go to the event log first. Did the event get appended? With the right data? Then check whether the projection handler saw it, whether it ran without erroring, whether its position advanced. The mental model is "events are truth, projections are caches that might be stale or buggy."
Tooling matters. Pretty event-log viewers, replay tooling, projection health dashboards - you'll build these or you'll suffer. Specialised event-store databases like EventStoreDB ship a lot of this out of the box. Rolling your own on Postgres is fine and what most teams do, but you'll be writing operator UIs sooner than you think.
When To Actually Reach For This
Event sourcing is a tool with a sharp edge. The teams it works for share a few things. The domain has a strong notion of "what happened, in order, who did it" - finance, healthcare, logistics, anything regulated. The product needs to answer historical questions or recompute views from past data. The team is comfortable with eventual consistency and willing to invest in tooling.
Teams it punishes share a different pattern. The domain is CRUD with a few notifications bolted on. The product team doesn't ask historical questions. The engineering team doesn't have time to build replay tools and projection dashboards. In that world, event sourcing is a complexity tax you pay daily for a benefit you collect almost never.
The honest framing is: a Postgres table with a good audit log will carry most apps further than you think. Reach for event sourcing when the audit log itself becomes the product - when "what was the state on March 3rd" is a real, repeated, business-critical question. For everything else, append (actor, action, before, after, at) to an audit_events table and call it a day.
When event sourcing fits, though, it really fits. The day you ship a projection that retroactively answers a question from two years of data, in an afternoon, you'll understand why people put up with the rest.