
So, you've built a REST API in Go. Maybe a couple of them. They serve JSON, they speak HTTP/1.1, they have a handful of endpoints, and they do the job. You can curl them. You can open them in a browser. You can hand a Postman collection to a frontend engineer and walk away. That's the floor. And for most internal services, the floor is enough.
And then one day you hit something REST is genuinely bad at.
Maybe it's a hot path between two of your own services where every millisecond shows up on a dashboard. Maybe it's a long-running operation that wants to push progress to the client instead of being polled into oblivion. Maybe it's a "schema" that lives entirely in a Notion doc and is wrong by the third paragraph. Maybe it's a pricing endpoint that returns slightly different JSON depending on which team last touched it and you've stopped being able to trust the response shape. You don't need a new framework. You need a new tool in the bag.
That tool is gRPC. And in Go, the story is unusually good. Go is one of gRPC's first-class languages, the codegen is clean, the streaming model fits goroutines, and the tooling around Protobuf has finally stopped being a yak-shave. This piece is the walk through it I wish I'd had: what Protobuf is actually doing, what gRPC adds on top, the four streaming shapes and when you'd reach for each, how to keep contracts honest as your service grows, and the honest performance story, not the marketing chart.
We'll cover:
- what
.protofiles actually describe, and why "the contract is the source code" matters, - the four call types (unary, server-stream, client-stream, bidirectional) and a worked example of each,
- the wire layer in plain language: HTTP/2 frames, multiplexing, why head-of-line blocking dies here,
- versioning rules that keep gRPC contracts safe to evolve,
- performance numbers you can trust, and where REST is still the right answer,
- and the rough edges (debuggability, browsers, the proxy story) that nobody warns you about.
Crack your knuckles. Let's start with the part that hides in plain sight.
The contract is the source code
Pop quiz: what's the schema of your REST API right now?
If your answer is "it's in the OpenAPI spec," follow up: is that spec generated from the code, or is the code generated from the spec, or are they two separate things that drifted last sprint? In most codebases I've audited, the answer is the third one. The spec was right in December. The handlers have moved on without it.
This is the problem gRPC solves first, before anything to do with performance. A gRPC service starts from a .proto file, and that file is the schema. The server is generated from it. The client is generated from it. Both sides import the same package, so when you rename a field or change a type, the compiler complains in both places before the change ever ships.
Here's the smallest real example. A users service, two endpoints, plain old proto3:
syntax = "proto3";
package users.v1;
option go_package = "github.com/you/yourservice/gen/users/v1;usersv1";
service UsersService {
rpc GetUser (GetUserRequest) returns (User) {}
rpc ListUsers (ListUsersRequest) returns (ListUsersResponse) {}
}
message User {
int64 id = 1;
string name = 2;
string email = 3;
int64 created_at_unix = 4;
}
message GetUserRequest {
int64 id = 1;
}
message ListUsersRequest {
int32 page_size = 1;
string page_token = 2;
}
message ListUsersResponse {
repeated User users = 1;
string next_page_token = 2;
}Read it for a second. Every field has a name and a number. The number is the field tag. That's what gets written on the wire, not the name. The name is for humans. The tag is what makes Protobuf both small and forward-compatible. We'll come back to that when we talk about versioning.
Generating Go code from this is one command, using buf, which is the friendliest tool in the Protobuf ecosystem these days:
buf generate...with a buf.gen.yaml that names the two plugins you need:
version: v2
plugins:
- remote: buf.build/protocolbuffers/go
out: gen
opt: paths=source_relative
- remote: buf.build/grpc/go
out: gen
opt: paths=source_relative,require_unimplemented_servers=trueWhat pops out is a Go package with two halves. The first half is the message types, User, GetUserRequest, etc., as ordinary Go structs with the right tags and a couple of generated helpers. The second half is the gRPC plumbing, a UsersServiceServer interface you implement, a RegisterUsersServiceServer function you call to mount the implementation onto a grpc.Server, and a UsersServiceClient you use from the other end.
That's the trick. You write a .proto file once, and the code that the server has to implement and the code that the client has to call are the same generated types. No JSON-shape negotiation. No "do I send created_at as a string or a number?" arguments. The compiler is the arbiter.
The Go side: server, then client
Let's wire the service up. The generated code gives you an interface like this:
type UsersServiceServer interface {
GetUser(context.Context, *GetUserRequest) (*User, error)
ListUsers(context.Context, *ListUsersRequest) (*ListUsersResponse, error)
mustEmbedUnimplementedUsersServiceServer()
}Your job is to implement it. The signature is friendlier than net/http: typed input, typed output, a context.Context for cancellation and deadlines, an error for the failure path. No ResponseWriter to remember to flush, no JSON tag mismatches to chase.
A complete in-memory implementation:
package users
import (
"context"
"sync"
"time"
"google.golang.org/grpc/codes"
"google.golang.org/grpc/status"
usersv1 "github.com/you/yourservice/gen/users/v1"
)
type Server struct {
usersv1.UnimplementedUsersServiceServer
mu sync.RWMutex
users map[int64]*usersv1.User
nextID int64
}
func NewServer() *Server {
return &Server{users: map[int64]*usersv1.User{}}
}
func (s *Server) GetUser(ctx context.Context, req *usersv1.GetUserRequest) (*usersv1.User, error) {
if req.GetId() == 0 {
return nil, status.Error(codes.InvalidArgument, "id is required")
}
s.mu.RLock()
defer s.mu.RUnlock()
u, ok := s.users[req.GetId()]
if !ok {
return nil, status.Errorf(codes.NotFound, "user %d not found", req.GetId())
}
return u, nil
}
func (s *Server) ListUsers(ctx context.Context, req *usersv1.ListUsersRequest) (*usersv1.ListUsersResponse, error) {
s.mu.RLock()
defer s.mu.RUnlock()
out := make([]*usersv1.User, 0, len(s.users))
for _, u := range s.users {
out = append(out, u)
}
return &usersv1.ListUsersResponse{Users: out}, nil
}
// CreateLocal is not part of the proto service; it's a test helper.
func (s *Server) CreateLocal(name, email string) *usersv1.User {
s.mu.Lock()
defer s.mu.Unlock()
s.nextID++
u := &usersv1.User{
Id: s.nextID,
Name: name,
Email: email,
CreatedAtUnix: time.Now().Unix(),
}
s.users[u.Id] = u
return u
}A few things to notice. The error path uses status.Error(codes.NotFound, ...) instead of returning a plain error. That's important: gRPC has its own typed status codes (OK, NotFound, InvalidArgument, Unauthenticated, PermissionDenied, DeadlineExceeded, Internal, Unavailable, and friends), and clients pattern-match on them with status.FromError. If you return a plain error, it gets coerced to codes.Unknown, which is the gRPC equivalent of "something went wrong, good luck."
The embedded UnimplementedUsersServiceServer is a forward-compatibility shim from the generated code. If somebody adds a new RPC to the proto, the old server still compiles. Every unimplemented method returns codes.Unimplemented by default, which is the right behaviour. The require_unimplemented_servers=true option in buf.gen.yaml makes that embedding mandatory so you can't forget it.
Now, wiring this into a real grpc.Server and listening on a port:
package main
import (
"log/slog"
"net"
"os"
"google.golang.org/grpc"
"google.golang.org/grpc/reflection"
usersv1 "github.com/you/yourservice/gen/users/v1"
"github.com/you/yourservice/internal/users"
)
func main() {
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
lis, err := net.Listen("tcp", ":9000")
if err != nil {
logger.Error("listen failed", "err", err)
os.Exit(1)
}
s := grpc.NewServer()
usersv1.RegisterUsersServiceServer(s, users.NewServer())
// Reflection lets grpcurl introspect the service over the wire.
reflection.Register(s)
logger.Info("gRPC listening", "addr", ":9000")
if err := s.Serve(lis); err != nil {
logger.Error("serve failed", "err", err)
os.Exit(1)
}
}That's the whole server. Compare it to the REST equivalent: no router, no JSON helpers, no validation tags, no error-response shape to standardise. The types are the contract; the contract is enforced by the compiler; the runtime is grpc.Server.
The client is just as small. Same package, opposite role:
package main
import (
"context"
"fmt"
"log/slog"
"os"
"time"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
usersv1 "github.com/you/yourservice/gen/users/v1"
)
func main() {
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
conn, err := grpc.NewClient(
"localhost:9000",
grpc.WithTransportCredentials(insecure.NewCredentials()),
)
if err != nil {
logger.Error("dial failed", "err", err)
os.Exit(1)
}
defer conn.Close()
client := usersv1.NewUsersServiceClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
u, err := client.GetUser(ctx, &usersv1.GetUserRequest{Id: 1})
if err != nil {
logger.Error("GetUser failed", "err", err)
os.Exit(1)
}
fmt.Println("got user:", u.GetName(), u.GetEmail())
}grpc.NewClient is the modern entry point (grpc.Dial is deprecated in recent versions of google.golang.org/grpc). insecure.NewCredentials() says "no TLS, just plain TCP," which is fine for local development; in production you'd hand it credentials.NewTLS(...) with a real config. The context.WithTimeout becomes the per-call deadline, and importantly, that deadline is propagated through the wire to the server, where it shows up as ctx.Deadline() and any downstream calls get the remaining budget automatically. That's a quietly enormous quality-of-life upgrade over JSON-over-HTTP, where every team invents their own timeout-passing convention or doesn't bother.
Streaming: the part REST really can't do
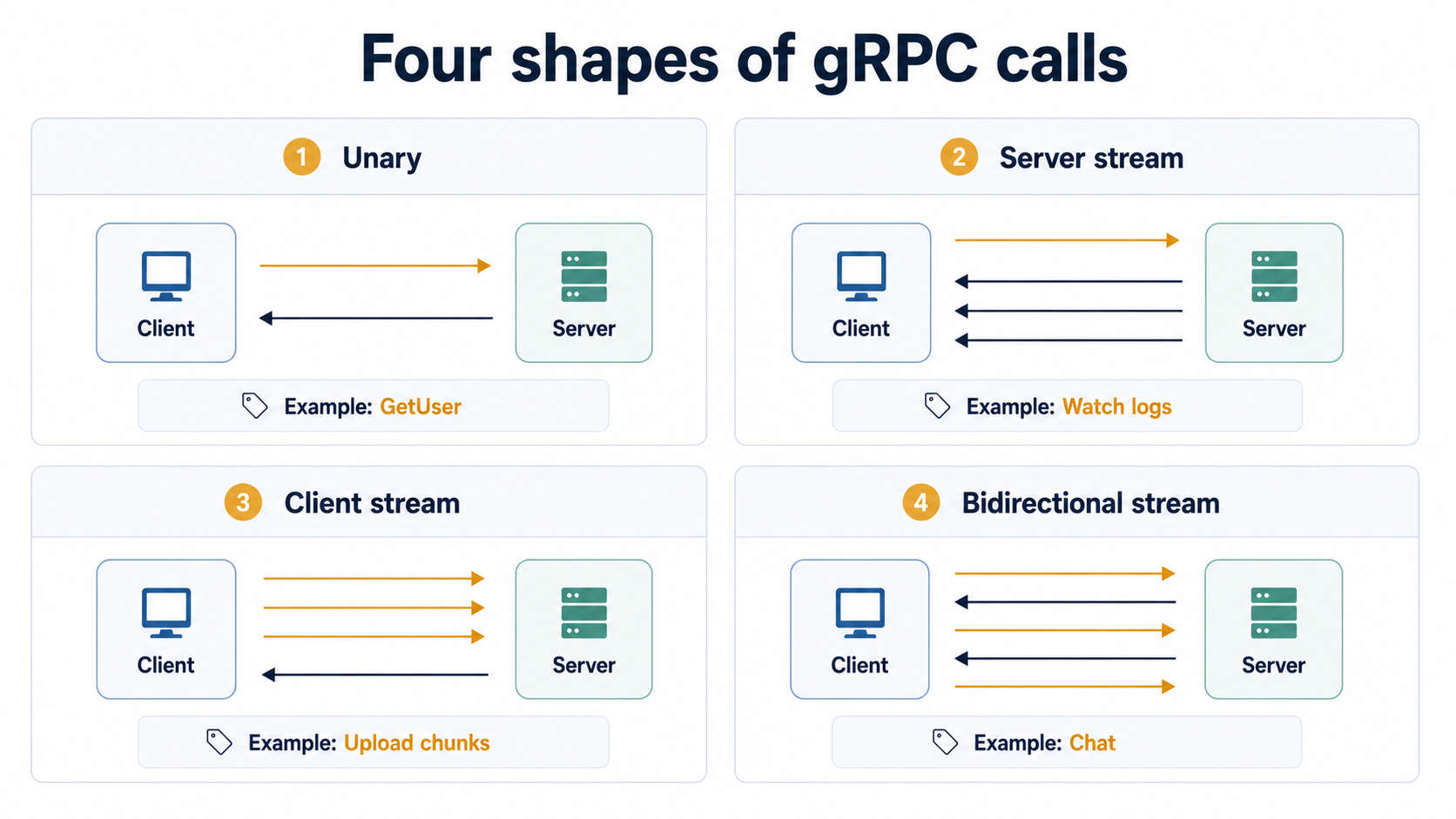
Unary calls (one request, one response) are gRPC's equivalent of a REST endpoint. They're the boring ones. The interesting four-quadrant map shows up when you let either side stream.
| Pattern | Client sends | Server sends | Real use case |
|---|---|---|---|
| Unary | one | one | GetUser, CreateOrder |
| Server stream | one | many | live tail of logs, search results as they arrive |
| Client stream | many | one | uploading chunks of a file, batch ingest |
| Bidirectional stream | many | many | chat, multiplayer game state, two-way telemetry |
Adding streaming to a .proto file is a single stream keyword on either side:
syntax = "proto3";
package orders.v1;
option go_package = "github.com/you/yourservice/gen/orders/v1;ordersv1";
service OrdersService {
// Server stream: the client subscribes, the server pushes order events.
rpc WatchOrders (WatchOrdersRequest) returns (stream OrderEvent) {}
// Client stream: the client uploads many line items, the server replies once.
rpc UploadCart (stream CartLineItem) returns (UploadCartResponse) {}
// Bidirectional stream: long-running negotiation.
rpc Negotiate (stream NegotiationMessage) returns (stream NegotiationMessage) {}
}
message WatchOrdersRequest {
int64 customer_id = 1;
}
message OrderEvent {
string event_id = 1;
int64 order_id = 2;
string status = 3;
int64 emitted_unix = 4;
}
message CartLineItem {
string sku = 1;
int32 quantity = 2;
}
message UploadCartResponse {
string cart_id = 1;
int32 item_count = 2;
}
message NegotiationMessage {
string from = 1;
string body = 2;
}The generated code now hands the server a Send-able stream object. The Go signature for WatchOrders becomes:
type OrdersService_WatchOrdersServer interface {
Send(*OrderEvent) error
grpc.ServerStream
}
type OrdersServiceServer interface {
WatchOrders(*WatchOrdersRequest, OrdersService_WatchOrdersServer) error
// ... other RPCs
}The implementation is almost shockingly small:
func (s *Server) WatchOrders(
req *ordersv1.WatchOrdersRequest,
stream ordersv1.OrdersService_WatchOrdersServer,
) error {
events := s.subscribe(req.GetCustomerId())
defer s.unsubscribe(req.GetCustomerId(), events)
for {
select {
case <-stream.Context().Done():
return stream.Context().Err()
case evt, ok := <-events:
if !ok {
return nil
}
if err := stream.Send(evt); err != nil {
return err
}
}
}
}If you've written Go for a while, that pattern is muscle memory: a select between cancellation and a work channel, and the loop drives until either side closes. The stream.Context() carries the same per-call deadline and cancellation we talked about before, and the client disconnecting closes that context. No timer fiddling, no goroutine leak, no event-source quirks to debug. This is one of the places gRPC's design and Go's design genuinely line up.
On the client side, server streaming is a single call that returns a stream object you call Recv on:
stream, err := client.WatchOrders(ctx, &ordersv1.WatchOrdersRequest{CustomerId: 42})
if err != nil {
return err
}
for {
evt, err := stream.Recv()
if errors.Is(err, io.EOF) {
return nil
}
if err != nil {
return err
}
fmt.Printf("event %s: order %d -> %s\n", evt.GetEventId(), evt.GetOrderId(), evt.GetStatus())
}Client streaming flips the direction. The server gets a Recv-able stream, the client calls Send many times and then CloseAndRecv to receive the final response:
func (s *Server) UploadCart(stream ordersv1.OrdersService_UploadCartServer) error {
var items []*ordersv1.CartLineItem
for {
item, err := stream.Recv()
if errors.Is(err, io.EOF) {
cartID := s.persist(items)
return stream.SendAndClose(&ordersv1.UploadCartResponse{
CartId: cartID,
ItemCount: int32(len(items)),
})
}
if err != nil {
return err
}
items = append(items, item)
}
}Bidirectional streaming is what it sounds like: both sides have Send and Recv, and you typically run them in two goroutines that share a context. The classic shape:
func (s *Server) Negotiate(stream ordersv1.OrdersService_NegotiateServer) error {
g, ctx := errgroup.WithContext(stream.Context())
incoming := make(chan *ordersv1.NegotiationMessage)
g.Go(func() error {
defer close(incoming)
for {
msg, err := stream.Recv()
if errors.Is(err, io.EOF) {
return nil
}
if err != nil {
return err
}
select {
case incoming <- msg:
case <-ctx.Done():
return ctx.Err()
}
}
})
g.Go(func() error {
for msg := range incoming {
reply := s.respondTo(msg)
if err := stream.Send(reply); err != nil {
return err
}
}
return nil
})
return g.Wait()
}That's not boilerplate gRPC forces on you. It's just how concurrent producer/consumer code looks in Go. The point is that the transport is finally out of your way. Two goroutines, one channel, an errgroup to wire failure semantics. The same pattern you'd write between any two parts of a single program now works between two services across a network.
grpc.Server. That's a quietly large reason to pick gRPC for a service that might need streaming one day, even if today's endpoints are all unary.
The wire, in plain language
You don't need a deep dive on Protobuf and HTTP/2 to use gRPC well, but a paragraph each is worth your time, because the two together are responsible for almost every performance difference between gRPC and JSON-over-HTTP/1.1.
Protobuf is a tag-length-value binary format. Each field on the wire is a small tag (a varint encoding the field number + wire type), a length when it's a length-delimited type, and the bytes. There are no field names on the wire. The integer 5 is one byte for the tag plus one byte for the value (two bytes total), versus "id":5 in JSON, which is at least six bytes plus quoting and the key. Strings, repeated fields, and nested messages add a length prefix. There's no whitespace, no quoting, no number-as-string fence-sitting. The decoder knows the shape from the generated .pb.go file, not from the bytes.
That's where the compactness comes from, and it's why Protobuf reads faster too: there's no string parsing, no boolean-vs-int inference, no float reconstruction from "3.14". A reader just reads the tag, dispatches on wire type, and fills the field. JSON has to do that and parse the structure as it goes.
HTTP/2 is the other half. gRPC mandates HTTP/2. There is no such thing as gRPC-over-HTTP/1.1. The two relevant things HTTP/2 brings over HTTP/1.1 are multiplexing and binary framing. Multiplexing means you can have many concurrent requests on a single TCP connection without blocking each other. Binary framing means every request and response is broken into typed frames (HEADERS, DATA, RST_STREAM, PING) interleaved on that connection.
If you've ever tried to serve a hundred parallel REST calls over HTTP/1.1, you've felt head-of-line blocking: each connection can only handle one request at a time, so the browser opens six connections per origin and you queue. HTTP/2 makes that problem disappear: hundreds of streams over one connection, each one independently flow-controlled. That's why server-to-server gRPC traffic can saturate a network pipe with a single open connection, while JSON-over-HTTP/1.1 needs a connection pool to get the same throughput.
And streaming falls out of this naturally. A gRPC stream is just a long-lived HTTP/2 stream where one side keeps sending DATA frames. There's no second protocol for "real-time" the way you needed Server-Sent Events or websockets on top of HTTP/1.1. The transport already handles it.
Versioning: the contract is the easy part; evolving it is the work
The reason field numbers exist in Protobuf is precisely so the schema can change without breaking running clients. Once you ship version one of a service, the field numbers in your messages become the wire format. As long as you follow a small handful of rules, old clients and new servers (and vice versa) keep working.
The rules are simple, but they're load-bearing. Memorise them.
Adding a field is safe. Old clients ignore unknown fields. New clients see the new field. As long as the new field has a sensible zero value, nothing breaks. Do not renumber existing fields when adding the new one. Just pick the next free number.
message User {
int64 id = 1;
string name = 2;
string email = 3;
int64 created_at_unix = 4;
string avatar_url = 5; // newly added, old clients ignore it
}Removing a field is breaking. The wire-level effect is that the field number gets reused if you're not careful, and old clients will decode garbage. The right move is to mark it reserved:
message User {
reserved 3; // "email" used to live here
reserved "email"; // and used to be named this
int64 id = 1;
string name = 2;
int64 created_at_unix = 4;
string avatar_url = 5;
}reserved is a compile-time guard. Anyone who tries to reuse tag 3 or the name email in this message gets a protoc error. That guard is the only thing standing between you and a deployed service that misinterprets bytes.
Changing a field's type is almost always breaking. Some narrow changes are wire-compatible (e.g., int32 <-> uint32 for non-negative values, int32 <-> int64 for small numbers), but if you're not absolutely sure, treat it as breaking. Add a new field with a new tag, deprecate the old one, migrate, then reserved the old one in a later release.
Renaming a field is safe on the wire (the tag is what matters) but breaks generated code on every client at compile time. That's actually the easier kind of break: the compiler tells you everywhere it broke. The wire stays unchanged.
Removing an RPC from a service is breaking. Old clients calling it will get codes.Unimplemented. Use deprecation instead: add option deprecated = true; to the RPC, keep it working, give callers time to migrate, then remove in a major version.
This is where buf breaking earns its keep. It compares your current .proto files against a baseline (a previous commit, a Buf module version, or a registered remote) and tells you whether your change is wire-incompatible:
buf breaking --against ".git#branch=main"Run that in CI on every PR that touches a .proto file. The number of bugs prevented by "you just renumbered a field, that's not allowed" being a CI failure instead of a 3am page is hard to overstate.
REST is not retired
I've been talking about gRPC as if you should reach for it whenever you can, and that's not actually what I believe. The honest framing is: REST is the right default for most surfaces, and gRPC is the right tool for some surfaces.
REST wins when:
- Your consumer is a browser. Browsers can't speak gRPC natively. You can get there with gRPC-Web and a proxy (Envoy or
grpc-gateway), but that's a separate protocol with separate streaming caveats and a deployment that has to keep working. For public-facing APIs hit by browser clients, REST is still the path of least resistance. - Third parties consume your API. A REST endpoint with an OpenAPI spec and a JSON response is something any engineer can integrate with in their first hour. A
.protofile is a different conversation, and a less welcoming one if the consumer's stack doesn't already have gRPC tooling. - Caching and CDN behaviour matters. Every HTTP cache, every CDN, every reverse proxy understands
GET /users/42and JSON. They don't understand gRPC. If your API benefits from edge caching, that benefit is enormous and gRPC throws it away. - Debuggability under fire. When something goes wrong at 3am,
curl -v https://api/...andjqare friends.grpcurlexists and is fine, but it's a smaller community and more setup. The first time you can't reproduce a production bug locally, you'll feel the difference.
gRPC wins when:
- It's service-to-service inside your own infrastructure. Both sides are yours, both sides have Go (or Python, or Java, or Node) clients, the contract is shared, the wire is binary, the connection is long-lived. This is the sweet spot.
- You need streaming. Watching, tailing, real-time updates, batch ingest: gRPC's streaming model is dramatically more pleasant than rolling your own with SSE or websockets.
- The contract is the bottleneck. When the cost of "what's the shape of this response?" is real and recurring across teams, generated code is worth the tooling cost.
- Latency-sensitive calls. A microsecond of CPU saved on every RPC adds up when you're doing them millions of times a day between services.
A perfectly defensible architecture: gRPC behind the front door, REST at the front door. The browser hits GET /api/orders/42 on the BFF (backend-for-frontend), which makes a gRPC call to OrdersService.GetOrder internally. The browser doesn't know gRPC exists; the internal services don't have to do JSON. Everybody gets the part of the world that suits them.
The honest performance story
Time to deflate a chart you've probably seen on a vendor slide. "gRPC is 7x faster than REST." Sometimes. With caveats. Under specific load patterns. With the workload that vendor was selling.
The realistic claims, distilled:
- Payload size for the same data is usually smaller in Protobuf than JSON. How much smaller depends on the shape of the payload: a message that's mostly small integers and booleans gets dramatic reductions; a message that's mostly long strings gets very little, because strings dominate the byte count in both formats. A rough rule of thumb that I've seen hold up across services: Protobuf payloads are roughly half to three-quarters the size of equivalent JSON. Don't expect 10x, don't be surprised by 1.3x.
- Serialization speed in Go: Protobuf encoding/decoding via the generated code is faster than
encoding/jsonon the same struct, mostly because it skips reflection-driven type discovery. The gap is real but moderate (measured in fractions of a microsecond per message on small payloads), and it's a much bigger deal when you're decoding millions of messages per second than when you're handling a request a minute. - End-to-end RPC latency between two services on the same host or the same VPC is dominated by network round-trip, not serialization. Whether your messages are JSON or Protobuf rarely moves the P50 by more than a percentage point. What gRPC's HTTP/2 multiplexing does move is the behaviour under concurrency: many parallel RPCs over a single connection don't queue the way HTTP/1.1 does, so the tail latencies (P99, P99.9) are visibly better when traffic is bursty.
- Connection establishment is where gRPC quietly shines. HTTP/2 keeps connections alive and multiplexes across them. JSON-over-HTTP/1.1 with
Connection: close(or short keep-alive) pays a TLS handshake on every call. If your client isn't pooling connections aggressively, gRPC will look much faster, but the comparison is really "pooled long-lived HTTP/2" versus "unpooled HTTP/1.1", not "binary versus text."
The biggest performance lesson is the one nobody writes a blog post about: the protocol is rarely the bottleneck. Most slow services are slow because of a database query, a synchronous fan-out, a missing index, or a chatty client design. Switching from REST to gRPC won't fix any of those. What gRPC will do (and this is real value) is take the protocol overhead and the contract drift cost off your plate, so you can stop debugging them and start debugging actual business logic.
Pick gRPC for correctness and ergonomics first; let the performance benefits come along as a bonus.
Things that bite you the first month
A handful of papercuts to know about before you live them.
The "where do I even put the proto files" question. Two camps. Camp one: keep them inside the service repo, under api/..., generate Go into gen/..., commit the generated code. Simple, but every consuming service has to vendor or copy them. Camp two: a separate "proto" or "schemas" repo (or a Buf Schema Registry module), every service depends on it, generated code lives in language-specific packages published to your internal registry. Cleaner long-term, more setup. Pick one based on team size. For under five engineers, camp one is fine.
Generated code in version control or generated on every build? Commit it. Yes, the directory is noisy. Yes, the diff is loud. But generated code in version control means go build works on a fresh clone without a Protobuf toolchain, CI is faster, and code review can spot accidental schema breaks that the .proto diff alone hides. The teams I've seen not commit generated code spent a lot of time fighting their build system.
Loading the .proto files at runtime. Don't, unless you're building a generic gateway. Protobuf was designed for code generation, and the generated code is the fast path. Reflection-based runtime decoding exists for tools like grpcurl and is the right answer for them; it's the wrong answer for a service that handles real traffic.
TLS in production. Use it. insecure.NewCredentials() is fine on a dev laptop; it is not the right answer for a service that traverses a real network, even inside your VPC. The gRPC TLS story is straightforward: credentials.NewServerTLSFromFile on the server, credentials.NewClientTLSFromFile or credentials.NewTLS(&tls.Config{...}) on the client. The certificate handling looks the same as for any other Go HTTP server. Don't skip it because a tutorial used insecure.
Deadlines are propagated, but only if you propagate the context. A common bug: server handler receives a request with a 500ms deadline, then calls a downstream service with context.Background() instead of the request's ctx. Now the downstream call has no deadline. Always pass ctx through. Linters can catch this; contextcheck is a good one.
Errors that aren't status.Error. As mentioned earlier, returning a plain error makes the client see codes.Unknown. Wrap your domain errors at the boundary:
if errors.Is(err, ErrUserNotFound) {
return nil, status.Errorf(codes.NotFound, "user %d not found", req.GetId())
}A small helper in your service that maps error -> status.Error keeps this from sprawling.
Browser clients. If you ever need to call gRPC from a browser, you need grpc-web (a separate protocol that browsers can speak, served by Envoy or improbable-eng/grpc-web or grpc-gateway). Server streaming works in grpc-web; client streaming and bidirectional streaming do not, because of browser limitations. Plan for that constraint or keep gRPC strictly server-to-server and expose REST/JSON to the browser via a thin BFF.
The reflection bit. reflection.Register(s) lets grpcurl introspect your service's schema from a running server, which is enormously useful for local development and on-call debugging. In production, you may want to leave it off for security reasons: it tells anyone who can reach the port what RPCs exist. The compromise some teams use: register reflection only in non-prod, or behind an authenticated interceptor.
Interceptors: the middleware layer
If you've used HTTP middleware in Go, the gRPC equivalent (interceptors) will feel familiar in shape. The signatures differ for unary versus streaming, but the idea is the same: wrap each RPC with cross-cutting code for logging, auth, metrics, tracing, panic recovery.
A unary server interceptor that logs every request:
package interceptors
import (
"context"
"log/slog"
"time"
"google.golang.org/grpc"
"google.golang.org/grpc/status"
)
func UnaryLogger(logger *slog.Logger) grpc.UnaryServerInterceptor {
return func(
ctx context.Context,
req any,
info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler,
) (any, error) {
start := time.Now()
resp, err := handler(ctx, req)
code := status.Code(err)
logger.Info("grpc",
"method", info.FullMethod,
"code", code.String(),
"duration_ms", time.Since(start).Milliseconds(),
)
return resp, err
}
}Wired in at server construction:
s := grpc.NewServer(
grpc.ChainUnaryInterceptor(
interceptors.UnaryLogger(logger),
interceptors.UnaryAuth(verifier),
interceptors.UnaryRecover(),
),
)Streaming RPCs need their own interceptor (grpc.StreamServerInterceptor) because the handler sees a stream object, not a single request. The same shape applies; the wrapping is slightly more involved because you typically wrap the stream itself to intercept SendMsg/RecvMsg.
The ecosystem ships pre-built interceptors for the usual suspects (Prometheus metrics, OpenTelemetry traces, structured logging, panic recovery, JWT auth) under github.com/grpc-ecosystem/go-grpc-middleware. Reach for those before writing your own; they've been ironed out by people running gRPC at serious scale.
What this article didn't cover
A few things that genuinely matter at scale but each deserve their own deep-dive. I'm listing them so you know they're on the menu when you need them:
- Load balancing. gRPC's long-lived connection model interacts oddly with naive L4 load balancers (one connection sticks to one backend). The fixes (client-side load balancing via DNS or xDS, service mesh, or proxyless service discovery) are a whole topic.
- Authentication and authorization beyond TLS. Per-call credentials via metadata headers, mTLS, JWT verification in an interceptor, propagating identity downstream: every team builds this slightly differently.
- Observability beyond logs. Prometheus metrics via interceptors, OpenTelemetry trace propagation across services, request IDs through metadata. The patterns are well-trodden; the wiring is the work.
- Schema governance at scale. Buf Schema Registry, proto linting rules, naming conventions for packages and services, breaking-change policy across teams. Becomes the most important topic once you have ten teams sharing schemas.
- REST gateways on top of gRPC services.
grpc-gatewayor Connect can expose your gRPC services as REST/JSON automatically, generated from the same.protofiles. That's the "best of both worlds" answer for services that need both surfaces, and it deserves its own piece.
Each of those is a real article. None of them are reasons not to start gRPC today.
The honest summary
REST isn't broken. It's still the right default for browser-facing APIs, third-party integrations, anything you want to cache at the edge, anything you want to debug with curl. Don't tear it out.
But there's a band of problems where REST is genuinely the wrong tool, and that band is wider than most teams realise. Service-to-service traffic where the contract keeps drifting. Endpoints that fundamentally want to stream. Latency-sensitive internal calls that pay a connection-pool tax. Anything where two teams keep arguing about JSON field names in a doc.
For those, gRPC's pitch is real, and in Go specifically it's clean: .proto files as the source of truth, generated server and client that the compiler keeps honest, HTTP/2 multiplexing under the hood, four streaming shapes that fit goroutines as if they were designed together. The performance differences are usually smaller than the marketing claims, but the correctness and ergonomics differences are larger than the marketing claims. That's the upgrade you're actually buying.
Start small. Pick one internal service-to-service call that hurts today. Write the .proto. Generate the client. Replace the REST call. See how it feels. If it feels good, do the next one. You don't have to convert your whole stack on a Friday afternoon. And you shouldn't.
Now go write that first .proto file.





