
So, you wrote your first goroutine. It returned in microseconds, the test passed, and for a moment the whole problem of concurrency felt like a solved one. Then you scaled up. Suddenly a goroutine isn't a tool, it's a leak. A chan int isn't a queue, it's a deadlock waiting for the right input. And the phrase "go is good at concurrency" starts to sound less like a feature and more like a dare.
The truth is that Go gives you sharp building blocks, not finished patterns. go, channels, select, sync.WaitGroup, and context are all primitives. The patterns you actually ship (the ones that survive a production weekend) are made out of those primitives in specific shapes, and there are only a handful of shapes that matter.
This piece is a tour of the three that show up in basically every Go codebase I've ever read: worker pools, fan-out/fan-in, and rate limiting. Each one solves a different problem. Each one has a couple of traps that look fine until they don't. And once you can see all three clearly, you can combine them to handle most of what production throws at you.
We're staying in Go the whole way, because this is a Go-specific topic. Code uses the standard library plus golang.org/x/sync/errgroup and golang.org/x/time/rate, both of which are de-facto standard for serious work.
The three patterns at a glance
Before any code, the picture, because half the battle is knowing which pattern your problem actually wants.
Worker pool Fan-out / Fan-in Rate limiting
=========== ================ =============
many jobs one job any number of jobs
identical workers splits into N subtasks but the WORLD says
consume from queue run in parallel "slow down please"
one in, one out collect all results spaced by a clockA worker pool is for "many independent jobs, finite parallelism." You have 10,000 emails to send and you want exactly 50 senders running at once. The job stream is the input. The pool sizes itself, not the job count.
Fan-out/fan-in is for "one job that's actually N parallel sub-jobs." You have a single request that needs to call six microservices, or a file that needs to be processed in chunks. You split, you wait, you stitch the results back together. The job count is fixed (and small) per call; the parallelism is opportunistic.
Rate limiting is the orthogonal one. It says nothing about how many workers you have or how the job splits. It says: regardless of the rest of your topology, this resource only gets touched at most N times per second. You bolt it onto the other patterns when a downstream service forces you to.
If you can name which one of these your problem is, half of the design is already done. If you can't, you're probably about to build a private fourth pattern that breaks the moment you scale.
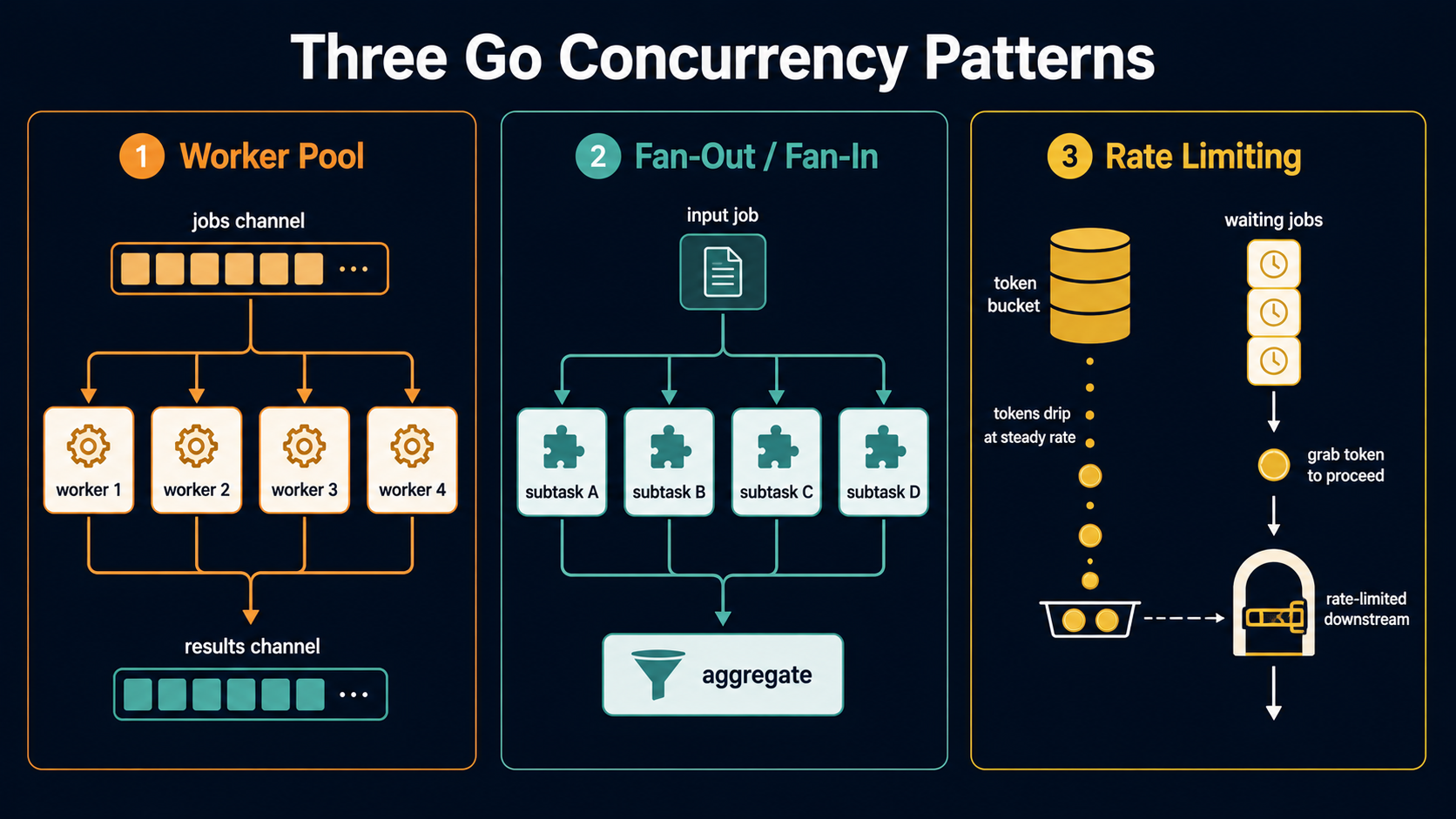
The rest of the article walks each pattern in detail, then shows what happens when you have to use all three together (because in real systems, you almost always do).
Worker pools
A worker pool is the answer to "I have a stream of work and I want a fixed amount of it running at once."
The canonical Go version is small enough to fit in a tweet, and that's part of why it's so easy to get wrong. The simple version looks like this:
package main
import (
"context"
"log/slog"
"sync"
)
type Job struct {
ID int
Payload string
}
type Result struct {
JobID int
Out string
Err error
}
func runPool(
ctx context.Context,
workers int,
jobs <-chan Job,
results chan<- Result,
handle func(context.Context, Job) (string, error),
) {
var wg sync.WaitGroup
for i := 0; i < workers; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for {
select {
case <-ctx.Done():
return
case j, ok := <-jobs:
if !ok {
return
}
out, err := handle(ctx, j)
select {
case results <- Result{JobID: j.ID, Out: out, Err: err}:
case <-ctx.Done():
return
}
}
}
}(i)
}
wg.Wait()
close(results)
slog.Info("pool drained")
}That's 30 lines and it gets a few non-obvious things right. Let's walk them, because each one is a separate trap if you skip it.
The outer select watches both ctx.Done() and jobs. If a worker is sitting idle and the context cancels, it exits without waiting for the next job to arrive first. That's the cooperative-cancellation contract Go expects. If you only range jobs instead, the worker will sit there until somebody closes jobs, which on shutdown might be never.
The inner select watches both ctx.Done() and results <- .... That looks paranoid, but it isn't. If your consumer of results has already stopped reading (panicked, timed out, returned), results <- will block forever and your worker will hang holding a half-finished job. Pairing every send with a <-ctx.Done() is the single thing that makes a worker pool actually cancellable.
close(results) happens once, after every worker has returned. That's the deal range results consumers count on: the channel closes exactly when no more values will ever be sent. If you close results early, consumers stop too soon. If you forget to close it, consumers block forever.
Sizing the pool
The question everyone asks is "how many workers?" and the honest answer is "measure." The useful answer is "depends on what the workers do":
CPU-bound work like image resizing, hashing, or compression should start at runtime.NumCPU(). You can't run more useful CPU work than you have cores; extra workers just thrash the scheduler.
IO-bound work like HTTP calls, database queries, or file IO can run wildly higher: 50, 500, sometimes thousands. The workers spend most of their time blocked on the network, so each one only consumes a few KB of stack and one open socket.
Mixed work is the annoying case. If a job is 90% IO and 10% CPU, you probably want a high worker count. If it's 50/50, you may want two pools: one big IO pool that hands off the CPU-heavy step to a small CPU pool. Pretending one number fits both is how you build a service that's somehow both starved and overloaded at the same time.
There's a separate ceiling you don't think about until it bites: the limits of whatever your workers talk to. A pool of 500 workers hammering a database with max_connections=100 is a denial-of-service tool with extra steps. Always know what the downstream limit is and stay comfortably under it.
Errgroup, when you want a structured pool
The hand-rolled version above is fine, but for the common case where you also want first-error-cancels-everything semantics, golang.org/x/sync/errgroup is what you reach for:
package main
import (
"context"
"log/slog"
"golang.org/x/sync/errgroup"
)
func runWithErrgroup(ctx context.Context, jobs []Job, workers int,
handle func(context.Context, Job) error,
) error {
g, ctx := errgroup.WithContext(ctx)
g.SetLimit(workers) // added in golang.org/x/sync v0.1.0 (requires Go 1.18+)
for _, j := range jobs {
j := j // capture loop var (not needed on Go 1.22+, but harmless)
g.Go(func() error {
if err := handle(ctx, j); err != nil {
slog.Error("job failed", "job_id", j.ID, "err", err)
return err
}
return nil
})
}
return g.Wait()
}SetLimit is the magic. It turns errgroup into a bounded pool: at most workers calls to g.Go run concurrently, the rest block in g.Go until a slot frees up. You get parallelism, error propagation, and context cancellation in 15 lines.
The trade-off versus the hand-rolled version is that errgroup doesn't fit "long-lived consumer that pulls from a channel forever." It fits "I have N jobs right now, run them with bounded parallelism, give me the first error." Pick by lifecycle: streaming inputs want the channel version, batch inputs want errgroup.
The two big mistakes
Mistake one is unbounded goroutines instead of a pool. The code reads for j := range jobs { go handle(j) }. There's no wg, no limit, no backpressure. With 10,000 jobs you get 10,000 goroutines hitting whatever handle calls. Cheap goroutines are not free resources downstream.
Mistake two is the busy-worker deadlock. A pool sends results into a channel; the consumer is supposed to read them; the consumer is itself blocked waiting for the pool to finish before reading. Nothing ever moves. The fix is either to buffer the results channel large enough to hold all in-flight work, or to read results concurrently with submission. Pick one and be deliberate about it.
Fan-out and fan-in
If a worker pool answers "many independent jobs, finite workers," fan-out/fan-in answers "one job that wants to be N parallel sub-jobs."
The classic example: a search handler that has to query six different indexes (products, articles, users, tags, suggestions, related searches), each of which takes 50-150ms. Run them serially and you've got a request that takes 600ms. Run them in parallel and the request takes as long as the slowest one, about 150ms.
The shape is: one producer, N workers that each do one piece, one aggregator that collects and combines. Sometimes "aggregator" just means "wait for them all." Sometimes it means "merge their channel outputs into a single channel." Both flavors come up.
The collect-all variant
The simplest version: launch one goroutine per sub-task, wait for all of them, collect results into a struct.
package main
import (
"context"
"golang.org/x/sync/errgroup"
)
type SearchResult struct {
Products []Product
Articles []Article
Users []User
Tags []Tag
Suggestions []string
Related []string
}
func Search(ctx context.Context, q string) (*SearchResult, error) {
var res SearchResult
g, ctx := errgroup.WithContext(ctx)
g.Go(func() error {
v, err := queryProducts(ctx, q)
res.Products = v
return err
})
g.Go(func() error {
v, err := queryArticles(ctx, q)
res.Articles = v
return err
})
g.Go(func() error {
v, err := queryUsers(ctx, q)
res.Users = v
return err
})
g.Go(func() error {
v, err := queryTags(ctx, q)
res.Tags = v
return err
})
g.Go(func() error {
v, err := querySuggestions(ctx, q)
res.Suggestions = v
return err
})
g.Go(func() error {
v, err := queryRelated(ctx, q)
res.Related = v
return err
})
if err := g.Wait(); err != nil {
return nil, err
}
return &res, nil
}This is fan-out/fan-in at its calmest. Each goroutine writes to its own field, so there's no shared write to synchronize. errgroup.WithContext gives you a derived context that cancels when the first error happens, meaning if queryProducts returns an error, queryArticles and the rest see ctx.Done() and can short-circuit instead of running to completion for results you're going to throw away.
The non-obvious thing is the field-per-goroutine pattern. People reach for a chan SearchResult here, or a map[string]any guarded by a sync.Mutex. Both work, but neither is necessary: as long as each goroutine writes to a different field of the same struct, there's no race. The compiler's memory model handles disjoint field writes just fine.
If you want a guarantee in the test suite, run with -race:
go test -race ./...The race detector will catch the case where two goroutines write to the same slice or map, which is the actual hazard.
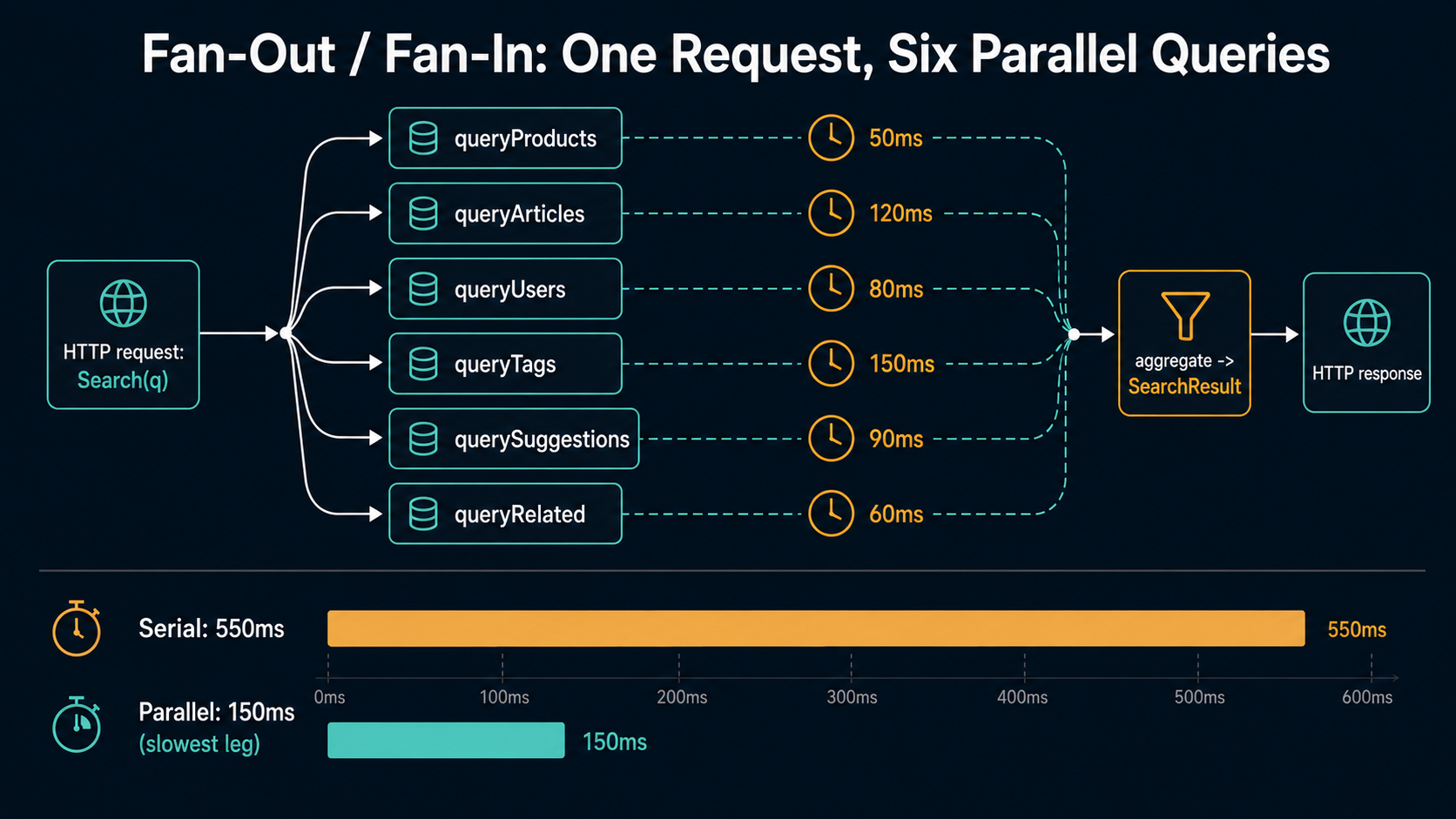
The channel-merging variant
The other flavor is when each sub-task produces a stream of values, not a single one, and you want them merged into a single channel for the consumer.
This is the pattern Rob Pike's classic 2012 "Go Concurrency Patterns" talk used. It still holds up. Imagine three producers (say, three readers tailing three log files) each emitting lines. You want a single output channel with all of their lines interleaved.
package main
import "sync"
// Merge fans in N input channels into one output channel.
// The output closes when every input has closed.
func Merge[T any](inputs ...<-chan T) <-chan T {
out := make(chan T)
var wg sync.WaitGroup
forward := func(c <-chan T) {
defer wg.Done()
for v := range c {
out <- v
}
}
wg.Add(len(inputs))
for _, c := range inputs {
go forward(c)
}
go func() {
wg.Wait()
close(out)
}()
return out
}Generics (T any) make this dead-simple to write once and reuse, but the pattern predates them; you can find pre-1.18 versions that use empty interfaces or repeat the function once per type.
The piece worth pausing on is the closer goroutine. Merge returns immediately, the merge runs in the background, and the output channel closes when (and only when) every input channel has closed. The consumer does a normal for v := range out and gets to see "all inputs are done" as the natural close of out. No "is this the last value?" check needed.
One real-world wrinkle: this pattern doesn't propagate cancellation, because there's no ctx. In a long-running pipeline you'd add one:
func MergeCtx[T any](ctx context.Context, inputs ...<-chan T) <-chan T {
out := make(chan T)
var wg sync.WaitGroup
forward := func(c <-chan T) {
defer wg.Done()
for {
select {
case <-ctx.Done():
return
case v, ok := <-c:
if !ok {
return
}
select {
case out <- v:
case <-ctx.Done():
return
}
}
}
}
wg.Add(len(inputs))
for _, c := range inputs {
go forward(c)
}
go func() {
wg.Wait()
close(out)
}()
return out
}Every channel operation is paired with <-ctx.Done(). Now your pipeline shuts down cleanly when the context cancels, regardless of which stage is currently blocked on which channel.
When fan-out is the wrong tool
Fan-out only helps if the sub-tasks are independent. If task B needs the output of task A, you can't parallelize them; you've just added scheduling overhead. The depressing version of this is when you fan out three calls, two of which run to completion, and the third was actually a prerequisite for the other two, meaning you've done the work in the wrong order and the parallel version is no faster than serial.
The other failure mode is fanning out too wide. Six parallel HTTP calls to your own services is great. Six hundred parallel HTTP calls to a payment provider's API will get you rate-limited or banned. The number of parallel legs has to respect the slowest downstream's capacity, which leads us directly to the third pattern.
Rate limiting
The first two patterns describe how you run work. Rate limiting describes how the world tells you to slow down.
Almost every external API has rate limits. Internal services often have them too (and if they don't, they should). The shape of the rule is usually "no more than N requests per second, with a burst of up to B requests allowed." That's a token bucket, and it's the model the standard golang.org/x/time/rate package implements.
A token bucket is exactly what it sounds like: a bucket holds up to B tokens. Tokens drip in at a steady rate of N per second. A request can only proceed if it can take a token. If the bucket is empty, the request waits until enough tokens have dripped in. Bursts up to B can fire immediately; after that, you're paced by the drip rate.
The basic rate limiter
package main
import (
"context"
"fmt"
"time"
"golang.org/x/time/rate"
)
func main() {
// 10 requests per second, burst of 20
lim := rate.NewLimiter(rate.Limit(10), 20)
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
for i := 0; i < 100; i++ {
if err := lim.Wait(ctx); err != nil {
fmt.Println("aborted:", err)
return
}
go func(i int) {
fmt.Println("request", i, "at", time.Now().Format("15:04:05.000"))
}(i)
}
}Wait blocks until a token is available or the context is canceled. That's the polite version. The first 20 requests fire essentially instantly (the burst), and then the remaining 80 are paced at 10 per second.
rate.Limit(10) says "10 events per second." For tighter precision, use rate.Every(100 * time.Millisecond), which says "one event every 100ms." Same thing, but the second form is sometimes clearer if you're thinking in periods rather than rates.
If you don't want to wait, and instead want to know immediately whether you have a token and drop the request if you don't, use Allow():
if !lim.Allow() {
return errors.New("rate limited")
}Allow() is non-blocking and returns immediately. It's the right shape for "shed load early." It's the wrong shape for "queue up and run when ready." If you mix them you'll get strange behavior; pick one per call site.
The leaky bucket vs token bucket distinction
You'll sometimes see "leaky bucket" thrown around as if it's the same thing as a token bucket. It isn't, quite.
A token bucket caps the rate of starts with a burst allowance. You can start 20 things right now if the bucket is full, then you're throttled.
A leaky bucket caps the rate of completions with no burst. Requests come in, get queued, and leak out at the configured rate. There's no burst, and every request waits its turn.
For most "we're calling someone else's API" use cases, a token bucket is what you want, which is why golang.org/x/time/rate ships with it. Leaky-bucket semantics tend to show up when you're shaping outbound traffic at the network level rather than at the application level.
Per-host rate limiting
A single global limiter is rarely the right shape. You're usually calling several different downstream services, each with its own rate limit. A map[string]*rate.Limiter keyed by host is the typical answer:
package main
import (
"context"
"net/http"
"net/url"
"sync"
"time"
"golang.org/x/time/rate"
)
type LimitedClient struct {
inner *http.Client
perHost map[string]*rate.Limiter
defaults rate.Limit
burst int
mu sync.Mutex
}
func NewLimitedClient(defaults rate.Limit, burst int) *LimitedClient {
return &LimitedClient{
inner: &http.Client{Timeout: 10 * time.Second},
perHost: make(map[string]*rate.Limiter),
defaults: defaults,
burst: burst,
}
}
func (c *LimitedClient) limiterFor(host string) *rate.Limiter {
c.mu.Lock()
defer c.mu.Unlock()
if l, ok := c.perHost[host]; ok {
return l
}
l := rate.NewLimiter(c.defaults, c.burst)
c.perHost[host] = l
return l
}
func (c *LimitedClient) Do(ctx context.Context, req *http.Request) (*http.Response, error) {
u, err := url.Parse(req.URL.String())
if err != nil {
return nil, err
}
if err := c.limiterFor(u.Host).Wait(ctx); err != nil {
return nil, err
}
return c.inner.Do(req.WithContext(ctx))
}Now payments.example.com gets its own bucket, inventory.example.com gets its own, and a noisy code path in one of them can't starve the others.
If you need different limits per host (because, say, your payment provider allows 5 rps and your image CDN allows 500), make the defaults map look-up driven rather than a single value. A map[string]struct{ rate rate.Limit; burst int } keyed by host gets you there.
Server-side: when you're the one being called
Rate limiting on the server side has a different shape. You're not calling someone else with constraints: you're protecting your own service from being called too aggressively. The decision point is "do I serve this request or 429 it?"
A per-IP or per-API-key limiter middleware is the standard pattern:
package main
import (
"net/http"
"sync"
"golang.org/x/time/rate"
)
type IPRateLimiter struct {
limiters map[string]*rate.Limiter
mu sync.Mutex
r rate.Limit
b int
}
func NewIPRateLimiter(r rate.Limit, b int) *IPRateLimiter {
return &IPRateLimiter{
limiters: make(map[string]*rate.Limiter),
r: r,
b: b,
}
}
func (l *IPRateLimiter) get(ip string) *rate.Limiter {
l.mu.Lock()
defer l.mu.Unlock()
if lim, ok := l.limiters[ip]; ok {
return lim
}
lim := rate.NewLimiter(l.r, l.b)
l.limiters[ip] = lim
return lim
}
func (l *IPRateLimiter) Middleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ip := clientIP(r) // your real implementation
if !l.get(ip).Allow() {
w.Header().Set("Retry-After", "1")
http.Error(w, "rate limited", http.StatusTooManyRequests)
return
}
next.ServeHTTP(w, r)
})
}There's an unbounded-map issue lurking here: every new IP creates a new entry, and they're never garbage collected. For a public-facing service that's a slow memory leak. The fix is either an LRU cache for limiters (so old IPs eventually fall off), or a background ticker that prunes entries that haven't been touched in N minutes. For an internal service where the IP set is bounded and known, the simple map is fine.
The other thing to know: in-process rate limiting only works for single-instance services. Once you scale to N replicas, a per-IP limit configured at "10 rps" is actually "10 rps per replica," which means the real limit is "10N rps." If you need a hard limit across replicas, you're looking at a Redis-backed limiter (INCR with a EXPIRE window, or a Lua script for the more precise sliding-window approach). Plenty of libraries wrap that.
Backoff and rate limiting are not the same thing
A trap I've seen more than once: somebody adds exponential backoff to a piece of code that's hitting a rate-limited API, sees errors go down, and concludes "we've handled the rate limit." They haven't.
Backoff is what you do after a request fails. Rate limiting is what stops requests from being sent in the first place. They're complementary, not substitutes. A correctly-rate-limited client never gets a 429 Too Many Requests in the normal case. A correctly-backed-off client recovers gracefully when the abnormal case happens (a transient outage, a sudden tightening of the upstream's limit). Build both, in that order.
Combining the patterns
In real systems, you almost never use one of these patterns alone. The common combination is "a worker pool, each worker fans out to several services, and the whole thing is rate-limited per downstream."
Picture a notification worker. The job: send a multi-channel notification (email + SMS + push) for a given user. The system has:
- Thousands of notification jobs queued up at any time (worker pool, say 50 workers).
- Each job sends to three channels in parallel (fan-out).
- Each channel has its own provider with its own rate limit (per-host rate limiter).
The whole thing falls out naturally once each pattern is in its right place:
package main
import (
"context"
"log/slog"
"golang.org/x/sync/errgroup"
"golang.org/x/time/rate"
)
type Notification struct {
UserID string
Title string
Body string
}
type Sender struct {
emailLim *rate.Limiter // e.g. 20 rps, burst 40
smsLim *rate.Limiter // e.g. 5 rps, burst 10
pushLim *rate.Limiter // e.g. 100 rps, burst 200
}
func (s *Sender) Send(ctx context.Context, n Notification) error {
g, ctx := errgroup.WithContext(ctx)
g.Go(func() error {
if err := s.emailLim.Wait(ctx); err != nil {
return err
}
return sendEmail(ctx, n)
})
g.Go(func() error {
if err := s.smsLim.Wait(ctx); err != nil {
return err
}
return sendSMS(ctx, n)
})
g.Go(func() error {
if err := s.pushLim.Wait(ctx); err != nil {
return err
}
return sendPush(ctx, n)
})
return g.Wait()
}
func RunNotificationWorkers(
ctx context.Context,
jobs <-chan Notification,
s *Sender,
workers int,
) error {
g, ctx := errgroup.WithContext(ctx)
g.SetLimit(workers)
for n := range jobs {
n := n
g.Go(func() error {
if err := s.Send(ctx, n); err != nil {
slog.Error("notification failed",
"user", n.UserID, "err", err)
return nil // don't kill the whole group on a single failure
}
return nil
})
}
return g.Wait()
}That return nil // don't kill the whole group is a small but important call. By default, errgroup cancels the whole context the moment any job returns an error. For a notification worker that's usually wrong: a Twilio outage shouldn't stop the email worker. So inside the worker, we log and swallow per-job errors. The outer group still benefits from g.SetLimit for parallelism, just without the "first error cancels all" semantics.
Three patterns, fifty lines, no goroutine leaks, no thundering herd against any of the providers, and clean cancellation throughout. None of them is doing anything fancy. They're each pulling their weight in a place that needs them.
A few traps that show up in code review
After enough Go concurrency reviews, the same handful of mistakes show up. They're worth naming once.
Forgetting that an unbuffered channel send is a synchronization point. If you write results <- v from a worker and nobody is reading the other end, you've just blocked the worker, possibly forever. Either buffer the channel, or read concurrently, or use select with a ctx.Done() case. Don't pretend the send is fire-and-forget. It isn't.
Closing channels you don't own. The rule is: the goroutine that writes to a channel closes it. Receivers do not close. Multiple writers means you need a coordinator (a sync.WaitGroup, an errgroup, or a single "fan-in" goroutine) that closes once the last writer is done. Closing a channel twice panics. Sending on a closed channel panics. Both make for spectacular crashes during shutdown.
Mistaking select { default: } for "skip if not ready." Sometimes that's exactly what you want. But putting default: in a loop without a time.Sleep or a blocking case turns the loop into a busy-wait that burns 100% CPU. If you reach for default, ask whether you're actually trying to do non-blocking IO (good use of default) or polling (almost never the right answer in Go; use a real blocking select).
Capturing the loop variable in go func(){ ... }() on pre-1.22 Go. This is the classic. Without the i := i line inside the loop, every goroutine reads the same i and they all see whatever value i had when the goroutine runs, not when it was launched. Go 1.22 fixed this by changing the loop-variable scoping, but plenty of code in the wild predates that. If your codebase is on 1.22+ you can drop the rebinds; if it isn't, keep them.
Using sync.Mutex where a channel would be clearer. Channels aren't always the answer (a shared counter wants atomic.Int64, not a chan), but if you find yourself locking a mutex just to coordinate "is there work for the next stage yet?", you're probably building a channel by hand and badly. Try the channel version first; reach for a mutex only when the data structure is genuinely shared mutable state.
Treating context.WithTimeout as if it's free. Each WithTimeout starts a goroutine that fires the cancel after the deadline. If you create thousands of them per second without calling cancel(), you leak goroutines until they all eventually time out. The defer cancel() line is not decorative; it's how you avoid the leak.
Assuming the goroutine scheduler is fair. It mostly is, in practice. But "fairness" inside select (where multiple cases are ready) is random, not round-robin. If you absolutely need to consume two channels in a specific ratio, build that yourself with priorities; don't rely on select to do it.
A closing thought
The shapes are simple. Worker pool, fan-out/fan-in, rate limit. You can fit a complete, production-ready version of each on a single screen of code. What makes them load-bearing isn't the cleverness. It's that they slot together cleanly, propagate cancellation, and stay honest about how much parallelism you actually have.
Most Go services you'll ever read are some arrangement of these three patterns. The interesting parts are always at the seams: how the pool's results stream feeds the next stage, how the rate limiter sits between your fan-out and the downstream, how context threads through all of it so that one cancellation tears the whole thing down without leaking a goroutine. Get those seams right and the concurrency stops feeling like a constant source of fear.
Then you can go back to worrying about the actually hard problem: making sure the work inside each handler is correct.





