You've shipped REST APIs for years.
You know the rhythm. GET /users/42 goes out, a Cache-Control: max-age=60 header comes back, the browser caches it, the CDN caches it, and your origin server gets a break. If you need to invalidate, you bust a key or wait for the TTL. It's not glamorous, but it works, and it works at every layer: browser, CDN, reverse proxy, service worker, application cache. HTTP caching has been refined for thirty years.
Then your team picks GraphQL for the new service. And on day one, every one of those reflexes breaks.
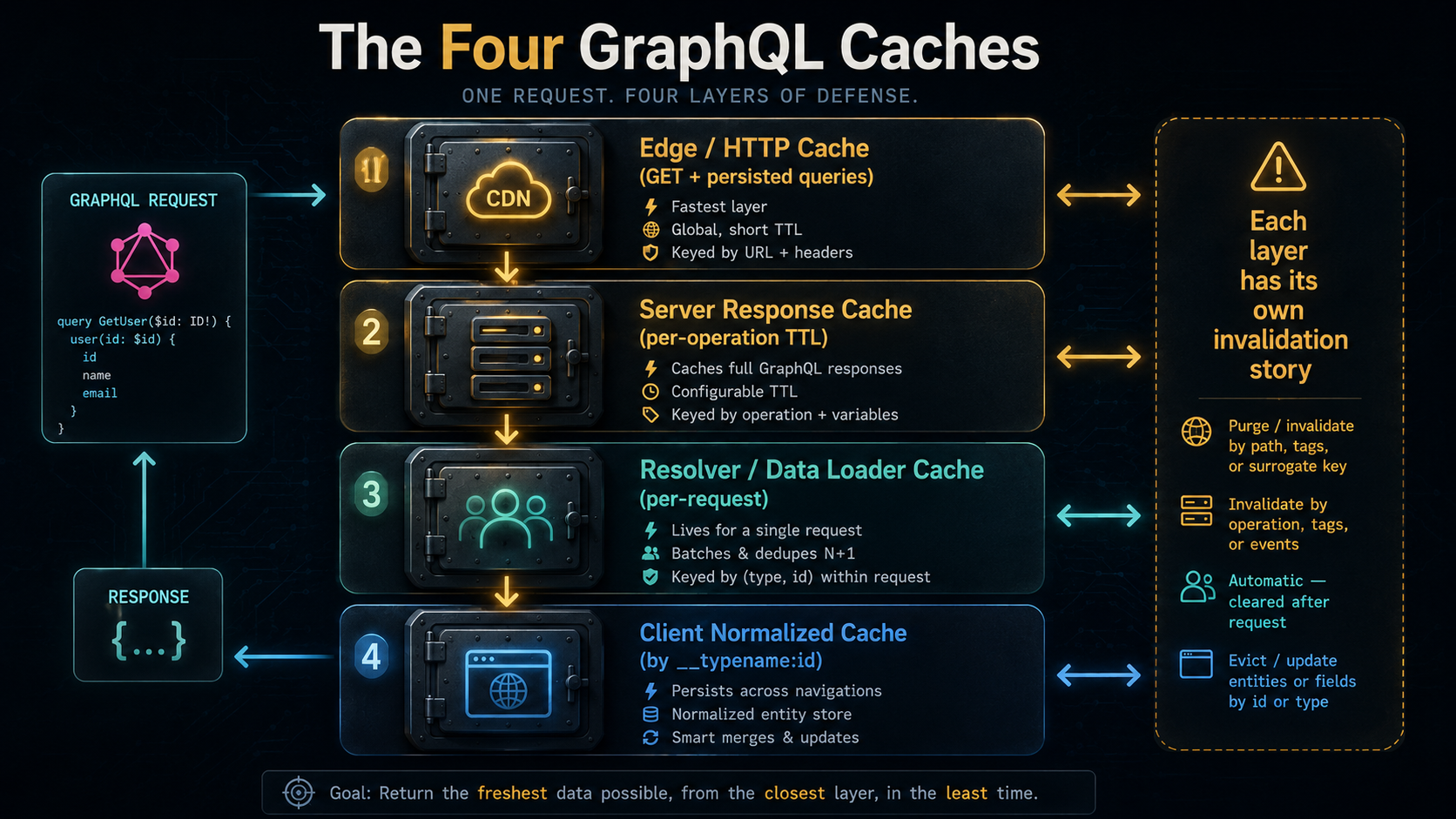
Not because GraphQL is bad. Because GraphQL was designed to solve a different problem, the over-fetching, under-fetching, version-sprawl mess of REST, and the design choices that solve those problems happen to be exactly the choices that make HTTP caching a non-starter. Once you understand why, the rest of the article writes itself. Caching in GraphQL isn't one decision. It's four caches stacked on top of each other, each with its own rules, its own invalidation story, and its own way to make you sad on a Friday afternoon.
Let's walk through them.
Why HTTP Caching Doesn't Just Transfer
Open the network tab on any GraphQL app and you'll see the same thing: a single endpoint, almost always /graphql, taking POST requests with a JSON body like {"query": "...", "variables": {...}}. Every read, every write, same URL, same method.
That's deliberate. The whole point of GraphQL is that the client describes exactly what it wants and the server hands back exactly that shape. The query is the contract. The URL is just a transport.
But HTTP caching keys off URL + method. CDNs cache GETs. Browsers cache GETs. Reverse proxies cache GETs. POST is, by spec, non-idempotent, so caches treat it as poison. Two different GraphQL reads, even if they're semantically identical to fetching /users/42 and /posts/9, look identical from the outside: both are POST /graphql. The cache can't tell them apart without parsing the body, and HTTP caches don't parse bodies.
So out of the box, you get zero HTTP-layer caching. Your CDN sits there doing nothing. Your browser cache sits there doing nothing. Every read goes to origin.
There's a workaround, and it's worth knowing because most production GraphQL setups eventually adopt it.
Persisted Queries And GET Requests
The trick: hash the query on the client, store the query text on the server (or in a CDN config), and send only the hash plus variables on the wire. Now your request looks like GET /graphql?id=abc123&variables=.... It's a GET. The URL changes with the query. Suddenly HTTP caching works again, at least for reads.
import { ApolloClient, InMemoryCache, HttpLink } from '@apollo/client';
import { createPersistedQueryLink } from '@apollo/client/link/persisted-queries';
import { sha256 } from 'crypto-hash';
const link = createPersistedQueryLink({ sha256, useGETForHashedQueries: true })
.concat(new HttpLink({ uri: '/graphql' }));
export const client = new ApolloClient({
link,
cache: new InMemoryCache(),
});The Apollo persisted-queries link does the hash dance automatically. First request: client sends the hash. Server responds "I don't know that hash" (PersistedQueryNotFound). Client retries with the full query plus the hash, server stores it. From then on, every client that issues the same query sends only the hash.
That's enough to make Cloudflare, Fastly, or your own Varnish cache the response. You can set Cache-Control: public, max-age=60 on safe queries and let the edge serve them. For a high-read, low-write app (a marketing site, a product catalogue, a recipe app), this gets you most of the way to REST-equivalent caching.
For the rest, it doesn't help much. Mutations are still POSTs. Personalised queries (anything that depends on the logged-in user) need Vary headers and per-user cache keys, which CDNs handle poorly. And the moment any mutation invalidates the underlying data, you're back to TTL-based staleness or surgical purges, neither of which is graceful.
So HTTP caching gets you a slice. For the rest, you go up the stack.
The Client Normalized Cache
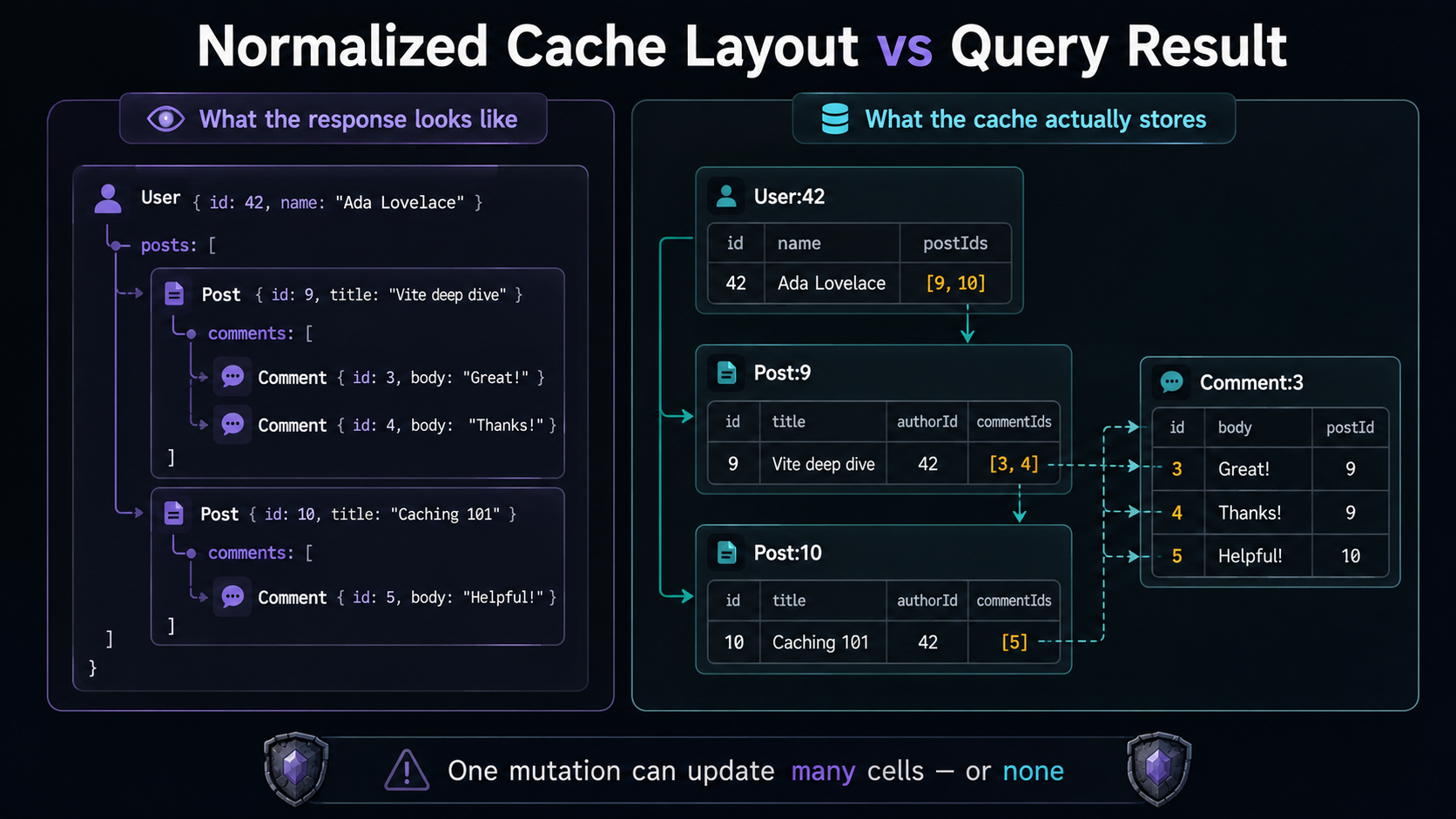
This is the one most GraphQL developers actually interact with. Apollo, urql with its normalized cache exchange, and Relay all do the same fundamental thing: they don't cache responses, they cache entities.
When the server returns:
{
"data": {
"user": {
"__typename": "User",
"id": "42",
"name": "Maria",
"posts": [
{ "__typename": "Post", "id": "9", "title": "Hello world" }
]
}
}
}The client doesn't store the whole response under some query key. It pulls each typed object out and stores them in a flat key-value store, keyed by __typename:id. So you end up with something like:
User:42 -> { id: "42", name: "Maria", posts: [Post:9] }
Post:9 -> { id: "9", title: "Hello world" }
ROOT_QUERY -> { user({"id":"42"}): User:42 }The query result is just a graph of pointers. The actual data lives in those entity records.
This is where the magic happens. The next time any query (a list, a detail page, a sidebar widget) asks for User:42, the cache already has the name. No network call. And when a mutation updates User:42, every component that depends on it re-renders automatically, no matter where in the UI it lives.
Why The Entity Key Matters
Every entity in your schema needs a stable identity for this to work. Apollo defaults to __typename + id. That's the magic phrase: you ask for id on every entity in every query, and Apollo wires it all up for you.
Forget the id field once and the cache silently breaks for that entity. The new fetch overwrites the previous one. Stale data shows up in places you didn't expect.
import { InMemoryCache } from '@apollo/client';
export const cache = new InMemoryCache({
typePolicies: {
Book: {
keyFields: ['isbn'],
},
SearchResult: {
keyFields: false,
},
},
});For entities that don't have an id field (a Book keyed by isbn, or a SearchResult that's deliberately not cached because every search is unique), you tell the cache explicitly. Get this wrong and you'll spend an afternoon wondering why "Maria" keeps coming back from the dead.
Fragments And Partial Data
Normalization also enables the trick that makes GraphQL clients feel snappy: partial data hydration. If you've already fetched a Post somewhere (let's say a list view showed id, title, and author.name) and you navigate to the detail page that needs id, title, author.name, body, and tags, Apollo can render the first three immediately from cache while it fetches the missing pieces.
That's the difference between an app that feels instant and an app that flashes a spinner on every navigation. You don't get it for free in REST without considerable plumbing.
But all of this (the fast renders, the cross-component updates, the partial hydration) rests on the cache being correct. Which brings us to the part nobody warns you about.
Invalidation: The Part That Bites
Invalidation in HTTP caching is brutal but simple: either it's expired or it's not. TTL goes to zero, the cache fetches a fresh copy, done.
Normalized caches have no TTL. The cache holds onto every entity it's seen, forever, unless you tell it not to. That's by design. The whole point is to avoid refetching things that haven't changed. But it means you are responsible for telling the cache when something has changed.
Most of the time, GraphQL mutations make this easy. If your mutation returns the updated entity, Apollo's cache sees __typename: "User", id: "42" in the response and updates User:42 automatically. Every component that depends on it re-renders. No code from you.
const UPDATE_USER = gql`
mutation UpdateUser($id: ID!, $name: String!) {
updateUser(id: $id, name: $name) {
id
name
}
}
`;
const [updateUser] = useMutation(UPDATE_USER);
await updateUser({ variables: { id: '42', name: 'Maria Rivera' } });That's the happy path. The cache picks up the new name from the mutation response and every User:42-displaying component in the tree updates. No refetch, no evict, no manual sync.
The unhappy paths are where you earn your money.
Adding And Removing From Lists
What happens when a mutation creates a new entity? The new Post:10 lands in the cache as a record, but the posts field on User:42 still points to [Post:9]. The list doesn't include the new post until you tell it to.
There are three ways to handle it, each with trade-offs:
const [createPost] = useMutation(CREATE_POST, {
update(cache, { data: { createPost } }) {
cache.modify({
id: cache.identify({ __typename: 'User', id: '42' }),
fields: {
posts(existing = []) {
const ref = cache.writeFragment({
data: createPost,
fragment: gql`
fragment NewPost on Post {
id
title
}
`,
});
return [...existing, ref];
},
},
});
},
});That's the surgical option: write the new entity, splice it into the list. It's exact, it's fast, and it works offline. It also means you write update callbacks for every list-mutating mutation and you maintain them as the schema changes.
The shortcut option is refetchQueries:
const [createPost] = useMutation(CREATE_POST, {
refetchQueries: ['GetUserPosts'],
});You name the queries that need to refetch, the client re-runs them, the new list comes back. Easier to write, but you pay one round trip per mutation, and the UI shows old data until the refetch resolves unless you also write an optimistic update.
The nuclear option is cache.evict({ fieldName: 'posts' }) followed by cache.gc(). The cache forgets the field entirely. Next time someone reads it, the client hits the network. Simple, correct, and wastes a request, but for low-frequency mutations it's the most honest thing you can do.
Most teams end up with a mix. Surgical updates for high-frequency mutations on hot screens. Refetch for less critical paths. Eviction for one-off admin actions. The wrong choice for the situation either burns network requests you didn't need or leaves stale data on screen for a beat too long.
The Cross-Entity Invalidation Problem
The hardest case isn't a single mutation. It's a mutation that implicitly changes other entities. You delete a Comment. The Post's commentCount field changes, but the mutation only returned the deleted Comment's id. The cache has no idea Post:9 needs to recompute its count.
You have two real options. One: redesign the mutation to return the affected Post, so the cache updates commentCount from the response. Two: write a manual cache.modify that decrements commentCount on the Post. Both work. Neither is automatic.
This is where teams that adopted GraphQL because "it removes the over-fetching problem" discover they've traded one form of plumbing for another. REST had explicit endpoints, and you wired your UI to call them in the right order. GraphQL has automatic cache normalization, and you wire the cache to react to mutations in the right way. The work doesn't disappear. It moves.
Server-Side Response Caching
Client caches are personal. Edge caches are coarse. Between them, there's a third layer most teams ignore until traffic forces the question: the server-side response cache.
Apollo Server, Yoga, Mercurius, and Hot Chocolate all ship some form of response cache plugin. The idea is straightforward: store the full response for a given query-plus-variables combination, keyed by the operation name and a hash of variables, with a TTL.
import { createYoga } from 'graphql-yoga';
import { useResponseCache } from '@graphql-yoga/plugin-response-cache';
import { schema } from './schema';
const yoga = createYoga({
schema,
plugins: [
useResponseCache({
session: (request) => request.headers.get('authorization'),
ttl: 30_000,
ttlPerType: { User: 60_000, Post: 5_000 },
invalidateViaMutation: true,
}),
],
});A few things to notice. session makes the cache key per-user: anonymous traffic gets one bucket, each logged-in user gets their own. ttlPerType lets you say "users are stable, cache them for a minute; posts churn, cache them for five seconds". invalidateViaMutation is the killer feature: the plugin watches what types a mutation returns and evicts any cached responses that referenced those types.
That's the part that makes server-side caching tractable. Without automatic invalidation, you're back to writing manual purge calls for every mutation. With it, you get most of the benefit for none of the wiring.
When Server-Side Caching Pays Off
The economics tip in favour of server-side caching when one of three things is true. Your most expensive queries hit slow downstream systems (legacy SOAP service, a reporting database, a third-party API). Your read-to-write ratio is heavily skewed (a feed read ten thousand times for every post). Or your fanout is high: one query needs data from five microservices, and you'd rather not call all five every time.
It does not pay off when your data is hyper-personalised, when freshness matters more than latency, or when your traffic pattern is bursty enough that the cache never warms. The cost of caching is the cost of being wrong, and "wrong" in a caching layer means "showed the user yesterday's price". Decide what you can afford before you turn it on.
The Resolver-Level Story
There's a cache that lives even closer to the resolvers, and most teams already use it without thinking about it: DataLoader.
DataLoader is per-request, not per-deployment. Within a single GraphQL request, if your Post resolver asks for the author of fifty different posts, DataLoader batches them into one findUsersByIds([1, 2, 3, ...]) call. The "cache" is the in-memory map of seen IDs within that request lifetime, which makes the N+1 problem disappear.
import DataLoader from 'dataloader';
export const userLoader = new DataLoader(async (ids: readonly string[]) => {
const users = await db.users.findMany({ where: { id: { in: [...ids] } } });
return ids.map((id) => users.find((u) => u.id === id) || null);
});It's not really a cache in the "valid for the next thirty seconds" sense. It's a request-scoped memoization. But every team writing a non-trivial GraphQL server needs it, because without it your nested queries fan out into a quadratic number of database calls. Mention this in any GraphQL caching discussion and someone will say "well, DataLoader is technically a cache too", and they're right.
Picking The Right Layers
By now you've seen four caches. Edge / HTTP via persisted queries. Server-side response cache with TTLs and per-type rules. Per-request DataLoader. Client-side normalized cache. They stack. You can run all four at once. Most production GraphQL deployments do.
The interesting question isn't "should I cache?". It's "which layer should own which use case?".
Public catalogue data, anonymous traffic, low write frequency? Push it to the edge with persisted queries and aggressive TTLs. The CDN does the work, your origin doesn't see it.
Personalised dashboards, logged-in users, frequent writes? The normalized client cache earns its keep. Optimistic updates make the UI feel instant; mutations return updated entities so invalidation is automatic.
Read-heavy admin views with mostly-stable data and expensive resolvers? Server-side response cache with a 30-second TTL and invalidateViaMutation turned on.
Anything that fans out across services or hits an N+1 trap? DataLoader, no exceptions.
The mistake teams make is picking one layer and pretending it solves everything. Apollo's normalized cache is great, but it doesn't help your anonymous public traffic. A CDN is great, but it doesn't help your logged-in users' personalised feed. Server-side caches are great until your write rate makes the invalidation churn cost more than the cache saved.
The other mistake is leaving all of them on with default settings and discovering, six months in, that a stale Post:9 is showing up because the deletion mutation forgot to return the affected User, the server cache held onto a TTL'd copy, and the CDN had cached the response from before the mutation. Three caches, three different staleness windows, one confused user reporting a bug that takes a day to reproduce.
If there's one rule that holds across all four layers, it's this: every cache you add is a contract about how stale your data is allowed to be. Write that contract down. Pick the TTLs deliberately. Decide which mutations purge what. Test the invalidation paths the same way you test happy-path queries. Because when caching breaks in GraphQL, it doesn't break with a 500. It breaks with a user looking at yesterday's number on today's screen, and no error in any log to tell you why.
Caching in REST was hard because of HTTP semantics. Caching in GraphQL is hard because GraphQL gave you a more expressive query model, and a more expressive query model means a richer space of things that can be wrong. The trade is real, and on a long-running product it's usually worth making, but only after you've understood what you're buying.
Now go look at your network tab and count how many caches are between your client and your database. The answer should not be zero. It should also not be unbounded. Knowing exactly where each layer lives, and what it promises, is what separates the GraphQL apps that scale gracefully from the ones that turn into a debugging side-quest every release.