
You've probably been on a team where someone proposed GraphQL as the answer to a problem that wasn't quite GraphQL-shaped. Or you've been on the team that adopted it three years ago and is now quietly wondering if a few well-named REST endpoints would have been kinder. Either way, the question keeps coming back: in a TypeScript codebase in 2026, is GraphQL still pulling its weight, or has the rest of the stack caught up?
This piece is an honest evaluation, not a takedown and not a sales pitch. The parts of GraphQL that earn their keep are real. The parts that don't are also real, and they bite in production in ways the marketing pages don't dwell on.
The Pitch You Already Know
GraphQL came out of Facebook with three promises stitched together: clients ask for exactly the fields they need, the schema is the contract, and one endpoint serves everyone: mobile, web, internal tools. In a TypeScript app, the schema bit lands especially hard, because your types and your API definitions stop being two separate documents you have to keep in sync. They become the same document.
For a while that was enough to win the argument. REST endpoints over-served data, mobile teams complained about waste, and schema-as-contract felt like a permanent upgrade. The trouble is that everything that wasn't GraphQL also kept improving. OpenAPI types got serious, tRPC arrived as a thinner alternative for full-stack TS, and TanStack Query made client-side cache management feel almost free.
So the question isn't whether GraphQL works. It works. The question is whether the parts that earn their keep (schema, types, exact-field selection) are still worth the parts that don't: resolver discipline, cache invalidation, runtime overhead.
What Schemas Actually Buy You
The strongest argument for GraphQL in a TypeScript app is the schema, and it's not for the reason most blog posts say. The reason isn't "documentation". REST has OpenAPI for that. The reason is that the schema becomes the single source of truth for types on both sides of the network.
You write a schema:
type User {
id: ID!
email: String!
posts(first: Int = 10): [Post!]!
}
type Post {
id: ID!
title: String!
publishedAt: DateTime
author: User!
}
type Query {
me: User
post(id: ID!): Post
}Then a codegen step (graphql-codegen is the standard) reads it and produces TypeScript types for the server's resolvers and for every operation the client sends. Your resolveUser function gets typed args and a typed return value, and your useQuery<MePageQuery>() hook on the client returns a typed data. If you rename a field, both sides fail to compile in the same commit.
That sync is the real prize. Without it, you're either hand-writing types twice or generating them from one side and hoping the other stays honest. With it, the API contract isn't a doc. It's a build-time check.
The catch is that this works best when there's exactly one schema and exactly one server. The moment you have a federated graph stitching together multiple services, or you start putting business logic in the schema by overloading directives, the schema goes from "source of truth" to "thing that has a meeting every Wednesday." Then you're paying the schema tax without getting the typing benefits, because too many people own pieces of it for any one team to move quickly.
Resolvers And The Problem Nobody Likes To Talk About
Resolvers look elegant until you watch them in production. The pattern is: every field on every type has a function that returns that field's value. You ask for me.posts[0].author.name, and the server walks the schema firing one resolver per node:
export const resolvers = {
Query: {
me: (_, __, ctx) => ctx.db.users.findOne({ id: ctx.userId }),
},
User: {
posts: (user, args, ctx) =>
ctx.db.posts.find({ authorId: user.id, limit: args.first }),
},
Post: {
author: (post, _, ctx) =>
ctx.db.users.findOne({ id: post.authorId }),
},
};That looks fine in isolation. Now imagine someone queries users(first: 50) { posts { author { name } } }. The query is one line. Your server fires:
- One query for the 50 users.
- 50 queries for the posts (one batch per user).
- For each post returned, one more query for the author.
You've turned a one-line client query into hundreds of database round-trips. The n+1 problem isn't a quirk of GraphQL. It's enabled by GraphQL, because the schema lets clients compose queries the server didn't anticipate.
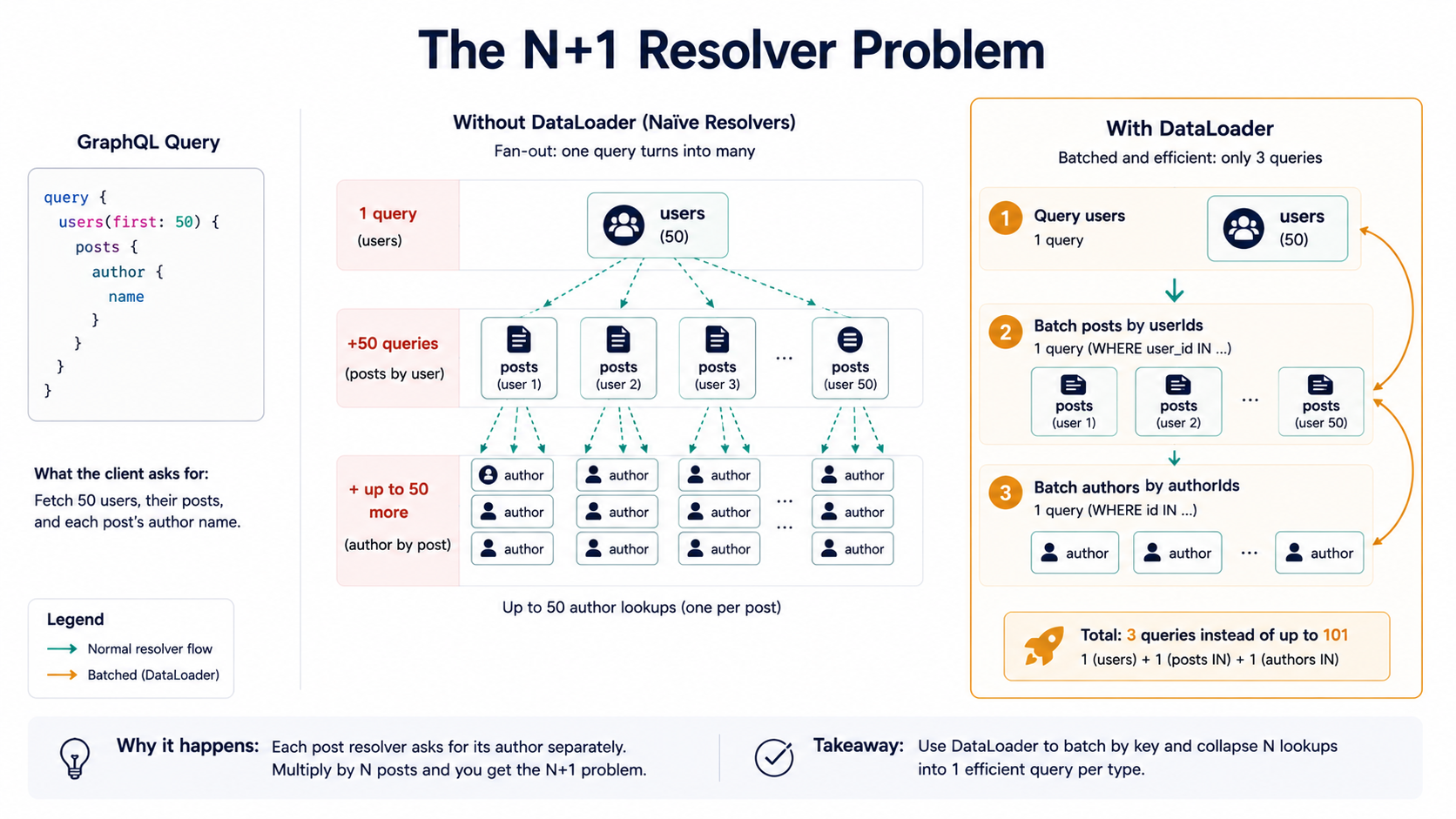
The standard fix is DataLoader, which batches and de-duplicates requests within a single resolver call. You wrap your data access in a loader, and instead of firing 50 queries for the authors, you get one query with 50 ids in an IN clause:
import DataLoader from 'dataloader';
export function createLoaders(db: Db) {
return {
userById: new DataLoader<string, User | null>(async (ids) => {
const users = await db.users.find({ id: { $in: ids as string[] } });
const byId = new Map(users.map((u) => [u.id, u]));
return ids.map((id) => byId.get(id) ?? null);
}),
};
}And in your resolver:
Post: {
author: (post, _, ctx) => ctx.loaders.userById.load(post.authorId),
},DataLoader works. It's not a workaround. It's how production GraphQL is meant to run. But notice what just happened: a feature your client doesn't see, defined per data source, that you have to remember to wire up on every relational edge of your schema. Forget one, and you ship the n+1 to prod. The "REST equivalent" is "the endpoint already knows what it needs and writes the join in SQL." Different mental model, more upfront discipline, fewer silent footguns.
Clients And The Cost Of A Smart Cache
On the client side, GraphQL forces a choice that REST doesn't. You can talk to a GraphQL endpoint with fetch and a typed query, the lightest possible setup, sometimes called "GraphQL without the GraphQL client":
async function gqlFetch<T, V>(query: string, variables?: V): Promise<T> {
const res = await fetch('/graphql', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query, variables }),
});
const json = await res.json();
if (json.errors) throw new Error(json.errors[0].message);
return json.data as T;
}Pair that with graphql-codegen for typed query functions, throw in @tanstack/react-query for caching and refetching, and you've reproduced about 80% of what an Apollo Client gives you with maybe 5% of the runtime cost.
The other 20% is the normalized cache, which is the big idea Apollo and urql sell. Instead of caching responses keyed by query, they break responses into entities keyed by __typename:id and store them in a flat lookup. Update the User:42 entity in one place and every component reading that user re-renders with the new email. It's powerful, and it's where most of the complexity hides.
import { ApolloClient, InMemoryCache } from '@apollo/client';
const client = new ApolloClient({
uri: '/graphql',
cache: new InMemoryCache({
typePolicies: {
User: {
fields: {
posts: {
keyArgs: ['filter'],
merge(existing = [], incoming) {
return [...existing, ...incoming];
},
},
},
},
},
}),
});That typePolicies block is the cost of a normalized cache. For every paginated list, every filtered query, every connection, you have to teach the cache how to merge new results with existing ones. Skip it and you get fun bugs where the next page replaces the first page instead of appending. Get the keyArgs wrong and unrelated queries clobber each other. It's not hard once you know the pattern, but the pattern isn't obvious from the docs, and the failure mode is silent until you click through five screens of broken pagination.
The alternative is urql with its document cache (simpler, less magic, less power) or graphql-request + react-query (no GraphQL-specific caching, just request-level caching keyed on the query). For a lot of TypeScript apps, that last combination is the sweet spot. You get types from codegen, deduping and stale-while-revalidate from react-query, and zero normalized-cache config.
What About Overfetching
The original GraphQL pitch leaned hard on overfetching. REST endpoints, the story went, returned bloated payloads. GET /users/42 shipped you 30 fields when you needed id and email. GraphQL fixed it: ask for two fields, get two fields.
In practice this matters less than it looked like it would in 2016, for two reasons.
The first is that most apps are not bandwidth-bound. They're round-trip-bound. Trimming 4KB off a 6KB response saves you almost nothing on a fast connection; it's noticeable on a 2G mobile network in a rural area, and that's a real concern for products that serve those users, but it's not the bottleneck for the median Node service. Saving a round trip, by batching or by doing the work server-side, beats trimming the payload of a single round trip by a wide margin.
The second is that REST got better at this. Sparse fieldsets (?fields=id,email), JSON:API, and explicit endpoint design ("we have a users-summary endpoint that returns the slim version and users-detail that returns everything") get you most of the overfetching win without paying for a query language. If your REST endpoints are bloated, the answer might just be "design your REST endpoints better."
Where GraphQL still wins on overfetching is when the client side is genuinely heterogeneous: iOS app, Android app, web app, and partner integrations all hitting the same backend and each needing a different shape. Then "every client asks for the fields it needs" is a feature you'd otherwise have to build by hand with multiple endpoint variants, and that gets ugly fast.
Caching On The Server
The conversation usually stops at the client cache, but the server side has its own caching story and it's where GraphQL gets harder than REST.
REST has HTTP caches. GET /users/42 is cacheable by every layer between your service and the user: your CDN, the browser, an in-cluster reverse proxy. The URL is the key, the response is the value, and the standard tells everyone what to do.
GraphQL, by default, defeats most of that. Every request is a POST with a query body, so the URL is the same regardless of what you're asking for. CDNs can't cache it. You can get the caching back, but you have to opt in:
- Persisted queries: the client sends a hash, the server looks up the canonical query text by hash. Now your URL effectively varies on the hash, which means CDNs can cache responses again. Apollo and Relay both support this.
@cacheControldirectives: fine-grained TTLs declared on the schema, with the server emitting standard cache headers based on the lowest TTL across the resolved fields.- Application-level caches keyed on the parsed query plus variables.
All of these work. None of them are free. You're rebuilding, in your application layer, what REST gets from the protocol. That's an honest trade-off, not a deal-breaker, but it's a line item that the original GraphQL pitch didn't include.
When To Reach For It
Here's where I'd actually pick GraphQL in a TypeScript codebase in 2026:
You have many client types (first-party mobile, web, and partner API consumers), and each wants a different slice of the same data graph. The schema + per-client query story is much cleaner than maintaining endpoint variants.
Your data is genuinely graph-shaped, with a lot of relational walking that's hard to predict. Think social networks, document outlines, knowledge graphs. The composability of GraphQL queries is a real win when "click any node, see related nodes" is a core interaction.
You're building a product where the public schema is part of the product: Shopify, GitHub, Linear-style developer platforms. The introspection, tooling, and self-documentation pay off because your users are integrating, not just consuming.
And here's where I'd skip it:
A small or medium SaaS app with one web client. The schema benefits are real but you can get most of them from tRPC or OpenAPI codegen, without the cache and resolver overhead.
A team that's never run GraphQL in production. The happy path is friendly. The production path (n+1, cache invalidation, persisted queries, error handling, query depth limits, schema federation) has more sharp edges than the docs make obvious.
An internal-only API where you control both ends. There's no overfetching argument when you can shape the endpoint to fit the client exactly. Just write the endpoint.
So, Still Useful?
Yes, for a smaller set of cases than the 2018 hype suggested, and on more honest terms. The schema-as-contract idea is still excellent, especially in TypeScript where the generated types feel native. The resolver model is a real shift in how you think about server data fetching, and DataLoader has been load-tested by enough companies that the n+1 story is solved as long as you actually wire it up. The client side is where the trade-offs bite hardest, and the smart move is often to use GraphQL as a transport (schemas, codegen, typed queries) without buying into the normalized-cache complexity.
GraphQL isn't dead. It's grown up. The hype peaked, the alternatives got serious, and what's left is a real tool for real problems, used by teams who picked it on purpose, not because it was 2018 and everyone was doing it.





