Pop quiz. You have ten microservices. Service A creates an order. Services B, C, and D each need to know about it, one ships it, one bills it, one emails the customer. Service E will exist next quarter and also needs to know. What do you reach for?
If the answer that came to mind was "SNS topic with three subscribers, and I'll wire E in later", you are in the majority. SNS is fine. It works. It's also probably the wrong answer for half the teams that pick it, because there's another AWS service sitting one tab over in the console that was built for exactly this problem, and most backend developers still treat it like a CloudWatch detail rather than a routing layer.
That service is EventBridge. This piece is about why you should reach for it more often, what it actually does under the hood, and the specific places it bites you in production so you don't find out at 2am.
Where EventBridge actually came from
EventBridge is not a new service. It's a 2019 rebrand of something older you have definitely used, Amazon CloudWatch Events, which launched in January 2016. CloudWatch Events was the thing that fired your scheduled Lambdas via cron expressions and reacted to EC2 state changes. In July 2019 AWS layered a partner-source story on top of it, opened up custom buses for application events, and renamed the whole thing EventBridge. Under the hood the API is still backward-compatible, so old CloudWatch Events rules kept working without code changes.
Since then the service has grown, and not in a small way. Schema Registry went GA in April 2020. Archive and Replay shipped November 2020, and you can rewind a bus and re-emit events through your rules, which is the kind of feature you don't appreciate until the first time you ship a bug that swallowed three days of orders. API Destinations in March 2021 turned EventBridge into a general HTTP fan-out, not just an AWS-internal router. And the headline addition: EventBridge Pipes at re:Invent 2022, which we'll get to.
If you last looked at EventBridge in 2019 and thought "this is CloudWatch Events with marketing", that mental model is genuinely out of date.
The model in one paragraph
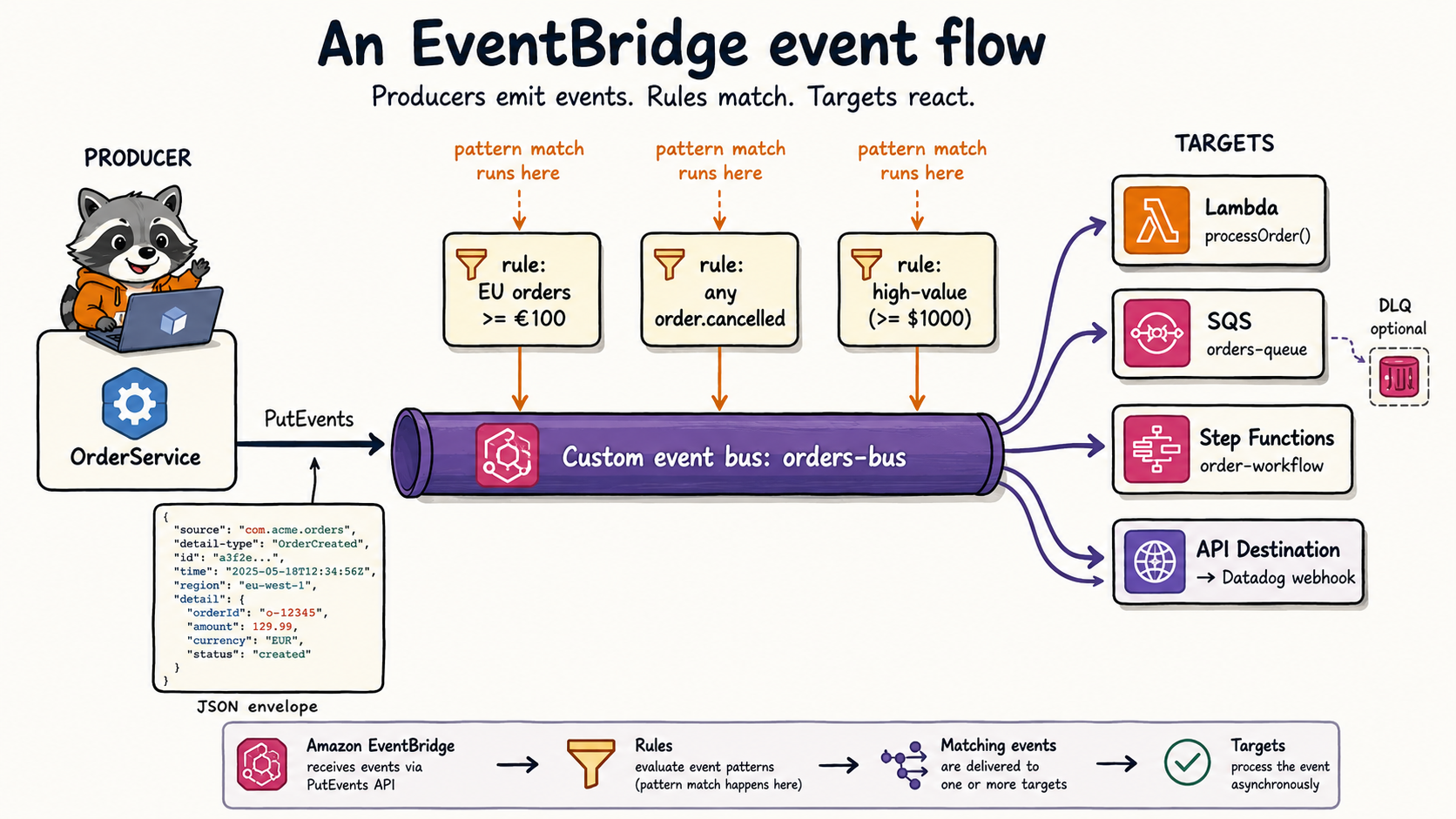
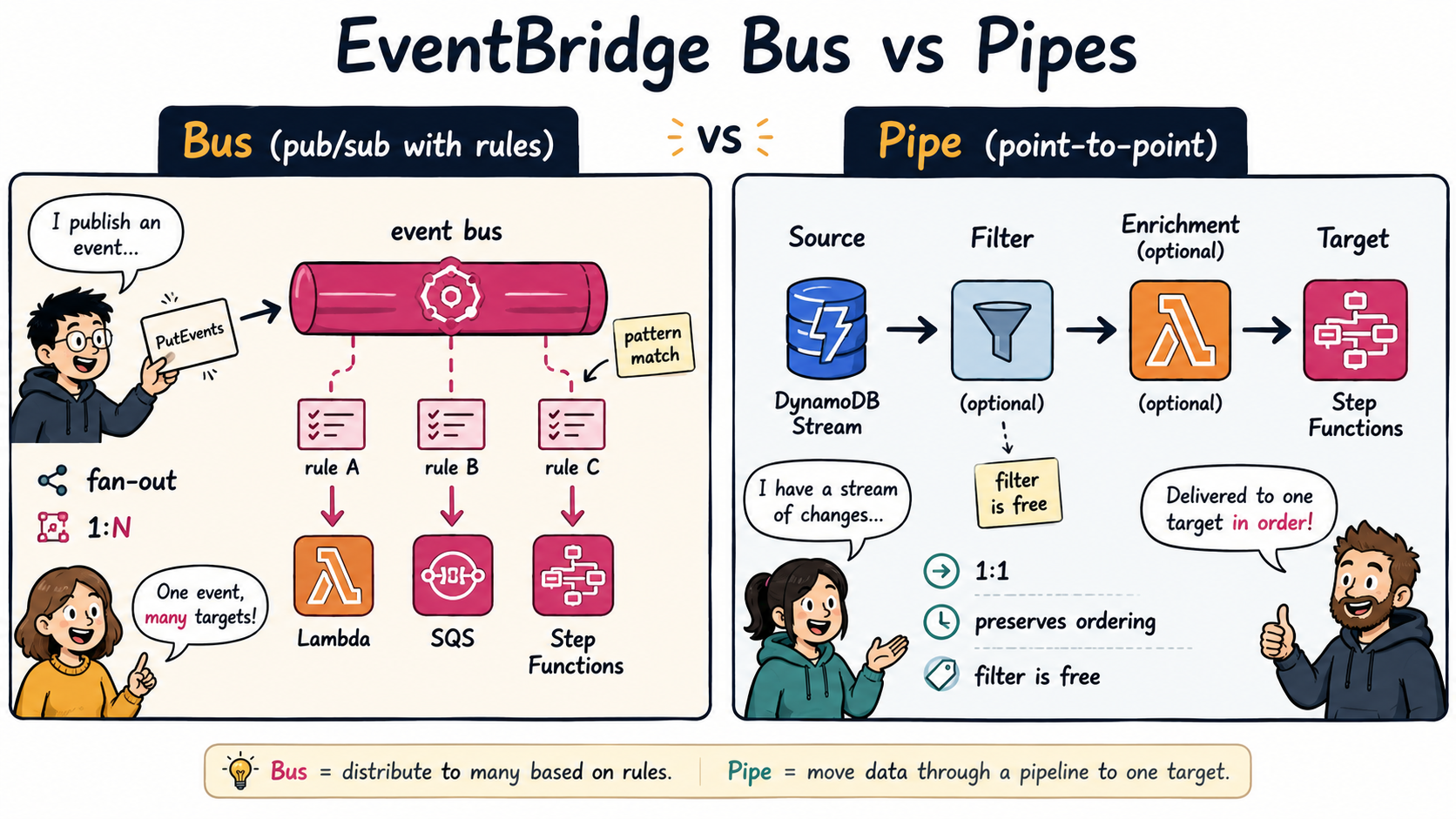
Here's the whole service in one breath. You have one or more event buses. Producers PutEvents onto a bus. Each bus has rules. Each rule has an event pattern (a JSON template describing which events it cares about) and up to 5 targets (Lambda, SQS, SNS, Step Functions, another bus, an API destination, ECS task, Firehose, and a long etc). When an event lands on a bus, EventBridge runs every rule's pattern against it and delivers a copy to every target of every matching rule. That's it. Pub/sub with content-based routing built in.
The bit that's worth saying out loud, because it's the part SNS doesn't do: the matching is content-based, not topic-based. You don't subscribe to a topic and filter clientside. The bus itself reads the event body and decides where it goes.
What an event actually looks like
Every event on an EventBridge bus is a JSON object with a fixed envelope. The required top-level fields are these:
{
"version": "0",
"id": "6a7e8feb-b491-4cf7-a9f1-bf3703467718",
"detail-type": "order.placed",
"source": "com.acme.orders",
"account": "111122223333",
"time": "2026-05-18T09:12:00Z",
"region": "us-east-1",
"resources": ["arn:aws:dynamodb:..."],
"detail": {
"orderId": "ord_01HX...",
"customerId": "cus_42",
"amountCents": 7900,
"currency": "USD",
"shippingCountry": "DE"
}
}The envelope (source, detail-type, account, region, resources) is the routing surface. The detail is your payload. You set source and detail-type; EventBridge fills in id, account, time, region, and the version.
If that shape looks familiar, it should. It's the same shape every AWS-emitted event uses. EC2 state changes, S3 object created notifications, CodePipeline stage transitions: they all arrive on your default bus as this exact envelope. Which means a rule you write to match your application's order.placed events looks structurally identical to a rule that matches aws.ec2 instance terminations. One mental model, many sources.
Patterns: the part that surprises most people
This is where EventBridge stops looking like SNS and starts looking like its own thing. A rule's event pattern is a JSON template, and you can match on any leaf in the event, including deep inside detail. Here's a rule that fires only on EU orders over €100:
{
"source": ["com.acme.orders"],
"detail-type": ["order.placed"],
"detail": {
"amountCents": [{ "numeric": [">=", 10000] }],
"shippingCountry": ["DE", "FR", "IT", "ES", "NL"]
}
}That filter runs on the bus side. The target Lambda never sees the events that don't match, which means you're not paying Lambda invocations to throw 90% of them away. SNS message filtering can do some of this; EventBridge can do a lot more of it.
The full operator list is worth knowing because the docs hide it: prefix, suffix, anything-but, numeric (with <, <=, =, >=, >), exists, cidr, equals-ignore-case, wildcard (single *, no consecutive), and $or. So you can write a rule like "any event whose source starts with com.acme. AND whose detail.userAgent contains iPhone AND whose detail.ipAddress is in 10.0.0.0/8 AND is not from the staging account" and the bus does the work. That's not something you get from SNS filter policies, and it's a real reason to prefer EventBridge once your routing logic stops being trivial.
The numbers that actually matter
Before you commit to anything I've said so far, the limits and the bill.
Throughput. PutEvents is capped at 10 entries per request and 256 KB total per call. The account-level TPS for PutEvents is 10,000/s in us-east-1, us-west-2, and eu-west-1, lower in smaller regions (us-east-2 and eu-central-1 sit at 2,400/s, the smallest regions at 400/s). All adjustable via Service Quotas. Invocation TPS (events leaving the bus toward targets) is 18,750/s in the big regions, also adjustable.
Rules. Default is 300 rules per bus, adjustable up to around 2,000. Each rule has at most 5 targets, and that one is not adjustable. If you need fan-out of 50, the answer is either one rule that targets an SNS topic with 50 subscribers, or a different architectural unit (Pipes for point-to-point, an SQS fan-out pattern, etc).
Event size. 256 KB hard cap per event, same as SNS and SQS. When you need to ship more, the standard answer is the claim check pattern: drop the payload into S3, put the S3 key in the event.
Retries and DLQ. Default retry is 24 hours and up to 185 attempts with exponential backoff. Both are tunable (retry attempts 0 to 185, event age 60s to 24h). Dead-letter queues are opt-in per target. If you don't attach an SQS DLQ and a target's retries are exhausted, the event is dropped silently. This is the single biggest production gotcha I'll mention in this article. Write it down.
Pricing, the part everyone wants to see:
- Custom events on a custom bus: $1.00 per million ingested.
- Partner events: $1.00 per million.
- AWS service events on the default bus: free.
- Cross-account delivery: $0.05/M for custom/partner, $1.00/M for AWS service events.
- Archive: $0.10 per GB processed, $0.023 per GB stored.
- Schema Discovery: $0.10/M events (first 5M/month free).
- Pipes: $0.40 per million requests after the filter (so non-matching events are free).
- API Destinations: $0.20/M invocations.
- Billing chunk: every 64 KB of payload counts as one event. Schema Discovery counts in 8 KB chunks. So a 200 KB event is billed as four events on ingest. Worth modeling if your payloads are large.
$1/M sounds cheap until you do the math on a busy product. A bus receiving 500M events a month costs $500 in ingest plus whatever the targets cost downstream. Worth knowing before you propose it.
The gotcha pile
You haven't really used a service until you've been bitten by it. Here is the list of things EventBridge will do that you should know going in.
It's at-least-once. Always. EventBridge can and does deliver duplicates. Most production incidents around the service come from someone designing as if delivery were exactly-once. Bake in idempotency on every consumer: store a processed-event ID set keyed by the event's id (it's UUID-shaped and unique per delivery attempt) and short-circuit re-deliveries. This is the same discipline SQS and SNS demand; the trap is that the EventBridge developer experience feels neater, which makes you forget.
There is no ordering guarantee. Two events emitted in order from the same producer can arrive at the same target out of order. If you need ordering (say, order.placed must arrive before order.shipped), encode causality in the event itself (include both IDs, let the consumer drop stale messages), or use a service that does ordering (Kinesis with a partition key, SQS FIFO).
The default bus is not what you think. By default, the default bus only receives events from AWS services in the same account. If service A in account 111 calls PutEvents targeting the default bus in account 222, it will fail unless you've added a resource policy to that bus granting events:PutEvents to the calling principal. Most production setups put application events on a custom bus precisely to keep this boundary clean.
Wildcards are limited. You can use the wildcard operator with * (single, no consecutive) in patterns, but only 30 rules per bus can contain wildcards, and that limit is not adjustable. If you find yourself reaching for wildcards a lot, the smell is usually a missing source taxonomy, so restructure your producers so a prefix match on source does the same job.
Cross-region needs Global Endpoints. EventBridge is regional. If you want one logical bus that survives a regional outage, the answer is Global Endpoints, which give you a single DNS name routing to a primary bus with failover to a secondary. Not magic, not free, and you need both buses configured with identical rules, but it does mean the multi-region failover story exists.
Schema Discovery costs accumulate. It's $0.10/M events, billed in 8 KB chunks. On a custom bus receiving 100M events a month, that's $10, but if your average event is 24 KB, it's $30. Turn it on intentionally, not as a default.
Pipes are not the bus. This is the conceptual one. We'll cover it next.
Pipes: the thing that quietly replaces half your Lambda glue
EventBridge Pipes launched at re:Invent 2022 and changed which problems EventBridge solves. The classic AWS "glue" pattern looked like this: DynamoDB Stream → Lambda → SQS, where the Lambda existed solely to read the stream, maybe enrich the record, and forward it. You wrote Lambda code, you owned its IAM, you paid for invocations, you debugged the error handling. Pipes ate that pattern.
A Pipe is a point-to-point connector between one source and one target, with optional filter, enrichment, and transformation stages in the middle, all configured, no Lambda required for the glue itself:
Source → Filter (free) → Enrichment (optional) → TargetSupported sources (6): DynamoDB Streams, Kinesis Data Streams, Amazon MSK, self-managed Kafka, SQS (Standard and FIFO), Amazon MQ (ActiveMQ and RabbitMQ).
Supported targets (~15+): Lambda, Step Functions, SNS, SQS, an EventBridge bus, API Gateway, API Destinations, Kinesis, ECS task, Batch job, CloudWatch Logs, Firehose, Redshift Data API, SageMaker Pipeline, Inspector.
Two things are easy to miss. First, the filter stage is free, so only events that pass the filter are billed at the $0.40/M rate. A pipe that throws away 95% of a high-volume Kafka topic costs you 5% of the published rate. Second, Pipes preserve the source's batching and ordering semantics. A DynamoDB Stream pipe targeted at Step Functions gets per-shard ordering for free; the same flow stitched together with EventBridge bus + Lambda would lose that ordering on the bus.
Concrete shape of when each one wins:
- Bus when you have multiple consumers of the same event, want content-based routing, want archive/replay, want SaaS partner sources, or want decoupled team ownership.
- Pipe when you have one source → one target glue and you want to delete the Lambda that was doing nothing but forwarding.
I've seen teams replace four Lambdas with a single Pipe and not regret it once.
SaaS partner sources: the underrated half of the product
The other thing EventBridge gives you that competitors don't is a first-class SaaS integration layer. AWS curates a list of partner sources, and when you enable one, that vendor pushes events directly onto a dedicated partner event bus in your account. From there it's an ordinary EventBridge rule on the partner bus.
The roster runs to roughly 50 partners today, and the names cover most of what a typical SaaS-heavy backend already pays for: Stripe, Auth0, Datadog, PagerDuty, Shopify, Zendesk, MongoDB (Atlas), Okta, New Relic, Segment, Twilio, Snyk, GitHub, Atlassian (Jira Service Management, Opsgenie), Freshworks, BigCommerce, Chargebee, Checkout.com, Tealium, Amazon Seller Partner API, SailPoint, and more.
What this replaces: the webhook receiver Lambda you would otherwise write for every one of those vendors. Stripe sends a payment_intent.succeeded? Without EventBridge you stand up an API Gateway, a Lambda to verify the Stripe signature, an SNS topic to fan out, IAM glue, retries, replay logic. With the Stripe partner source enabled, that event lands directly on a dedicated bus in your account, signed and authenticated by the vendor side, and you write a rule.
You still pay $1/M for partner events. But you delete a lot of Lambda code, and you get the same content-based routing surface for vendor events as for your own.
Where it loses
EventBridge is not the right answer for everything. Quick rundown of where the alternatives win:
- SNS wins when you need raw fan-out and don't care about filtering beyond simple attribute equality. SNS standard is $0.50/M for publishes vs $1.00/M for EventBridge ingest, and the latency floor is lower. If your routing logic genuinely fits a topic-per-event-type model, SNS is cheaper and simpler.
- SQS wins for plain queuing. EventBridge often targets an SQS queue. They're complementary, not competitors.
- Kinesis Data Streams wins when you need ordered, replayable, shard-partitioned streams with consumer-managed checkpoints. KCL-style consumers are a different model than EventBridge's push-with-retries model, and analytics workloads usually want Kinesis.
- Step Functions wins for orchestration with state. EventBridge is choreography (loose coupling, no central state); Step Functions is orchestration (central state machine, retries with state). The two compose well: a bus rule triggers a Step Functions execution.
The EventBridge sweet spot is many heterogeneous event types, multiple decoupled consumers, content-based routing, and a non-trivial chance you'll want to add a SaaS source next quarter. That's an enormous slice of backend work, and it's the slice that defaults to SNS or to "Lambda receives the webhook" by habit.
A small migration story
Imagine the simplest version of the move. You have an orders service emitting order.placed events as SNS messages, with a Lambda subscriber that filters by region == EU and forwards them to a shipping service. Two months later, a second team wants the same events but filtered by amount >= $1000 for fraud review. You add a second Lambda subscriber. Two months later, a third team wants them filtered by customer.segment == enterprise for CSM alerting. You add a third Lambda.
You've just rebuilt EventBridge by hand. Each Lambda is invoked for every event, filters most of them out, and bills you for the invocations. The filter logic is duplicated across three codebases. Add a fourth consumer and the math gets worse.
The EventBridge equivalent is one bus, three rules, three targets, and the bus does the filtering. The fourth consumer is one new rule, no Lambda. The fifth is another rule. The cost stops being a function of total event volume and starts being a function of matched events per consumer.
That's the article in one paragraph: when your routing logic gets richer than "one topic per type", EventBridge stops being optional.
The honest minimum to start
If you read this and want to try it tomorrow, the minimum viable shape is short.
- Make a custom bus (
orders-bus). Don't put application events on the default bus. - Emit events with stable
source(e.g.,com.yourco.orders) and cleandetail-type(order.placed,order.cancelled). Treat them like a public API: these names are hard to change later. - For each consumer, write a rule. Attach an SQS DLQ to every target from day one. Not optional. The silent-drop default is the bug you don't want to debug at 4am.
- Turn on archive on the bus (1 to 7 days retention is cheap insurance). The first time you ship a bug and need to replay yesterday's events, you'll be grateful.
- Add an idempotency check on every consumer keyed on event
id. Duplicates will happen.
That's it. Five things. The rest of the surface (Pipes, partner sources, Schema Registry, API Destinations, Global Endpoints) you can grow into as the use cases show up.
EventBridge is one of those AWS services that looks like a feature of another service the first time you read about it, and then six months later you realize half your custom Lambda glue could have been a rule.