
You open a pull request. Thirty seconds later, an AI reviewer drops a comment: "Looks good to me. No issues found."
You feel a tiny chemical reward. Approval. Speed. You're one click closer to merging. The cognitive cost of waiting for a human reviewer just got compressed into half a minute, and the diff you spent two hours wrestling with is now blessed by a system that has read more code than any single engineer alive.
Then a week later, the same code ships a subtle authorization bug to production, and you're staring at an incident channel wondering how that "Looks good to me" survived a real review.
This is the question that follows every AI code reviewer around like a shadow. Is it a helpful assistant - a faster, calmer, more patient version of the senior engineer who used to leave you twelve comments before lunch? Or is it a false confidence machine - a tool that says reassuring things about code it doesn't fully understand, and convinces you to merge anyway?
The honest answer is both, and which one you get depends almost entirely on how you set up the workflow around it. Let's break down the four angles that actually matter - what these reviewers catch well, where they fail on correctness, where they fail on security, where they make things up, and how to design a review process that gets the upside without buying the downside.
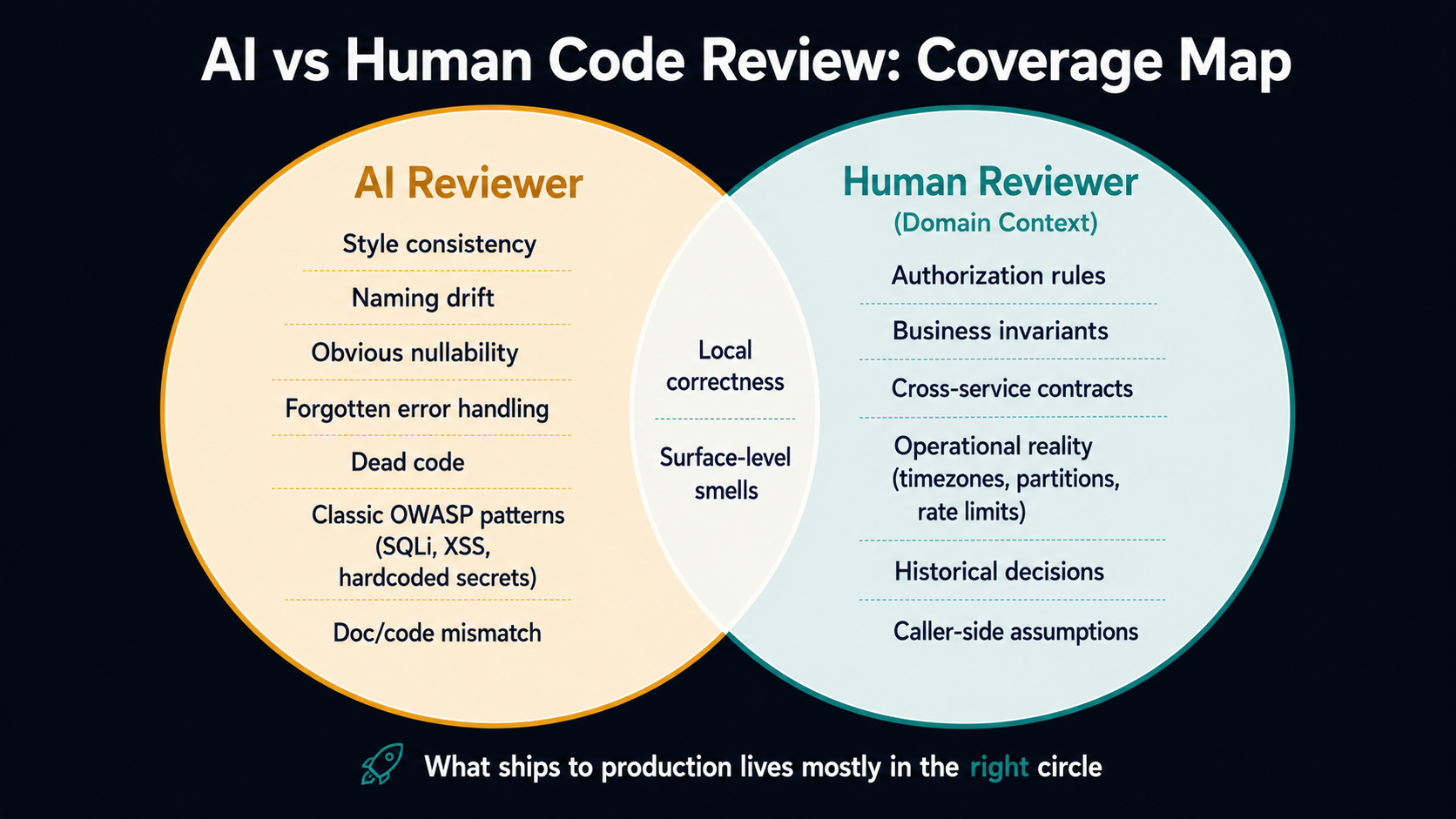
What AI Code Review Is Actually Good At
Before we pile on the failure modes, it's worth being fair about what these tools do well - because most teams hire them for the right reasons and then forget what those reasons were.
AI reviewers are excellent at the surface layer of code review. The kind of comments that good engineers stop making out loud because they got tired of writing them but still wish someone would catch:
- Inconsistent naming inside the same diff. You called it
userIdin one function anduser_idin the next. - Style drift. A trailing comma here, a missing one there, a callback where the rest of the file uses async/await.
- Obvious nullability holes. You destructured
response.data.usertwo lines after atryblock that could returnundefined. - Forgotten error handling. The new endpoint catches the database error but swallows the auth error two lines below.
- Dead code, unused variables, imports that no longer point at anything.
- Documentation that contradicts the function it's documenting because the signature changed and the JSDoc didn't.
These comments aren't glamorous, but they used to consume real review bandwidth from senior engineers. Pushing them onto a tool that doesn't get tired, doesn't get cranky, and doesn't write "as I've mentioned in the last four reviews..." in the comment thread is a clear win.
The second thing AI reviewers are good at is mechanical pattern matching against well-known antipatterns. The same patterns that have been on the OWASP Top 10 for fifteen years. The same patterns that have been in every senior interview question for ten years. The same patterns that show up in a thousand training-set blog posts.
If you write a SQL query by concatenating a string with req.query.user, an AI reviewer is going to spot it. If you skip CSRF protection on a state-changing endpoint, it'll spot it. If you log a raw password, it'll spot it. If you commit a JWT secret, it'll spot it.
What both of these categories have in common is that the code reveals the problem. The function looks suspicious. The diff is the evidence. The reviewer doesn't need to know what your system does - it only needs to read the lines you handed it.
This is the half of code review that AI is genuinely changing. And if your team treats AI review as exactly this much and no more, you'll get a real productivity win with very little risk.
The problem starts the moment you start expecting it to do the other half.
The Other Half: Correctness, Intent, And Where Bugs Actually Live
Real bugs almost never live in the code you can see in the diff. They live in the relationship between the code in the diff and the rest of the system.
Think about the last few real bugs your team shipped. Walk through them. How many of them were caught by:
- A reviewer noticing that the new endpoint duplicated logic from another endpoint, and now both versions disagreed?
- A reviewer remembering that the field
account.statuscould bepending_reviewonly in tenants migrated before 2022, and the new code didn't handle that case? - A reviewer realizing that the new background job ran every five minutes, but the table it queried got partitioned by date last quarter, and the query was about to start scanning the entire archive partition?
- A reviewer noticing that the new logic was correct in isolation, but the caller already did the same check three frames up, and now the count was off by one?
None of those bugs are visible in the diff. The diff looks fine. The diff is fine, locally. The bug lives in the conversation between the diff and everything outside it - the other twenty thousand lines of your codebase, the migration that ran two years ago, the operational reality of how the system runs in production.
This is where AI code review hits its hardest ceiling, and it's worth being precise about why. It's not that the model is bad. It's that the information needed to catch the bug isn't in the prompt. The reviewer is reading the diff. It might be reading the surrounding file. It might even be reading some retrieved chunks of your codebase. But it isn't reading:
- The Slack thread from two years ago where the team decided that all auth checks happen at the middleware layer, not the controller.
- The runbook that says this service runs in three regions and the new code's assumption of a single timezone breaks two of them.
- The product manager's verbal decision that "soft delete" means hidden-from-list-but-still-billable, not gone.
- The unwritten rule that any
for awaitin this codebase needs a concurrency limit because the database connection pool is sized for ten.
A senior reviewer who's worked on your team for two years catches these because the system lives in their head. The AI catches them only if some surface artifact of those decisions made it into the code or into the context window. Most of the time, none of it did.
The failure mode here isn't wrong feedback. It's confident absent feedback. The AI reviewer doesn't flag the bug because it doesn't see the bug. And worse, it tells you "no issues found", which sounds like an affirmative review, not an admission of partial coverage. A human who didn't know the codebase well would at least hesitate. A model doesn't hesitate. That's the false confidence.
The fix isn't to expect the model to do more. It's to stop treating its silence as evidence.
Security Review Is The Sharpest Edge Of This Problem
Security is where the gap between "what looks suspicious in the diff" and "what's actually exploitable" gets the widest, the fastest.
Consider three diffs:
@app.route("/users/<user_id>")
def get_user(user_id):
query = f"SELECT * FROM users WHERE id = {user_id}"
return db.execute(query).fetchone()This is a SQL injection. Every AI reviewer alive will catch it. It's in the training data of every model from every era. It's also unlikely to ship in any team that has any review at all.
@app.route("/users/<user_id>")
@authenticated
def get_user(user_id):
user = db.users.find_one({"id": user_id})
return user.to_dict()This looks clean. There's an @authenticated decorator. The query is parameterized. The return is structured. An AI reviewer reads this and says "looks good" - and on the surface, it does.
But this might be an Insecure Direct Object Reference (IDOR) vulnerability. There's no check that the authenticated user is allowed to fetch this particular user_id. Anyone who's logged in can read anyone else's profile.
The model can't catch this without knowing the intent of your authorization model. Does your system let authenticated users read all other users? Maybe - it's a social app. Or maybe not - it's a healthcare app and each user can only read themselves and their dependents. The diff doesn't say which. The reviewer doesn't know which. So it defaults to a comfortable answer, which is silence.
@app.route("/teams/<team_id>/invite", methods=["POST"])
@authenticated
def invite_member(team_id):
email = request.json["email"]
team = db.teams.find_one({"id": team_id})
team.invite(email)
return {"ok": True}Same shape, harder to spot. Even if the model checks for the user's authorization to act on team_id, it might miss that request.json["email"] is not validated, that the same endpoint can be used to enumerate which emails are already members based on the response shape, that the rate limit on this endpoint is missing because the team's existing pattern is to put rate limits on the gateway and this new endpoint is registered through a different path. None of that is visible in the eight lines you can see.
This pattern repeats across every security category. Authorization bugs depend on the rules of your domain. Race conditions depend on the concurrency model your runtime actually uses in production. Cryptographic mistakes depend on which threat model you've accepted. Secrets handling depends on which systems the data flows through after this code returns. None of it is in the diff. All of it is in your team's head.
The AI reviewer is genuinely useful as a first pass on security - it'll catch the patterns that match the training data, the OWASP-shaped problems, the obvious dumb stuff. The danger is treating that first pass as a security review. It isn't. Real security review needs someone who knows what your application is for, what data it holds, who's allowed to do what, and what an attacker would actually want.
The Hallucination Problem In Review Specifically
Hallucination in code generation is a known and well-discussed failure mode. Models invent function names, package versions, config flags, API endpoints. You've probably watched a model confidently import a module that doesn't exist.
What's less discussed is what hallucination looks like in code review. The shape is different - and arguably more dangerous - because the model isn't writing code you'll run. It's making assertions you'll act on.
A reviewing model can hallucinate in three distinct ways, and each one bites a different way.
Phantom references. The reviewer comments: "This is similar to the pattern in src/auth/middleware.py where we already handle this case." You open src/auth/middleware.py. There is no such pattern. There might not even be a file at that path. The model invented a plausible reference because that's what its training distribution rewards.
You can spot this one if you check, but the dangerous version is when the reference is almost real - the file exists, the function name is close but slightly wrong, the pattern is similar but not identical. You scan it, decide "yeah, that looks consistent", and merge. The reviewer has just convinced you of a fact that isn't quite true.
Phantom guarantees. The reviewer comments: "The framework handles input validation for you here, so you don't need to add it explicitly." Sometimes this is true. Sometimes the framework has some validation but not the kind that matters for this endpoint. Sometimes the framework had this feature in v3 and you're on v5 and they removed it. Sometimes the framework never had it and the model is mixing it up with a different framework's docs.
You're now relying on an assertion about a system you didn't verify. The diff didn't change. The vulnerability is now live, and the reasoning that justified shipping it is a sentence that sounded confident in a review thread.
Phantom approvals. The reviewer reads the diff, doesn't understand a chunk of it, and chooses safety: it says nothing about that chunk, and says positive things about the parts it does understand. The overall summary lands as "looks good". You read the summary. You don't notice that the most complex part of the diff was never actually addressed.
This is the quietest failure mode and the easiest to miss. The reviewer didn't say anything wrong. It just didn't say anything about the part that mattered. And because there's no visual indicator of "I read this and have no comment" vs "I didn't really understand this and have no comment", you can't tell the difference.
The defence against all three is the same and it's old-fashioned: don't trust assertions. When the AI reviewer references a file, open the file. When it claims the framework does X, find the docs. When the diff has a tricky section and the AI didn't comment on it, that's a signal, not a relief.
This is the discipline that turns AI review from a confidence machine into a useful one. The model is allowed to say things you'd never have noticed. It's not allowed to be the last layer of trust on anything that matters.
Designing A Review Workflow That Actually Works
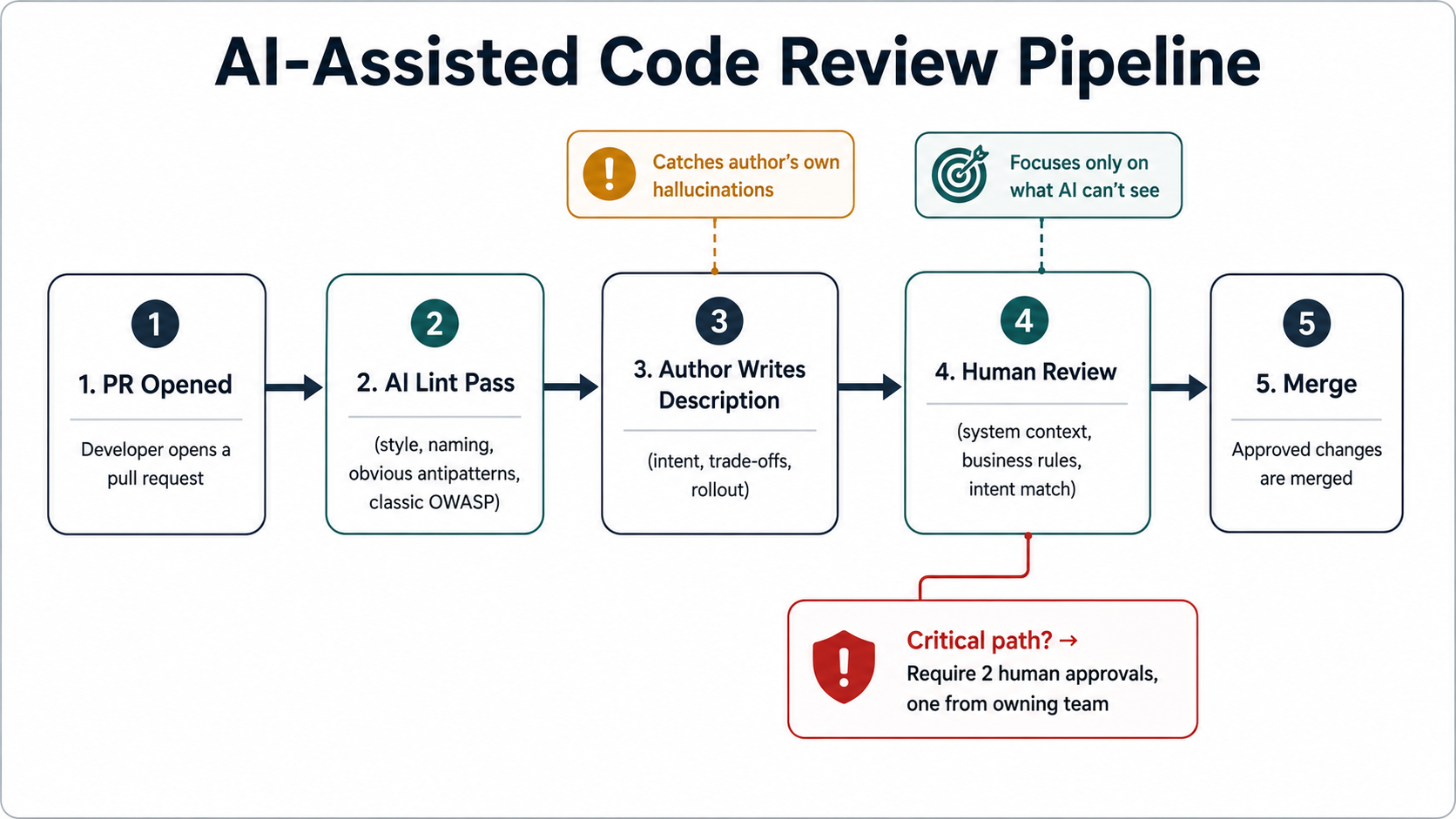
Once you accept that AI review is great at one half of the job and structurally incapable of the other half, the workflow design becomes obvious. You arrange the two halves in series, not in parallel, and you give each one the job it can actually do.
Here's the shape of a workflow that gets the upside.
Step 1 - AI reviewer runs first, as a lint pass. The moment a pull request opens, the AI reviewer sweeps it. It flags style issues, naming inconsistencies, obvious antipatterns, classic security patterns, missing error handling, contradictory documentation. It posts these as inline comments on the diff, the same way a linter would.
The author addresses these before any human reviewer is paged. This is the whole productivity win - the senior engineer never has to write "please use the existing util for this" again. The boring layer is done. The author shows up to human review with a diff that's already past the obvious objections.
Step 2 - Author writes the description that the AI didn't. This is the step that gets cut and shouldn't. The AI is reviewing the code. The human reviewer needs to review the change. A change is the code plus the intent plus the constraints plus the trade-offs the author made.
The author writes - in plain English - what this change does, why now, what alternatives they considered, what the rollout plan is, what they're explicitly not trying to solve. If you've never read Tigran Sloyan's or Will Larson's writing on this, the short version is: a PR description is for the next person who reads the commit in three years, not for you today.
A good description here is also the thing that catches the author's own hallucinations. If you can't explain in two paragraphs why this change is correct, you've found the actual problem.
Step 3 - Human reviewer focuses on what the AI can't see. With the lint layer handled and the description written, the human reviewer's attention can land on the real questions:
- Does this change match what we agreed to build?
- Does it interact correctly with the rest of the system?
- Are the security invariants of this product preserved, given who the users are and what data they hold?
- Is this the right unit of change to ship, or should it be split, sequenced, or guarded behind a feature flag?
- What are we not going to be able to undo after this merges?
These are the questions that need a person who knows the codebase and the product. They're the questions you wanted the AI to handle and it can't.
Step 4 - Critical paths get an explicit "AI didn't review this" gate. Any change to authentication, authorization, payments, data deletion, migrations, or anything else where the worst-case outcome is "the company gets fined or sued" carries a flag in your review template: "This change touches a critical path. AI review is not sufficient. Require N human approvals with one being from
This isn't because the AI's review is wrong on critical paths. It might be perfectly fine. It's because the cost of being wrong is asymmetric, and you don't let asymmetric risks ride on confidence-shaped reassurance.
Step 5 - Treat AI review output as evidence, not verdict. When the AI says "no issues found", that is not a green light. It's an absence of red flags from a system that can only see a fraction of them. Your team's mental model of an AI review needs to be: "the obvious problems are probably caught; the subtle ones are not addressed either way". The decision to merge still belongs to a human and a passing test suite.
This shape works. It doesn't deliver the "agents review your PRs and you ship faster forever" narrative - but it delivers something better, which is fewer comments your senior engineers hate writing and more attention on the parts of review that actually prevent incidents.
What This Means For The Senior Engineer
If you're a senior engineer reading this, the practical shift is small and worth doing deliberately.
You're not going to stop using AI reviewers - they're too useful at the lint layer to give up. But you're going to stop deferring to them on anything that matters. When the AI says "looks good", you're going to read it as "the cheap problems aren't here, what about the expensive ones". When the AI references something in the codebase, you're going to confirm it. When the AI gives you a confident-sounding explanation, you're going to ask the question "how would I know this was wrong?" before you accept it.
You're also going to write better PR descriptions, because once the AI handles the lint layer, the bottleneck in review moves to the human reviewer's ability to understand the change. That's a writing problem, not a coding problem, and it's the one part of code review that has gotten more important since AI showed up, not less.
And you're going to push back when leadership says "we have AI review now, we can have fewer humans on it". The answer is no, and the reason isn't sentiment - it's that the half of the job AI doesn't do is the half where the bugs that cost real money live. You'd rather have one AI reviewer plus a careful senior than two AI reviewers and a fast merge button.
The question in the title of this piece - assistant or false confidence machine - isn't really about the tool. It's about the team. The same model, in the same codebase, on the same diff, is one or the other depending on whether a human is treating its output as evidence or as a verdict.
If you remember anything from this, remember that distinction. AI review is evidence. Humans make the verdict. The day you flip those two roles is the day your incident channel gets a lot louder.





