Enterprises care about boundaries.
Not because they dislike AI — because they already have security reviews, cloud policies, audit requirements, IAM roles, compliance controls, procurement rules, data residency concerns, and internal governance. A developer may ask:
Why not just call the model API directly?Sometimes that's perfectly fine. But for many companies, using Claude through Amazon Bedrock is attractive because it fits into an existing AWS operating model. You can access Claude models through AWS-managed infrastructure, control access with IAM, monitor usage through AWS tooling, integrate with existing services, and keep architecture inside the AWS boundary that the company already understands.
This article explains the practical engineering reasons teams consider Claude on Bedrock, what it gives you, what it doesn't, and when direct API usage may still be simpler.

Why Cloud Boundaries Matter
In small projects, AI integration often starts like this:
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])That's simple and productive. In enterprise environments, the questions are different:
- Which team owns the API key?
- Where is usage logged?
- Can access be controlled through existing roles?
- Can we restrict model access by account or environment?
- Can we audit who invoked what?
- Can we integrate with existing AWS billing?
- Can we keep traffic inside approved cloud architecture?
- Can we apply internal governance?
Claude on Bedrock can make these conversations easier for AWS-heavy companies. It doesn't remove the need for security design — but it gives you familiar AWS control points.
Model Access Through AWS
Amazon Bedrock provides access to foundation models from multiple providers, including Anthropic Claude models, depending on availability and region. Before using a model, teams usually need to request or enable model access in Bedrock — and that step matters because model access becomes part of AWS governance.
A simplified AWS SDK example:
import boto3
import json
client = boto3.client("bedrock-runtime", region_name="us-east-1")
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "Summarize the deployment risk from this change."
}
],
}
response = client.invoke_model(
modelId="anthropic.claude-sonnet-4-5-20250929-v1:0",
body=json.dumps(body),
)
payload = json.loads(response["body"].read())
print(payload)Model IDs, regions, and availability can change. Always check Bedrock model access in your AWS account before implementation.
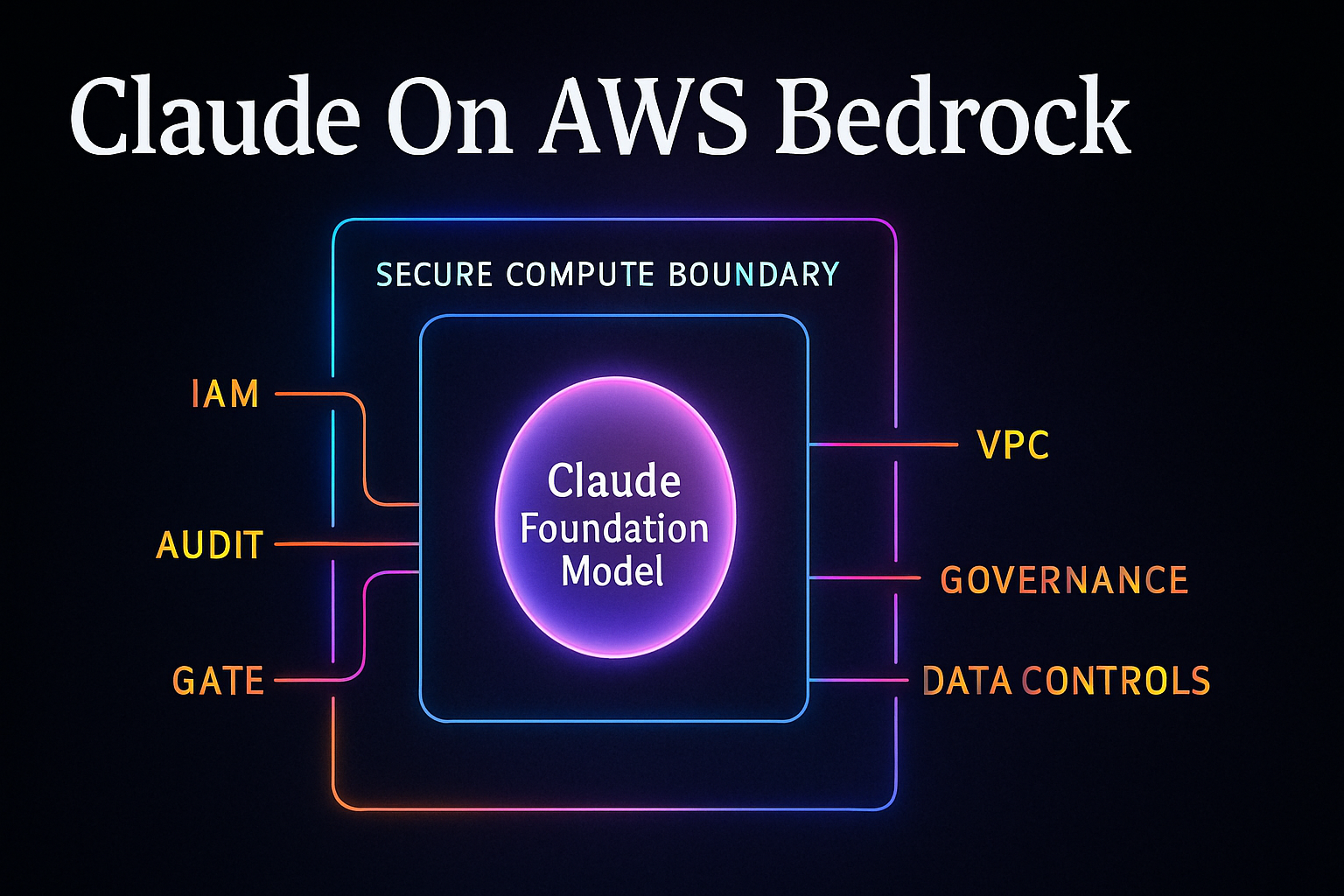
IAM: Access Is A First-Class Control
One major advantage of Bedrock is IAM. Instead of distributing raw provider API keys across services, you can give AWS roles permission to invoke specific Bedrock actions.
Example concept:
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-*"
]
}Production policies should be tighter than this. You may restrict exact model IDs, AWS accounts, environments, application roles, regions, or invocation paths. The idea is simple:
AI model access becomes part of normal cloud access control.That's easier for many enterprise teams than managing separate API keys.
Audit And Governance
Enterprise systems need auditability. You usually want to know which app invoked the model, which role was used, when it happened, which model was used, how much it cost, whether errors occurred, and which environment made the call. AWS-native integration helps because you can connect model usage to existing observability and governance workflows.
A production app should still log its own application-level metadata:
{
"request_id": "req_123",
"user_id": 481,
"feature": "pr_review_summary",
"model_provider": "bedrock",
"model": "claude",
"input_document_count": 6,
"tool_calls_enabled": false,
"environment": "production"
}Don't log raw prompts if they contain sensitive data — log metadata first.

Private Data Concerns
Using Claude through Bedrock doesn't mean you can send anything without thinking. You still need data minimization. Don't send:
- secrets,
- raw production
.envfiles, - unnecessary customer PII,
- full database exports,
- private documents unrelated to the task,
- sensitive logs without redaction.
Safer pattern:
def build_ai_context(question: str, user: User) -> list[DocumentChunk]:
chunks = retrieve_relevant_chunks(question)
allowed = [
chunk for chunk in chunks
if user_can_access(user, chunk)
]
redacted = [
redact_sensitive_fields(chunk)
for chunk in allowed
]
return redacted[:8]Even inside AWS, least privilege still matters. Bedrock can help with enterprise boundaries, but it doesn't replace application-level data controls.
Integration With Existing AWS Infrastructure
Claude on Bedrock fits well when your system already uses AWS services. Common integrations:
S3:
Store source documents, logs, exports, or generated summaries.
Lambda:
Run lightweight AI workflows or document processing jobs.
ECS/EKS:
Host internal AI services.
IAM:
Control model access and service permissions.
CloudWatch:
Collect logs and metrics.
EventBridge:
Trigger AI workflows from events.
Step Functions:
Orchestrate multi-step AI workflows.
Bedrock Knowledge Bases:
Build managed RAG over internal data.
Secrets Manager:
Store app secrets outside code.Example AI workflow:
Pull request opened
↓
EventBridge or GitHub webhook
↓
ECS service reads diff
↓
Bedrock Claude summarizes risk
↓
Result posted as PR comment
↓
Logs and metrics go to CloudWatchThat's not exotic. It's normal AWS architecture with an LLM call inside.
Claude + Bedrock Knowledge Bases
For internal engineering assistants, Claude and Bedrock Knowledge Bases can work together.
Example:
User asks:
"How does payment retry work?"
Knowledge Base retrieves:
- payment retry runbook,
- architecture doc,
- incident summary.
Claude generates:
- concise answer,
- source citations,
- risk notes,
- follow-up links.This is useful because the model doesn't rely only on pretraining — it answers using your internal sources. A good prompt:
Answer the engineering question using only retrieved context.
Cite sources.
If the context is incomplete, say what is missing.
Do not invent internal behavior.Pros Compared To Direct API Usage
Claude through Bedrock may provide:
- AWS IAM-based access control,
- integration with AWS billing and governance,
- AWS-native operational model,
- easier approval for AWS-centered companies,
- Bedrock Knowledge Bases integration,
- consistency with other AWS AI services,
- ability to centralize model access in AWS accounts.
That can matter a lot in enterprise environments.
Cons Compared To Direct API Usage
Direct provider APIs may still be better when:
- you want the newest model features immediately,
- you need provider-specific APIs not yet available through Bedrock,
- you want simpler local development,
- your company is not AWS-centered,
- you need lower integration complexity,
- your vendor approval process already covers direct API usage.
Also, model availability, names, regions, and features can differ between direct APIs and Bedrock. Always check what's actually available in your account.

Practical Decision Framework
Ask these questions:
Is our company already AWS-first?
Do we need IAM-based model access?
Do security teams prefer AWS boundaries?
Do we need Bedrock Knowledge Bases?
Do we need centralized billing and audit?
Do we need the newest model feature immediately?
Do we need provider-specific APIs?
How sensitive is the data?
Who owns model governance?If your answers lean toward AWS governance, Bedrock may be a strong fit. If they lean toward speed, simplicity, and direct feature access, the direct API may be better. This doesn't need to be all or nothing — some teams use:
Direct API for prototypes.
Bedrock for production enterprise workflows.That can be a reasonable path.
Example: Internal PR Review Service
Architecture:
GitHub Pull Request
↓
Webhook
↓
Internal AI Review Service on ECS
↓
IAM Role invokes Claude through Bedrock
↓
Claude reviews diff and risk policy
↓
Service posts advisory PR comment
↓
Logs metadata to CloudWatchPseudo-code:
def review_pull_request(pr: PullRequest) -> str:
diff = github.get_diff(pr)
policy = load_review_policy()
prompt = f"""
You are an advisory code reviewer.
Review this pull request using the team policy.
Team policy:
{policy}
Diff:
{diff}
Return:
- summary,
- high-risk findings,
- missing tests,
- questions for human reviewers.
"""
return invoke_claude_on_bedrock(prompt)This is a practical enterprise use case. You can keep access inside AWS roles, log usage, and apply team governance — all without spinning up a new control plane.
Final Thoughts
Claude on AWS Bedrock isn't automatically better than direct API usage. It's better for certain organizational constraints. If your company already runs on AWS and cares deeply about IAM, audit, governance, billing, and cloud boundaries, Bedrock can make enterprise AI adoption smoother.
But you still need good application architecture. You still need data minimization, redaction, permissions, prompt design, evaluation, and human review for risky actions. Bedrock gives you an enterprise control plane — it doesn't remove engineering responsibility.
That's the right way to think about it.