
So, you've got a main.go and one folder of helpers, and the project is starting to feel uncomfortable. New files keep landing in utils/. The same struct gets imported from three places that shouldn't know about each other. Somebody added an HTTP handler that opens a database connection directly. You can feel it, the project wants a structure, and you don't quite know which one to give it.
This is the moment most Go teams reach for an authoritative folder layout. They search "go project structure," find the golang-standards/project-layout repo, copy the tree, and then spend the next year arguing about whether pkg/ should exist. That repo, by the way, is explicitly not an official standard (even the README says so), but the convention stuck because Go gives you almost no rules of its own. The compiler is happy with one file in the root. The community had to invent the rest.
Here's the thing nobody tells you up front: Go's structure isn't really about folders. It's about boundaries, who's allowed to import whom, where business logic actually lives, and which files you're willing to break the build over. The folders are just how Go enforces some of those boundaries through internal/ and module paths. Pick the boundaries first, and the folder names almost write themselves.
This piece walks through the layout that holds up in real production services, cmd/, internal/, pkg/, and inside internal/ the trio of handlers/, services/, and repositories/. We'll go through each one in detail, what it should contain, what it should never contain, and how a request actually flows through all of them.
The Layouts You'll Outgrow First
Before we talk about what works, it helps to see what stops working.
The flat layout. Everything in the repo root. main.go, db.go, user.go, handlers.go, auth.go. This is the right shape for a 200-line tool or a code sample. Past that, package main becomes a junk drawer, every type in it is in every other file's namespace, and you can't reuse anything from elsewhere because everything is in package main.
The "group by technical role" layout. A folder for models/, a folder for controllers/, a folder for services/, a folder for repositories/. It looks tidy on day one. By month six you've got 80 files in models/ from 14 unrelated features, and every change to one feature edits four folders. This is the layout the Laravel and Rails worlds get away with because their frameworks paper over the friction. Go gives you nothing to lean on, you'll feel every cross-folder hop.
The "everything in pkg/" layout. People see pkg/ in some Kubernetes-shaped repo and decide everything goes there. Now your import paths look like github.com/acme/billing/pkg/internal/billing/usecase/billing. Nobody can find anything. You broke internal/'s only real superpower, compiler-enforced privacy, by stuffing it inside pkg/ where every external consumer can reach in.
The shape that survives looks roughly like this:
.
├── cmd/
│ ├── api/
│ │ └── main.go
│ └── worker/
│ └── main.go
├── internal/
│ ├── billing/
│ │ ├── handler.go
│ │ ├── service.go
│ │ ├── repository.go
│ │ └── types.go
│ ├── user/
│ │ ├── handler.go
│ │ ├── service.go
│ │ └── repository.go
│ ├── platform/
│ │ ├── postgres/
│ │ ├── httpserver/
│ │ └── config/
│ └── app/
│ └── wire.go
├── pkg/
│ └── ratelimit/
├── migrations/
├── api/
│ └── openapi.yaml
├── go.mod
└── go.sumTwo things to notice. First, internal/ is grouped by feature (billing, user), not by technical role. Second, pkg/ exists but it's small, only the genuinely shareable bits live there. The rest of this article is about why those two choices matter.
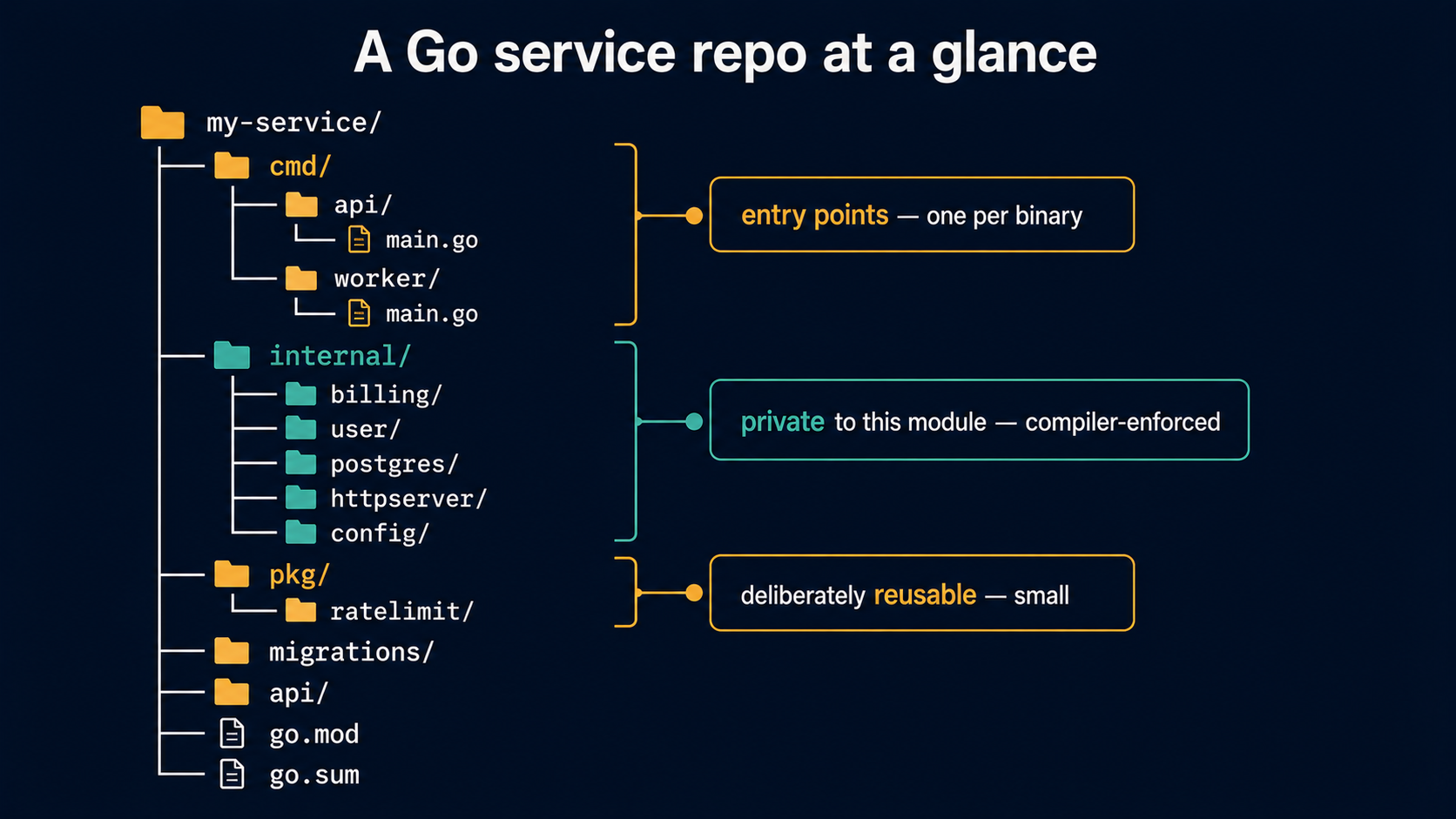
cmd/: One Folder Per Binary, And Nothing Else
cmd/ is the front door. Each subdirectory under it is exactly one binary your repo produces. If you ship an HTTP API, a queue worker, and a CLI tool, you have three folders.
cmd/
├── api/
│ └── main.go
├── worker/
│ └── main.go
└── migrate/
└── main.goThe convention exists because Go modules can produce many binaries from one repo, and the binary name comes from the folder. go build ./cmd/api produces an api executable. go install ./cmd/... installs all three. You don't have to name them this way, you could put main.go at the repo root and ship a single binary, but the moment you need a second binary, cmd/ is what saves you from confusing build paths.
The rule for what goes inside each main.go is short: wire dependencies, start the server, and exit cleanly. That's it. Nothing else. No business logic. No HTTP handlers defined inline. No database queries.
package main
import (
"context"
"log/slog"
"os"
"os/signal"
"syscall"
"github.com/acme/shop/internal/app"
"github.com/acme/shop/internal/platform/config"
)
func main() {
cfg, err := config.Load()
if err != nil {
slog.Error("config load", "err", err)
os.Exit(1)
}
ctx, stop := signal.NotifyContext(context.Background(),
syscall.SIGINT, syscall.SIGTERM)
defer stop()
server, cleanup, err := app.NewAPIServer(ctx, cfg)
if err != nil {
slog.Error("wire", "err", err)
os.Exit(1)
}
defer cleanup()
if err := server.Run(ctx); err != nil {
slog.Error("server run", "err", err)
os.Exit(1)
}
}Look at how thin that is. Read config. Make a cancelable context. Wire the app. Run it. Wait for the signal to bring it down. Every interesting line of code lives somewhere else.
The reason this matters: cmd/ is the part of your codebase most likely to be different between environments, different binaries, different startup paths, different sets of dependencies wired up. The less logic lives here, the less you have to reason about per-binary. If two binaries need to share startup logic, that logic moves into internal/app/ or internal/platform/, not into a shared helper inside cmd/. cmd/ packages don't import each other. They each stand alone.
One small gotcha: each subdirectory under cmd/ must use package main. They are independent programs. You cannot put func someHelper() in cmd/api/helpers.go and call it from cmd/worker/main.go. The compiler won't let you, and that's correct. The moment you wanted that, you wanted internal/ instead.
internal/: The Wall Around Your Real Code
internal/ is the most important folder in a Go project, and most people use it as a vibe rather than a feature.
Here's the actual rule, baked into the Go compiler since Go 1.4: a package located at path/internal/X can only be imported by packages rooted at path/. Anything outside that module path gets a hard compile error. It is not a convention. It is not a linter rule. It is the toolchain refusing to build.
That means github.com/acme/shop/internal/billing can be imported by github.com/acme/shop/cmd/api, by github.com/acme/shop/internal/user, by anything inside the shop module. It cannot be imported by github.com/other/project, even if they vendor your repo. Go will refuse.
This is exactly the property you want for almost all of your code. Your billing service is not a library. Your User struct is not a library. They are private implementation that happens to live in a Go module. internal/ lets you keep them genuinely private without writing a single line of documentation about it.
The practical consequence: default to internal/. When you're not sure where a package goes, put it under internal/. You can always move it out later if a real external consumer appears. Moving the other way, discovering you accidentally let three external repos import your billing internals, is a maintenance nightmare.
Inside internal/, the two organizing principles that actually work are features and platform. Feature folders own one slice of business behavior end-to-end. Platform folders own infrastructure adapters that any feature can use.
internal/
├── billing/ # feature: everything billing-related, top to bottom
├── user/ # feature: user accounts
├── catalog/ # feature: products and search
├── platform/
│ ├── postgres/ # database connection, retries, transaction helpers
│ ├── httpserver/ # router, middleware, request ID
│ ├── kafka/ # producer/consumer wrappers
│ └── config/ # config loading
└── app/
└── wire.go # composition root — builds the object graphThe feature folders are the bulk of your code. Each one owns its own HTTP handlers, services, repositories, and types. A billing change touches internal/billing/*. A new shipping feature is a new folder. You don't have to chase a feature through four parallel folders to find what it does.
The platform folders own the boring infrastructure shared by every feature: the database pool, the HTTP server, the message broker, the config loader. The rule there is the same as shared/ in any other language, small, stable, well-tested, owned. If it's still finding its shape, it doesn't belong in platform/ yet.
app/ (sometimes called bootstrap/ or wiring/) is the composition root. It's the one place that knows how to build a real instance of every service and wire them together. We'll get back to it.
pkg/: The Part You Actually Mean To Share
Here's the controversial folder. Half the Go community uses pkg/. The other half thinks it's pointless. Both are right depending on what you put in it.
The original idea: code under pkg/ is deliberately public, you've decided this package is a library, you support its API, you'd be okay if a teammate's other repo started importing it tomorrow. Everything else goes in internal/ (private) or at the repo root (entry points).
The way pkg/ goes wrong: people put domain code in there. They write pkg/billing/ because it feels like "the real code lives in pkg." Now their billing logic is part of the public API of the module, and any refactor risks breaking a downstream consumer that quietly started importing it. Worse, they put pkg/internal/billing/ to "get the best of both worlds," which is a tree-shaped lie, internal/ works at any depth, but burying it in pkg/ makes the layout actively misleading.
The way pkg/ goes right: a small, well-defined library that has nothing to do with your business. A rate limiter. A typed HTTP client. A telemetry wrapper. Something you'd be happy to lift into its own module someday.
pkg/
├── ratelimit/
│ ├── ratelimit.go
│ └── ratelimit_test.go
└── httpx/
├── client.go
└── retry.goA useful test: could this package be extracted into its own repo without losing meaning? If yes, pkg/ is fine. If no, it belongs in internal/.
A second useful test: does it depend on your domain types? If pkg/ratelimit imports internal/user, you've inverted the dependency. The library now knows about your business. Either the library doesn't belong in pkg/, or the domain types it touches don't belong in internal/. Usually it's the former.
Many production Go services have no pkg/ folder at all, and they're fine. That's the honest answer. Don't add the folder out of pattern fidelity, add it when you have something that earns it.
Inside A Feature: Handlers, Services, Repositories
Open internal/billing/. What's in there?
internal/billing/
├── handler.go # HTTP layer
├── service.go # business logic
├── repository.go # database access
├── types.go # domain types: Invoice, Charge, etc.
└── billing_test.goThree files do the bulk of the work, and each one has exactly one job. This is the classic three-layer split, and it's worth being clear-eyed about what each layer is allowed to know.
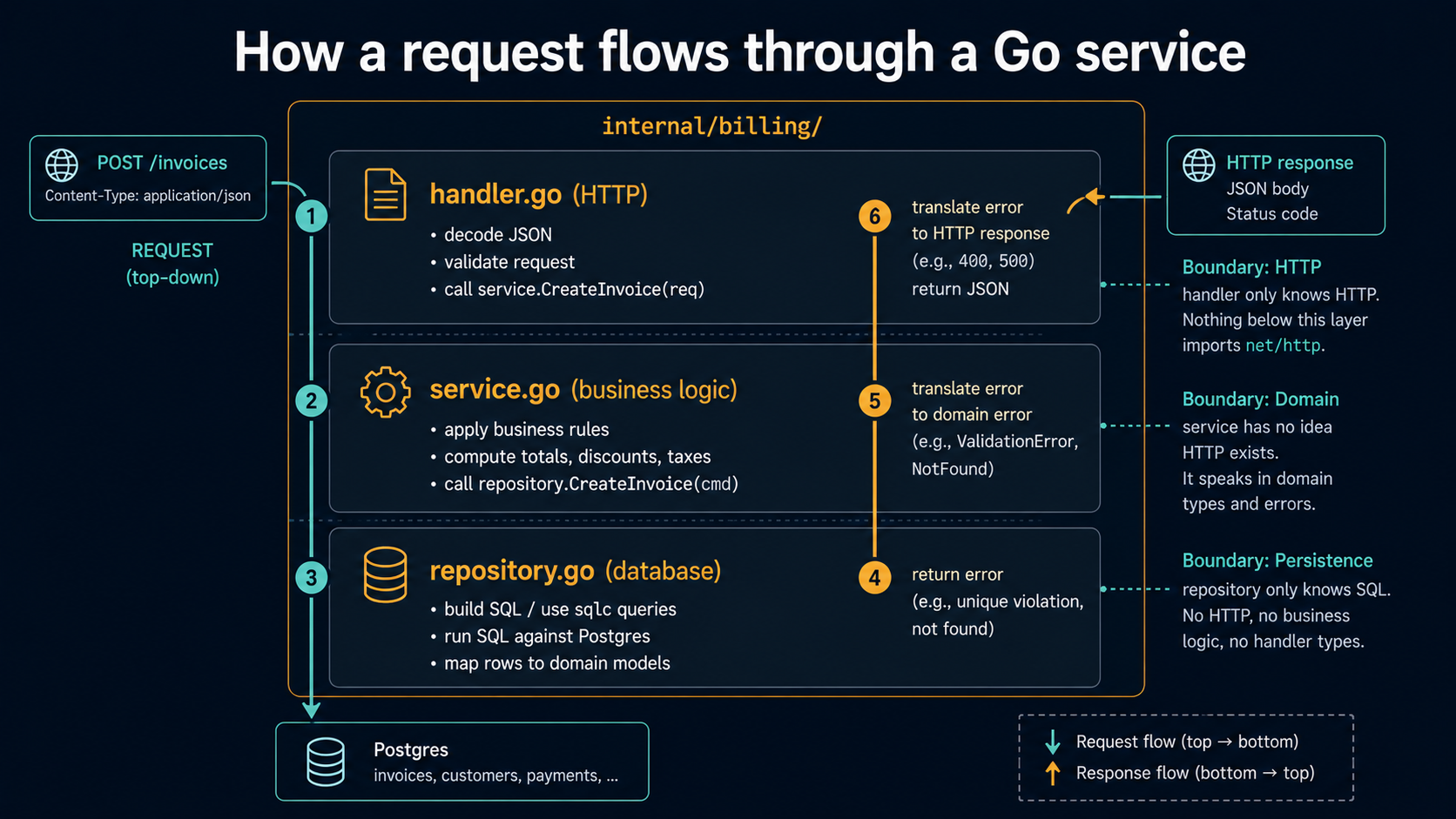
handler.go: The HTTP Boundary
The handler is the only file in the feature that knows HTTP exists. It decodes the request, validates the inputs, calls the service, and writes the response. That's the entire job.
package billing
import (
"encoding/json"
"errors"
"log/slog"
"net/http"
)
type Handler struct {
svc *Service
log *slog.Logger
}
func NewHandler(svc *Service, log *slog.Logger) *Handler {
return &Handler{svc: svc, log: log}
}
func (h *Handler) CreateInvoice(w http.ResponseWriter, r *http.Request) {
var req CreateInvoiceRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
http.Error(w, "invalid json", http.StatusBadRequest)
return
}
if err := req.Validate(); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
inv, err := h.svc.CreateInvoice(r.Context(), req.ToInput())
switch {
case errors.Is(err, ErrCustomerNotFound):
http.Error(w, "customer not found", http.StatusNotFound)
return
case errors.Is(err, ErrInvoiceFrozen):
http.Error(w, "invoice locked", http.StatusConflict)
return
case err != nil:
h.log.Error("create invoice", "err", err)
http.Error(w, "internal error", http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
_ = json.NewEncoder(w).Encode(inv)
}Things to notice. The handler doesn't reach into the database. It doesn't compute totals. It doesn't decide whether the customer is allowed to be charged. All of that lives in the service. The handler's job is translation, turn HTTP into a service call, turn the result back into HTTP.
The error-mapping switch is doing real work. Each sentinel error from the service maps to a specific HTTP status. The service doesn't know about HTTP, so it can't return a 404. It returns ErrCustomerNotFound. The handler is the one place that decides what an HTTP-shaped response looks like for that error. If you wrap that service with a gRPC handler tomorrow, the mapping is in a different file and the service doesn't change.
The other rule: the handler operates on a request/response struct, not on the domain type. CreateInvoiceRequest is whatever JSON shape your API contract promises. Invoice is your internal domain object. They're allowed to diverge, and they usually should, because your API stability and your internal model don't move at the same pace.
service.go: Where The Decisions Live
The service is the part of your codebase that contains the actual business rules. It is the only file that fully understands what a billing operation means. It takes inputs from above (a handler, or a queue worker, or a CLI command), applies the rules of the domain, and asks the repository to persist what happened.
package billing
import (
"context"
"errors"
"fmt"
"time"
)
var (
ErrCustomerNotFound = errors.New("billing: customer not found")
ErrInvoiceFrozen = errors.New("billing: invoice is frozen")
)
type Service struct {
repo *Repository
clock func() time.Time
}
func NewService(repo *Repository, clock func() time.Time) *Service {
if clock == nil {
clock = time.Now
}
return &Service{repo: repo, clock: clock}
}
func (s *Service) CreateInvoice(ctx context.Context, in CreateInvoiceInput) (Invoice, error) {
cust, err := s.repo.GetCustomer(ctx, in.CustomerID)
if err != nil {
return Invoice{}, fmt.Errorf("create invoice: %w", err)
}
if cust.Frozen {
return Invoice{}, ErrInvoiceFrozen
}
inv := Invoice{
CustomerID: cust.ID,
Lines: in.Lines,
Total: sumLines(in.Lines),
IssuedAt: s.clock(),
Status: InvoiceStatusOpen,
}
if err := s.repo.InsertInvoice(ctx, &inv); err != nil {
return Invoice{}, fmt.Errorf("create invoice: %w", err)
}
return inv, nil
}The service has no idea HTTP exists. It accepts a context.Context and plain Go types, and it returns plain Go types or an error. That's the property that lets you call this from a handler today, from a CLI command tomorrow, from a queue consumer the day after, all without touching this code.
The service is also the file that depends on the repository through an interface, even if you don't always need one. Look at Service's repo field, I've typed it as *Repository here for brevity, but in practice many teams define an interface in the same file:
type Repository interface {
GetCustomer(ctx context.Context, id string) (Customer, error)
InsertInvoice(ctx context.Context, inv *Invoice) error
}The interface is declared by the consumer (the service), not by the implementer (the repository). That's idiomatic Go, "accept interfaces, return structs." It lets you stub the repo in tests without dragging the whole database in.
The service is also where you put cross-feature orchestration when you need it. If creating an invoice has to publish an event, the service is the one that calls into internal/platform/kafka or whatever messaging adapter you have. Handlers stay dumb. The service is the brain.
repository.go: The Database, And Only The Database
The repository is the one file that knows SQL. It opens connections (or rather, uses the pool given to it), it writes queries, it scans rows into domain types. It returns errors that the service can understand, but it does not return HTTP status codes and it does not make business decisions.
package billing
import (
"context"
"database/sql"
"errors"
)
type Repository struct {
db *sql.DB
}
func NewRepository(db *sql.DB) *Repository {
return &Repository{db: db}
}
func (r *Repository) GetCustomer(ctx context.Context, id string) (Customer, error) {
const q = `SELECT id, name, frozen FROM customers WHERE id = $1`
var c Customer
err := r.db.QueryRowContext(ctx, q, id).Scan(&c.ID, &c.Name, &c.Frozen)
if errors.Is(err, sql.ErrNoRows) {
return Customer{}, ErrCustomerNotFound
}
if err != nil {
return Customer{}, err
}
return c, nil
}
func (r *Repository) InsertInvoice(ctx context.Context, inv *Invoice) error {
const q = `
INSERT INTO invoices (id, customer_id, total, issued_at, status)
VALUES ($1, $2, $3, $4, $5)
`
_, err := r.db.ExecContext(ctx, q,
inv.ID, inv.CustomerID, inv.Total, inv.IssuedAt, inv.Status)
return err
}Notice the translation at the boundary: sql.ErrNoRows becomes ErrCustomerNotFound. The service should never see sql.ErrNoRows. The service should not know whether the storage is Postgres, MongoDB, or an in-memory map. If you swap the database tomorrow, only this file changes.
That translation is what gives the layered split its value. If you let sql.ErrNoRows leak up to the handler, you've coupled your HTTP layer to your database driver. A new database, a new driver, a different error type, and now you're rewriting handler code.
A practical question that comes up: should the repository return the domain type, or a separate row struct? For simple cases, returning the domain type is fine, the database row maps cleanly to Customer. For richer domain models, entities with invariants, aggregates that compose other types, you'll want a row-shaped DTO and a small constructor on the domain side. Don't over-engineer this on day one; let it appear when the mapping starts hurting.
Wiring It All Together In internal/app/
The three layers know about each other through constructors. None of them know how to build themselves. That's a feature, it means every layer is testable in isolation, and the assembly happens in exactly one place.
That place is the composition root. Conventionally internal/app/:
package app
import (
"context"
"github.com/acme/shop/internal/billing"
"github.com/acme/shop/internal/platform/config"
"github.com/acme/shop/internal/platform/httpserver"
"github.com/acme/shop/internal/platform/postgres"
"github.com/acme/shop/internal/user"
)
type APIServer struct {
http *httpserver.Server
}
func NewAPIServer(ctx context.Context, cfg config.Config) (*APIServer, func(), error) {
db, dbClose, err := postgres.Open(ctx, cfg.DatabaseURL)
if err != nil {
return nil, nil, err
}
userRepo := user.NewRepository(db)
userSvc := user.NewService(userRepo)
userHTTP := user.NewHandler(userSvc, cfg.Logger)
billingRepo := billing.NewRepository(db)
billingSvc := billing.NewService(billingRepo, nil)
billingHTTP := billing.NewHandler(billingSvc, cfg.Logger)
srv := httpserver.New(cfg, cfg.Logger)
srv.Mount("/users", userHTTP)
srv.Mount("/invoices", billingHTTP)
cleanup := func() { dbClose() }
return &APIServer{http: srv}, cleanup, nil
}
func (a *APIServer) Run(ctx context.Context) error {
return a.http.Run(ctx)
}This is the only place that needs to know that billing.NewHandler takes a service, that billing.NewService takes a repository, and that the repository takes a *sql.DB. Everywhere else, each layer just accepts what it needs through its constructor.
Some teams use google/wire or similar code-generation tools to generate this file. It's a perfectly reasonable choice once wire.go grows past ~200 lines. For most services, handwritten wiring is shorter, easier to read, and one less moving part. Pick the option that matches your team's appetite for tooling.
The other reason this folder exists: second binaries reuse it. Your worker's cmd/worker/main.go calls a different constructor, app.NewWorker(ctx, cfg), that wires up the same services in a different topology. No HTTP server. Maybe a queue consumer. The feature code (billing, user) doesn't change at all. The shape of the binary is decided at the composition root.
Things That Live On The Edges
A few folders that almost always exist but aren't part of the three-layer story.
migrations/, SQL files at the repo root, named with a timestamp or sequence number. Tools like golang-migrate/migrate, pressly/goose, or amacneil/dbmate all expect a directory of .sql (or .go) files. Keep them at the root so they're easy to find, easy to mount in CI, and not coupled to any one binary. The migrate binary at cmd/migrate/main.go just points at this folder.
api/, your OpenAPI spec, your .proto files, your AsyncAPI definitions. The contracts with the outside world. If you generate code from these, the generated output should live under internal/ (it's private, even if the spec isn't) and be regenerated through go generate or a Makefile target.
scripts/ or build/, shell scripts, Dockerfiles, deployment manifests. Cross-cutting concerns that don't fit anywhere else. Some teams call this deploy/ instead. The name doesn't matter much; just don't put Go code here.
testdata/, Go has a special rule for this folder. The go tool ignores any directory named testdata and any directory or file beginning with . or _ when it walks the package tree. Put fixtures, golden files, and seed JSON in there. The convention is so reliable that linters and IDEs all know about it.
docs/, anything human-readable that doesn't belong in the README. Architecture decision records, runbooks, onboarding notes. Markdown is fine. Treat it as part of the codebase, review it in PRs, keep it current.
Where People Get Stuck
A few decisions come up over and over. Quick answers.
"Where do I put shared types like User if both billing and user need it?"
Don't put User in two places. The user feature owns User. billing imports user.User when it needs to. Cross-feature imports are fine as long as the direction is one-way. If you find yourself wanting user to import billing.Invoice, that's a signal, either the line is in the wrong place, or both features actually depend on a third concept that should live in its own folder.
"Where do my errors live?"
Inside the feature. ErrCustomerNotFound belongs in internal/billing/. Errors that are truly shared across features (like a generic ErrNotFound envelope) can live in internal/platform/errx/, but most teams find they need fewer of these than they thought. Resist the urge to build a big errors package upfront.
"Where do my interfaces live?" Where the consumer is, not where the implementation is. The service defines the repository interface it needs. The handler defines the service interface it needs. This is the opposite of Java or C#, and it takes some unlearning. Once you accept it, your packages stop depending on each other for no reason.
"Where do my tests live?"
Next to the code, in the same package, using package billing for white-box tests or package billing_test for black-box tests. Don't make a separate tests/ folder, Go's tooling is built around colocated tests, and you give up go test ./... ergonomics by fighting it. Integration tests that span features can live in a tests/ folder at the root, but they're a different category and should be tagged with //go:build integration so they don't run in normal go test.
"Should I version my internal packages like internal/billing/v2/?"
Almost never. Internal code doesn't need versioning, you control all the call sites and refactor them together. Version your external contracts (the api/ folder, your OpenAPI spec, your gRPC services), not your internal Go packages.
The Layout Is A Means, Not An End
Reread this article in six months and the folder names won't feel that important. What matters is the underlying property: every package has one clear job, depends only on the layers below it, and can be replaced or tested without dragging the rest of the system along.
cmd/ exists to keep entry points thin. internal/ exists to keep everything else private. pkg/ exists for the rare library you actually mean to share. Inside a feature, handlers translate the wire format, services contain the rules, repositories talk to the storage. The arrows go in one direction.
When you find yourself debating whether something belongs in pkg/ or internal/, or whether services/ should be plural or singular, you're at the wrong altitude. Ask instead, who else needs to import this, and what would break if it changed? The folder name is just where you write the answer down.





