
Open your terminal. Type the names of the tools you use every day to ship software. docker, kubectl, helm, terraform, vault, consul, nomad, etcd, prometheus, grafana-agent, containerd, cri-o, caddy, traefik, step, cosign, argocd, flux, tekton. Every single one of those is written in Go. Most of the tooling around them (Kubernetes operators, kubectl plugins, custom controllers, the little CLI your platform team built last quarter for spinning up dev environments) is Go too.
That's not a coincidence, and it's not just because Google wrote Kubernetes. Go won DevOps the way a single material wins a whole category of tools: it's not the fanciest at any one thing, but the trade-offs line up almost perfectly with what infrastructure code actually needs.
This piece is a tour of why Go fits this space so well, and a walk through the libraries and patterns you'd reach for if you sat down today to build the next tool in that list. We'll cover CLIs (cobra, viper, the charm stack), the Kubernetes ecosystem (client-go, informers, controller-runtime, kubectl plugins), cloud SDKs and Terraform providers, and the small recurring patterns (context, retries, exec, structured logging) that hold automation code together without it turning into a swamp.
It's not exhaustive. It's the version I'd give a backend engineer who just got pulled onto the platform team and wants to be useful by Friday.
Why Go won this category in the first place
Spend ten minutes thinking about what a DevOps tool actually has to do, and the Go fit becomes obvious.
A DevOps tool ships to other people's machines, often laptops you can't control. It needs to start fast. Operators expect a kubectl get pods to feel instant. It needs to do a lot of I/O concurrently, because half its job is talking to a control plane, the other half is talking to a cloud API, and both of those are slow networks. It has to cross-compile, because the same binary might run on an engineer's M2 Mac, a Linux CI runner, and an arm64 container in production. It can't drag in a runtime, because half the time it's running inside a tiny scratch image where you don't even have libc.
Go ticks all of those:
- Static binaries by default.
go buildproduces one file with no dependencies. Drop it on a machine, mark it executable, run it. Nopip install, nonpm install, no JVM, no DLL hell. For a tool you're shipping to a thousand developer laptops, that one property alone is worth a lot. - Fast startup. Go binaries cold-start in milliseconds. That matters when the tool is invoked from a shell loop, a
Makefile, a CI step, or a Kubernetes init container. A 400ms JVM startup feels fine for a long-running service. It feels awful when you're pipingkubectl get pods | xargs .... - Goroutines for I/O. Almost every interesting DevOps tool fans out to many endpoints: list all your S3 buckets across all regions, query the API server for every namespace, hit a dozen pods to grab logs. Goroutines plus channels make that natural. You're not reaching for a thread pool or an event loop; you're just writing
go func() { ... }and reading from a channel. - Cross-compilation that actually works.
GOOS=linux GOARCH=arm64 go buildproduces a working binary on your laptop without setting up a cross-toolchain. The cloud-native world is multi-arch now; this matters every day. - A standard library that knows about the internet.
net/http,encoding/json,crypto/tls,os/exec, andcontextare all in the box. You're not picking between four competing HTTP clients before you write the first line. - A type system that's strict enough to catch mistakes, loose enough to ship. Go isn't Haskell, and that's the point. You can refactor a 50k-line CLI in an afternoon and the compiler will tell you what you broke.
That last point is the underrated one. The Kubernetes ecosystem moves fast. APIs add fields, controllers add hooks, plugins ship and break monthly. A language that lets you refactor across a huge codebase without ceremony has a real advantage. Try renaming a field across a Python project that size and you'll spend the day in grep.
With the why out of the way, let's start building.
CLIs: the front door of every DevOps tool
The first thing almost any DevOps tool is, before it's anything else, is a CLI. So if you can't build a good CLI in Go, you can't build the tool. Three libraries cover roughly 95% of the space.
cobra + viper for anything serious
cobra is the library behind kubectl, helm, hugo, docker (the CLI), the GitHub CLI, and most of the Kubernetes operator tooling. If you've ever typed tool subcommand --flag value, you've talked to cobra. It models commands as a tree: a root command, subcommands, sub-subcommands, each with their own flags and their own Run function.
A small but real shape:
package cmd
import (
"fmt"
"os"
"github.com/spf13/cobra"
"github.com/spf13/viper"
)
var rootCmd = &cobra.Command{
Use: "envctl",
Short: "Manage developer environments",
Long: "envctl spins up, tears down, and inspects dev environments on the platform.",
}
func Execute() {
if err := rootCmd.Execute(); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
func init() {
cobra.OnInitialize(initConfig)
rootCmd.PersistentFlags().String("config", "", "path to config file")
rootCmd.PersistentFlags().String("log-level", "info", "log level (debug, info, warn, error)")
// Bind the flags to viper so config file, env, and flags all flow into one place.
_ = viper.BindPFlag("config", rootCmd.PersistentFlags().Lookup("config"))
_ = viper.BindPFlag("log_level", rootCmd.PersistentFlags().Lookup("log-level"))
}
func initConfig() {
if cfg := viper.GetString("config"); cfg != "" {
viper.SetConfigFile(cfg)
} else {
viper.AddConfigPath("$HOME/.envctl")
viper.SetConfigName("config")
}
viper.SetEnvPrefix("ENVCTL")
viper.AutomaticEnv()
_ = viper.ReadInConfig() // fine if it doesn't exist
}That's the spine. Each subcommand sits in its own file under cmd/:
package cmd
import (
"context"
"time"
"github.com/spf13/cobra"
)
var upCmd = &cobra.Command{
Use: "up [name]",
Short: "Create a new dev environment",
Args: cobra.ExactArgs(1),
RunE: func(cmd *cobra.Command, args []string) error {
ctx, cancel := context.WithTimeout(cmd.Context(), 5*time.Minute)
defer cancel()
return createEnvironment(ctx, args[0])
},
}
func init() {
upCmd.Flags().String("size", "small", "environment size (small|medium|large)")
upCmd.Flags().Bool("seed", false, "seed the database with demo data")
rootCmd.AddCommand(upCmd)
}A few things to notice. RunE returns an error, which cobra propagates to Execute, so you don't sprinkle os.Exit(1) through the codebase. cmd.Context() gives you a context wired to OS signals if you set it up that way, which is how you make Ctrl+C actually cancel the in-flight HTTP request to your control plane. And cobra.ExactArgs(1) validates positional args before your function even runs, which keeps the body focused on the actual work.
viper complements cobra by giving you one place to read configuration from (flags, environment variables, config files, remote config stores) without your code caring which source it came from. The whole point of BindPFlag is that further down the codebase you write viper.GetString("log_level") and never have to know whether that value originally came from a flag, ENVCTL_LOG_LEVEL, or a YAML file. For a tool that runs in three environments with three different ergonomics, that's a real simplification.
The charm stack for tools people actually want to look at
The newer wave of CLIs (gh, glab, lazygit, k9s, aws-vault's prompts, gum-flavoured shell scripts) leans heavily on the Charm libraries: bubbletea for interactive TUIs, lipgloss for terminal styling, bubbles for ready-made components (text inputs, lists, spinners), and gum as a "Charm CLI" for shell scripts that want a TUI without writing any Go.
A bubbletea program is built on the Elm architecture: a Model, an Update(msg) (Model, Cmd), and a View() string. It's overkill for mytool add foo, but it's exactly right when your tool needs to choose between options interactively, display progress with real cursor control, or navigate a list of resources. If you're building a kubectl plugin that should feel like a dashboard, bubbletea + bubbles is the path.
urfave/cli when you want less ceremony
If your tool is one or two commands and you don't need the full cobra tree, urfave/cli is lighter. It's the library behind restic, parts of gophercloud's tooling, and a lot of one-off automation binaries. The API is closer to a configuration object than a registration tree:
package main
import (
"log"
"os"
"github.com/urfave/cli/v2"
)
func main() {
app := &cli.App{
Name: "rotate-keys",
Usage: "rotate AWS access keys for a list of accounts",
Flags: []cli.Flag{
&cli.StringFlag{Name: "input", Required: true, Usage: "path to accounts.csv"},
&cli.BoolFlag{Name: "dry-run", Value: true},
},
Action: func(c *cli.Context) error {
return run(c.String("input"), c.Bool("dry-run"))
},
}
if err := app.Run(os.Args); err != nil {
log.Fatal(err)
}
}The rule of thumb most teams settle on: cobra for anything with subcommands and persistent flags, urfave/cli for single-purpose binaries, charm on top when the UX justifies it.
Talking to Kubernetes: the part Go was made for
This is where Go's position in DevOps stops being a coincidence and starts being a moat. The entire Kubernetes ecosystem is written in Go. The API types, the API server, kubectl, every official controller, every official operator framework. When you write Kubernetes code in Go, you import the same packages the API server itself uses. There is no impedance mismatch. A corev1.Pod in your code is the same struct the API server unmarshals from etcd.
There are roughly three levels to working with Kubernetes from Go, and you pick based on what you're building.
Level 1: client-go for scripts and simple tools
client-go is the official Kubernetes client. If you're writing a CLI that needs to "list all pods in this namespace with this label and do X," you're at this level.
package main
import (
"context"
"fmt"
"path/filepath"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
)
func main() {
kubeconfig := filepath.Join(homedir.HomeDir(), ".kube", "config")
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
if err != nil {
panic(err)
}
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
pods, err := clientset.CoreV1().Pods("default").List(context.TODO(), metav1.ListOptions{
LabelSelector: "app=checkout",
})
if err != nil {
panic(err)
}
for _, p := range pods.Items {
fmt.Printf("%s\t%s\n", p.Name, p.Status.Phase)
}
// `p` is a corev1.Pod, with full type safety.
_ = corev1.Pod{}
}A few things to notice. There's no client-side schema. The API server tells you what version of corev1 it speaks via discovery; client-go matches your version against that. Every list/get/create/update method takes a context.Context, which means cancellation, timeouts, and deadlines propagate cleanly. And the returned pods.Items is a slice of typed structs, so you get autocompletion on p.Status.Phase because the type is real, not a map[string]interface{}.
For one-shot tools, this is enough. You build the config, get a clientset, call the API, do the work, exit. Fast, boring, exactly what you want.
Level 2: informers and watches for tools that have to stay current
The moment your tool needs to react to changes ("page me when a deployment goes into CrashLoopBackOff", "auto-label new pods"), naive polling stops scaling. Hammering the API server with List calls every second is rude to the cluster, slow for you, and won't scale past a couple of dozen tools.
Kubernetes' answer is watches and the abstraction built on top of them, informers. An informer maintains a local cache of a resource type by opening a long-lived watch against the API server, then keeping the cache in sync by streaming change events. You read from the cache, not from the API server. The informer also gives you event hooks (AddFunc, UpdateFunc, DeleteFunc) so your code reacts as things change.
package main
import (
"context"
"fmt"
"time"
corev1 "k8s.io/api/core/v1"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
config, _ := clientcmd.BuildConfigFromFlags("", "/home/you/.kube/config")
clientset, _ := kubernetes.NewForConfig(config)
factory := informers.NewSharedInformerFactory(clientset, 30*time.Second)
podInformer := factory.Core().V1().Pods().Informer()
podInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
p := obj.(*corev1.Pod)
fmt.Printf("added: %s/%s\n", p.Namespace, p.Name)
},
UpdateFunc: func(_, newObj interface{}) {
p := newObj.(*corev1.Pod)
if p.Status.Phase == corev1.PodFailed {
fmt.Printf("failed: %s/%s\n", p.Namespace, p.Name)
}
},
})
stop := make(chan struct{})
defer close(stop)
factory.Start(stop)
factory.WaitForCacheSync(stop)
<-context.Background().Done()
}The SharedInformerFactory is the important piece. Multiple parts of your tool can all ask for "the Pods informer" and they'll share one watch and one cache. That's how production controllers keep their footprint sane.
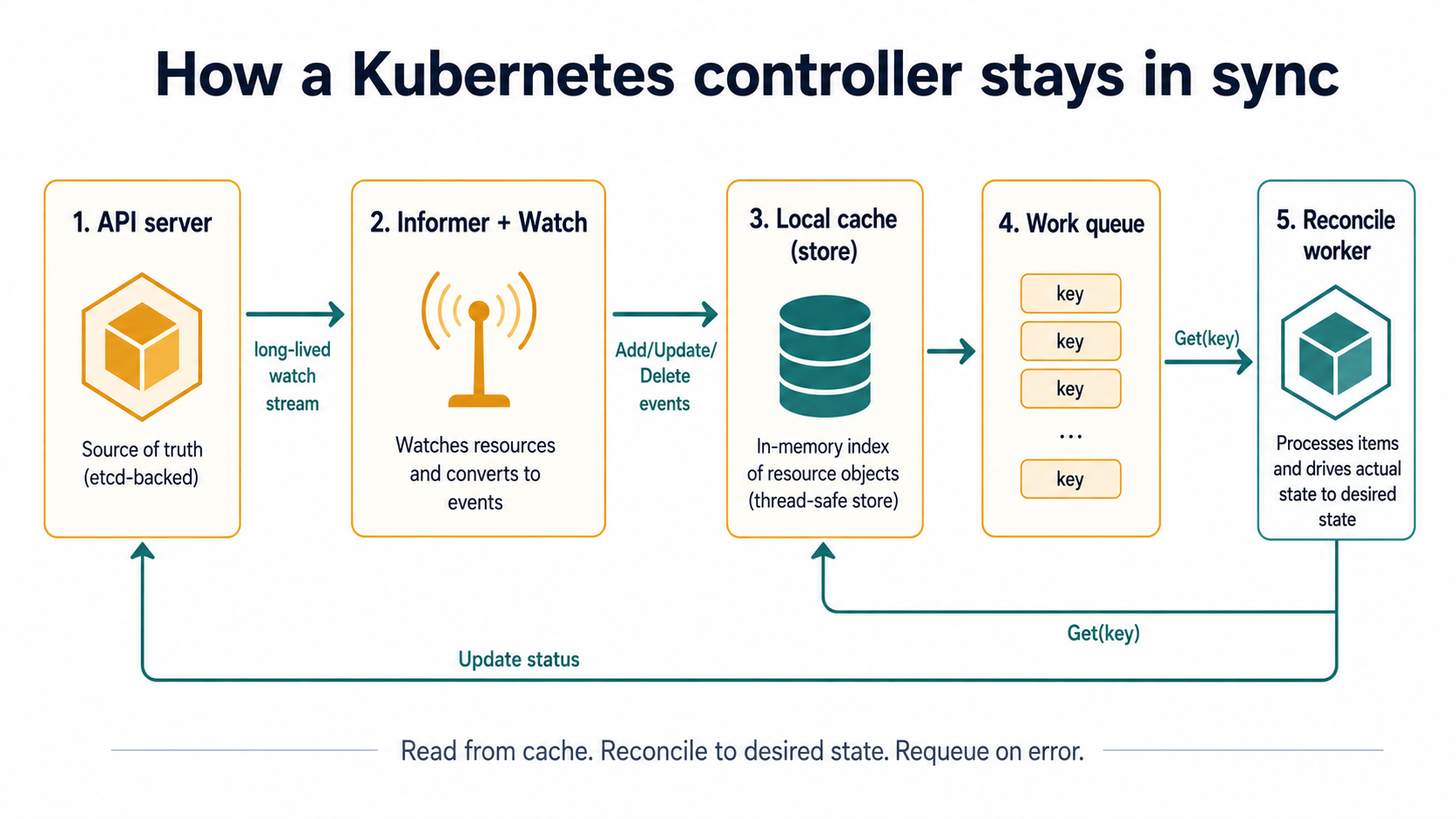
Level 3: controller-runtime and Kubebuilder for operators
When you're writing an operator, meaning a controller that manages a Custom Resource Definition (CRD) and reconciles cluster state to match user-declared spec, you want controller-runtime. It's the library that powers Kubebuilder and the Operator SDK, and almost every well-known operator (Prometheus Operator, cert-manager, Argo Rollouts, the cloud-native database operators) is built on top of it.
The model is the reconciler. You define a Reconcile(ctx, req) (Result, error) method on a type, register it with the manager for a particular resource, and controller-runtime calls it whenever that resource changes, or whenever you ask it to requeue itself. Your job inside Reconcile is to compare what the spec says should exist with what actually exists and converge them.
package controllers
import (
"context"
"time"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
platformv1 "example.com/myapp/api/v1"
)
type MyAppReconciler struct {
client.Client
Scheme *runtime.Scheme
}
func (r *MyAppReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
logger := log.FromContext(ctx)
var app platformv1.MyApp
if err := r.Get(ctx, req.NamespacedName, &app); err != nil {
// Resource was deleted — nothing more to do.
return ctrl.Result{}, client.IgnoreNotFound(err)
}
if err := r.ensureDeployment(ctx, &app); err != nil {
logger.Error(err, "failed to ensure deployment")
return ctrl.Result{RequeueAfter: 30 * time.Second}, err
}
if err := r.ensureService(ctx, &app); err != nil {
return ctrl.Result{RequeueAfter: 30 * time.Second}, err
}
app.Status.Ready = true
if err := r.Status().Update(ctx, &app); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}
func (r *MyAppReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&platformv1.MyApp{}).
Complete(r)
}Three properties make this powerful. First, the reconciler is idempotent by contract: your job is to make reality match spec, and if you get called twice for the same change, the second call is a cheap no-op. That's a huge simplification compared to event-driven code where you have to deduplicate yourself. Second, errors trigger automatic requeue with exponential backoff, so you return the error and the framework figures out when to call you again. Third, controller-runtime handles all the boilerplate of caching, leader election, metrics, and graceful shutdown via the manager.
Kubebuilder scaffolds all of this for you. kubebuilder init and kubebuilder create api give you a working project layout with the CRD types, the reconciler skeleton, manifests for deployment, and a Makefile to install everything in a local kind cluster. From scaffold to a working operator that does something useful is genuinely a couple of hours, not a couple of days.
Bonus: kubectl plugins are just Go binaries
A kubectl plugin is any executable on your PATH named kubectl-<name>. Run kubectl whatever and kubectl looks for kubectl-whatever and execs it, passing along arguments and environment. That's it. There's no plugin framework, no entry point, no registration step.
Which means a Go binary that uses client-go and cobra is a kubectl plugin the moment you rename it. Most production plugins (kubectl-neat, kubectl-tree, kubectl-rabbitmq, the whole krew ecosystem) follow exactly that pattern. The official cli-runtime package gives you helpers to make your plugin behave like kubectl itself (same --kubeconfig, --context, --namespace flags, same config-loading rules), so you can write kubectl mything --namespace prod and it does the right thing without surprises.
Cloud APIs and infrastructure-as-code in Go
Outside of Kubernetes, the second giant slice of DevOps work is talking to clouds. The three big providers and most of the smaller ones publish official Go SDKs, and they all look broadly similar once you get past the naming.
Cloud SDKs: AWS, GCP, Azure
AWS SDK v2 is the modern shape. You build a config, build a client, call a method that takes a context and an input struct, and get back an output struct and an error:
package main
import (
"context"
"fmt"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/s3"
)
func main() {
ctx := context.Background()
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
panic(err)
}
client := s3.NewFromConfig(cfg)
out, err := client.ListBuckets(ctx, &s3.ListBucketsInput{})
if err != nil {
panic(err)
}
for _, b := range out.Buckets {
fmt.Println(*b.Name)
}
}GCP's cloud.google.com/go/... packages and Azure's azure-sdk-for-go follow the same shape: auth from the environment, typed client per service, context-aware methods. Once you've used one, you can read code for any of them. That uniformity is the whole reason terraform and pulumi can support a hundred providers without becoming chaos: each provider is a thin Go wrapper around the SDK that already exists for that cloud.
Terraform providers
A Terraform provider is, structurally, a Go binary that speaks Terraform's plugin protocol over RPC. You define resources (schema.Resource in the legacy Plugin SDK v2, or resource.Resource in the newer Plugin Framework), and for each one you implement Create, Read, Update, and Delete. The provider handles the plumbing.
The official template at github.com/hashicorp/terraform-provider-scaffolding-framework gets you to a working terraform init && terraform plan against your provider in under an hour. From there, every resource you add is a small Go struct plus four functions that talk to whatever API you're wrapping. If your company has an internal control plane and engineers keep asking for "Terraform support," writing a provider is much less work than people think, usually a couple of weeks for a handful of resources.
Pulumi and crossplane
Pulumi takes a different bet: instead of HCL, you describe infrastructure in Go (or TypeScript, or Python). Resources are real Go objects, and the dependency graph is built from how your variables flow:
package main
import (
"github.com/pulumi/pulumi-aws/sdk/v6/go/aws/s3"
"github.com/pulumi/pulumi/sdk/v3/go/pulumi"
)
func main() {
pulumi.Run(func(ctx *pulumi.Context) error {
bucket, err := s3.NewBucketV2(ctx, "logs", &s3.BucketV2Args{
Tags: pulumi.StringMap{"env": pulumi.String("prod")},
})
if err != nil {
return err
}
ctx.Export("bucketName", bucket.Bucket)
return nil
})
}This is the same shape as the cloud SDK code above, with a wrapper that lets Pulumi diff your desired infrastructure against your actual infrastructure. If you've ever wanted "Terraform, but I can use a for-loop without losing my mind," Pulumi in Go is the thing.
Crossplane is the third stop on this tour. It's a Kubernetes operator that turns cloud resources into Kubernetes CRDs, so you can kubectl apply an S3 bucket. The providers Crossplane uses are themselves Go controllers built on controller-runtime. Everything in this space, even the things that look like they're "Kubernetes-native," reduces to Go controllers under the hood.
The small patterns that hold automation code together
You can know all of the libraries above and still write bad automation code. The difference between a DevOps tool people enjoy using and one they curse at is usually a handful of small patterns. Here's the shortlist.
context.Context everywhere
Pass a context.Context as the first argument of every function that does I/O. Period. Not "when I need to," not "when I add timeouts later." Every function. It's a cheap habit and it lets you wire cancellation and deadlines through the whole tool without rewrites.
func backupDatabases(ctx context.Context, dbs []string) error {
for _, db := range dbs {
select {
case <-ctx.Done():
return ctx.Err() // Ctrl+C stops the loop cleanly.
default:
}
if err := backupOne(ctx, db); err != nil {
return fmt.Errorf("backup %s: %w", db, err)
}
}
return nil
}Wire context.Background() to OS signals at the top of main:
ctx, cancel := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer cancel()
if err := run(ctx); err != nil {
log.Fatal(err)
}Now Ctrl+C cancels the in-flight backup, the in-flight HTTP request, the in-flight kubectl exec, anything that's been given the context.
Structured logging with log/slog
Since Go 1.21, the standard library has log/slog: structured logging, leveled, with JSON and text handlers. Use it. Stop using log.Printf. Stop pulling in zap or logrus for new projects unless you have a specific reason.
logger := slog.New(slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{
Level: slog.LevelInfo,
}))
logger.Info("starting backup",
"db", db.Name,
"size_bytes", db.Size,
"region", db.Region,
)The output is one JSON object per line. Your log aggregator (Loki, CloudWatch, Datadog, whichever) parses it for free. You can grep by field instead of hoping your fmt.Sprintf was consistent. Every value gets a key. This is how all logs in a DevOps tool should look.
Retries with backoff, but not by hand
Network calls fail. Cloud APIs throttle. The right answer is almost never "let it crash" and almost never "retry forever in a for loop." Use a library that knows about exponential backoff and jitter. The most common picks are cenkalti/backoff for general-purpose retries and the per-cloud retry helpers built into the SDKs themselves.
import "github.com/cenkalti/backoff/v4"
op := func() error {
_, err := client.ListBuckets(ctx, &s3.ListBucketsInput{})
return err
}
bo := backoff.WithContext(backoff.NewExponentialBackOff(), ctx)
if err := backoff.Retry(op, bo); err != nil {
return fmt.Errorf("list buckets after retries: %w", err)
}The thing to internalise is that retries respect the context. If the user cancels, retries stop. If the deadline passes, retries stop. Without that, your "retry on failure" loop becomes a way to never let go.
os/exec for shelling out to other tools
A lot of DevOps tools are, deep down, a polished wrapper around other tools. You shell out to kubectl, to terraform, to docker, to aws. The Go pattern for that is os/exec, and the trap is forgetting to handle stderr.
func runKubectl(ctx context.Context, args ...string) ([]byte, error) {
cmd := exec.CommandContext(ctx, "kubectl", args...)
cmd.Env = append(os.Environ(), "KUBECONFIG=/etc/automation/kubeconfig")
var stdout, stderr bytes.Buffer
cmd.Stdout = &stdout
cmd.Stderr = &stderr
if err := cmd.Run(); err != nil {
return nil, fmt.Errorf("kubectl %s failed: %w\nstderr: %s",
strings.Join(args, " "), err, stderr.String())
}
return stdout.Bytes(), nil
}Three things that matter here. exec.CommandContext ties the subprocess to the context, so cancelling the context kills the subprocess instead of leaking it. Capturing stderr separately and including it in the error message is the difference between "kubectl failed" and "kubectl failed: error: the server doesn't have a resource type 'fobar'." And being explicit about the environment instead of inheriting everything is good hygiene: your tool's behaviour shouldn't depend on whatever happened to be in the operator's shell.
Worker pools instead of unbounded goroutines
The temptation when you have a list of 5,000 things to process is to write for _, x := range xs { go process(x) }. Don't. You'll DDoS your own control plane and your error handling will be a mess. Use a worker pool (N goroutines pulling from a channel), or one of the helper libraries that wrap it.
func processAll(ctx context.Context, items []Item, workers int) error {
jobs := make(chan Item)
errs := make(chan error, len(items))
var wg sync.WaitGroup
for i := 0; i < workers; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for item := range jobs {
if err := process(ctx, item); err != nil {
errs <- err
}
}
}()
}
for _, item := range items {
jobs <- item
}
close(jobs)
wg.Wait()
close(errs)
var firstErr error
for err := range errs {
if firstErr == nil {
firstErr = err
}
}
return firstErr
}golang.org/x/sync/errgroup does the same shape with less ceremony when you want first-error semantics. The point is that "100 things in flight" is a number you choose, not a number you accidentally pick because that's how many items happened to be in the input.
Testing automation code without melting your dev cluster
Two libraries deserve a mention because they change what's possible.
sigs.k8s.io/controller-runtime/pkg/envtest spins up a real kube-apiserver and etcd binary in a temp directory, points your reconciler at them, runs your test, and tears them down. It's the standard way to write integration tests for Kubernetes controllers: your reconciler is talking to a real API server, just one that lives and dies with the test.
github.com/testcontainers/testcontainers-go is the Go port of the Testcontainers project. It starts Docker containers from your test, gives you their connection strings, and tears them down when the test exits. If your tool talks to Postgres, Redis, MinIO, or a fake AWS endpoint via LocalStack, testcontainers turns that into a clean Go test.
Both of these mean you can write tests that exercise real systems without owning long-lived infrastructure. For DevOps code, where most of the bugs live in the "wait, that's not the response shape I expected" layer, that matters more than unit tests.
Where Go runs out of road
Go is great for this category but it's not infinite. Three places where you'd reach for something else:
The first is anything heavy with complex domain logic and rich types. Go's type system, on purpose, doesn't have generics-on-everything or algebraic data types or pattern matching. For a controller that's mostly "watch a thing, change a thing," that's a feature. For a policy engine that has to model a deep, evolving rule language, you might end up writing the same defensive code over and over.
The second is anywhere you need a real REPL or notebook workflow. Go has gore and go run and that's about it. For exploring a cloud API interactively before you write the tool, Python or a notebook still wins. Many engineers explore in Python and then write the production tool in Go.
The third is anything where memory layout and zero-cost abstractions actually matter: the very-low-level kernel-adjacent stuff. Go has a garbage collector. The GC is excellent and it's not the problem people think it is for almost all workloads, but if you're writing a CNI plugin's hot path or an eBPF userspace agent that has to keep up with a million events per second, Rust or C is the honest answer.
That's a pretty narrow exclusion zone. Everything that's a normal tool, whether a CLI, a controller, a daemon, a sidecar, a CI agent, a migration runner, or a backup orchestrator. Go fits.
A short reading list, by the way
If you want to go deeper, the books and resources that actually move the needle in this space:
- The Go standard library docs.
net/http,os/exec,context,encoding/json,log/slog. Read them top to bottom once. They're short and shockingly well-written. Programming Kubernetes(Hausenblas & Schwartz, O'Reilly): the canonical book on writing operators withclient-goandcontroller-runtime.- The Kubebuilder Book (free, online at
book.kubebuilder.io): the practical step-by-step for getting your first operator running. - The source code of the tools you already use.
kubectl,helm,cobra,k9sare all on GitHub, they're all written in idiomatic Go, and reading them is the fastest way to absorb the shape of "good DevOps Go."
Go didn't win DevOps because anyone decided it should. It won because, again and again, when somebody sat down to build a tool that had to ship to other people's machines and talk to slow networks and not blow up at 3am, the trade-offs landed in Go's favour. The good news is that the same trade-offs apply to whatever you're building next. The libraries are mature, the patterns are well-trodden, and the path from "I have an idea for a tool" to "binaries on developer laptops" is shorter in Go than almost anywhere else.
Pick something annoying you do twice a week. Go build it.





