
So, you've broken the monolith into services. You replaced the chatty synchronous calls with events on a broker, drew an architecture diagram with clean little arrows that all point one way, and for a beautiful few weeks everything felt like it should.
Then someone clicks the same checkout button twice in a flaky elevator and gets charged twice. A worker pod gets OOM-killed mid-batch and you spend the morning trying to figure out which orders got fulfilled and which didn't. A user updates their email, refreshes the page, and sees their old email staring back at them. Your dashboard shows green. Your customers do not.
Welcome to event-driven architecture, where the failure modes don't go away. They just put on different clothes and move next door.
EDA is a great answer to a real problem. When two services talk to each other through a queue instead of an HTTP call, the producer doesn't care if the consumer is up. The consumer can scale on its own pace. New consumers can join later without the producer ever knowing. That's actual, durable decoupling, and once you've felt it, going back to a tangle of synchronous chains feels like wearing a wool sweater on a hot day.
But the trade is real, and most teams discover it the same way: by being burned by it. So before you reach for the broker, it's worth being honest about what you're swapping in and what you're swapping out, and what the boring, well-understood patterns are for handling the swap.
Decoupling Isn't Free, You Just Move The Failure Modes
Here's the mental shift that helps most: in a synchronous system, your failure mode is the call failed. It's loud, it's local, and it's almost always handled in one place: wrap it in a try/catch, retry a couple times, propagate the error.
In an event-driven system, the failure modes are quieter and they've spread out. The event might be delivered. Or delivered twice. Or delivered six minutes from now. Or delivered after the next event arrives. Or never delivered, because the producer crashed between writing to its database and publishing the event. Or delivered fine, but the consumer crashed halfway through processing and the broker re-delivered it, and now the side-effect happened twice.
None of these are exotic. All of them happen in normal production, on normal Tuesdays. They show up because the broker, the consumer, and the producer are now three independent things that can fail independently.
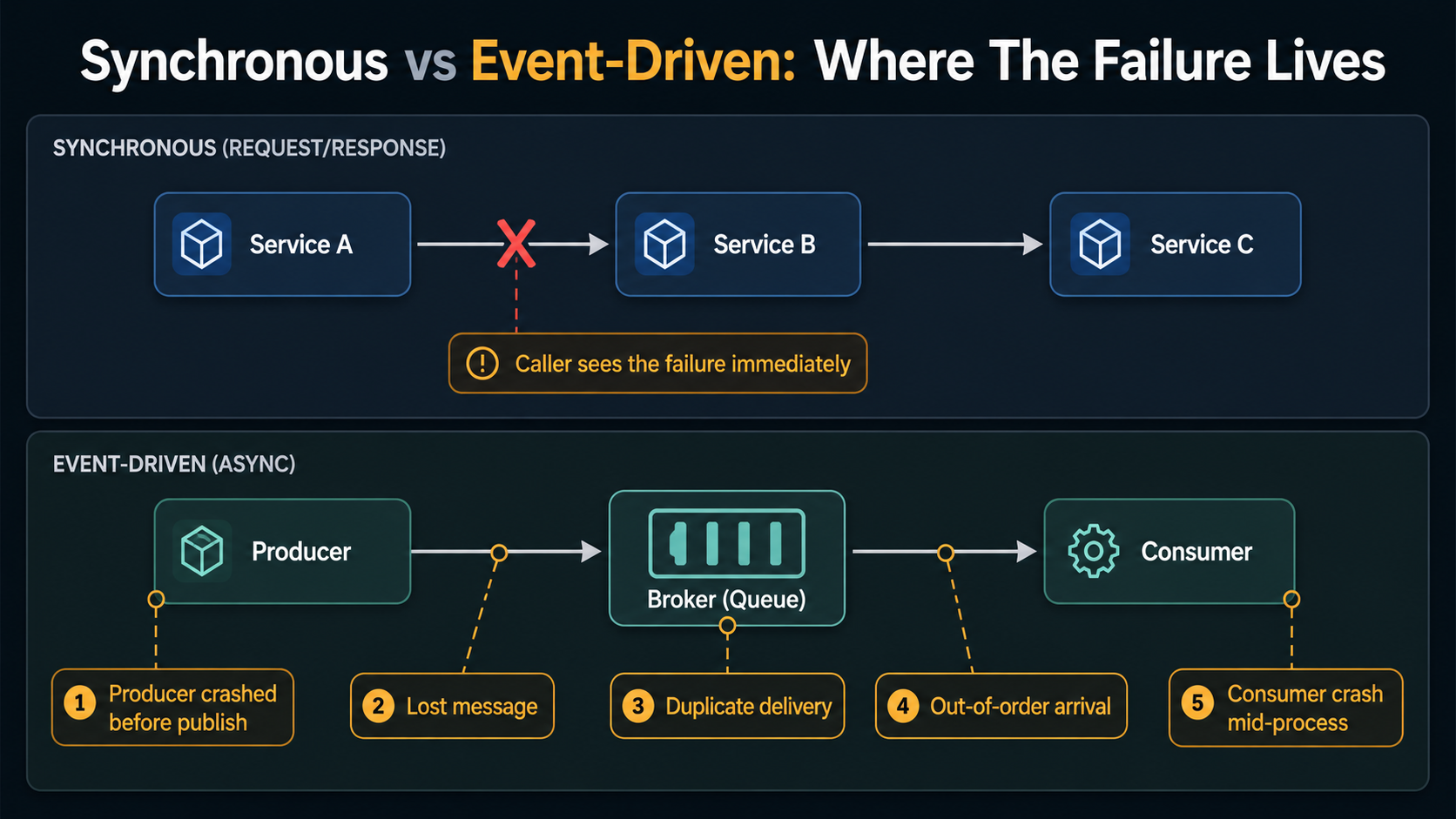
The point isn't that EDA is bad. It's that the work you used to do in one place, handling failure in the calling code, is now spread across the producer, the broker config, the consumer, and your data model. Pretending that's not the case is how you end up with the duplicate-charge bug.
Once you accept that, the rest of this article is just a tour through the specific failure modes and the boring, well-tested patterns that handle each one.
At-Least-Once Is The Default, Get Used To It
The first thing to internalize: almost every popular message broker gives you at-least-once delivery by default, not exactly-once. Kafka, SQS, RabbitMQ, NATS JetStream, Pub/Sub. Same story. They all promise that if you publish a message, a consumer will eventually receive it. They do not promise it will receive it exactly one time.
Some of them sell "exactly-once" with serious caveats. Kafka has exactly-once semantics, but only end-to-end within Kafka (transactional producer + idempotent consumer + read-process-write loop using Kafka topics for state). The moment your consumer writes to Postgres or calls a third-party API, you're back in at-least-once territory because the broker has no way to make your external side-effect transactional.
So the working assumption is: any consumer of any event might run twice. Sometimes more. Plan for it.
This is the single most important shift, because it determines how you write almost every handler. A handler that assumes "this code runs once per event" is a bug waiting to ship.
Idempotency Is The Price Of Admission
Idempotency just means: running the operation twice produces the same outcome as running it once. For an event handler, that's the contract you owe the broker.
The naive way of writing a handler looks fine in dev and quietly bills your customers twice in production:
async function handleOrderPlaced(event: OrderPlacedEvent) {
await charges.charge(event.userId, event.amount);
await orders.markAsPaid(event.orderId);
}async def handle_order_placed(event: OrderPlacedEvent) -> None:
await charges.charge(event.user_id, event.amount)
await orders.mark_as_paid(event.order_id)func HandleOrderPlaced(ctx context.Context, e OrderPlacedEvent) error {
if err := charges.Charge(ctx, e.UserID, e.Amount); err != nil {
return err
}
return orders.MarkAsPaid(ctx, e.OrderID)
}Reads beautifully. Charges twice the moment the broker re-delivers. And the broker will re-deliver: every time the consumer crashes after charge and before markAsPaid, every time an ack is lost on the network, every time you scale your consumer group and a partition rebalances mid-message.
The fix has two flavors, and you usually want both: an idempotency key that uniquely identifies the operation, and a processed-events table that lets the consumer skip work it has already done.
The key is the easy part. For an event-handler, the event ID is the natural choice. The broker assigns one (or you do, at the producer). The processed-events table is a small table whose only job is to remember which event IDs you've already handled, with a unique constraint:
CREATE TABLE processed_events (
event_id UUID PRIMARY KEY,
handler TEXT NOT NULL,
processed_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);handler is in there because the same event often goes to multiple consumer groups, and each one needs its own dedup state. Now the handler wraps its real work in an insert-then-do-the-thing pattern, with both inside one DB transaction so a crash in the middle rolls back cleanly:
async function handleOrderPlaced(event: OrderPlacedEvent) {
await db.transaction(async (tx) => {
const inserted = await tx
.insertInto('processed_events')
.values({ event_id: event.id, handler: 'charge-on-order-placed' })
.onConflict(c => c.doNothing())
.returning('event_id')
.executeTakeFirst();
if (!inserted) return; // already processed — skip silently
await charges.charge(event.userId, event.amount, { idempotencyKey: event.id });
await orders.markAsPaid(event.orderId, { tx });
});
}Two things to notice. First, the onConflict.doNothing() plus the returning check is the cheap exclusive-lock equivalent across most databases. If two consumers race on the same event, one inserts and proceeds, the other sees no rows and bails. Second, the idempotencyKey passed to charges.charge. Most modern payment APIs (Stripe, Adyen, Braintree) accept an idempotency key precisely because they know their callers retry. Use it.
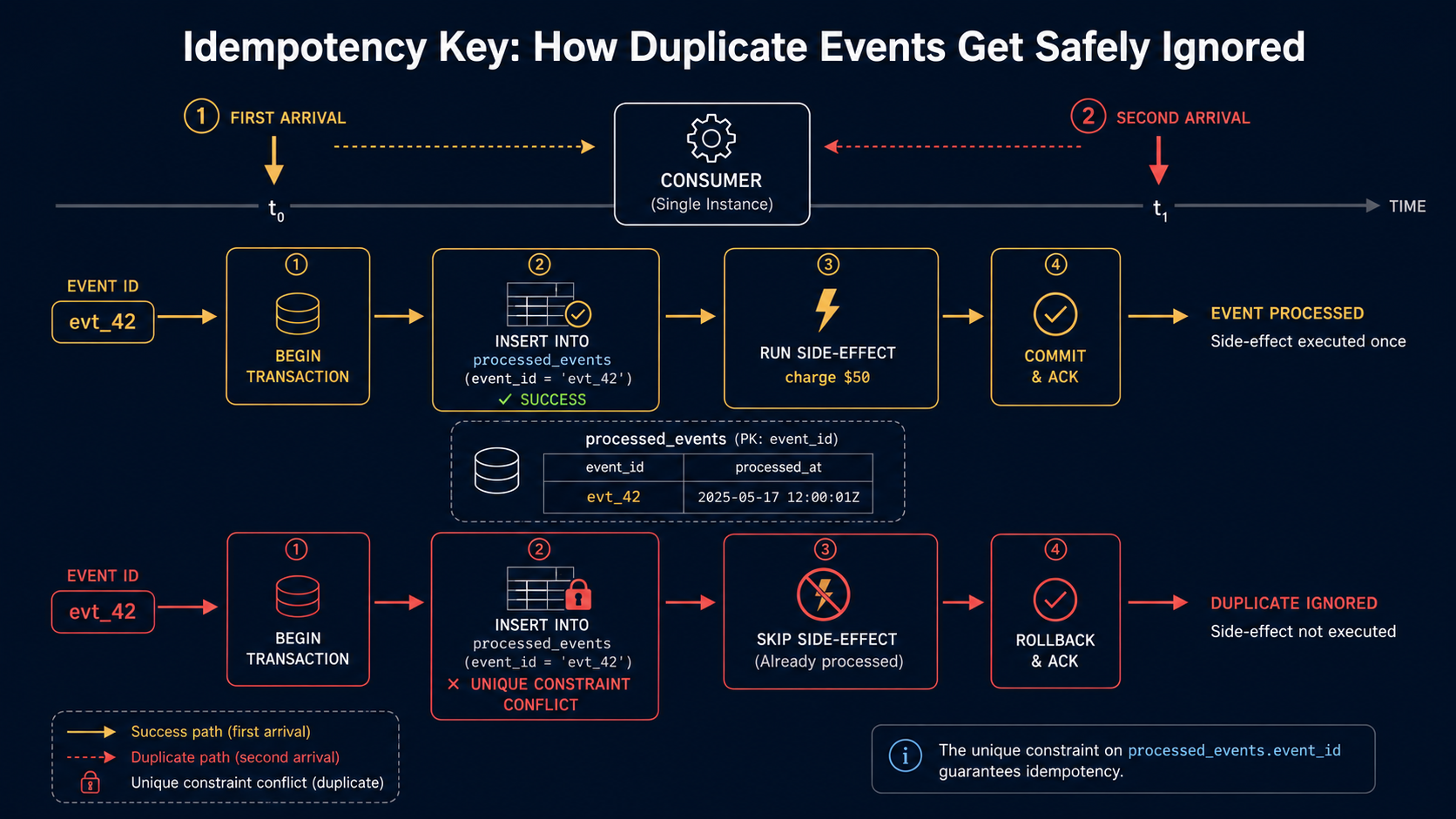
What about non-DB side-effects? Sending an email, calling an external API, dropping a file in S3? Two options. Either the external system supports an idempotency key directly (most modern ones do), or you wrap the side-effect inside the same dedup transaction so a crash before commit means the side-effect didn't "count", even though it actually happened. That second option is a trade-off: you might send an email twice if the consumer crashes between the API call and the commit. For email that's usually fine; for charging a credit card it isn't. Pick the side-effect strategy per handler, based on how bad a duplicate actually is.
Retries Look Easy Until They Don't
Most brokers retry for you. SQS visibility timeouts, RabbitMQ requeues, Kafka commit offsets. They're all variants of "the consumer didn't ack, so we'll send it again." That's helpful right up until the moment a single bad message gets stuck in an infinite retry loop and saturates your consumer pool.
Three patterns handle this, and you want all three.
Backoff with jitter. Don't retry immediately. The thing you depend on (downstream API, database, third-party service) is probably struggling, and hammering it harder is the opposite of helpful. Exponential backoff with jitter is the well-trodden path:
func withBackoff(ctx context.Context, op func() error, maxAttempts int) error {
var lastErr error
for attempt := 0; attempt < maxAttempts; attempt++ {
if err := op(); err == nil {
return nil
} else {
lastErr = err
}
// base * 2^attempt, capped at 30s, with up to 1s of random jitter
base := 200 * time.Millisecond
delay := time.Duration(math.Min(
float64(base)*math.Pow(2, float64(attempt)),
float64(30*time.Second),
))
delay += time.Duration(rand.Int63n(int64(time.Second)))
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(delay):
}
}
return lastErr
}The jitter matters more than people think. Without it, every retrying consumer hits the downstream service at the same backoff intervals, which is how you turn a brief outage into a synchronized stampede every two seconds.
A retry cap and a Dead Letter Queue. You can't retry forever. Past some attempt count, usually somewhere between 5 and 25 depending on the workload, the message goes to a DLQ for human inspection. SQS, RabbitMQ, Kafka, Pub/Sub, all of them have this concept built in or one config away.
The DLQ message should carry enough context to figure out what happened without going back to logs:
{
"originalMessage": {
"id": "evt_8f3a...",
"type": "OrderPlaced",
"payload": { "orderId": "ord_91...", "userId": "usr_12...", "amount": 4900 }
},
"failureMetadata": {
"attempts": 12,
"firstFailedAt": "2022-02-10T14:22:11Z",
"lastFailedAt": "2022-02-10T14:47:03Z",
"lastError": "PaymentGatewayTimeout: upstream returned 504 after 30s",
"consumer": "billing-worker-v3",
"traceId": "1b9f2e..."
}
}When something lands in the DLQ at 3am, the on-call engineer should be able to look at that JSON and immediately know whether it's a poison message (broken payload, will never succeed) or a transient failure (downstream was down). Without the failure metadata, every DLQ entry is a mystery.
Distinguish retryable from non-retryable failures. A 503 from a downstream API is retryable: wait, try again. A 400 because the payload is malformed is not. It's never going to succeed, and retrying it 25 times before giving up wastes capacity and delays everything else in the queue. The handler should classify the error and tell the broker to either retry or send to DLQ immediately:
class RetryableError extends Error {}
class PoisonMessageError extends Error {}
async function handle(event: Event) {
try {
await processEvent(event);
} catch (err) {
if (isClientError(err)) {
// 4xx-style: malformed input, validation failure, missing referenced data
throw new PoisonMessageError(err.message);
}
if (isTransient(err)) {
// 5xx, timeouts, network blips, deadlocks
throw new RetryableError(err.message);
}
throw err; // unknown — be conservative and treat as retryable
}
}Your worker framework then routes PoisonMessageError straight to the DLQ and lets RetryableError go through the backoff loop. This single distinction will save you more pages than any other change.
Out-Of-Order Delivery: Even FIFO Isn't Always FIFO
A surprise that catches teams late: even on a "FIFO" queue, parallel consumers can process messages out of order. SQS FIFO uses message group IDs to keep messages in order within a group, not across the whole queue. Kafka guarantees order within a partition, not across partitions. RabbitMQ doesn't guarantee order across consumers at all.
So if you have ten parallel consumers all pulling from the same queue, and three messages for the same order arrive close together, you can end up handling OrderShipped before OrderPaid before OrderCreated. Then your handler tries to ship an order that doesn't exist yet, throws, retries, and eventually lands in the DLQ, when nothing was actually broken.
Two main ways to handle it.
The first is partition by entity so all events for a single entity hit the same consumer in order. In Kafka, that means using the entity ID (order ID, user ID) as the partition key. In SQS FIFO, that's the MessageGroupId. The trade-off is that you can't parallelise within a partition: one slow event for an entity blocks all later events for the same entity. That's usually fine for entity-level workloads.
The second is make the handler order-tolerant. The handler reads the current state of the entity, decides what the event means in that context, and applies the change idempotently. If an OrderShipped event arrives before the order exists, you can treat it as "skip until you see the create" or "create the entity in a partial state." Either way, the handler doesn't crash; it cooperates.
This is also where event-version fields earn their keep. If every event for an entity carries a monotonically increasing version, the handler can compare-and-skip:
async def handle(event: dict) -> None:
order = await orders.get(event["order_id"])
if order is None:
# depending on type, either create from this event or wait for OrderCreated
return await handle_missing_order(event)
if event["version"] <= order["version"]:
# we've already seen this or a newer state — drop it
return
await orders.apply(event)The version field doesn't have to be magic. A sequence number from the producer, an event timestamp with reasonable resolution, or even a per-entity counter all work. What matters is that the handler can answer "is this event still relevant?" without asking the producer.
Eventual Consistency Is A UX Problem, Not Just A Database Problem
This one's worth its own section because it's the failure mode users feel most directly.
In a synchronous system, when the user clicks "Save", the server returns 200 and the next page-load shows the change. In an event-driven system, the API that handled the click might publish an event, return 200 immediately, and rely on a downstream consumer to actually update the read model the next page-load reads from. The save "happened", but it hasn't propagated yet. The user refreshes, sees the old data, and loses faith in your software.
This is read-your-writes, and it's almost always solved at the edge, not in the data layer. A few patterns that work:
Read from the write source for the user who just wrote. After the user submits, route their next read to the primary database (or the write-optimized service) for a short window. Most "stale UI" complaints are about your own writes; reading your own writes from the source of truth is the most reliable fix.
Optimistic UI updates. Show the change immediately in the client, even before the server confirms. If the write fails, roll it back. This is what every modern productivity app does. Linear, Notion, Figma all update the local state before the server has acknowledged. It works because the user almost always sees what they expect to see, and the cases where the write actually fails are rare enough that a polite retry-or-undo banner handles them.
Wait-for-version polling. When the client needs to reflect a server-side computation that runs after the event, the response can include a "this will be ready at version N" hint, and the client polls until the read model catches up. Less elegant, but honest about what's actually happening.
Show the propagation explicitly. Sometimes the right answer is to just tell the user. A "your changes are syncing..." banner with a checkmark when it's done is more honest than pretending the system is synchronous when it isn't. Slack does this in places. So does GitHub.
The wrong answer is to pretend eventual consistency doesn't exist and let users discover it through bug reports. Decide upfront, per surface, how stale data can be and how the UI handles the gap.
The Dual-Write Problem (And The Outbox Pattern)
Now we get to the failure mode that bites teams hardest, because it looks like it shouldn't be possible.
You're handling a request. You write to your database. You publish an event. Both succeed, the user gets a 200, life is good. Until one day, the database write succeeds, your service crashes before publishing the event, and now your DB and downstream consumers are permanently out of sync. There's no retry that'll fix it. The event was never published; nobody knows it should have been.
This is the dual-write problem, and naïvely-written EDA code is full of it:
// THIS IS THE BUG
async function placeOrder(input: PlaceOrderInput) {
const order = await db.orders.insert(input); // ✅ committed
await broker.publish('OrderPlaced', { orderId: order.id }); // ❌ may never run
return order;
}You can't solve this by reordering: publishing first means the event might fire for an order that didn't actually save. You can't solve it with retries either, because by the time you'd retry, the response has already gone out. You need a transactional boundary that includes both the data change and the intent to publish.
The well-trodden solution is the transactional outbox pattern. Instead of publishing directly, you write the event to an outbox table in the same DB transaction as the business write. A separate publisher process polls the outbox, publishes any new rows to the broker, and marks them as published. If your service crashes between insert and publish, the row sits in the outbox until the publisher comes back up and finds it.
CREATE TABLE outbox (
id BIGSERIAL PRIMARY KEY,
aggregate_id UUID NOT NULL,
event_type TEXT NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
published_at TIMESTAMPTZ
);
CREATE INDEX outbox_unpublished_idx ON outbox (created_at) WHERE published_at IS NULL;The handler now writes to two tables in one transaction:
func PlaceOrder(ctx context.Context, db *sql.DB, input PlaceOrderInput) (Order, error) {
var order Order
err := withTx(ctx, db, func(tx *sql.Tx) error {
var err error
order, err = ordersRepo.Insert(ctx, tx, input)
if err != nil {
return err
}
return outboxRepo.Insert(ctx, tx, OutboxRow{
AggregateID: order.ID,
EventType: "OrderPlaced",
Payload: mustMarshal(order),
})
})
return order, err
}And a publisher loop, separate from the request path, drains the outbox into the broker:
func runOutboxPublisher(ctx context.Context, db *sql.DB, broker Broker) {
ticker := time.NewTicker(500 * time.Millisecond)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
rows, err := outboxRepo.FetchUnpublished(ctx, db, 100)
if err != nil {
log.Error("outbox fetch failed", "err", err)
continue
}
for _, row := range rows {
if err := broker.Publish(ctx, row.EventType, row.Payload, row.ID); err != nil {
log.Warn("publish failed; will retry", "id", row.ID, "err", err)
continue
}
if err := outboxRepo.MarkPublished(ctx, db, row.ID); err != nil {
// event was published but we couldn't mark it — consumer will see a duplicate
// (this is fine, because consumers are idempotent, right?)
log.Warn("mark-published failed", "id", row.ID, "err", err)
}
}
}
}
}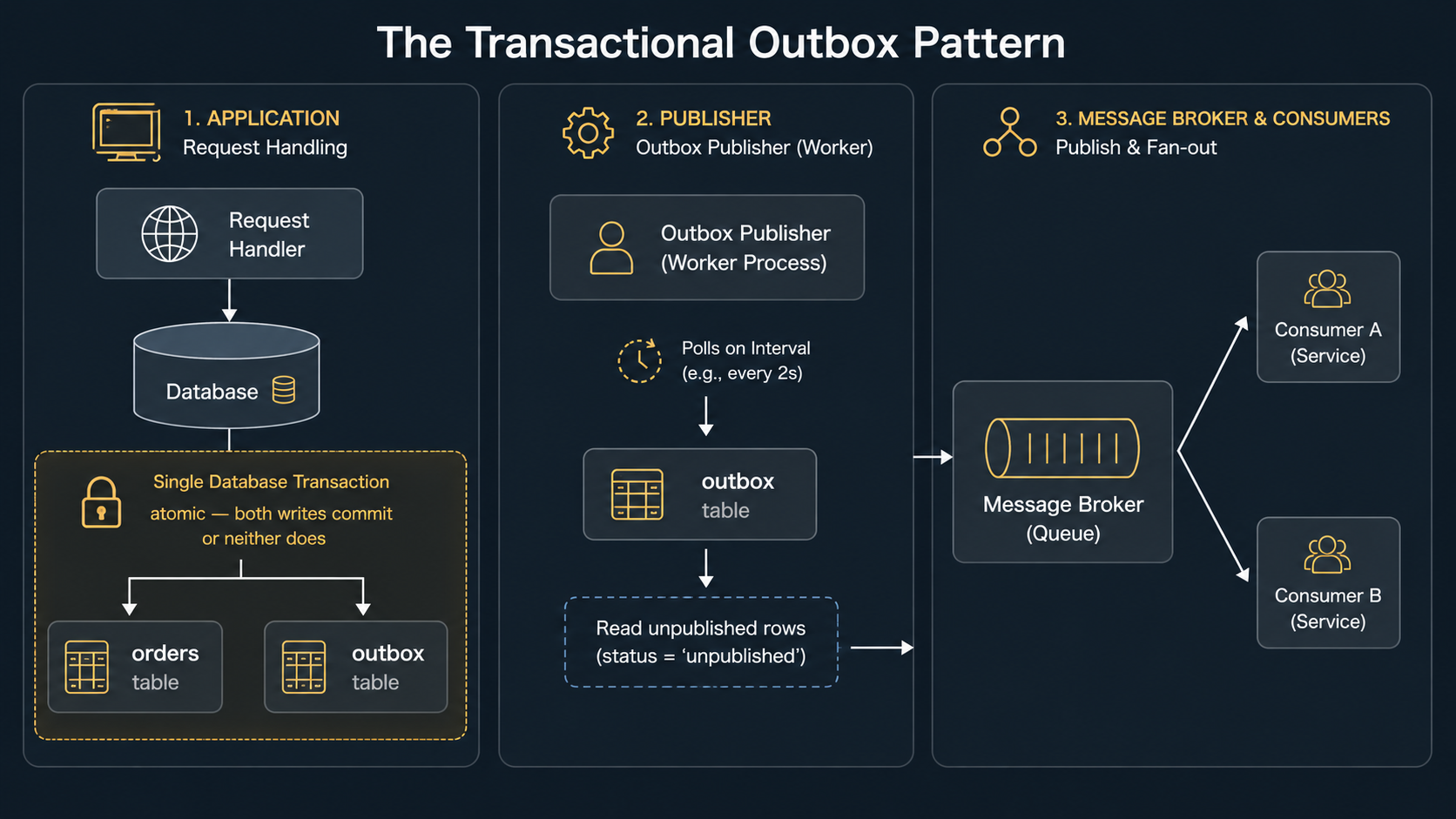
Notice the comment in MarkPublished: if the publish succeeds but the mark fails, the publisher will retry the same event next tick and the consumer will see a duplicate. That's fine, because consumers are idempotent, which is exactly the contract from the section above. Outbox and idempotency are best friends; one without the other only fixes half the problem.
If polling feels too crude, the same idea works with change data capture: Debezium, Maxwell, AWS DMS streaming events from the database's write-ahead log directly into the broker. CDC is operationally heavier but skips the polling entirely and tends to scale better at high event rates. The mental model is the same: the only thing the request handler ever does is write to its own database. Everything downstream is somebody else's problem.
A Few Smaller Failure Modes Worth Knowing
A handful of footguns that don't deserve their own section but will surprise you:
Schema evolution. The producer ships a new field. Six consumers read events from this topic. Two get redeployed today, three next week, one is owned by another team and might never get redeployed. If you add fields without thinking about backward compatibility, the old consumers crash on the new payload. The fix is the same as for any contract: add fields, never remove or rename; mark optional; bump a version field when behaviour changes; consider a schema registry (Confluent Schema Registry, Apicurio) if you're at any scale.
Slow consumers. A consumer that's slower than the producer falls behind. Lag grows. Eventually the broker either drops messages (if it has a retention limit) or your storage bill turns into a horror show. Lag is the single most important metric for an event-driven system. Alert on it before alerting on almost anything else.
Replays. Sooner or later you'll need to replay events: bug fix, data backfill, new consumer joining. If your handlers aren't idempotent, replaying is a one-way trip to data corruption. If they are, replays are routine. (Are you noticing a theme? Idempotency is the foundation everything else sits on.)
Observability. A request that touches five services through a chain of events leaves five different logs in five different services with no obvious connection. Distributed tracing (OpenTelemetry, W3C trace context propagated through event headers) and correlation IDs in every event payload turn this from "impossible to debug" back into "annoying to debug." Don't ship EDA without it.
When Decoupling Pays Off
Reading all that, you'd be forgiven for thinking event-driven architecture is a maze of footguns. It's not. It's a maze of known footguns, every one of which has a well-trodden pattern attached.
EDA pays off when you genuinely need the decoupling. New consumers added without touching the producer. Asynchronous workloads that don't belong on the request path (sending emails, generating thumbnails, syncing to a warehouse). Bursty workloads that need a buffer between producer and consumer so the producer doesn't have to wait for the consumer to scale. Multi-team systems where coordinating a synchronous deploy across services would be painful every week.
It does not pay off when you reach for it because microservices feel modern and queues feel decoupled. A two-service system that calls each other once per request, where both teams sit five feet apart, doesn't need a broker between them. An HTTP call is a fine, simple, observable, cheap thing. The cost of EDA is that every operation is now async, every handler needs an idempotency story, every dual write needs an outbox, and every UI surface needs a stance on staleness. That's a lot of tax to pay for "loose coupling" that you might not actually need.
The honest version of the trade is: synchronous calls couple services in time (both must be up). Events couple services in contract (both must agree on the schema, forever, with backward compatibility). You're not removing coupling. You're trading time-coupling for contract-coupling, and contract-coupling is, in the long run, harder to undo.
If that trade buys you something real (independent deploys, async work, fan-out, isolation between teams), take the deal, with the patterns above bolted in from day one. If it doesn't, keep the HTTP call. The boring choice is often the right one.





