So, you've used MongoDB for a few years. You know what a collection feels like. You know what a document feels like. You know you can throw a JSON-ish blob in there, query it by any field, and life is mostly fine until someone forgets an index.
Now your team is moving a service to DynamoDB. You crack open the AWS console, you create a table, you write your first PutItem, and the thing you put in looks like a document. JSON-shaped. Nested objects. Arrays. No CREATE TABLE with columns and types.
You think: "Okay, this is basically MongoDB with an AWS bill."
That's the trap.
DynamoDB is not a document database. It just looks like one for the first ten minutes. Underneath, it's a distributed key-value store with a small, very opinionated query system bolted on top. The mental model is different, the schema work is different, the failure modes are different, and the pricing model punishes you specifically for treating it like Mongo.
This is the article I wish someone had handed me the first time I started designing a DynamoDB table.
A DynamoDB item looks like JSON. It is not a document.
Let's start with what's the same. Both DynamoDB and MongoDB store items with a flexible shape. Both let you add a new attribute without a migration. Both can hold nested objects and arrays. Both let you serialize a domain object straight in without an ORM in between.
Here's a user item in MongoDB:
// MongoDB document
{
_id: ObjectId("64f0a..."),
email: "ada@example.com",
profile: {
displayName: "Ada Lovelace",
timezone: "Europe/London"
},
roles: ["admin", "billing"]
}And the same idea in DynamoDB:
{
"pk": "USER#42",
"sk": "PROFILE",
"email": "ada@example.com",
"profile": {
"displayName": "Ada Lovelace",
"timezone": "Europe/London"
},
"roles": ["admin", "billing"]
}Looks identical, right? Two JSON blobs, same fields. If you squint, the only odd thing is those pk and sk fields at the top.
Those two fields are the entire game.
In MongoDB, you can ask the database: "give me every user where roles contains billing." You can ask: "give me users created in the last 30 days, sorted by login count, where timezone starts with Europe/." If there's no index, it'll be slow. But it will run. You can explore your data interactively.
In DynamoDB, none of that works out of the box. You can ask: "give me the item where pk = "USER#42" and sk = "PROFILE"." That's GetItem, and it's blisteringly fast at any scale. You can ask: "give me all items where pk = "USER#42"." That's Query, and it's also fast. But "give me every user with roles containing billing"? That's a Scan over the entire table, and you don't want to do that, ever, in production.
The fields inside the item are inert. They're payload. DynamoDB does not index them, does not search them, does not know they exist for query purposes unless you specifically attach a secondary index. The only things the database thinks about are your keys.
So the better mental model is: DynamoDB is a key-value store where the value happens to be JSON. Mongo is a document database where the document happens to have an _id. The difference is which side of the relationship is doing the work.
The partition key is the database
DynamoDB is built on a partitioning model. Every item lives in one logical partition, and the partition it lives in is determined by hashing the partition key (sometimes called the hash key).
When you write pk = "USER#42", DynamoDB takes the string "USER#42", hashes it, and that hash decides which physical storage node will hold that item. When you read it back with GetItem({ pk: "USER#42", sk: "PROFILE" }), DynamoDB hashes the partition key, jumps directly to the right node, and pulls the item. There's no scan, no broadcast, no fan-out. One hop. That's why DynamoDB stays fast at any size: the table can be ten gigabytes or ten petabytes and a GetItem is still a single-hop lookup.
But it also means you cannot query across partition keys efficiently. If your access pattern is "find me a user by email" and email is not the partition key, DynamoDB has no shortcut. It would have to visit every partition and look at every item. That's a Scan, and it scales with the size of your table, not the size of the result.
This is the first and biggest break from MongoDB. In Mongo, you create the collection, then later you decide "hmm, we should add an index on email", and the query starts working. In DynamoDB, the choice of partition key is baked into how the table is physically organized. Picking the wrong one isn't a missing index: it's a missing primitive. You can fix it (with a GSI, more on that later), but it costs storage and write throughput, and you have to plan for it.
The second consequence is hot partitions. If 90% of your traffic hits items where pk = "TENANT#bigcorp", all of that traffic lands on the same physical node. DynamoDB tries to smooth this out with adaptive capacity, but a true hot partition will still throttle, regardless of the throughput you've provisioned for the table as a whole. The partition key has to be both queryable in the way you need and distribute load evenly. Both, not either.
That's already a different kind of decision than you ever made in MongoDB.
The sort key is your secondary access path
A primary key in DynamoDB can be one field (just a partition key) or two (partition key + sort key, also called the range key). Most non-trivial tables use both.
The sort key sounds like it's just for ordering, but it's much more interesting. Within a single partition, items are stored sorted by sort key, and Query can do range operations on it: equals, begins-with, between, less-than, greater-than. So if you set things up like this:
pk | sk
---------------|------------------------
USER#42 | PROFILE
USER#42 | ORDER#2026-01-12#a1b2
USER#42 | ORDER#2026-02-04#c3d4
USER#42 | ORDER#2026-03-21#e5f6
USER#42 | SESSION#abc
USER#42 | SESSION#xyz...then a single Query like pk = "USER#42" AND begins_with(sk, "ORDER#") returns all of that user's orders, in order, in one call. No join, no second query, no scatter-gather. The sort key effectively gives you one extra access pattern for free, as long as you can express it as a prefix or range on a single string.
This is where DynamoDB starts to feel powerful, and where it starts to look nothing like Mongo. Mongo's primary key is _id and it's just a unique identifier. DynamoDB's primary key is a unique identifier and a way to lay items out on disk in a useful order.
The classic trick is encoding hierarchical or temporal data into the sort key:
ORDER#2026-01-12T14:32:00Z#a1b2c3Now begins_with(sk, "ORDER#2026-01") returns every order from January 2026 for that user. begins_with(sk, "ORDER#2026-01-12") returns just that day. between(sk, "ORDER#2026-01-01", "ORDER#2026-02-01") returns the month. You've got a date range query, no extra index needed, and it's all driven by string comparison on the sort key.
You're going to use this trick a lot.
Query, GetItem, Scan: what's actually on offer
DynamoDB's read API is small on purpose. There are essentially three reads:
GetItem takes a full primary key (partition + sort, if you have one) and returns at most one item. It's the cheapest, fastest operation. Always prefer this when you can.
Query takes a partition key and an optional condition on the sort key. It returns up to 1 MB of items per call (you paginate after that) and it scans only within that one partition. This is the workhorse: Query is what makes DynamoDB feel like a real database instead of a glorified hash map.
Scan is what happens when you've given up. It reads every item in the table, with optional filtering applied after the read. The filtering doesn't save you money or throughput; DynamoDB still bills you for every item it touched, not just the ones that matched. A Scan of a 50 GB table will cost you for 50 GB of reads even if you only wanted three items back.
In Mongo, db.users.find({ email: "ada@example.com" }) works fine without an index; it just gets slow when the collection grows. In DynamoDB, the equivalent is Scan with a filter, and you'll feel the cost in your AWS bill the same week you ship it.
The discipline this forces on you is unusual. You can't write the query first and tune the index later. You have to know your access patterns before you create the table, because the keys are the index, and the keys are the table.
This is genuinely uncomfortable for engineers coming from a Mongo or relational background. It feels like the database is refusing to help you. It is. That's the deal: in exchange, DynamoDB gives you single-digit-millisecond reads at any scale, with no operational overhead beyond writing IAM policies.
Access patterns drive the schema. Not the other way around.
In a relational database, you usually start with entities. Users, Orders, Products. You draw boxes, you draw lines, you normalize, and the schema falls out. Queries come later. That's what indexes are for.
In MongoDB, you usually start with documents. What does a User look like? What gets embedded? What gets referenced? Queries come later. That's what indexes are for. Notice a pattern.
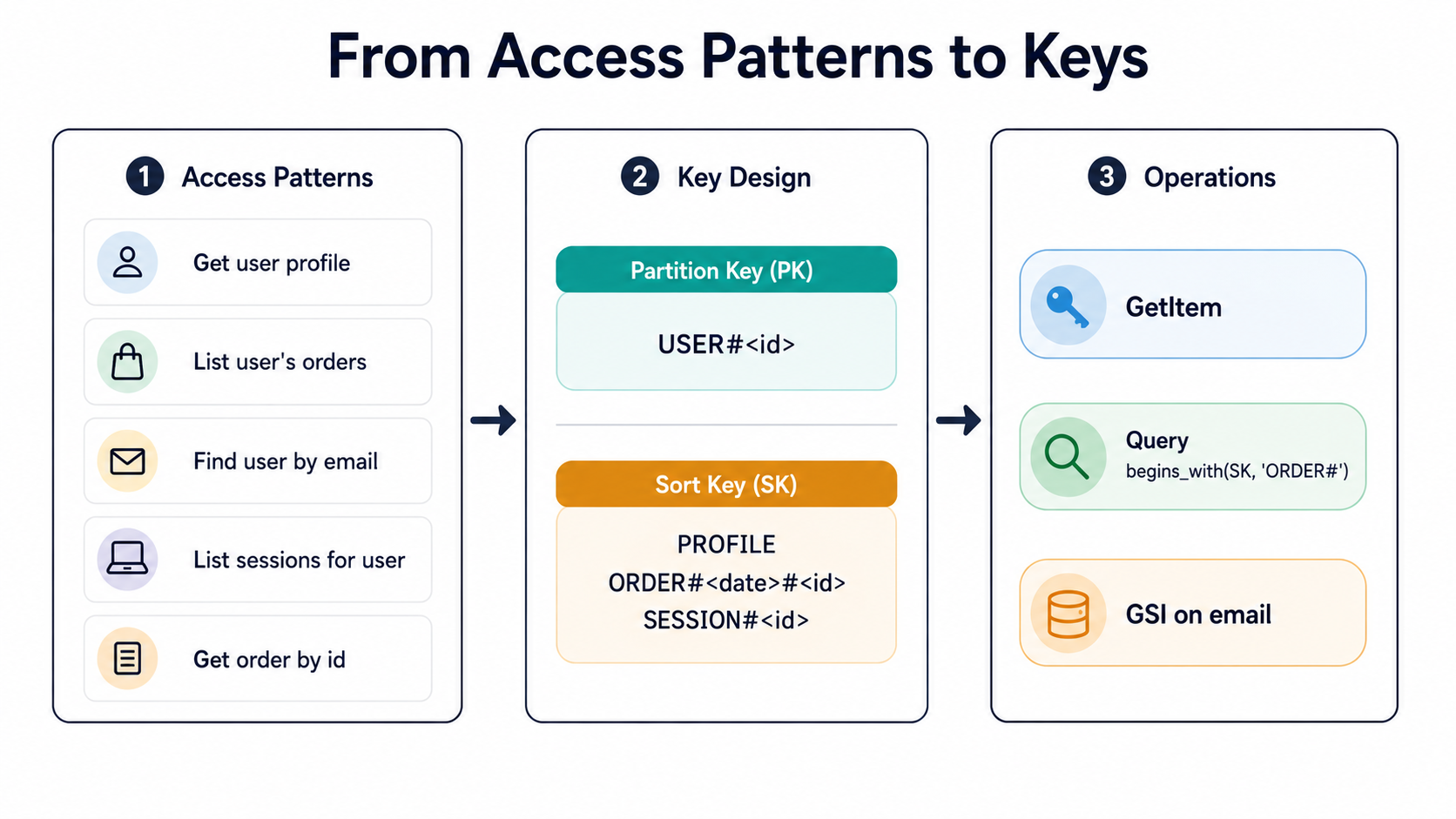
In DynamoDB, you start with access patterns. You list every read and every write your application is going to make, on day one, in production. Things like:
- Get a user's profile by user id
- List a user's last 20 orders, newest first
- Get an order by order id (without knowing the user)
- List all orders placed in a given month, across users (for finance)
- Find a user by email
- Get all sessions for a user, sorted by created-at desc
- Get the active session for a user, if anyThat list is the schema's input. The partition keys, sort keys, GSIs, and item layouts are the schema's output. You don't start with "what does a User look like." You start with "what do we need to ask of the data," and the item shapes fall out of the answer.
This is the inversion that catches people. You can't model DynamoDB like Mongo and then add the access patterns later, because adding an access pattern often means changing the partition key, and the partition key is physical. You'd be reshuffling the table.
So the workflow becomes:
- Write out every access pattern in plain English.
- For each one, decide the minimum information needed to answer it (which keys, which fields).
- Group access patterns by which "thing" they're asking about.
- Design keys that satisfy as many access patterns as possible with the cheapest operations:
GetItemif possible,Queryif not, neverScan. - The leftovers become GSIs, or get denormalized into other items.
If you've never done this before, it feels backwards. Like designing a house by listing every conversation you plan to have inside it before drawing any rooms. It is backwards, by Mongo standards. It's the price of admission.
Single-table design: yes, really, one table
This is the part that makes people say "wait, what?" the first time they see it.
In a relational world, you'd have a users table, an orders table, a sessions table, an addresses table. Each entity gets its own home. Joins glue them together at query time. Idiomatic, predictable, the way databases have worked for 40 years.
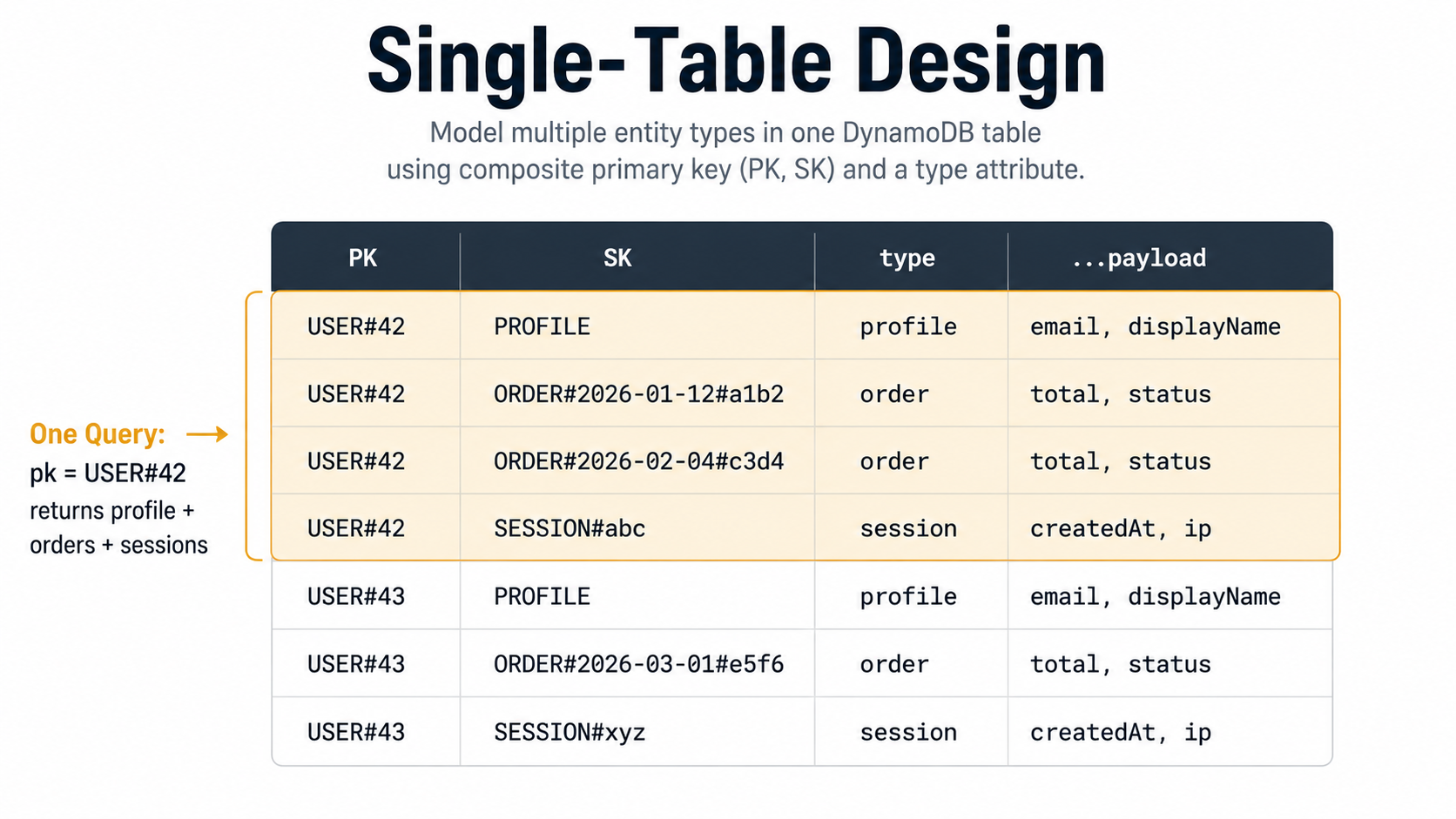
In DynamoDB, the recommended pattern is to put all of those entities in a single table. Different entity types, same physical table, distinguished by the values of the partition and sort keys. The table doesn't have columns in the relational sense; items in the same table can have totally different attributes. The keys are the structure; the rest is payload.
A single-table layout for a user with profile, orders, and sessions:
pk | sk | type | ...attributes
---------------|---------------------------------|----------|---------------------------
USER#42 | PROFILE | profile | email, displayName, ...
USER#42 | ORDER#2026-01-12T14:32Z#a1b2 | order | total, currency, status, ...
USER#42 | ORDER#2026-02-04T09:15Z#c3d4 | order | total, currency, status, ...
USER#42 | SESSION#abc | session | createdAt, ip, userAgent, ...
USER#43 | PROFILE | profile | email, displayName, ...
USER#43 | ORDER#2026-03-01T11:22Z#e5f6 | order | total, currency, status, ...One table, three "entity types" in the relational sense, all colocated by pk. The trick this unlocks: with a single Query call on pk = "USER#42", you can pull a user's profile, their entire order history, and their sessions in one round trip. The relational version of that would be three queries or a multi-way join.
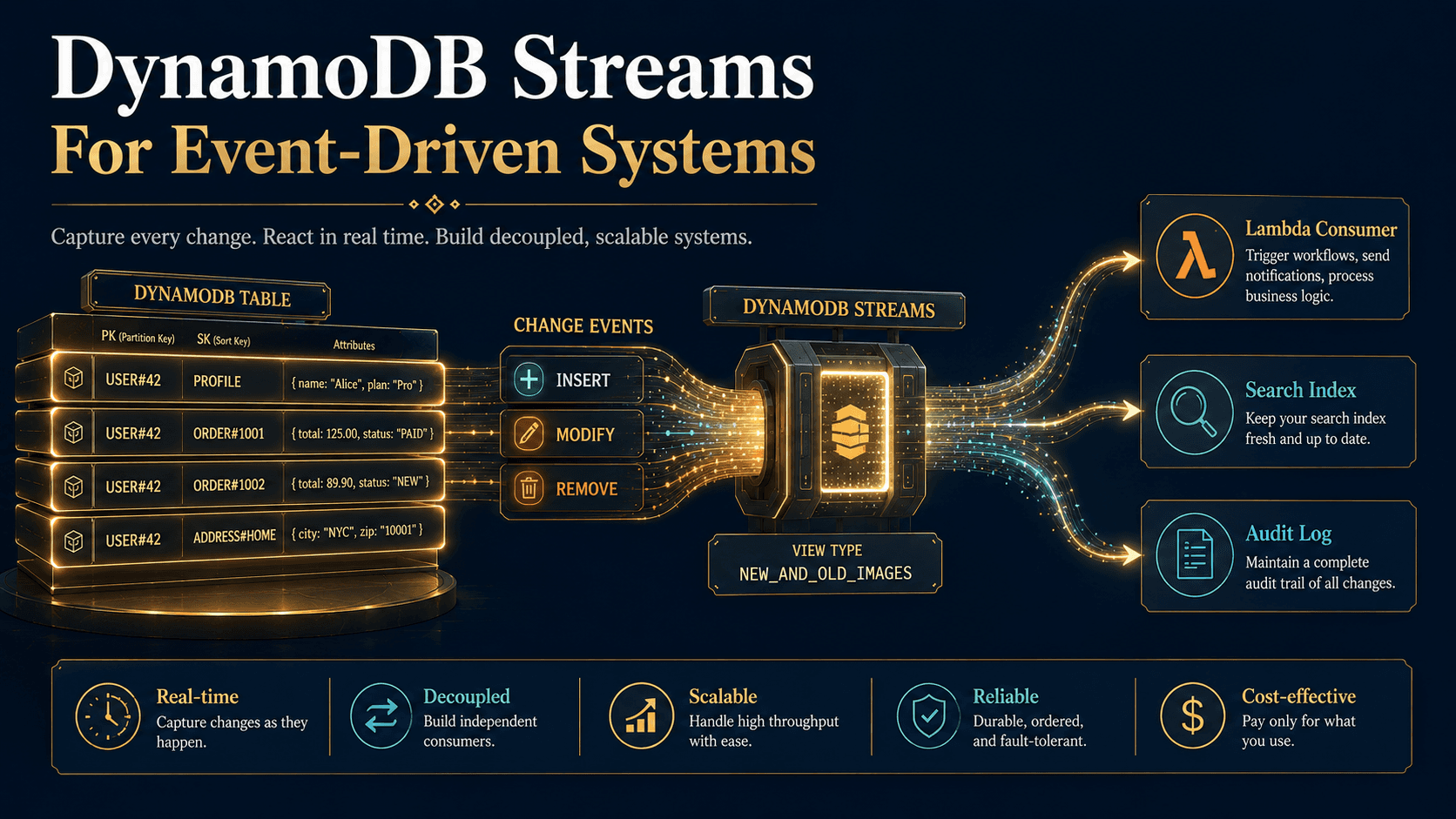
The reason this is the recommended pattern, not just a pattern, is that DynamoDB's pricing rewards it. You pay for each request and for the bytes returned. One request that pulls the whole picture for a user is dramatically cheaper than four requests against four tables. And because DynamoDB Streams and global tables operate per-table, having one table means you only have one stream to wire up, one replication topology to manage, one IAM policy to maintain.
The cost is the cognitive load. A single-table design looks like chaos at first. Different item shapes in the same table. Generic key names (pk, sk, gsi1pk, gsi1sk) instead of meaningful ones (user_id, order_id). Sort key strings encoded with prefixes like ORDER# because the sort key has to do five different jobs. The discipline is real, and the table feels less self-describing than a normalized SQL schema. That's the tradeoff you're signing up for.
GSIs: alternate access paths, not free queries
The first time you hit an access pattern that doesn't fit the partition key, you reach for a Global Secondary Index (GSI).
A GSI is, essentially, a second copy of your table with a different partition key and sort key. You define it once, DynamoDB maintains it for you. You query it just like you query the base table, but using the index's keys.
The canonical use case: "find a user by email" when the primary key is USER#<id>. You add a GSI with gsi1pk = "EMAIL#<email>", leave gsi1sk unused or set to "USER", and now you can Query the index by email and get back the user item.
The pricing reality, though, is that a GSI is not a free index. It's a second copy of the data. Every write to the base table costs you an extra write to every GSI that includes the changed attribute. A table with three GSIs has roughly 4x the write cost of the same table with no GSIs (with some optimizations for projection, but the order of magnitude is right). Storage is also 2x, 3x, 4x, once per index.
And the consistency is eventual. A GetItem on the base table is strongly consistent (if you ask for it). A Query on a GSI is always eventually consistent, full stop. There's no flag for strong consistency on a GSI. So if your access pattern is "a user just registered, immediately look them up by email", you cannot trust a GSI to find them within milliseconds. You'd either tolerate the lag, write to the GSI synchronously through a different mechanism, or restructure so the lookup hits the base table.
The takeaway: GSIs are a tool, not a habit. Reach for one when an access pattern truly cannot fit on the base table's keys, and only after you've considered whether the access pattern even justifies a separate code path. Three is a lot of GSIs. Five is usually a sign that the table design isn't doing its job.
What DynamoDB does not do (well)
Once you've internalized that DynamoDB is a key-value store with secondary access paths, you can see clearly what it's bad at, and where MongoDB starts to look attractive again.
Ad-hoc queries. "I want to find every order over $500 placed last week from a user in the EU." That's a Scan with three filters. In Mongo, it's find({ amount: { $gt: 500 }, placedAt: { $gte: lastWeek }, region: "EU" }) and it'll use whatever indexes exist. In DynamoDB, you either pre-plan that access pattern (a GSI keyed on something useful) or you do an analytics dump to S3 + Athena and query it there. There's no in-database equivalent.
Aggregations. Mongo has an aggregation pipeline. SQL has GROUP BY. DynamoDB has neither. If you need a sum or a count or a top-10 by some field, you either maintain a counter item that you update on every write, or you stream the table to another system that can aggregate. DynamoDB is a great source of truth for these aggregations; it's a poor place to compute them.
Full-text search. Mongo has text indexes. SQL has LIKE (slow) and full-text extensions. DynamoDB has neither. You'd typically stream into OpenSearch or Elasticsearch and search there.
Schema-on-read exploration. "Let me just look at a few documents and see what fields they have" is great in Mongo. In DynamoDB, the console can show you items, but with single-table design, what you're looking at is a polyglot: five entity types interleaved. Exploration without a key is Scan, and Scan is expensive.
Joins. No joins. Ever. You denormalize, or you do multiple reads in the application, or you design the keys so colocated items come back in one Query. The single-table-design trick is how you fake the join. It works well when you've planned for it. It does nothing for you when you haven't.
If a service is dominated by read patterns where you know exactly which entity you want and how it relates to its neighbors, and the write rate is high, DynamoDB is excellent. If a service is dominated by exploratory queries, aggregation, search, or relationships you discover as you build, MongoDB or a relational database will be much kinder. They are not interchangeable, no matter how similar the JSON looks.
How a write usually looks
Just so the shape is concrete, here's the same operation (creating a new order for a user) in two DynamoDB SDKs and one MongoDB driver. The point is not the SDK syntax; it's how different the intent is.
import { DynamoDBClient, PutItemCommand } from "@aws-sdk/client-dynamodb";
import { marshall } from "@aws-sdk/util-dynamodb";
const ddb = new DynamoDBClient({});
const now = new Date().toISOString();
const orderId = "a1b2c3";
await ddb.send(new PutItemCommand({
TableName: "app",
Item: marshall({
pk: "USER#42",
sk: `ORDER#${now}#${orderId}`,
type: "order",
total: 4299,
currency: "USD",
status: "pending",
}),
// Make sure we don't overwrite an existing order with the same id
ConditionExpression: "attribute_not_exists(pk)",
}));import boto3
from datetime import datetime, timezone
ddb = boto3.resource("dynamodb")
table = ddb.Table("app")
now = datetime.now(timezone.utc).isoformat()
order_id = "a1b2c3"
table.put_item(
Item={
"pk": "USER#42",
"sk": f"ORDER#{now}#{order_id}",
"type": "order",
"total": 4299,
"currency": "USD",
"status": "pending",
},
ConditionExpression="attribute_not_exists(pk)",
)import { MongoClient } from "mongodb";
const client = new MongoClient(process.env.MONGO_URI);
const orders = client.db("app").collection("orders");
await orders.insertOne({
userId: 42,
total: 4299,
currency: "USD",
status: "pending",
createdAt: new Date(),
});Look at where the work is happening.
The Mongo version expresses what you're storing: an order, with these fields. The relationship to the user is a foreign key (userId: 42). The collection is dedicated to orders. The createdAt field is just data; you'd separately add an index on it if you wanted to sort.
The DynamoDB version expresses where the item lives: under partition USER#42, with a sort key shaped ORDER#<timestamp>#<id> so that all the user's orders are stored next to each other in time order, in the same table as the user's profile and sessions. The sort key isn't a field, it's a coordinate. The ConditionExpression is the closest thing to a unique constraint: there are no DB-level unique indexes outside the primary key.
Same domain. Same data. Completely different way of thinking about where it goes.
A short closing thought
The biggest mistake people make with DynamoDB is treating it like a faster, AWS-flavored Mongo. The schema looks like JSON, so the assumption is "flexible document store, just like Mongo, just at AWS scale." And then six months in, somebody asks for a new dashboard, and the team realizes the table they designed can't answer the question without a Scan, and the bill arrives, and someone says we should have used Postgres.
DynamoDB rewards a very specific kind of upfront work: list every access pattern, design the keys to satisfy them, accept that the schema is the key design, and put almost everything in one table. When you do that work, you get a database that does single-digit-millisecond reads at any scale, costs almost nothing per request, and never needs operational attention.
When you don't, you get an expensive key-value store you don't know how to query.
Pick the one you actually need.