So you've spun up a new service on AWS, and now you're staring at the database picker. RDS sits there with its familiar engine list. Postgres, MySQL, MariaDB, Aurora. DynamoDB sits next to it, single line, no engine choice, no version dropdown. Two buttons, one bill, one decision you'll live with for the next three years.
Most teams pick by gut. Someone on the team likes Postgres, so RDS wins. Or someone watched a re:Invent talk on serverless and DynamoDB wins. Or the loudest engineer says "NoSQL doesn't scale how you think it does" and the conversation ends there.
That's a coin flip with extra steps.
The honest answer is that RDS and DynamoDB are not competitors. They solve different problems, they think about scale in completely different ways, and they reward completely different access patterns. If you pick the wrong one for your shape of data, you don't just pay more, you fight the database every day until you migrate or rewrite. Pick the right one and the database stays out of your way.
Let's break it down properly. By the end you should be able to walk into the next design review and defend your pick with something more than "I've used it before."
What you're actually choosing between
Before the comparison, let's name the two things accurately.
RDS is a managed service for running relational databases. AWS handles the box, provisioning, patching, backups, replicas, failover, and gives you a near-stock Postgres / MySQL / MariaDB / Oracle / SQL Server / Aurora instance you connect to with the same driver you'd use anywhere else. Your data model is rows in tables, joined by foreign keys, queried with SQL, protected by ACID transactions. The thing you pay for is roughly: an EC2 instance under the hood, EBS storage attached to it, and the I/O it does.
DynamoDB is a managed distributed key-value store. There's no instance to size, no engine to pick, no driver port to remember. You define a table with a partition key (and optionally a sort key), then you read and write items by those keys. There are no joins. There is no SQL. Transactions exist, but they're bounded and limited. The thing you pay for is roughly: storage by the GB, plus reads and writes you actually perform, either on-demand per request, or provisioned per second.
That's the surface difference. The deeper difference, the one that drives every other tradeoff, is the unit of scale.
RDS scales the machine. You make the instance bigger. You add read replicas. You shard manually. You eventually hit Aurora's clever distributed storage layer and push that further. But the mental model is one logical database that's been made faster.
DynamoDB scales the partition. The table is, conceptually, an infinite pool of partitions. Every item lives in one, picked by hashing its partition key. AWS adds and removes physical nodes underneath you as your data and traffic grow, and you never see it happen. The mental model is a hash map distributed across the planet.
Everything else in this article follows from that one difference.

Data model: rows you join vs items you fetch
In RDS, the schema is the contract. You declare your tables and columns and types up front, you add foreign keys, you add indexes, and the database enforces all of it. Then you query with SQL, and the magic of SQL is the join. You can ask questions you didn't design for, because the relational model lets you stitch tables together at query time.
-- Get the last 10 orders for a customer, with line items and product names.
SELECT o.id, o.placed_at, li.quantity, p.name
FROM orders o
JOIN line_items li ON li.order_id = o.id
JOIN products p ON p.id = li.product_id
WHERE o.customer_id = $1
ORDER BY o.placed_at DESC
LIMIT 10;You wrote this query today. Maybe line_items didn't even exist when orders was designed. Doesn't matter, the relational engine will join them for you. You'll add an index if it's slow, but you won't redesign the schema.
In DynamoDB, that query is the wrong question. There are no joins. There is no WHERE roles CONTAINS 'admin' without a Scan, and Scan is the move you almost never want. The only fast operations are GetItem (one item by full key) and Query (a range of items inside a single partition key). Everything you want to read fast has to be answered by one of those two operations, on a key you put there deliberately.
So you stop thinking "what's the entity?" and start thinking "what's the access pattern?" You list the questions your application will ask of this data, "get a user's profile by id", "list a user's orders by date", "get the full order with all line items", and you design keys that turn each of those questions into a single GetItem or Query.
A typical DynamoDB single-table layout for the same orders example might look like this:
PK | SK | data
--------------|--------------------|--------------------------------------
USER#42 | PROFILE | { email, name, timezone }
USER#42 | ORDER#2026-05-17#9 | { total, status }
USER#42 | ORDER#2026-05-16#7 | { total, status }
ORDER#9 | ITEM#1 | { product_id, qty, unit_price }
ORDER#9 | ITEM#2 | { product_id, qty, unit_price }
PRODUCT#abc | META | { name, price, sku }To get a user's last 10 orders, you Query partition USER#42 with sk begins_with "ORDER#", descending, limit 10, one call, one partition, one-digit milliseconds. To get the full order, you Query partition ORDER#9 and get the item rows. To enrich each line with the product name, you do a BatchGetItem on the PRODUCT#* partitions.
It works. It's fast. But notice what just happened: every read your app does was anticipated at schema-design time. The flexibility lives in your code now, not in the database.
That's the deal. RDS makes the database flexible; DynamoDB makes the application explicit.
Scale: vertical instance vs horizontal partition
RDS scaling has a well-worn ladder.
Step one is vertical, bigger instance class. db.t3.medium → db.m6i.2xlarge → db.r6i.8xlarge. More CPU, more RAM, more IOPS. You can take this surprisingly far. Modern Postgres on a fat box can comfortably hold tens of thousands of transactions per second if your queries are tight.
Step two is read replicas. RDS will stream the write-ahead log from your primary to one or more replicas, and you point read-only queries at them. This is great for read-heavy workloads, reports, dashboards, search, but every replica is eventually consistent (lag of a few hundred ms to several seconds is normal under load), so you can't read your own writes from a replica safely without thinking about it.
Step three is application-level sharding. You pick a sharding key, customer id, region, and you run multiple primaries with non-overlapping data. Now you've reinvented half of what DynamoDB does for free, except you wrote the routing code yourself, and joins across shards stop existing.
Aurora softens this. Its distributed storage layer separates compute from storage, so you can grow storage to 128 TB without resizing, add up to 15 read replicas with millisecond lag, and fail over fast. But the write path is still a single primary. If your bottleneck is write throughput on one shard's worth of data, Aurora doesn't change physics, it just gives you a nicer chair to sit in while you hit the ceiling.
DynamoDB scales differently because it never had a single primary to begin with.
A DynamoDB table is split into partitions automatically by AWS. Each partition handles a slice of the key space and gets a budget, by default, around 3,000 read capacity units and 1,000 write capacity units per second, per partition. When your table grows or your traffic grows, AWS splits the partition and rebalances data without telling you. There's no resize window, no failover, no replica lag to reason about for the basic table. The only way to hit a ceiling is to hammer a single partition key, the famous hot partition problem.
That single difference reshapes the whole conversation. With RDS, you plan capacity for the next twelve months and pick an instance class. With DynamoDB, you plan key distribution and let AWS handle the boxes.
This also means there's a kind of workload DynamoDB is uniquely good at: traffic that spikes from 100 req/s to 100,000 req/s and back, on a key space that's well-spread. On-demand DynamoDB will absorb that spike with no warning, no scaling action, and the bill at the end of the month will reflect roughly the work you actually did. RDS in the same scenario would either be over-provisioned for the baseline or page someone at 3am.
Consistency, transactions, and what "ACID" actually means here
If you've spent years in RDS, you've internalized full ACID transactions without thinking about it. BEGIN; UPDATE ...; UPDATE ...; COMMIT; either all happens or none of it does, and the database makes other connections wait or version their view of the world until you're done. Postgres in particular has very strong defaults. Read Committed by default, Serializable available if you ask.
DynamoDB has transactions, but they're a different shape.
TransactWriteItems lets you make up to 100 writes across multiple items (and multiple tables) atomically, all succeed or all fail. TransactGetItems gives you a snapshot read of up to 100 items. That's it. There is no concept of an open transaction you hold across multiple round-trips. There is no SELECT ... FOR UPDATE. Locking is done with conditional writes, "write this item, but only if its version attribute is still 7", which is optimistic concurrency, not pessimistic.
Reads also have a choice you don't get in RDS. By default, GetItem returns an eventually consistent read, which can be a few hundred milliseconds behind the latest write. You can ask for a strongly consistent read, which costs double the read capacity and is single-region only (Global Tables fall back to eventual cross-region). RDS has nothing to choose, you read your own writes from the primary, period.
The practical fallout:
If your workload looks like "transfer money between two accounts, must be atomic, must be auditable, must roll back on error". RDS makes this trivial. You wrap it in a transaction and move on. DynamoDB will do it, but you'll be hand-coding the transaction with conditional writes and idempotency tokens, and you'll spend real engineering time getting it right.
If your workload looks like "record this event, ack the client, fan out to processors". DynamoDB's model lines up beautifully. One conditional PutItem, optimistic concurrency, no lock contention even at huge scale.
The mistake people make in both directions: assuming DynamoDB can't do transactions at all (it can, you just have to design for them), and assuming RDS will happily handle 100k writes/sec on one row (it won't, row locks become contention very fast).
Queries, indexes, and the cost of asking a new question
In RDS, adding a new query is cheap. Write the SQL, run EXPLAIN, add an index if needed, deploy. Indexes cost storage and slightly slow down writes, but you can have many of them, on any columns, including partial indexes, expression indexes, and full-text indexes. The flexibility is what you're paying the relational tax for.
In DynamoDB, adding a new query usually means adding a new secondary index. There are two kinds:
A Global Secondary Index (GSI) is essentially a second copy of the table, keyed differently. You pick a different partition key (and optional sort key), and DynamoDB maintains the index asynchronously as you write to the base table. GSIs are eventually consistent, they have their own capacity budget you pay for, and you can have up to 20 of them per table (used to be 5; AWS raised the limit). Every write to the base table that touches the GSI's keys triggers an additional write to the GSI, billed separately. So a heavily-GSI'd table can easily 2x or 3x your write costs.
A Local Secondary Index (LSI) keeps the same partition key but adds a different sort key. It's strongly consistent with the base table, but you can only define LSIs at table creation and you're limited to 5 per table. Most teams skip LSIs and lean on GSIs.
Either way, you cannot ask "give me items where some-attribute = X" without either an index that's keyed by that attribute or a Scan. A Scan reads the entire table, paginated, paying for every item, fine for nightly jobs, suicide for real-time queries.
So in RDS, new queries are a database conversation. In DynamoDB, new queries are a schema migration plus a cost-model conversation.
Cost: provisioned hours vs pay-per-request
The two services bill in nearly opposite ways, and the mental model matters as much as the dollar figure.
RDS bills you for the instance while it exists, whether it's serving 0 queries or 50,000 queries per second. A db.r6i.2xlarge running 24/7 costs around the same per month regardless of load. You pay separately for the EBS storage (per GB), the IOPS if you're on gp3 or io1, the backup storage beyond your free quota, data transfer out, and the multi-AZ standby (which doubles instance cost and gives you HA).
The good news with RDS: predictable. You can do capacity math on a napkin, you can buy Reserved Instances or Savings Plans for ~30-60% off if your usage is stable, and you don't get surprise five-figure bills from a runaway loop.
The bad news: you pay for headroom. You usually over-provision for the peak, then sit idle through the trough. A workload that does 10x its baseline for 2 hours a day and 0.1x its baseline at night is a bad fit for the RDS pricing model.
DynamoDB has two pricing modes.
On-demand bills per read and per write. A Write Capacity Unit (WCU) is a strongly-consistent write of an item up to 1 KB; a Read Capacity Unit (RCU) is a strongly-consistent read of an item up to 4 KB (eventually consistent reads are half the RCUs). On-demand pricing is roughly 5x more per request than provisioned, but you literally pay zero when no one's using it. For spiky or unpredictable workloads, on-demand is hard to beat.
Provisioned lets you reserve a steady WCU/RCU per second, with optional auto-scaling. It's much cheaper per unit if your traffic is predictable, but if you under-provision, you get throttled, ProvisionedThroughputExceededException in your SDK. Reserved capacity (1-year or 3-year) shaves another 50%+ off provisioned.
You also pay for storage (per GB-month), data transfer out, streams reads if you use Streams or DynamoDB Kinesis, Point-in-Time Recovery if you enable it, and Global Tables replication (per WCU written to each replicated region).
The trap people fall into: comparing the headline numbers. "On-demand is 5x provisioned per request, so RDS must be cheaper than on-demand DynamoDB." Maybe. But RDS at 5% utilization is paying 95% headroom tax. DynamoDB at 5% utilization is paying 5% of the bill. And once you factor in the engineer-hours to keep a fleet of RDS instances healthy, the gap closes further.
A rough heuristic, not a rule, but a starting point:
| Workload shape | Often cheaper |
|---|---|
| Steady traffic, predictable peak | RDS (especially with Reserved Instances) |
| Spiky traffic, big peak-to-trough ratio | DynamoDB on-demand |
| Very high steady throughput on a single key space | RDS or Aurora (DynamoDB hot partition risk) |
| Very high steady throughput on a wide key space | DynamoDB provisioned with auto-scaling |
| Low traffic side service that mostly idles | DynamoDB on-demand (RDS still bills the box) |
When RDS is the right pick
RDS earns its keep when your data has real relationships and your queries are not all known on day one.
Reach for RDS when:
- The domain is genuinely relational. Orders have customers and line items, line items have products, products have categories, categories have tax rules, and you'll be asking questions across all of them. Joins are not a bug. They're the whole reason you're paying for a relational engine.
- Ad-hoc analytics and reporting matter. A BI tool, a "let me check something in the database" Slack message, an exec dashboard that aggregates yesterday's orders by region, these are SQL workloads, and they want a SQL database. (Even better: replicate from RDS into a warehouse for the heavy analytical queries, and keep transactional queries on RDS.)
- Strong transactions are part of the business logic. Money movement, inventory hold/release, anything that must be atomic across multiple rows and where wrong-but-consistent is worse than slow-but-correct.
- Your team's existing ORM, migration tool, and operational muscle memory all assume SQL. Don't underestimate this one, fighting your tools costs more than a slightly larger instance class.
- You're building a CRUD service of unknown future shape. A typical internal admin app, a customer-facing dashboard, an SaaS feature that will grow new query shapes monthly. Postgres on RDS will absorb a year of feature work without complaint.
The honest test: if you tried to enumerate every query your app will ever ask, and the list keeps growing as you write it, that's an RDS signal.
When DynamoDB is the right pick
DynamoDB earns its keep when access patterns are few, known, and high-traffic, or when the workload is so spiky that paying for idle RDS instances is irrational.
Reach for DynamoDB when:
- The data is naturally keyed. A session store. A user profile cache. A shopping cart by cart id. A device-state table by device id. A leaderboard partition. You always know the partition key when you read, and the query "give me X by id" is the whole API.
- The workload is huge or extremely spiky. Mobile-app backends, real-time event ingestion, ad-tech click logs, IoT telemetry, multiplayer game state, anything where the traffic profile is shaped like a flagpole. DynamoDB on-demand will scale into this without a runbook.
- You want operational silence. No primary failovers to think about, no read-replica lag to reason about, no minor-version upgrades to schedule, no parameter group to tune. You get a table; you read and write to it; you stop thinking about the database.
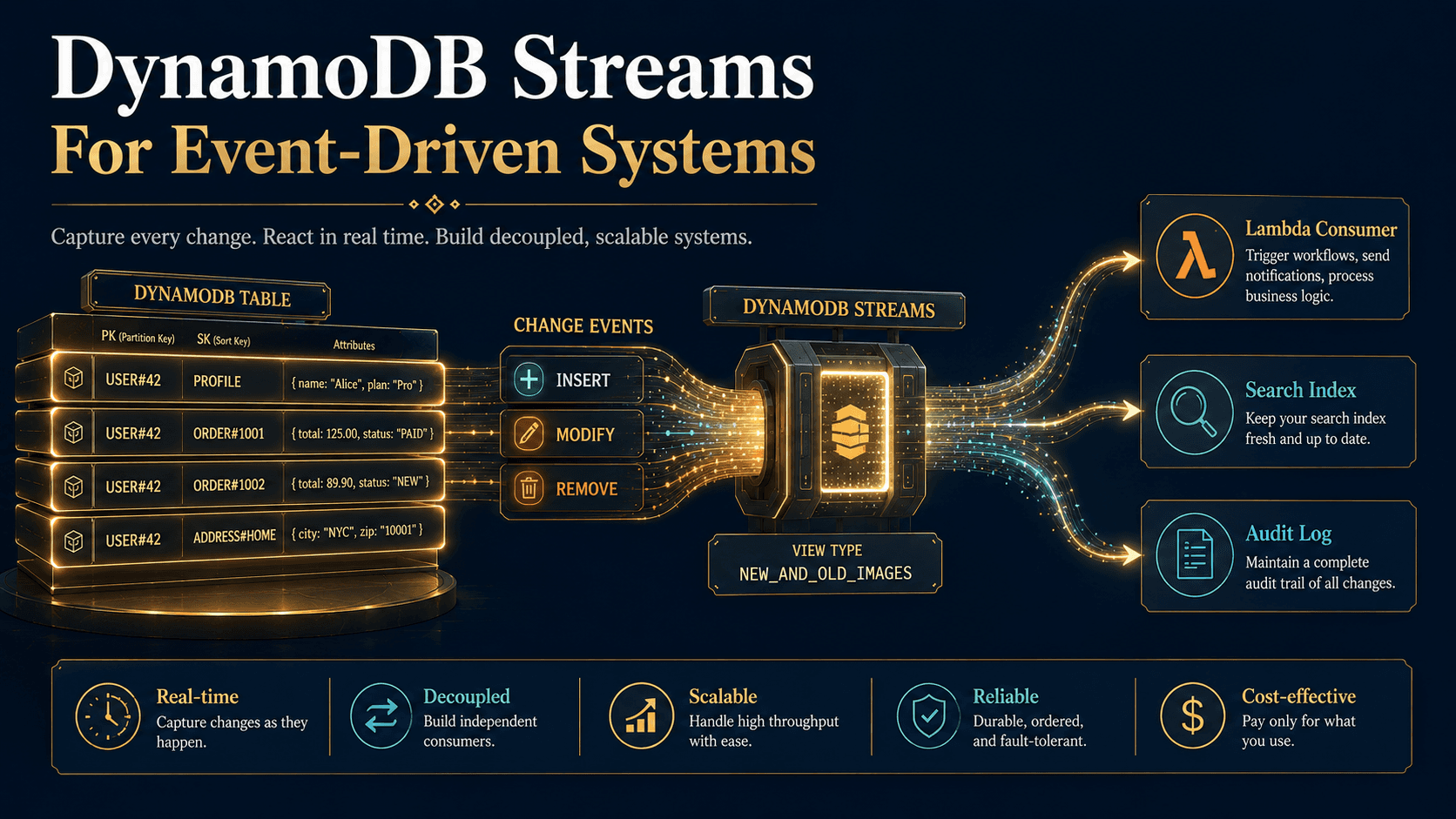
- You're embracing event-driven architecture. DynamoDB Streams emit a change log of every item modification, which plugs directly into Lambda or Kinesis. Building a Change Data Capture pipeline on top of RDS is doable (Debezium, logical replication) but it's never as plug-and-play.
- You're cost-sensitive on a low-traffic service. A tiny side service that handles 50 requests per hour pays $5/month on DynamoDB on-demand and $50/month for the smallest reasonable RDS instance. At small scale, the box tax matters.
The honest test: if you can write down every read your app will ever do on this data on the back of a napkin and you're confident the list is closed, that's a DynamoDB signal.
When neither is right
Both services have things they're genuinely bad at, and AWS sells better tools for those cases. Knowing the boundary is half of picking well.
If your queries are "find documents matching this text" or "items where this list of attributes contains values", that's OpenSearch territory. RDS full-text search works but underperforms. DynamoDB has no story for it at all.
If your workload is "big analytical aggregations across years of history", that's Redshift or Athena. RDS will technically run the query and your OLTP latency will fall off a cliff while it does. DynamoDB will refuse politely.
If your data is graph-shaped, "friends of friends, two hops out, filtered by activity", that's Neptune. SQL self-joins can express the query but performance degrades with depth. DynamoDB will not even pretend.
If your access pattern is "high-frequency reads of recent items, throwaway after 24 hours", that's ElastiCache (Redis or Memcached). Both RDS and DynamoDB will work; neither will be as cheap or as fast.
A common pattern in production is to use RDS or DynamoDB as the source of truth and one of these specialty stores as a satellite. OpenSearch indexed off DynamoDB Streams, Redshift loaded nightly from RDS, Redis cache in front of either. "One database to rule them all" is a developer fantasy, not a production architecture.
The decision question, simplified
When the question lands on your desk, ignore the brochures and ask yourself two things.
First: can you list every query your application will ever ask of this data? If yes, and the list is short, DynamoDB will be smaller, cheaper, and faster. If no, or if the list is long and changes monthly, RDS will save you from rebuilding the schema every quarter.
Second: what shape is your traffic? Steady, predictable, with a clear peak you can size for, RDS, especially with Reserved Instances, wins on cost. Spiky, unpredictable, or near-zero most of the time, DynamoDB's pay-per-request model wins by not making you pay for idle compute.
If both answers point the same way, the pick is easy. If they conflict, short access pattern list but spiky traffic, or unpredictable queries but steady load, go with the one whose failure mode you'd rather inherit. RDS's failure mode is "the instance is too small, I'll resize" (annoying, doable, downtime measured in seconds with Multi-AZ). DynamoDB's failure mode is "the access pattern we didn't anticipate is now a full table Scan, and either the query is slow or we add a GSI" (annoying, doable, no downtime).
Both pick "no downtime, just engineering work." That's why both stay popular.
The wrong move is to pick by what's trendy or what one engineer is comfortable with. The right move is to look at your data, look at your traffic, and pick the database that matches both, then commit to learning that one deeply instead of fighting it for years.