Here's an uncomfortable claim: most of the try/catch blocks in your Node.js API are doing nothing useful. They catch, they log, they re-throw, and they make the code harder to read without making it any more reliable. Some of them are worse than nothing: they swallow bugs that should have crashed the process and turned into a clean restart.
Error handling in a Node.js API isn't about catching more errors. It's about deciding which errors you actually own, which ones you should never have caught in the first place, and what the system around your code does when something fails. That's four things: a classification, a central handler, a retry/backoff strategy for the things that should be retried, and observability that lets you see what happened after the fact.
Let's get into it.
The split that changes everything: operational vs programmer
This distinction comes from a 2014 post by Dave Pacheco at Joyent, and it's still the cleanest way to think about errors in a long-running Node process. Two categories, and you handle them in opposite ways.
Operational errors are runtime problems that a correctly-written program can encounter:
- A DNS lookup fails.
- A Postgres connection times out.
- A user posts JSON that's missing a required field.
- An upstream API returns a 503.
- Disk fills up.
These aren't bugs. They're the world being the world. Your code is supposed to deal with them: log them, return a clean 4xx/5xx, retry the ones worth retrying, surface a useful message.
Programmer errors are bugs:
- You called
user.idonundefined. - You forgot to
awaita promise and a state machine is now half-updated. - You passed the wrong type to a function.
- An assertion you wrote is now false.
These are not "the world." They're "you wrote the wrong code." And the moment one fires in production, your process is in an unknown state. The Joyent guidance, and it's aged extraordinarily well, is that the only safe response to a programmer error is to crash the process and let a supervisor restart it (PM2, systemd, Kubernetes, whatever). Trying to "recover" from an undefined is not a function keeps the broken process running and turns one bug into a cascade.
That sounds extreme until you've debugged a Node server that's been running for six hours with a corrupted in-memory cache because someone caught a TypeError and "logged it."
So the rule shakes out like this:
| Operational | Programmer | |
|---|---|---|
| Examples | timeout, validation, 503 | undefined.x, missed await, bad type |
| Handle? | Yes, explicitly | |
| Where? | At a known boundary | Nowhere; let it propagate |
| Logged as? | warn / error with context | fatal, with a stack trace |
The implication for your codebase: stop wrapping every block in try/catch. Wrap the boundaries where operational errors happen: the HTTP request handler, the database call, the external API call. Let everything else fall through.
A real AppError class (not the one from the tutorials)
Most tutorials show you a four-line AppError extends Error and stop. That's not enough for a real API. You want a class that carries enough metadata for the middleware not to need to think.
export type ErrorKind =
| 'validation' // 400
| 'unauthenticated' // 401
| 'forbidden' // 403
| 'not_found' // 404
| 'conflict' // 409
| 'rate_limited' // 429
| 'upstream' // 502
| 'unavailable' // 503
| 'internal'; // 500
const statusFor: Record<ErrorKind, number> = {
validation: 400, unauthenticated: 401, forbidden: 403,
not_found: 404, conflict: 409, rate_limited: 429,
upstream: 502, unavailable: 503, internal: 500,
};
export class AppError extends Error {
public readonly kind: ErrorKind;
public readonly status: number;
public readonly code: string;
public readonly retryable: boolean;
public readonly context: Record<string, unknown>;
public readonly cause?: unknown;
constructor(opts: {
kind: ErrorKind;
code: string;
message: string;
retryable?: boolean;
context?: Record<string, unknown>;
cause?: unknown;
}) {
super(opts.message);
this.name = 'AppError';
this.kind = opts.kind;
this.status = statusFor[opts.kind];
this.code = opts.code;
this.retryable = opts.retryable ?? (opts.kind === 'unavailable' || opts.kind === 'upstream');
this.context = opts.context ?? {};
this.cause = opts.cause;
Error.captureStackTrace?.(this, AppError);
}
isOperational(): boolean {
return true;
}
}A few things to notice:
kindis the only thing the call site has to pick. Status comes from a table. You don't have callers writingnew AppError(409, 'CONFLICT', ...)and getting the number wrong.codeis a stable string likeUSER_EMAIL_TAKEN. Clients can switch on it.kindis for HTTP;codeis for product logic.retryableis a hint that propagates outward: if this error reaches an upstream caller, they know whether to retry. Don't make every caller re-derive that.causeis the ES2022causechain. Use it. Wrapping a Postgres error as anAppErrorwithout keeping the original loses you debugging time.isOperational()is the marker the centralized handler keys off. Anything that doesn't answer true to that question is treated as a programmer error.
The whole point of this class is that the middleware never has to interpret an error. It just reads fields.
The centralized middleware (and the bit nobody shows you)
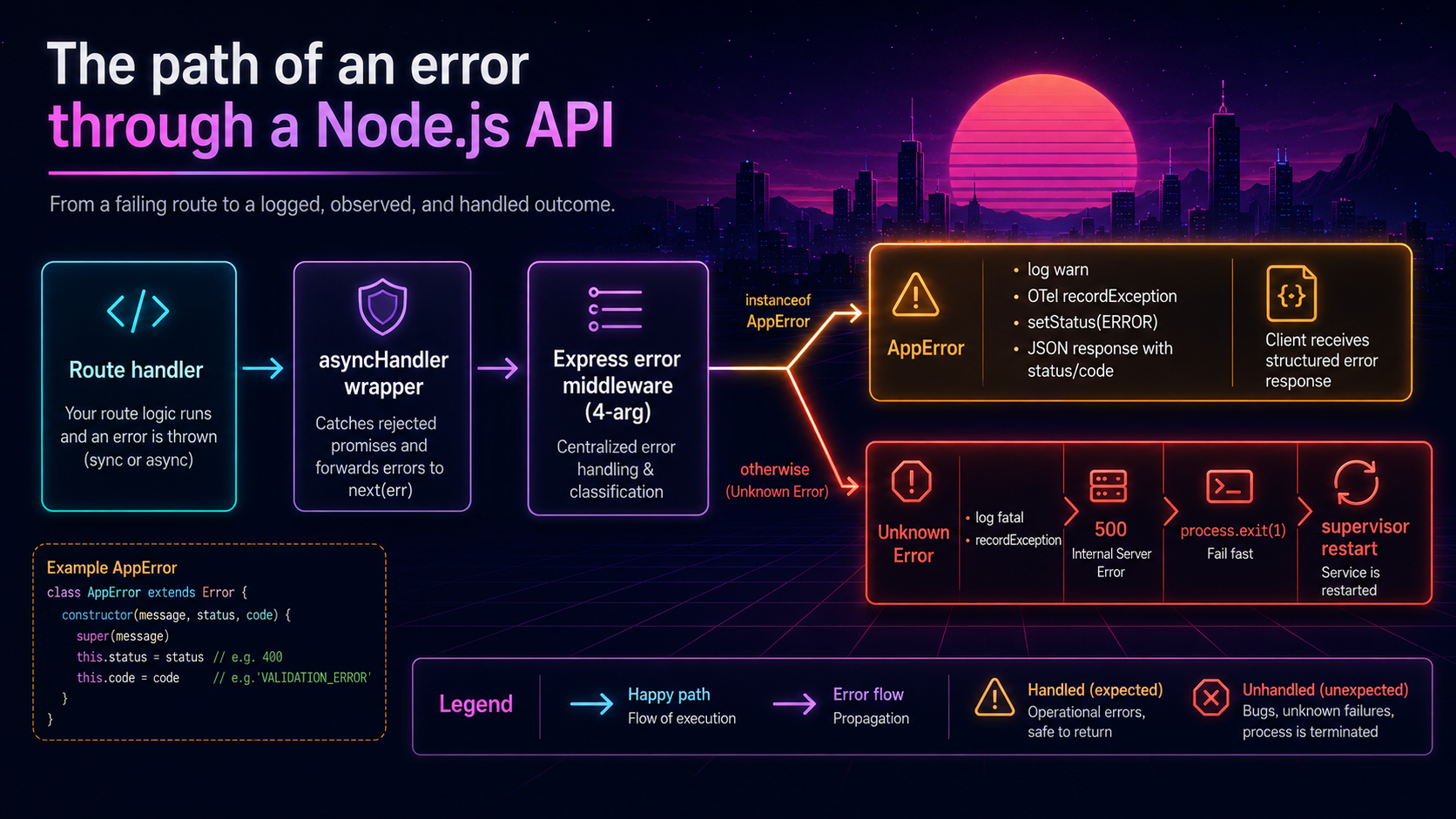
Here's the Express handler, in one piece. Note the four-argument signature. That's what tells Express it's an error handler, not a regular middleware. Get the argument count wrong and Express will silently treat it as normal middleware and your error path is dead. This is one of the most common bugs in Express apps.
import type { ErrorRequestHandler } from 'express';
import { AppError } from '../errors/AppError';
import { logger } from '../observability/logger';
import { context, trace, SpanStatusCode } from '@opentelemetry/api';
export const errorHandler: ErrorRequestHandler = (err, req, res, _next) => {
const span = trace.getSpan(context.active());
if (err instanceof AppError) {
span?.setAttribute('error.kind', err.kind);
span?.setAttribute('error.code', err.code);
span?.setStatus({ code: SpanStatusCode.ERROR, message: err.code });
span?.recordException(err);
logger.warn({
err, code: err.code, kind: err.kind, ctx: err.context,
requestId: req.id, path: req.path,
}, 'operational error');
res.status(err.status).json({
error: {
code: err.code,
message: err.message,
kind: err.kind,
},
});
return;
}
// Anything reaching here is a programmer error. Treat it as fatal.
span?.setStatus({ code: SpanStatusCode.ERROR, message: 'programmer_error' });
span?.recordException(err as Error);
logger.fatal({ err, requestId: req.id, path: req.path }, 'programmer error — crashing');
res.status(500).json({ error: { code: 'INTERNAL', message: 'Internal Server Error' } });
// Let the supervisor restart us. Flush logs first if you can.
setImmediate(() => process.exit(1));
};The line that surprises people is process.exit(1) at the end. "You're crashing the server because one user got a 500?" Yes, because by definition, you got here because something the application doesn't understand happened, and the process is in an undefined state. Letting it limp on is how you get the six-hour-corrupted-cache outage from earlier.
If setImmediate(() => process.exit(1)) feels too aggressive, the middle ground is: serve the 500, stop accepting new connections, finish in-flight requests, then exit. That's what process.exitCode = 1 plus closing the HTTP server gives you. Either way, the process dies, and the supervisor (PM2, Kubernetes, systemd) starts a fresh one with a clean heap.
A note on the OpenTelemetry calls: recordException adds a span event named exactly "exception" (that's a hard requirement in the OTel spec) with the error's stack and message as attributes, and setStatus({ code: ERROR }) marks the span as failed so backends like Jaeger, Tempo, or Honeycomb light it up red. You want both. recordException alone leaves the span green, and setStatus alone hides the stack.
The async problem nobody warns you about
You wrote your handlers as async. Then you wrote your tests. Then in production, an unhandled rejection in a route handler... didn't trigger your middleware. Express 4 doesn't catch rejected promises in handlers. You have to forward them yourself. Express 5 fixes this, but most production apps you'll touch are still on 4.
The classic wrapper:
import type { RequestHandler } from 'express';
export const ah = (fn: RequestHandler): RequestHandler =>
(req, res, next) => {
Promise.resolve(fn(req, res, next)).catch(next);
};
// usage
app.get('/users/:id', ah(async (req, res) => {
const user = await users.findById(req.params.id);
if (!user) throw new AppError({ kind: 'not_found', code: 'USER_NOT_FOUND', message: 'No such user' });
res.json(user);
}));That's it. Three lines, and your async errors now flow into the middleware. Forget this wrapper exactly once and you'll spend an afternoon hunting a "silent 503" that's really an uncaught rejection mid-handler.
Fastify users get this for free: Fastify awaits async handlers and pipes rejections into its error handler. NestJS users get it via the framework's exception filter. The wrapper above is Express-4-specific tax.
There's also a process-level safety net for anything you miss:
process.on('unhandledRejection', (reason) => {
logger.fatal({ err: reason }, 'unhandledRejection — crashing');
process.exit(1);
});
process.on('uncaughtException', (err) => {
logger.fatal({ err }, 'uncaughtException — crashing');
process.exit(1);
});Same rule: log, exit, let the supervisor restart. Don't try to be clever.
Request context without prop-drilling
You want every log line and every error to carry the request ID, the user ID, the route, and probably the tenant. You do not want to thread these through every function call. Node has had AsyncLocalStorage since v13, and it's the right tool: it's what NestJS, Fastify hooks, and the OpenTelemetry SDK all use under the hood.
import { AsyncLocalStorage } from 'async_hooks';
import { randomUUID } from 'crypto';
type ReqCtx = { requestId: string; userId?: string; route?: string };
const als = new AsyncLocalStorage<ReqCtx>();
export const requestContext = {
run<T>(ctx: ReqCtx, fn: () => T): T {
return als.run(ctx, fn);
},
get(): ReqCtx | undefined {
return als.getStore();
},
set<K extends keyof ReqCtx>(key: K, value: ReqCtx[K]) {
const store = als.getStore();
if (store) store[key] = value;
},
};
export const requestContextMw: import('express').RequestHandler = (req, _res, next) => {
const requestId = (req.header('x-request-id') ?? randomUUID()) as string;
requestContext.run({ requestId, route: req.path }, () => next());
};Now anywhere in your call tree, three calls deep in a service, inside a database adapter, inside a Kafka producer, you can pull the request ID and stamp it on a log line or an outbound header. No more passing requestId as a parameter to getUserById.
The footgun: if you setTimeout or setImmediate inside the request, the context follows you. If you stash a callback for later execution outside the request (e.g., on a long-lived event emitter), it does not. The store was tied to that request's async chain. This matches how async_hooks tracks context, but it'll catch you the first time you try to use ALS to "attach the user" to a background queue.
Retries: the part where people make it worse
A retry without a backoff is a denial-of-service attack on your dependency. A retry without jitter is a denial-of-service attack on your dependency that synchronizes across your fleet. A retry on something non-idempotent is a bug-generation machine. Three rules, in order, and they all matter.
Rule 1: only retry idempotent operations. A GET is idempotent. A PUT /users/123 is idempotent. A POST /payments is not: retrying a charge that maybe-succeeded-maybe-failed is how you bill a customer twice. If you need to make a non-idempotent operation retry-safe, you make it idempotent yourself: the caller generates an idempotency key (UUID), the server records "I processed this key" durably before responding, and a retry with the same key returns the original result instead of re-executing.
Rule 2: exponential backoff with jitter. Doubling delays (100ms, 200ms, 400ms, 800ms, ...) keeps you from hammering a struggling service. But if a thousand clients all hit the same outage at the same second, doubling delays means they all retry together at t+100ms, then together at t+300ms, and so on. That's the thundering herd. Jitter randomizes the delay so they spread out. AWS's "Exponential Backoff and Jitter" post made the case for full jitter (delay = random(0, base * 2^attempt)) and decorrelated jitter (delay = random(base, prev_delay * 3)) over a decade ago, and they're still the right defaults.
Rule 3: have a hard ceiling. Three retries is plenty for most things. Five is the upper end. "Retry until success" is what people write when they don't want to think; it's also what turns a 30-second outage into a stampede when the dependency comes back.
The library worth knowing here is cockatiel. It's the resilience library the VS Code team uses, and its API composes nicely. The default jitter generator is decorrelated jitter, which matches the AWS post.
import { retry, handleAll, ExponentialBackoff, ConsecutiveBreaker, circuitBreaker, wrap } from 'cockatiel';
const retryPolicy = retry(handleAll, {
maxAttempts: 3,
backoff: new ExponentialBackoff(),
});
const breakerPolicy = circuitBreaker(handleAll, {
halfOpenAfter: 10_000,
breaker: new ConsecutiveBreaker(5),
});
const resilient = wrap(retryPolicy, breakerPolicy);
export async function fetchUserFromUpstream(id: string) {
return resilient.execute(async ({ signal }) => {
const res = await fetch(`https://accounts.internal/users/${id}`, { signal });
if (res.status >= 500) {
throw new AppError({
kind: 'upstream', code: 'ACCOUNTS_5XX',
message: `accounts upstream returned ${res.status}`,
retryable: true,
});
}
if (!res.ok) {
throw new AppError({
kind: 'not_found', code: 'ACCOUNTS_NOT_FOUND',
message: 'upstream rejected', retryable: false,
});
}
return res.json();
});
}A 4xx that isn't a 429 should not be retried: retrying a 400 just gets you another 400 and wastes time. The retryable flag on AppError encodes that decision once, at the boundary where you know what the status code meant. Cockatiel can be told to only retry specific errors via handleType instead of handleAll: pair that with retryable and you get an explicit, auditable retry policy.
Circuit breakers: the thing that keeps your timeouts from killing you
Imagine your /checkout endpoint calls a fraud service. The fraud service goes down. Every checkout request now waits 10 seconds for a timeout, fails, retries three times (another 30 seconds), and finally fails the request. Your Node event loop is now backed up with thousands of in-flight checkouts holding sockets and memory. Your /checkout latency goes from 200ms to 40 seconds for every request, including the ones that don't need fraud service. The fraud service is the only thing broken, but it's pulling your whole API down.
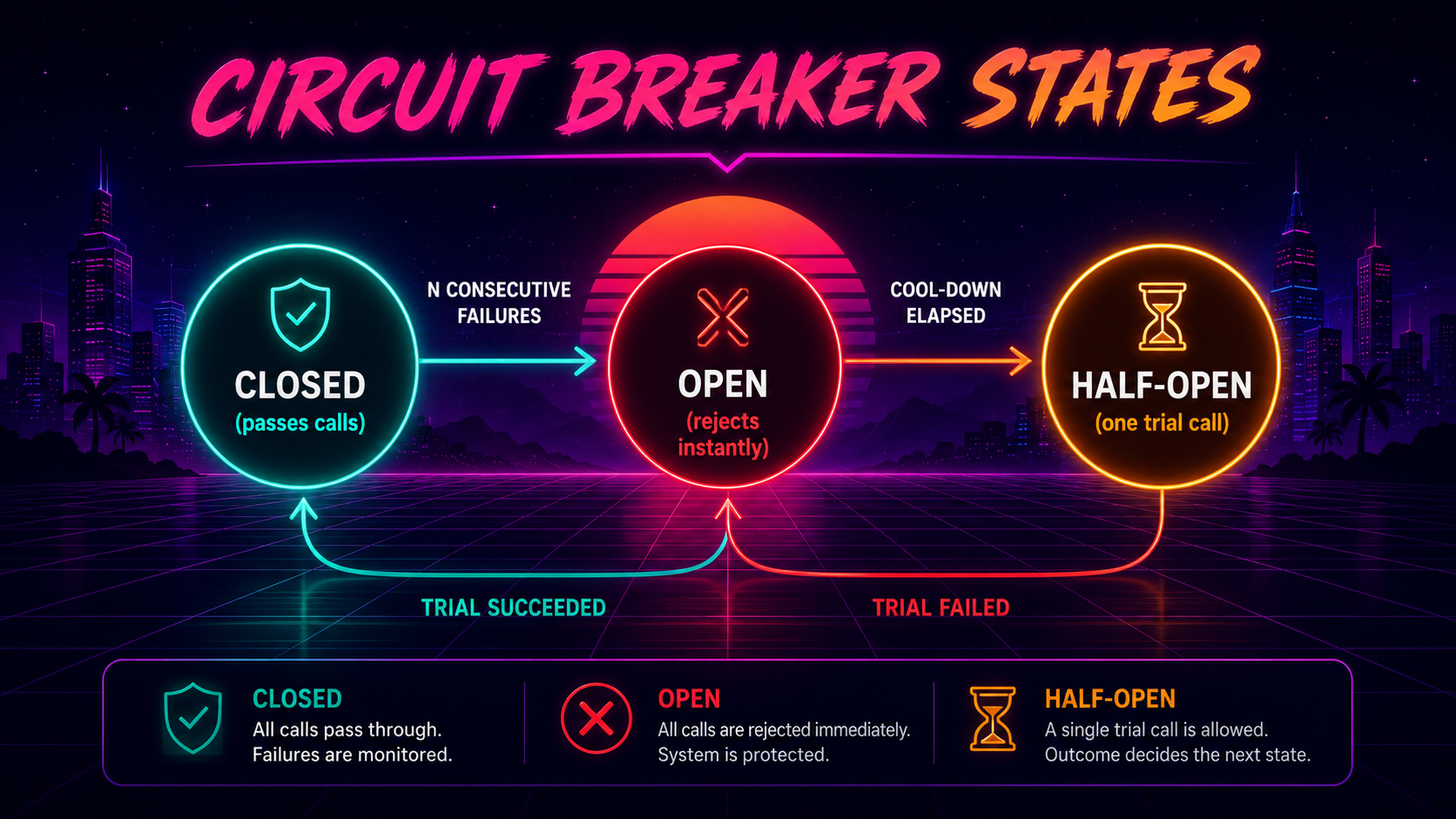
A circuit breaker stops this. After N consecutive failures, the breaker "opens": subsequent calls fail immediately without touching the network. After a cool-down, the breaker goes "half-open" and lets one trial request through. If it succeeds, the breaker closes; if it fails, the breaker stays open for another cool-down.
That's what circuitBreaker does in the cockatiel example above. The two well-known Node libraries here are cockatiel and opossum (formerly from Red Hat / nodeshift). Opossum is mature, has built-in stats, and is widely used; cockatiel is more composable and uses decorrelated jitter as the default backoff. Either is a serious choice; what matters is that one of them is in your codebase in front of every cross-network call.
The gotcha: if the breaker is open, callers see a different error than "upstream failed." They see "breaker open." Map that to an AppError with kind: 'unavailable' and a clear code (UPSTREAM_BREAKER_OPEN) so your logs distinguish "we tried and the dependency said no" from "we didn't try, by policy." Both produce 503s; only one is genuine signal about the dependency.
Timeouts: the cheapest reliability win you're not using
Here's a one-line audit of your codebase: grep for fetch( and axios. and see how many have a timeout. If the answer is "less than 100%," you have a problem. Network calls without timeouts hang forever; "forever" eventually means a process running out of file descriptors and dying in a way that's much harder to debug than a clean timeout error.
Node 18+ has AbortSignal.timeout(ms) built in:
const res = await fetch(url, { signal: AbortSignal.timeout(2_000) });For databases, the timeout setting depends on the driver: statement_timeout on Postgres (set per-connection or per-query), connectTimeout on mysql2, socketTimeoutMS on the MongoDB driver. Pick numbers slightly shorter than your upstream's timeout, so you fail fast before the caller gives up on you. If your API has a 5-second SLA, your database query shouldn't be allowed to run for 10.
Combined with the retry/breaker pattern: timeout → retry → breaker opens. Each layer protects the one above it.
Observability: errors are data, not strings
A log line that says Error: failed to fetch user is useless. A log line that says { kind: 'upstream', code: 'ACCOUNTS_5XX', requestId: 'r-9f...', userId: 'u-123', upstreamStatus: 503, latencyMs: 4837, attempt: 3, retryable: true } lets you ask questions: how many of these in the last hour, on which route, for which tenant, with what status, after how long.
That means:
- Structured logging only. Pino is the de facto choice in Node: fast, JSON output, child loggers for context. Bunyan and Winston work too. The point is that every log line is a JSON object, never a printf string. Greppable structured fields beat free-text every time.
- Every error becomes a span event.
span.recordException(err)andspan.setStatus({ code: SpanStatusCode.ERROR }). The OTel spec requires the event to be named"exception", so any backend (Jaeger, Tempo, Honeycomb, Datadog, New Relic) can find errors uniformly. - Custom attributes on the span.
error.kind,error.code,user.tenant, whatever's load-bearing for your product. These are queryable in your tracing backend. - Sampling errors at 100%. Whatever your normal sampling rate, sample error spans at 100%. Tail-based sampling in the OTel Collector (using the
tail_samplingprocessor) is the standard way to do this: you keep every trace that contains an error, drop most of the rest. - One metric for "error rate by kind." Not "errors per second": that mixes 404s with 503s and you can't tell what's happening.
errors_total{kind="upstream"},errors_total{kind="validation"}, etc. Then your alerts can target the kinds that actually matter (upstream and unavailable usually wake people up; validation almost never should).
The thing this gives you on a bad day: you get paged, you open the dashboard, you see errors_total{kind="upstream", code="ACCOUNTS_5XX"} is up 80x in the last 10 minutes. You drill into a trace, you see recordException on a span called fetchUserFromUpstream, you see the breaker is open. Time to first useful insight: about 30 seconds, instead of 30 minutes of grepping logs.
What "good" looks like in one diagram
Put it all together and a request through the system looks like this:
HTTP request
│
├─ requestContextMw (ALS sets requestId, route)
├─ tracing middleware (OTel starts root span)
├─ auth middleware (may throw AppError(kind: 'unauthenticated'))
├─ route handler (wrapped in ah())
│ │
│ ├─ db.query(... statement_timeout: 2s ...)
│ ├─ resilient.execute(fetchUserFromUpstream)
│ │ ├─ timeout (AbortSignal.timeout)
│ │ ├─ retry (exponential + decorrelated jitter, max 3)
│ │ └─ breaker (5 consecutive fails → open for 10s)
│ │
│ └─ throws AppError | returns
│
└─ errorHandler (4-arg)
├─ AppError → log warn, OTel error event, JSON response with code/kind
└─ anything else → log fatal, OTel error event, 500, process.exit(1)Every box on that diagram exists for a reason that came up in production at some company at some point. None of it is optional once you're past the toy stage.
A few things that look smart but aren't
A handful of patterns that show up constantly and quietly make things worse:
catch (e) { throw e; }: does literally nothing except lose you the original stack trace if you forgot to set it. Delete.
catch (e) { console.log(e); }: swallows the error, lets the function return undefined (or whatever the post-catch path produces), and leaves you debugging in production from a log line with no context. If you must catch, decide what the function returns and document it.
Generic 500 messages that include the error message. { error: err.message } leaks SQL queries, internal hostnames, and stack fragments to clients. The internal code and kind are safe to expose; raw upstream messages aren't.
Retrying inside the handler and at the API gateway and at the client. Three layers of "I'll retry three times" means a single failure can produce 27 actual requests. Pick one layer to own retries (usually the one closest to the dependency, where you can see the actual failure mode) and turn it off everywhere else.
if (err.message.includes('timeout')): error-message-matching is a string-parsing exercise that breaks the moment a library updates its phrasing. Match on err.code, err.name, or instanceof checks. If the underlying library doesn't expose those, wrap it in a thin adapter that does.
Sentry / Bugsnag / Datadog APM doing the same job as your OTel pipeline. Double-instrumentation doubles your overhead, doubles your bill, and gives you two slightly different views of the same incident. Pick one. Sentry-style error tracking and OTel tracing aren't the same thing functionally, but they overlap enough that you should be deliberate about which pieces of data each one owns.
The shortest possible summary
Classify errors. Centralize the handler. Crash on programmer errors. Wrap your async handlers. Use AsyncLocalStorage for request context. Time out every network call. Retry only what's idempotent, with exponential backoff and jitter, with a ceiling. Put a circuit breaker in front of every cross-network dependency. Record every error as a span event with structured attributes. Sample errors at 100%.
Most outages aren't caused by code that "doesn't handle errors." They're caused by code that handles them in ways that look careful (broad try/catch, silent retries, generic 500s) and quietly turn small problems into big ones. The patterns above are the opposite of that: each one says "here is exactly what we do in this situation, and nothing else."