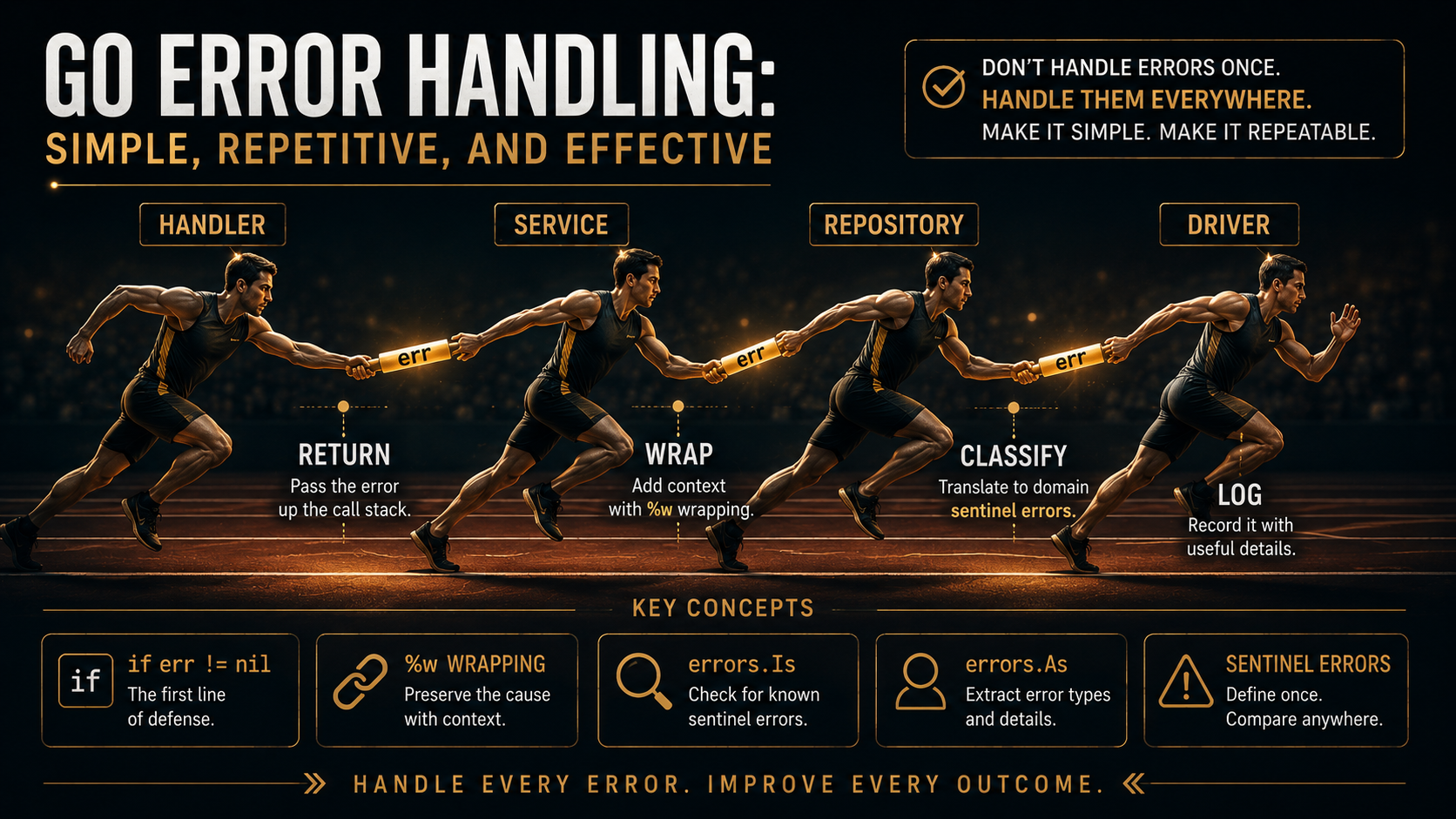
So, you've written a bit of Go. You've also probably written if err != nil { return err } about three thousand times. At some point you stopped seeing it. It became wallpaper.
That's the part most people get wrong about Go's error model. The repetition isn't a bug. It's the whole point. There's no try/catch, no implicit propagation, no monad library doing clever things behind your back. Every function that can fail tells you, in plain syntax, that it can fail. You either handle it or you forward it. There's no third option.
Newcomers usually fight this. They write helpers to "make it cleaner," then a year later quietly delete the helpers because they made the codebase harder to read. Go's error handling is verbose on purpose. The interesting question isn't "how do I avoid writing if err != nil?" It's "what should the err actually contain by the time it reaches the top?"
That's the question this article is about.
We're going to walk through:
- the
errorinterface and why it's just a one-method type, - the
if err != nilhabit and what it's really doing, - wrapping with
fmt.Errorfand%w, and whatUnwrapadds, - sentinel errors like
io.EOFandsql.ErrNoRows, - custom error types with
errors.Isanderrors.As, - when to reach for each one,
- and how errors should look by the time they cross a boundary: HTTP, queue, log line.
If you came here looking for a way to make Go feel like Java's checked exceptions or Rust's ? operator, this article is going to disappoint you. Go's error story isn't fancier than other languages. It's just smaller, and it leans on you to do the thinking.
The error interface is one method long
Before any of the patterns make sense, look at what error actually is in the standard library:
type error interface {
Error() string
}That's it. Any value with an Error() string method satisfies error. There's no hierarchy, no parent class, no marker interface. The simplest possible custom error is a string with a method on it:
type errString string
func (e errString) Error() string { return string(e) }
var ErrTimeout = errString("operation timed out")This is roughly how the standard library does it for many of its sentinel errors, though it usually uses errors.New, which wraps a string in a struct with a pointer comparison. We'll get to that.
The thing to take away here: errors in Go are values. They're not exceptions in disguise. You return them from functions like any other value, you pass them around, you store them in fields, you compare them. They go down the normal data path of your program, not a sidecar control-flow channel.
That single design choice is why everything else in this article exists. If errors are just values, then "handling an error" is just "looking at a value and deciding what to do with it." Wrapping, classifying, matching: those are all operations on data.
The if err != nil habit
The basic shape:
f, err := os.Open("config.yml")
if err != nil {
return err
}
defer f.Close()Three lines. The first does the work. The second checks whether it failed. The third returns it to the caller. Multiply by every line that does I/O, parses something, or calls another function that does either, and you have most of a real Go program.
People joke about this. They shouldn't. Look at what those three lines say in plain English:
Try to open the file. If you couldn't, hand the error to whoever called me. They'll know what to do.
There's nothing hidden. The error doesn't leap up the stack on its own. You see exactly where it's checked, exactly where it's propagated, exactly which functions can't fail (because they don't return error). When you're debugging an issue in production at 2am, that property is worth a lot.
The temptation to write helpers like must(f, err) or try(f.Read(buf)) shows up the first week and goes away after the first real bug. Helpers hide the check. The check is the thing that makes Go errors useful.
There are two variants worth knowing. First, you can choose not to forward:
n, err := strconv.Atoi(s)
if err != nil {
n = 0 // fall back to zero, this is fine for our use case
}Second, you can add context before forwarding, and this is where the article actually gets interesting.
Wrapping with fmt.Errorf and %w
A raw error often loses the context that made it useful.
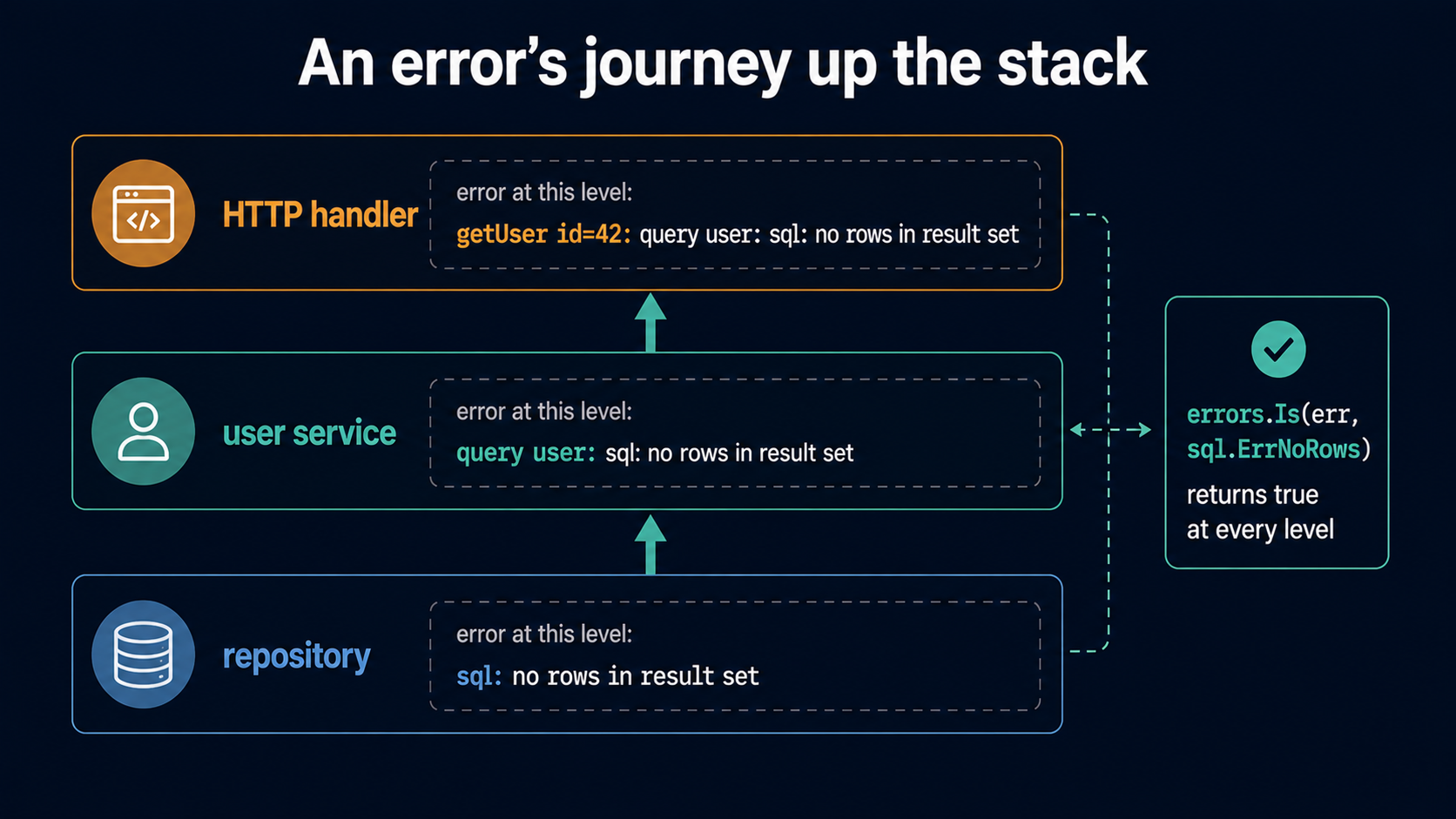
Imagine a function deep in your repository layer returns sql: no rows in result set. By the time it reaches your HTTP handler four call sites up, you have no idea which row was missing, which table, which user. The error is technically correct and operationally useless.
The fix is wrapping. Since Go 1.13, fmt.Errorf understands the %w verb:
func getUser(ctx context.Context, id int64) (*User, error) {
u, err := db.queryUserByID(ctx, id)
if err != nil {
return nil, fmt.Errorf("getUser id=%d: %w", id, err)
}
return u, nil
}%w does two things at once: it formats the underlying error into the string (so logs read naturally), and it preserves the underlying error as a wrapped value you can later unwrap programmatically. The output of err.Error() becomes something like:
getUser id=42: query user: sql: no rows in result setEach layer prepended its own context. Read from left to right, it's a tiny trace through your codebase: handler, service, repository, with the original cause at the end. That's the whole convention: each layer adds what it was trying to do, then forwards.
The compare-and-contrast version with %v instead of %w matters:
return nil, fmt.Errorf("getUser id=%d: %v", id, err) // ❌ loses the wrapped error
return nil, fmt.Errorf("getUser id=%d: %w", id, err) // ✅ keeps it%v formats the error into the string and throws away the original. %w keeps a reference. From a logging point of view both look the same. From an errors.Is / errors.As / unwrap chain point of view, the first one is a dead end. Use %w unless you have a specific reason not to (and you almost never do).
A small but real rule: wrap with %w at most once per call. Multiple %w verbs in one fmt.Errorf call were added in Go 1.20, and they produce a multi-error, useful when you genuinely have several causes, confusing if you reach for them out of habit. Stick to single wraps in normal flow.
errors.Is and errors.As
Once you've wrapped, the next question is: how do you ask "is this that kind of error?" without parsing strings.
Two functions in the standard library:
errors.Is(err, target) // value comparison, walking the wrap chain
errors.As(err, &target) // type assertion, walking the wrap chainerrors.Is is for sentinel errors: known package-level error values you compare by identity:
u, err := getUser(ctx, id)
if errors.Is(err, sql.ErrNoRows) {
return nil, ErrUserNotFound
}
if err != nil {
return nil, err
}errors.Is walks the wrap chain. Even though sql.ErrNoRows came from four layers down and got wrapped twice on the way up, this still returns true. That's the whole reason %w exists: to keep that identity intact.
errors.As is for typed errors: when the error is a struct that carries fields you want to read:
var pgErr *pq.Error
if errors.As(err, &pgErr) {
if pgErr.Code == "23505" {
return ErrEmailTaken
}
}You pass a pointer to a variable of the target type. If any error in the wrap chain is assignable to that type, errors.As sets the variable and returns true. Now you have the underlying typed error and can pull fields off it.
Two things that catch people:
Don't compare errors with
==unless you're sure nothing has wrapped them yet. The moment one layer addsfmt.Errorf("...: %w", err), yourerr == io.EOFcheck silently becomes false. Useerrors.Is(err, io.EOF)and it keeps working forever.errors.Asneeds a pointer to a typed variable, not a pointer to a genericerror. The compiler will catch this if you forget. It's a runtime panic in early Go that's now a compile error in modern versions, but the muscle memory is "always declare avar foo *MyErrorfirst."
Sentinel errors
A sentinel is a package-level error value you export so callers can compare against it. The classics:
io.EOF
sql.ErrNoRows
context.Canceled
context.DeadlineExceeded
fs.ErrNotExistYou make your own with errors.New:
var (
ErrInsufficientFunds = errors.New("insufficient funds")
ErrAccountFrozen = errors.New("account frozen")
ErrCardExpired = errors.New("card expired")
)The reason errors.New works for this (even though two strings could have the same content) is that under the hood it returns a pointer to a struct. Each call gives you a unique address. So ErrInsufficientFunds and a separate errors.New("insufficient funds") are not equal, even though their Error() strings match. Identity, not content.
That's also the reason you should declare sentinels once, at the package level, and not inside functions. A sentinel made inside a function is a new value every call, useless for comparison.
Sentinels work well when:
- The error has no extra fields worth carrying. It's just the thing that happened.
- Callers want to branch on identity. They want to ask "was this specifically
ErrInsufficientFunds?" - The error is part of the package's API contract. You're promising your callers, "this function can return one of these named errors, and you can switch on them."
They work poorly when:
- You want to attach data to the error (which account? which amount?). Strings concatenated into the message work, but they're not programmatically accessible without parsing.
- The set of possible errors is large or open-ended. A dozen exported sentinels is fine. A hundred is a code smell.
A common pattern that mixes both worlds: a sentinel for the kind, wrapped with context for the specifics:
return fmt.Errorf("withdraw account=%d amount=%d: %w", id, amount, ErrInsufficientFunds)The caller checks errors.Is(err, ErrInsufficientFunds). The logs show the account and amount. Best of both: kind on the outside via Is, details on the inside via the wrapped message.
Custom error types
When the error has data you want callers to read, not just compare, reach for a custom type.
type ValidationError struct {
Field string
Message string
}
func (e *ValidationError) Error() string {
return fmt.Sprintf("validation: %s: %s", e.Field, e.Message)
}Now you can do:
var vErr *ValidationError
if errors.As(err, &vErr) {
log.Warn().
Str("field", vErr.Field).
Str("reason", vErr.Message).
Msg("validation failed")
}The caller can access Field and Message directly. No string parsing, no fragile regex, no strings.Contains(err.Error(), "email") nonsense.
A couple of practical rules around custom errors:
Use pointer receivers for the Error() method, and return pointers. This matches the rest of the standard library and avoids subtle bugs around method sets and errors.As. A custom error type usually means "this error carries data," and pointer semantics fit data better than value semantics.
Implement Unwrap() if your error wraps another. It's how errors.Is and errors.As keep walking past you:
type DBError struct {
Op string
Err error
}
func (e *DBError) Error() string { return fmt.Sprintf("db %s: %v", e.Op, e.Err) }
func (e *DBError) Unwrap() error { return e.Err }Without Unwrap, errors.Is(err, sql.ErrNoRows) stops at your type and returns false. With it, the chain keeps going.
Implement Is(target error) bool only if you need custom matching. Most types don't. But if your error semantically equals several sentinels, say a unified NotFoundError that should match both sql.ErrNoRows and fs.ErrNotExist, you can teach errors.Is how to think about that:
func (e *NotFoundError) Is(target error) bool {
return target == sql.ErrNoRows || target == fs.ErrNotExist
}Use this rarely. Most of the time it confuses readers.
When to reach for each one
Here's a decision sketch:
- The error is a fact with no data (e.g., "the input has no rows") → sentinel with
errors.New, compared viaerrors.Is. - The error carries fields the caller will read (validation context, retryable flag, the offending account ID) → custom type, accessed via
errors.As. - The error adds context to another error as it bubbles up (handler context, service context) →
fmt.Errorf("...: %w", err). No new type required.
The temptation is to define elaborate type hierarchies for everything. Resist. Most error sites in real Go code are one of those three shapes, and reaching for the simplest one keeps the codebase easy to read.
A small library or service might define:
- Three or four package-level sentinels for its top-level domain failures (
ErrNotFound,ErrConflict,ErrForbidden). - One or two custom error types for things that carry data (
ValidationError,RetryableError). - A lot of
fmt.Errorf("...: %w", err)calls everywhere else.
That's a reasonable balance. If you find yourself with twenty custom types and a hundred sentinels, something has drifted.
Errors at boundaries
The interesting place, and where every team eventually has to make a decision, is what happens when errors cross a boundary. HTTP response, queue message, log line, RPC reply. Internal errors carry rich context; external errors carry exactly what the consumer needs and not a byte more.
Inside the service, errors look like this:
getUser id=42: query user: sql: no rows in result setOutside the service, the same error should look like this:
HTTP/1.1 404 Not Found
Content-Type: application/json
{"error": "user_not_found", "request_id": "abc-123"}Don't leak the SQL error string to the client. It tells an attacker your driver, your query layer, and your data model. It tells a regular user nothing useful. The translation happens in one place, usually a middleware or a top-level handler, and it does roughly this:
func writeError(w http.ResponseWriter, r *http.Request, err error) {
log := hlog.FromRequest(r)
reqID := middleware.GetReqID(r.Context())
switch {
case errors.Is(err, ErrUserNotFound):
log.Warn().Err(err).Msg("user not found")
writeJSON(w, 404, errResp{"user_not_found", reqID})
case errors.Is(err, ErrUnauthorized):
log.Warn().Err(err).Msg("unauthorized")
writeJSON(w, 401, errResp{"unauthorized", reqID})
case errorsAsValidation(err):
log.Warn().Err(err).Msg("validation failed")
writeJSON(w, 400, errResp{"validation_failed", reqID})
default:
log.Error().Err(err).Msg("internal error")
writeJSON(w, 500, errResp{"internal_error", reqID})
}
}Three useful things this pattern does:
- The full wrapped error goes to the log (with the request ID attached), so you can find it later. Operational errors land at
warn, real bugs aterror. The alert wiring uses the level: page onerror, ignorewarn. - The client sees a clean error code and the request ID. No stack traces, no internal field names, no driver-specific strings. If they complain, support reads the ID off their screenshot and finds the exact log line.
- Classification happens once. The rest of the code just returns
err, wrapped or not, and never thinks about HTTP status codes. That's a quiet but huge architectural win:net/httpstays at the edge of the application instead of leaking through every service method.
This is also why errors.Is and errors.As matter. The wrapping chain is what lets the boundary handler look at an error from four layers down and still ask, "is this fundamentally a not-found?" Without %w, that switch up there has to become a string match: fragile, error-prone, and the first thing that breaks when somebody adds fmt.Errorf("%s: %v", ...) instead of %w.
Joining multiple errors
Sometimes a single operation produces several errors at once. Closing a writer might both fail to flush and fail to release a handle. Running validation might surface five field errors, not one. Since Go 1.20:
err := errors.Join(flushErr, closeErr)Join returns an error whose Error() method shows both messages and whose Unwrap() []error exposes each one. errors.Is and errors.As walk all branches.
The pattern shows up most often in cleanup paths:
func (s *Store) Close() error {
var errs error
if err := s.cache.Flush(); err != nil {
errs = errors.Join(errs, fmt.Errorf("cache flush: %w", err))
}
if err := s.conn.Close(); err != nil {
errs = errors.Join(errs, fmt.Errorf("conn close: %w", err))
}
return errs
}If everything succeeds, errs stays nil. If anything fails, the caller gets one composite error that doesn't lose any of the underlying ones. That last property is the thing. Before errors.Join, you had to choose which failure to report and silently drop the others.
panic and recover (and when not to)
Go does have panic. It does have recover. They are not your error handling tool.
panic is for unrecoverable situations: invariants you can't believe just broke, like a switch over an enum that hit a value you don't have a case for, or a configuration that's so wrong the program shouldn't run. The whole goroutine unwinds. If nothing recovers, the program crashes.
recover is for very specific places: the top of a handler in a long-running server, or the boundary of a worker goroutine, where a single bug in one request shouldn't take the whole process down:
func recoverMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
defer func() {
if rec := recover(); rec != nil {
hlog.FromRequest(r).Error().
Interface("panic", rec).
Bytes("stack", debug.Stack()).
Msg("handler panic")
writeJSON(w, 500, errResp{"internal_error", middleware.GetReqID(r.Context())})
}
}()
next.ServeHTTP(w, r)
})
}That's about it. Anything expected, bad input, missing record, expired token, network blip, is not a panic. It's an error value returned through the normal flow. If you start using panic for control flow, you've reimplemented exceptions, badly, on top of a language that deliberately doesn't have them.
What "good" Go error code looks like
After all the patterns, here's what a normal Go function ends up looking like in practice:
func (s *AccountService) Withdraw(ctx context.Context, id int64, amount int64) error {
acc, err := s.repo.GetAccount(ctx, id)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
return fmt.Errorf("withdraw id=%d: %w", id, ErrAccountNotFound)
}
return fmt.Errorf("withdraw id=%d: get account: %w", id, err)
}
if acc.Frozen {
return fmt.Errorf("withdraw id=%d: %w", id, ErrAccountFrozen)
}
if acc.Balance < amount {
return fmt.Errorf("withdraw id=%d amount=%d balance=%d: %w",
id, amount, acc.Balance, ErrInsufficientFunds)
}
if err := s.repo.DebitAccount(ctx, id, amount); err != nil {
return fmt.Errorf("withdraw id=%d: debit: %w", id, err)
}
return nil
}Count the patterns:
- One sentinel translation (
sql.ErrNoRows→ErrAccountNotFound) so callers don't need to know the storage layer exists. - Three wrapped sentinels for domain failures, each one annotated with the relevant identifiers.
- Two pure forward-with-context wraps for everything else.
- Zero string parsing, zero custom types in this function, zero
panic. Everything that could go wrong is named in the return path.
The boundary handler downstream switches on errors.Is(err, ErrAccountFrozen) and friends, picks the right HTTP status, logs the full chain, and returns a clean response. The repository layer at the other end just bubbles whatever the database driver gave it, wrapped with what it was trying to do.
Six or seven if err != nil blocks. Probably twenty in the file. Maybe two hundred in the package. That's Go. Verbose, repetitive, and once you stop fighting it, oddly calming. Every failure mode is visible in the same shape, and there's exactly one place that decides what to do with it at the edge.
You don't make Go errors elegant by avoiding them. You make them effective by deciding what they should carry, where they should be classified, and how they should look the moment they leave your service. The rest is if err != nil { return err }, and that's fine.





