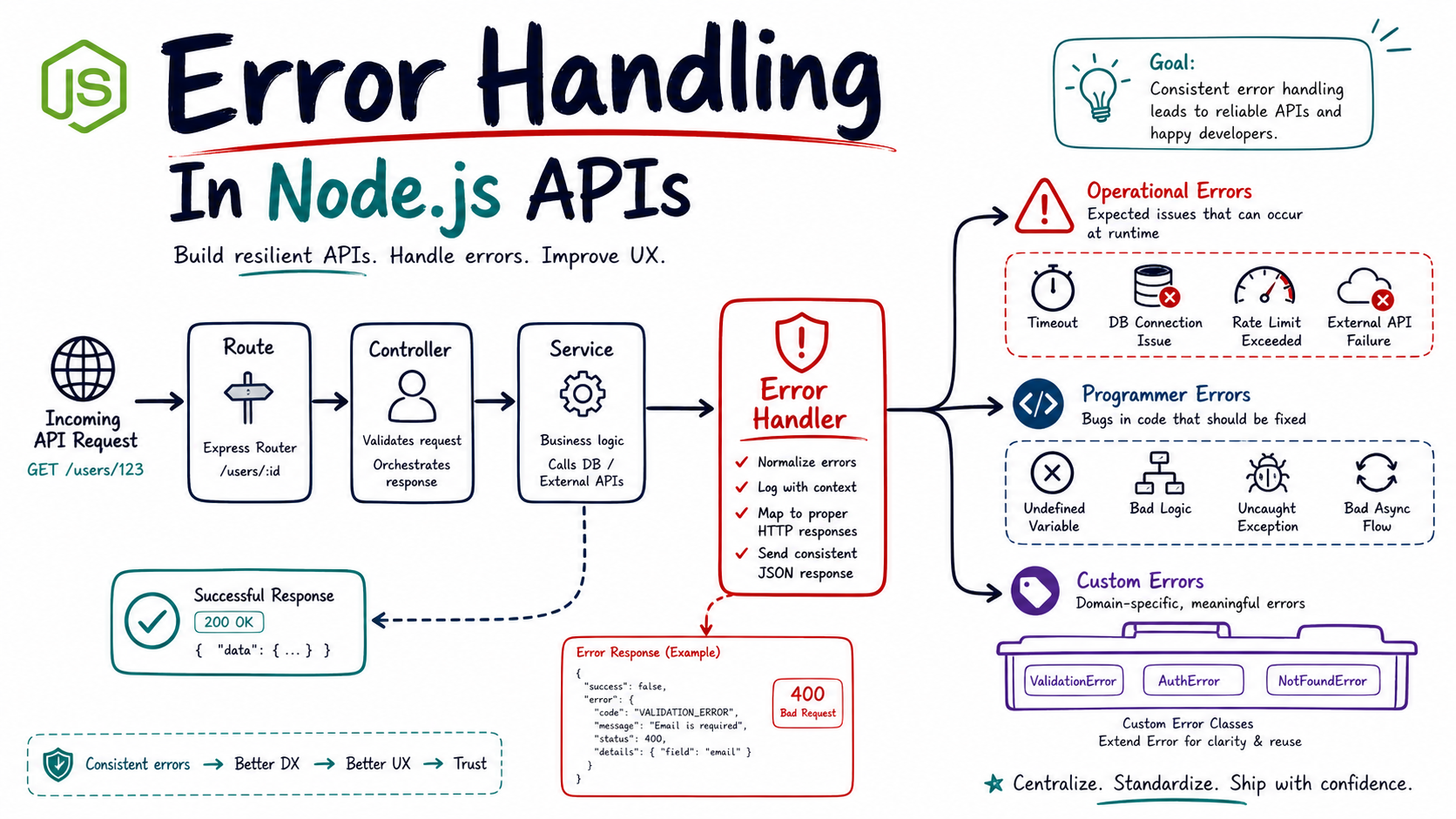
The first time you'll really care about error handling is the night a customer screenshots your stack trace back at you. Or when your logs show 47 different shapes of "failed" with no request ID to tie them together. Or when a thrown promise rejection silently kills the process during a deploy.
All three of those have the same root cause: nobody decided what an "error" is in this codebase. Different developers reach for different patterns at different layers, and the result is something between noise and cosplay. This article is the model I use to keep that under control.
Operational vs Programmer Errors
The single most useful classification, borrowed from the original Joyent error guide, is older than half the codebases that need it:
- Operational errors are expected failures in correctly-written code: a network call timed out, a record didn't exist, the user sent invalid input, you ran out of disk. The right response is to handle the case and move on.
- Programmer errors are bugs: a
TypeError, anundefinedaccess, a logic error, an off-by-one. The right response is to log loudly, fail the request, and fix the code. You cannot recover from these — pretending you can hides bugs.
Mixing them is the root cause of most error-handling bad smells. A service that catches every try/catch and returns "something went wrong" is treating bugs as operational. A service that crashes on an expected 404 is treating operational issues as bugs. Both are wrong, in different directions.
Custom Error Classes Are Cheap
Don't throw strings. Don't throw plain objects. Throw classes that carry the metadata your error middleware needs to do its job.
export class AppError extends Error {
constructor(
message: string,
public statusCode = 500,
public code = 'internal_error',
public expose = false, // safe to send to the client?
) {
super(message);
this.name = new.target.name;
}
}
export class BadRequest extends AppError { constructor(m: string, c='bad_request') { super(m, 400, c, true); } }
export class Unauthorized extends AppError { constructor(m='unauthorized') { super(m, 401, 'unauthorized', true); } }
export class Forbidden extends AppError { constructor(m='forbidden') { super(m, 403, 'forbidden', true); } }
export class NotFound extends AppError { constructor(what: string) { super(`${what} not found`, 404, 'not_found', true); } }
export class Conflict extends AppError { constructor(m: string, c='conflict') { super(m, 409, c, true); } }
export class TooMany extends AppError { constructor(m='rate limited') { super(m, 429, 'rate_limited', true); } }The expose flag is the underrated part. It says "this message is safe to show the user." For programmer errors and unknown failures, expose is false — the middleware sends a generic message and the real one stays in the logs.
One Error Middleware To Rule Them All
Wire one place that knows how to translate any thrown thing into an HTTP response. Nothing else in your code should call res.status(...).json(...) for errors.
import { ZodError } from 'zod';
import { AppError } from '../errors';
export function errorHandler(err, req, res, _next) {
// 1. zod errors -> 400 with field details
if (err instanceof ZodError) {
return res.status(400).json({
error: 'validation_failed',
details: err.flatten(),
requestId: req.id,
});
}
// 2. our own classified errors
if (err instanceof AppError) {
req.log?.warn({ err, code: err.code }, 'operational error');
return res.status(err.statusCode).json({
error: err.expose ? err.message : 'internal_error',
code: err.code,
requestId: req.id,
});
}
// 3. everything else is a bug
req.log?.error({ err }, 'unhandled error');
res.status(500).json({
error: 'internal_error',
code: 'internal_error',
requestId: req.id,
});
}Note the log levels: operational errors are warn (expected, useful for trending), unknown errors are error (a bug, alert on this). Don't log every 404 as error — your alerting will hate you and you'll start ignoring it.

Async Errors, Without The Footgun
The Express 4 trap: throw inside an async handler that isn't awaited correctly, and the request hangs. The fix is a 5-line wrapper or — in Express 5 — nothing, because async errors propagate by default.
export const asyncHandler =
(fn) => (req, res, next) =>
Promise.resolve(fn(req, res, next)).catch(next);Then router.post('/', asyncHandler(async (req, res) => { ... })). In Fastify, async handlers always propagate — no wrapper needed.
The other footgun is swallowing errors. A try/catch that does nothing useful is worse than no try/catch — it hides the failure and the next person reading the code thinks the path is safe. If you catch, you must do one of three things: handle it, transform it (throw new NotFound('user')), or rethrow.
unhandledRejection And uncaughtException
Despite all the wrappers, things will still slip through. A rejected promise nobody awaited, a setTimeout callback that throws — these don't go through your error middleware because they don't go through any handler at all.
process.on('unhandledRejection', (reason) => {
logger.fatal({ reason }, 'unhandledRejection — crashing');
shutdown('unhandledRejection');
});
process.on('uncaughtException', (err) => {
logger.fatal({ err }, 'uncaughtException — crashing');
shutdown('uncaughtException');
});The right policy is log fatally and exit. Recovering from these is undefined behavior — V8 may have left state in a corrupt place. Let your orchestrator restart the process. The reason this is the right policy: if you swallow them, you'll deploy a service that quietly leaks promises forever, and you'll find out on a Sunday.
Errors From The Database And External APIs
Two boundaries that need translation, not pass-through.
Database: Prisma throws PrismaClientKnownRequestError with a .code. Map the relevant ones (P2002 unique constraint → Conflict, P2025 not found → NotFound) inside the repo so the service never sees P2002. Same for pg (23505 is a unique violation), mysql2, etc. The service speaks domain errors. The repo translates infrastructure errors into domain errors.
External APIs: A fetch to a third party can fail in many shapes — DNS, TLS, 5xx, timeout, malformed JSON. Wrap each external client in a thin adapter that throws one custom error class for "external dependency unavailable" so retry logic and circuit breakers have something to match on. AbortController with a timeout signal is your friend here.
const ctrl = new AbortController();
const t = setTimeout(() => ctrl.abort(), 3000);
try {
const res = await fetch(url, { signal: ctrl.signal });
if (!res.ok) throw new ExternalUnavailable(`${url} -> ${res.status}`);
return res.json();
} finally {
clearTimeout(t);
}A One-Sentence Mental Model
Decide once what an error is in your service — operational or programmer, expected or bug — and let one middleware translate it into one HTTP response while one logger captures one shape, so the next incident is a query, not an investigation.





