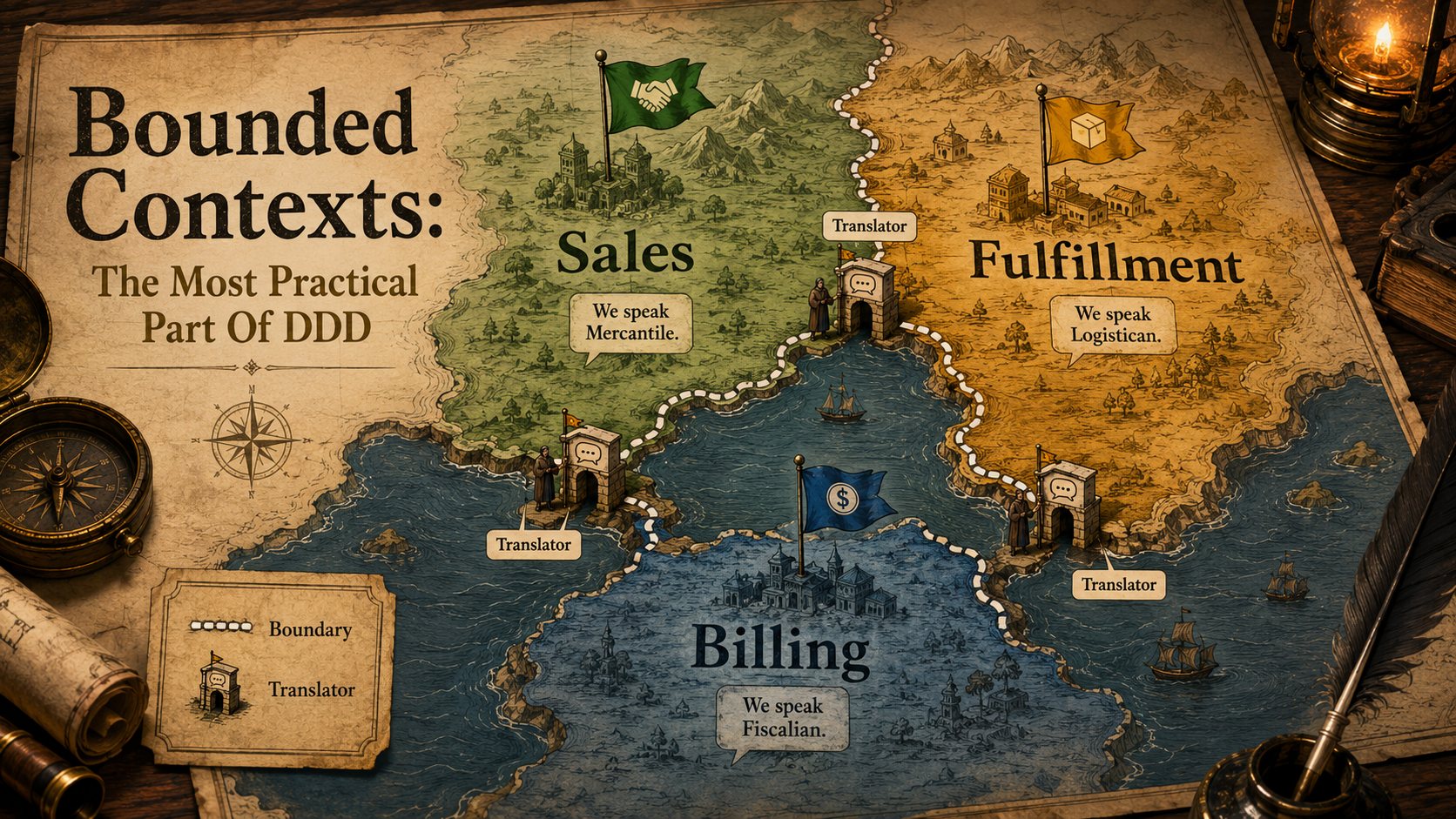
So, you've been in this meeting before.
Sales says "the customer just needs to confirm the address." Support says "the customer hasn't replied to the ticket in four days." Billing says "the customer's last invoice failed and we should pause shipments." Three people, one word, three completely different things, and every one of them is right inside their own world.
That's the moment bounded contexts start to make sense. Not as theory. As survival.
Most of Domain-Driven Design has a reputation for being heavy. You hear "DDD" and picture the blue book, three months of event storming workshops, and a senior architect drawing hexagons on a whiteboard while you try to ship a feature. But there's one piece, one, that pays for itself almost immediately, in any codebase, regardless of whether you ever touch the rest of DDD.
It's the bounded context. And if you only ever take one strategic pattern from DDD into your day job, take this one.
So, What Is A Bounded Context?
A bounded context is a part of your system where one model and one set of words have a clear, consistent meaning.
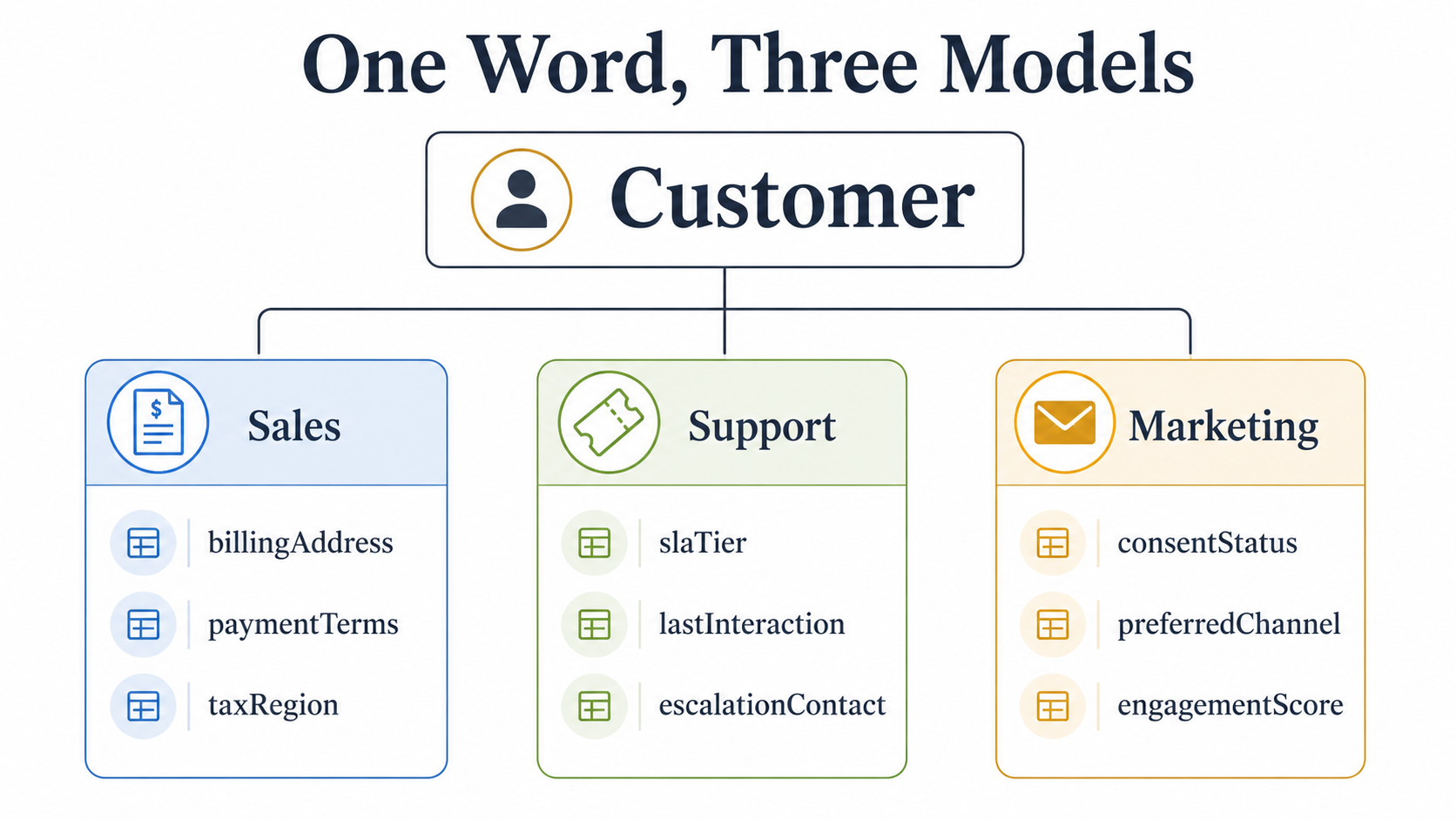
Inside that boundary, "Customer" means one specific thing. Let's say, "a person we send invoices to." It has fields like billingAddress, paymentTerms, taxRegion. Outside the boundary, "Customer" can mean something else entirely. In the Support world, the same person is "a contact who can open tickets" with fields like slaTier, lastInteraction, escalationContact. In the Marketing world, they're "a recipient" with consentStatus, preferredChannel, engagementScore.
None of those models are wrong. They're three different views of the same real-world thing, and trying to merge them all into one God-Class has killed more codebases than any framework upgrade.
The bounded context says: let each model live where it's used, on its own terms. When the Sales context talks to Billing, they translate at the boundary. They don't share a class. They don't share a database table. They share a contract.
That's the core idea. The rest of this article is about what changes once you actually take it seriously.
Language Lives Inside The Boundary
Eric Evans calls it the ubiquitous language, the words your domain experts and your code agree on, inside a given context. The "ubiquitous" part is important: every method name, every field, every Slack channel about that context, every Jira ticket. All of them use the same vocabulary.
But that vocabulary stops at the boundary.
Take "Order" as an example. In your Sales context, an order is "a customer's intent to buy". It has line items, discounts, statuses like pending, confirmed, cancelled. In Fulfillment, "order" means "a thing to pack and ship". Same ID, but the model is about pick lists, warehouse zones, and carrier handoffs. In Finance, "order" is "a recognised revenue event" with deferred amounts, recognition schedules, and tax allocations.
If you tried to write one Order class that covered all three, it would have sixty fields, half of them null at any given moment, and your validation code would be a nest of if (context === 'finance') branches. Anyone who's worked on a codebase with a class called OrderService that's five thousand lines long has met this beast personally.
Inside each bounded context, you build the smallest, sharpest model that fits that context's job. When data needs to flow across, you publish an event or an API response, never a shared class.
class Order {
constructor(
public readonly id: OrderId,
private items: LineItem[],
private status: OrderStatus,
private discount?: Discount,
) {}
confirm(): void {
if (this.status !== OrderStatus.Pending) {
throw new DomainError("Only pending orders can be confirmed");
}
this.status = OrderStatus.Confirmed;
}
}class Order {
constructor(
public readonly id: OrderId,
public readonly items: PickListEntry[],
public readonly destination: WarehouseZone,
private state: FulfillmentState,
) {}
markPicked(): void {
this.state = FulfillmentState.Picked;
}
}Same id. Different class. Different fields. Different rules. Both are correct.
The shared part is just the ID: a stable identifier that lets the two contexts refer to the "same" real-world order without sharing implementation. Everything else is private to its context.
Teams And Contexts Shape Each Other
Here's the thing nobody told you in the DDD book club: bounded contexts aren't really about code. They're about people.
Conway's Law says systems end up mirroring the communication structures of the organisations that build them. Bounded contexts are Conway's Law dressed for production. The Sales team has its own Slack channel, its own oncall rotation, its own backlog. They don't want to wait for the Fulfillment team to approve a schema change just to add a discount field. So the smartest move is usually to draw the context boundary where the team boundary already is, and let each team own its own model end-to-end.
The rule of thumb: one team should fully own one bounded context.
Two teams owning one context is where the ambiguity creeps back in. Different teams will pull the model in different directions, both convinced they're "fixing" it. You'll see PRs that add fields one team needs and break invariants the other team relied on.
The inverse problem is real too. One team owning five contexts gets stretched thin and starts shortcutting boundaries to ship faster. They merge models that shouldn't be merged because, hey, it's all our code anyway. Six months later, the boundaries are gone, and the context is back to being one God-Class wearing five hats.
A couple of heuristics that help when you're trying to find the seams:
Listen for vocabulary mismatches. If the same word means visibly different things in two parts of your codebase, that's almost always a context boundary trying to surface. Don't fight it with a shared parent class. Lean into it.
Watch the meeting calendar. If your team can finish a feature without booking time on another team's calendar, you're probably inside one context. If every change requires a sync with two other groups, you're either sitting on a boundary, or you've drawn the boundary in the wrong place.
Pay attention to who gets paged. Oncall rotations are a brutally honest map of ownership. If three rotations get paged for the same component, the component is doing three jobs.
When teams reorg (and they always reorg), the context map you drew last year describes last year's org chart. New teams plus old context boundaries is one of the most common sources of "why does it take three sprints to ship a small change" pain. The boundaries need to move with the people. That's annoying, but pretending otherwise is more annoying.
Each Context Owns Its Data
Once you have a real bounded context, the next question is brutally simple: who owns the storage?
The answer is also simple, even if it's uncomfortable: the context that defines the model owns the data. Not the team that "needs the data the most." Not the team that built the database first. The team whose ubiquitous language defines what the data means.
What that looks like in practice depends on how mature your split is.
In a monolith, ownership might be expressed as schema separation. The sales_orders table and the fulfillment_orders table both live in the same Postgres instance, but only the Sales code writes to sales_orders and only Fulfillment writes to fulfillment_orders. Cross-context reads go through service methods, not raw SQL joins.
In a split-services world, each context has its own database, sometimes its own type of database. Sales might use Postgres because their queries are relational. Fulfillment might use a document store because their pick lists are nested and irregular. Finance might use a ledger database with append-only semantics. Each context picks the storage that fits its model, instead of forcing one schema to serve everyone.
The hard rule, regardless of deployment shape: no context reads another context's tables directly. Once you allow that, the boundary is gone. The schema becomes part of the public contract, and any change risks breaking three teams downstream.
CREATE TABLE sales_orders (
id UUID PRIMARY KEY,
customer_id UUID NOT NULL,
status TEXT NOT NULL,
total_cents BIGINT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);CREATE TABLE fulfillment_orders (
id UUID PRIMARY KEY,
-- references sales_orders.id, but does not foreign-key to it
state TEXT NOT NULL,
warehouse_zone TEXT NOT NULL,
carrier TEXT
);Notice what's missing: a foreign key between the two tables. That's deliberate. A foreign key would make the two contexts physically inseparable. You couldn't split them later without a migration that drops the constraint, and you couldn't change one schema without coordinating with the other team. Soft references (just an ID, no FK) keep the boundary movable.
This is where teams new to bounded contexts get nervous. "You're telling me to give up referential integrity?" You're giving up cross-context referential integrity. Inside a context, foreign keys are still your friend. Use them. Across contexts, the integrity guarantee shifts to event-driven eventual consistency or synchronous API checks at the boundary.
If that trade-off scares you, that's fine. It should. It means the boundary you're drawing is real. The gain is that each context can evolve its schema independently, without rolling out coordinated migrations across three repos and four teams.
Integration: Where Contexts Meet
Real systems aren't islands. The Sales context confirms an order; Fulfillment needs to know. Billing recognises revenue; Finance needs the entry. Customers exist in five places at once.
So the next question is: how do contexts talk to each other without leaking their internals?
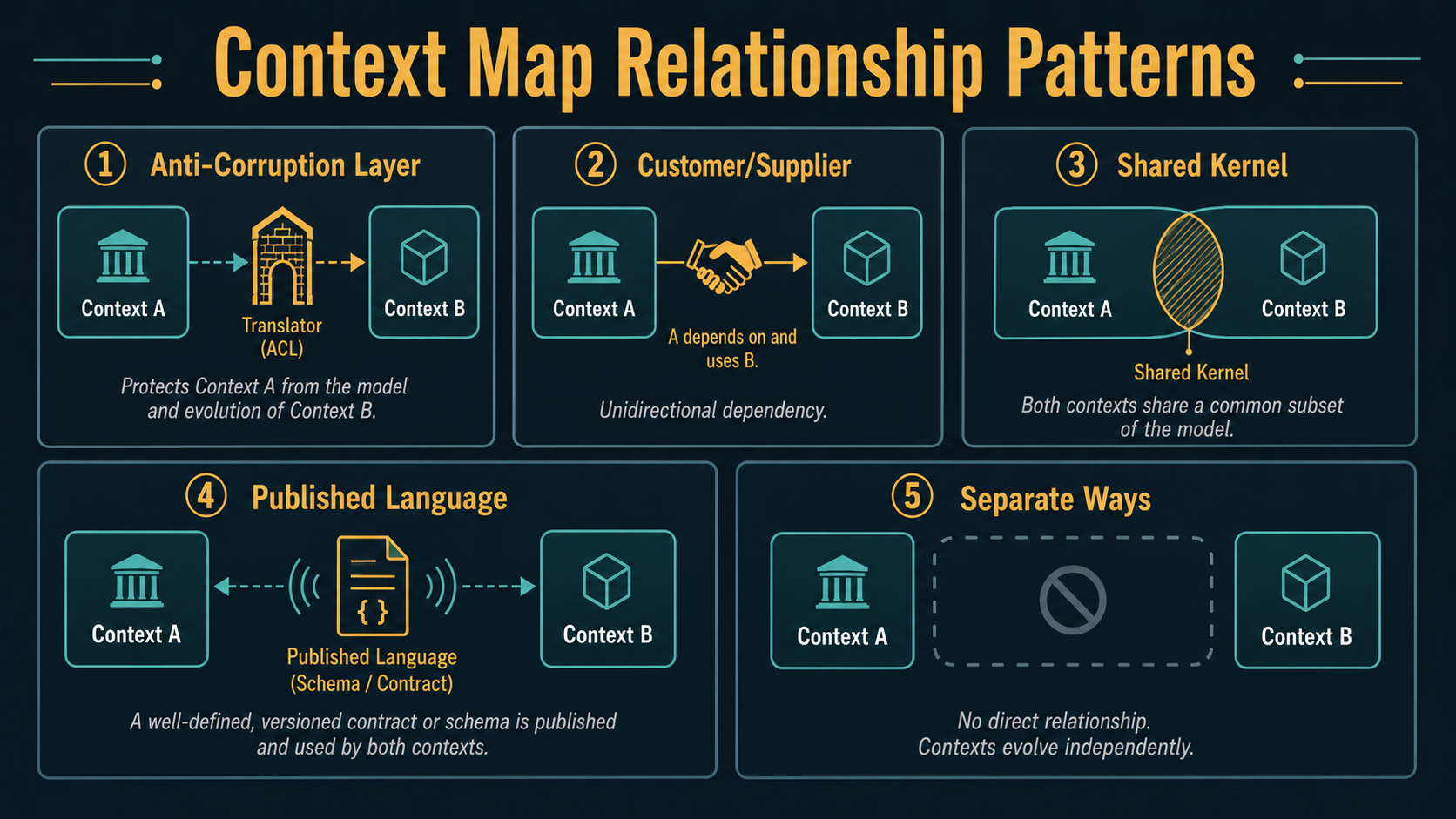
DDD calls these relationships context mapping patterns. There are about half a dozen of them in the literature. You don't need all of them on day one. You need to know they exist, and which one you're (probably accidentally) using right now.
Anti-Corruption Layer (ACL)
The most useful one. You wrap an external context behind a translator that speaks your context's language. Outside concepts come in and get reshaped before they touch any of your domain code.
import type { SalesOrderConfirmedEvent } from "@/contracts/sales";
import { Order, PickListEntry, WarehouseZone, FulfillmentState } from "@/contexts/fulfillment/order";
export function translateSalesOrder(event: SalesOrderConfirmedEvent): Order {
return new Order(
event.orderId,
event.lines.map(l => new PickListEntry(l.sku, l.qty)),
WarehouseZone.fromShippingAddress(event.shipTo),
FulfillmentState.ReadyToPick,
);
}If the Sales team renames lines to items next quarter, you change the translator. Your domain code stays untouched. That insulation is the whole point. The ACL is a one-way mirror: your context sees the outside world only through a lens you control.
Customer / Supplier
One context (the supplier) provides a service the other (the customer) depends on. The customer can negotiate the contract; the supplier owns the model. Most internal API consumers fall into this category.
It works when both teams are in the same company and can talk to each other. It breaks when the supplier team treats their API as a take-it-or-leave-it commodity. If you find yourself unable to influence an upstream contract you depend on, you're not in customer-supplier. You're in conformist territory. And you should probably wrap that conformist relationship in an ACL before it starts dictating the shape of your domain.
Shared Kernel
The dangerous one. Two contexts agree to share a small piece of model code: a Money type, a Currency enum, a TimeWindow. Both can read it. Either can change it (with coordination).
Shared kernels are tempting because they kill duplication. They're dangerous because every change requires negotiation across teams. Use them only when the shared piece is truly universal and truly stable. A Money type that handles currencies and rounding might qualify. A "User" definition almost never does. Every team thinks they need the same User, and they don't.
Published Language
When more than two contexts need to integrate, sharing N-by-N translators gets ugly fast. A published language, usually a versioned event schema or an API spec, gives everyone a common middle ground. Each context translates to and from the published language at its own boundary.
This is what most modern event-driven systems are doing, even if they don't use the DDD vocabulary out loud. Your OrderConfirmed event schema is a published language. Your gRPC .proto files are a published language. Your OpenAPI spec is a published language. The trick is to treat that schema as a first-class deliverable, not a side effect of whichever team shipped first.
Separate Ways
The most under-used pattern. Sometimes the right answer is "these two contexts have nothing meaningful to share, let them go their separate ways." If your "Internal Tooling" team and your "Customer-Facing API" team genuinely don't overlap, don't force an integration. Two completely independent systems is sometimes the cleanest design. The cost of not integrating is usually lower than the cost of integrating wrong.
Picking The Right Relationship
How do you choose between these patterns? A few rules of thumb that have held up well:
If you can influence the upstream model, prefer customer-supplier. It's the lowest-friction option. You collaborate, ship, move on.
If you can't influence the upstream model, wrap it in an ACL. Always. The day the upstream team renames a field, you'll be glad you did.
If two teams keep wanting to share types, ask why first. Often the "shared" thing is actually two things wearing the same name. Splitting them gives both teams freedom; sharing them gives both teams meetings.
If integration is mostly broadcast (many consumers, one producer), invest in a published language early. The ROI on a stable event schema across five consumers is enormous, and it grows every time you add a sixth.
If two contexts have no real relationship, let them have no relationship. Don't manufacture integrations to feel "well-architected." A clean non-relationship is better than a messy relationship.
The pattern you pick matters less than the principle: every cross-context relationship should be explicit, named, and owned by someone. Implicit integrations, where one team's code happens to read another team's tables, or one service silently depends on another's response shape, are where the next outage comes from.
Where To Start If You're Working In A Monolith
You don't need microservices to get value from bounded contexts. Most teams who try to "do DDD" jump straight to splitting services and end up with a distributed monolith that's slower than what they had before. Bounded contexts are a modeling idea first; deployment is downstream.
The cheapest place to start is usually inside the codebase you already have:
- Pick a part of the codebase where multiple teams keep stepping on each other.
- Look for a word that means different things to different teams. Pick the most painful one.
- Define one small, sharp model for that word, for one team's view of it.
- Move just that team's code to use the new model. Leave the old one in place.
- When the other team needs to interact with the new model, build a small translator at the boundary.
- Repeat for the next painful word.
You don't have to redraw your entire architecture. You don't have to convince leadership to fund a "DDD initiative." You just need to stop letting one model do three jobs.
Bounded contexts are the cheapest expensive idea in software architecture. Cheap to introduce: you can do it in a single PR. Expensive to keep not introducing, because every quarter you wait, the shared model grows another twenty fields and another two teams who depend on each one of them.
The blue book is five hundred pages. You can get most of the value from one chapter: the one where bounded contexts show up. If you're going to read that book on a Tuesday afternoon and pick a single page to act on, this is the page.
Draw the borders. Speak the dialects. Translate at the gates.
Everything else in DDD is just sharper tools you'll reach for once you've already done that.





