There's a comfortable moment, early in a GraphQL project, when the schema fits in one file and every type maps cleanly to a database table. User has the same fields as the users table. Order has the same fields as orders. You feel like a genius — you've replaced a folder of REST endpoints with a single, self-documenting graph.
Then the schema grows. Someone adds a viewer query. A second team adds Product. A third team wants to query Order but only the public-safe fields. Inputs start drifting — CreateUserInput has email required, but UpdateUserInput has it optional and also accepts a brand new preferredLanguage field that doesn't appear on the type. Mutations sprout boolean return values, then nullable types, then nested error fields with codes that nobody documented. Two years in, your "self-documenting graph" is a 12,000-line schema.graphql that nobody fully reads anymore, and breaking changes ship without anyone noticing because every type is owned by everybody and nobody.
That's the moment people start asking what they should have done differently. The honest answer is that big GraphQL schemas don't fail because GraphQL is bad — they fail because schema design at scale is its own discipline, and it doesn't look much like database modelling, REST endpoint design, or RPC.
This piece is about that discipline. Types, inputs, mutations, and the boundaries that hold a large schema together when twenty teams are pushing changes a week.
Types: stop mirroring your database
The first instinct in any GraphQL project is to ship a type per table. It feels obvious. The table is already there. The columns are already named. Why invent another shape?
The reason is that your database schema answers a different question than your GraphQL schema. The database is optimised for storage and integrity — denormalised columns where you needed performance, normalised tables where you needed correctness, nullable columns because some rows have history and some don't. The GraphQL schema is supposed to answer the question "what does a client want to express?" — and a client almost never wants the literal row.
A client wants to express things like "the currently authenticated user, with their three most recent unread notifications". That sentence is the type. Not users JOIN notifications.
Here's a schema that mirrors the database:
type User {
id: ID!
email: String!
password_hash: String!
created_at: String!
updated_at: String!
deleted_at: String
email_verified_at: String
last_login_ip: String
preferences_json: String
}Nine fields, almost all of them either irrelevant to the client (password_hash, last_login_ip) or stringly-typed because the database stores them as strings (preferences_json). The client now has to know that preferences_json is actually a JSON blob it needs to parse. Worse, every consumer of User is shaped by what the users table happens to contain today.
The intent-driven version is much smaller and much sharper:
type User {
id: ID!
email: EmailAddress!
displayName: String!
emailVerified: Boolean!
createdAt: DateTime!
preferences: UserPreferences!
}
type UserPreferences {
locale: Locale!
theme: Theme!
emailDigest: EmailDigestFrequency!
}
enum Theme {
LIGHT
DARK
SYSTEM
}Notice what changed. password_hash and last_login_ip are gone — they're not concepts a client should be able to ask for, even by accident. The JSON blob became a typed UserPreferences object with its own enums. email_verified_at (a nullable timestamp) became emailVerified: Boolean! (a non-null derived value). The dates are real DateTime scalars, not strings. The pattern is the same in every field: what does the client need to know, not what is in the row.
The same logic applies upward. A large schema benefits from naming the relationship between user and the rest of the graph through a Viewer type:
type Query {
viewer: Viewer
user(id: ID!): User
}
type Viewer {
user: User!
unreadNotificationCount: Int!
recentNotifications(first: Int = 10): NotificationConnection!
permissions: ViewerPermissions!
}Viewer is a small but powerful idea. It separates "the user as a public entity" (queryable by ID, visible to other users) from "the user as the authenticated caller" (whose unread count and permissions only make sense in their own session). In a small schema, this looks like over-engineering. In a large one, it's the difference between a query you can authorize with a single check at the top of the resolver tree and a query where every leaf has to re-check who's calling.

A few practical rules for type design once a schema is past the toy stage:
Custom scalars carry intent. String says "any text". EmailAddress! says "this is an email, validate it, accept it as one in inputs, reject malformed values at the schema layer". The same is true for URL, DateTime, Duration, Currency, JSON (yes, sometimes a typed JSON scalar is honest about what you're returning — a blob of analytics events doesn't deserve a thousand fields). Define them once at the schema root, reuse everywhere. Validation moves out of resolvers and into the type system.
Interfaces and unions are how a graph becomes a graph. If Notification is a real concept, but it has three concrete shapes (CommentNotification, MentionNotification, SystemNotification), don't flatten them into one type with thirty nullable fields. Make Notification an interface, give it the fields they all share (id, createdAt, read), then let each concrete type add its own. Clients ask for the common fields with one query and ... on CommentNotification { comment { ... } } for the specifics. The schema documents the variation instead of hiding it.
The Node interface is cheap, and it pays off. Picking the Relay convention — every entity implements interface Node { id: ID! }, and there's a top-level node(id: ID!): Node query — gives you global object identity for free. Caching libraries, dev tools, and federation gateways all understand the pattern. The marginal cost is one extra line on each type. The upside is that "refetch any entity by its global ID" becomes a built-in, not a custom resolver per type.
Pagination is a type decision, not an argument decision. Don't return [Post!]! and call it done — once a list can grow, you'll regret not having forward/backward pagination, cursors, and total-count semantics in the type. Connections are verbose but they survive scale:
type Query {
posts(first: Int, after: String, last: Int, before: String): PostConnection!
}
type PostConnection {
edges: [PostEdge!]!
pageInfo: PageInfo!
totalCount: Int
}
type PostEdge {
cursor: String!
node: Post!
}
type PageInfo {
hasNextPage: Boolean!
hasPreviousPage: Boolean!
startCursor: String
endCursor: String
}If you start with [Post!]! and try to retrofit cursors in year two, you're looking at a breaking change for every client that consumed it. Pay the verbosity tax up front — it's small.
Inputs: not just types with question marks
Inputs are where most schemas quietly rot. The pattern that breaks them is treating the input type as "the same fields as the output, but most of them optional".
That works for two months. Then someone adds a field that exists on the input but not the output (a one-time-use verificationCode you accept on create but never return). Then someone makes a field optional in Update that's required in Create — and you forget to enforce it server-side. Then a client sends null instead of omitting the field, and now you're guessing whether null means "set it to null" or "leave it alone".
Distinct, purpose-built input types are the antidote.
input CreatePostInput {
title: String!
body: String!
tags: [String!] = []
publishAt: DateTime
}
input UpdatePostInput {
id: ID!
patch: UpdatePostPatch!
}
input UpdatePostPatch {
title: String
body: String
tags: [String!]
publishAt: DateTime
}
input PublishPostInput {
id: ID!
}A few things to notice. CreatePostInput has every required field as non-null. UpdatePostPatch makes everything optional — but it's a separate type, so nobody can confuse them. PublishPostInput is its own input, even though it only carries an ID, because "publish a post" is a different intent than "update a post and happen to flip its publishedAt field". The intent shows up in the type name.
The null vs missing problem is a real one. GraphQL distinguishes between "this field was not provided in the input" and "this field was explicitly set to null", but most server libraries do not surface that distinction by default. If you're going to allow partial updates, you have two honest options:
The first is to use a separate "unset" marker. Instead of accepting null in a partial update, you accept an enum or a sentinel:
input UpdateUserPatch {
email: String
displayName: String
bio: BioInput
}
input BioInput {
set: String
unset: Boolean
}Verbose, but the semantics are unambiguous. bio: { set: "..." } sets a value. bio: { unset: true } clears it. Omitting bio entirely leaves it alone.
The second is to read the raw GraphQL info object and check which fields were present in the query. Most server libraries can do this — info.fieldNodes[0].arguments or equivalent — but the ergonomics are bad and the rule "any field absence means leave-alone" has to be documented somewhere a client team will actually read.
Pick one, write it down in the schema's contributing guide, and never mix them. The worst version of this is a schema where some mutations treat null as "leave alone" and others treat it as "set to null".
A more subtle input mistake is the input enum that overlaps with a field. Imagine status: PostStatus on Post, and UpdatePostPatch with status: PostStatus. Now somebody asks for "unpublish a post" and adds a new mutation, but it just calls updatePost with { status: ARCHIVED }. Six months later, the audit log has no record of who archived what because the business event was hidden inside a generic update. Mutations name intents — a status field in a patch isn't one.
Mutations: return types are where schemas grow up
Most GraphQL schemas start with mutations that return the affected entity:
type Mutation {
createPost(input: CreatePostInput!): Post
updatePost(input: UpdatePostInput!): Post
deletePost(id: ID!): Boolean
}This is fine for week one. The problems start when any of these can fail in a way the client cares about — and at scale, all of them can. Validation errors, authorization errors, optimistic-concurrency conflicts, rate limits, third-party service outages. With the naive shape, you have two choices: throw a GraphQL error (which goes in the top-level errors array and isn't typed) or return null (which carries no information).
Throwing works for exceptional problems. The schema is for expected outcomes. A failed login isn't exceptional — it's one of two normal outcomes. A coupon code that doesn't apply isn't an exception — it's a result.
The pattern that solves this is making the mutation return a result type — usually a union, sometimes a payload object with typed errors:
type Mutation {
createPost(input: CreatePostInput!): CreatePostResult!
publishPost(input: PublishPostInput!): PublishPostResult!
}
union CreatePostResult =
| CreatePostSuccess
| ValidationError
| RateLimitedError
type CreatePostSuccess {
post: Post!
}
union PublishPostResult =
| PublishPostSuccess
| NotAuthorizedError
| PostAlreadyPublishedError
| PostScheduledInFutureError
type PublishPostSuccess {
post: Post!
publishedAt: DateTime!
}
interface UserFacingError {
message: String!
code: String!
}
type ValidationError implements UserFacingError {
message: String!
code: String!
fields: [FieldError!]!
}
type FieldError {
path: String!
message: String!
}
type NotAuthorizedError implements UserFacingError {
message: String!
code: String!
}
type RateLimitedError implements UserFacingError {
message: String!
code: String!
retryAfterSeconds: Int!
}
type PostAlreadyPublishedError implements UserFacingError {
message: String!
code: String!
publishedAt: DateTime!
}
type PostScheduledInFutureError implements UserFacingError {
message: String!
code: String!
scheduledFor: DateTime!
}The first time you write this, it feels like a lot of types for one mutation. After you've shipped a few of them, you stop noticing — and your clients stop having to guess what went wrong.
What you get is a contract the client can exhaustively handle. The frontend writes:
const result = await client.publishPost({ id });
switch (result.__typename) {
case "PublishPostSuccess":
showToast(`Published at ${result.publishedAt}`);
break;
case "NotAuthorizedError":
redirectToLogin();
break;
case "PostAlreadyPublishedError":
showToast(`Already published at ${result.publishedAt}`);
break;
case "PostScheduledInFutureError":
showToast(`Scheduled for ${result.scheduledFor}`);
break;
}If you add a new error type to the union next month, TypeScript or your client codegen will tell every consumer. If you'd kept the naive Post return and surfaced errors via the top-level errors array, you'd be parsing error.extensions.code strings and hoping nobody renamed them.
A small but important call: the success type is also its own type, not the bare Post. That gives you somewhere to put non-entity outputs of the mutation — publishedAt, the cache invalidation hint, the new total count, a one-time-use signed URL. You almost always want one of those eventually. Once the mutation returns Post directly, you can't add them without a breaking change.
Other mutation patterns worth picking up early:
Idempotency keys are a mutation-input concern. If clients can retry — and at scale, every client retries — createPayment(input: { idempotencyKey: ID!, ... }) saves you a real production incident. Yes, it's an input field, not a header. GraphQL doesn't have HTTP-style request semantics. Put it in the input where it can't be forgotten.
Bulk mutations need to think about partial failure. bulkArchivePosts(ids: [ID!]!): BulkArchivePostsResult returns a result that lists which IDs succeeded and which failed, with per-ID error details. Anything else collapses information the client will eventually need.
Subscriptions are mutations' shadow. If a mutation modifies state that another user is looking at right now, somewhere there's a subscription publishing it. Co-locating their schemas — same module, same review cycle — keeps the two from drifting. A mutation that changes a Post's publishedAt should publish to subscription { postUpdated(id: $id) { ... } } with the same payload shape it returned.
Boundaries: the schema is a product
This is where small schemas and large schemas part company. In a small schema, every type belongs to the schema. In a large schema, every type belongs to a team, and the schema's job is to make that ownership readable.
You can do this without federation, and you can do it with federation. The decision depends on the org, not the technology.
Without federation, the schema is one repository but organised by module. Each module owns a directory: types, resolvers, tests, and a README that names the team. The build step concatenates module schemas into one root, but no module imports types from another except through a small, explicit set of "shared" types (User, Money, DateTime, error types). Cross-module references happen by ID — the Order module never reaches into the Catalog module's Product type definition; it stores a productId and the gateway resolves it through a dataloader.
This works surprisingly well up to maybe ten or fifteen teams. The friction shows up at review time — every team's changes go through the same schema.graphql, which means cross-team PR review, which means a schema-review bottleneck.
Federation moves the bottleneck. With Apollo Federation (or the equivalent in other tools), each team runs their own subgraph with its own schema. The gateway composes them at build time. The User type is owned by the identity team, but the Order team can extend it with orders: [Order!]!. The composition step is what enforces consistency.
type User @key(fields: "id") {
id: ID!
email: EmailAddress!
displayName: String!
}extend type User @key(fields: "id") {
id: ID! @external
orders(first: Int, after: String): OrderConnection!
}
type Order @key(fields: "id") {
id: ID!
total: Money!
status: OrderStatus!
user: User!
}The shape the client sees is unified. viewer { user { orders { edges { node { total } } } } } works as one query, but it's two services, two deployments, two teams. The boundary is real but the API is seamless.
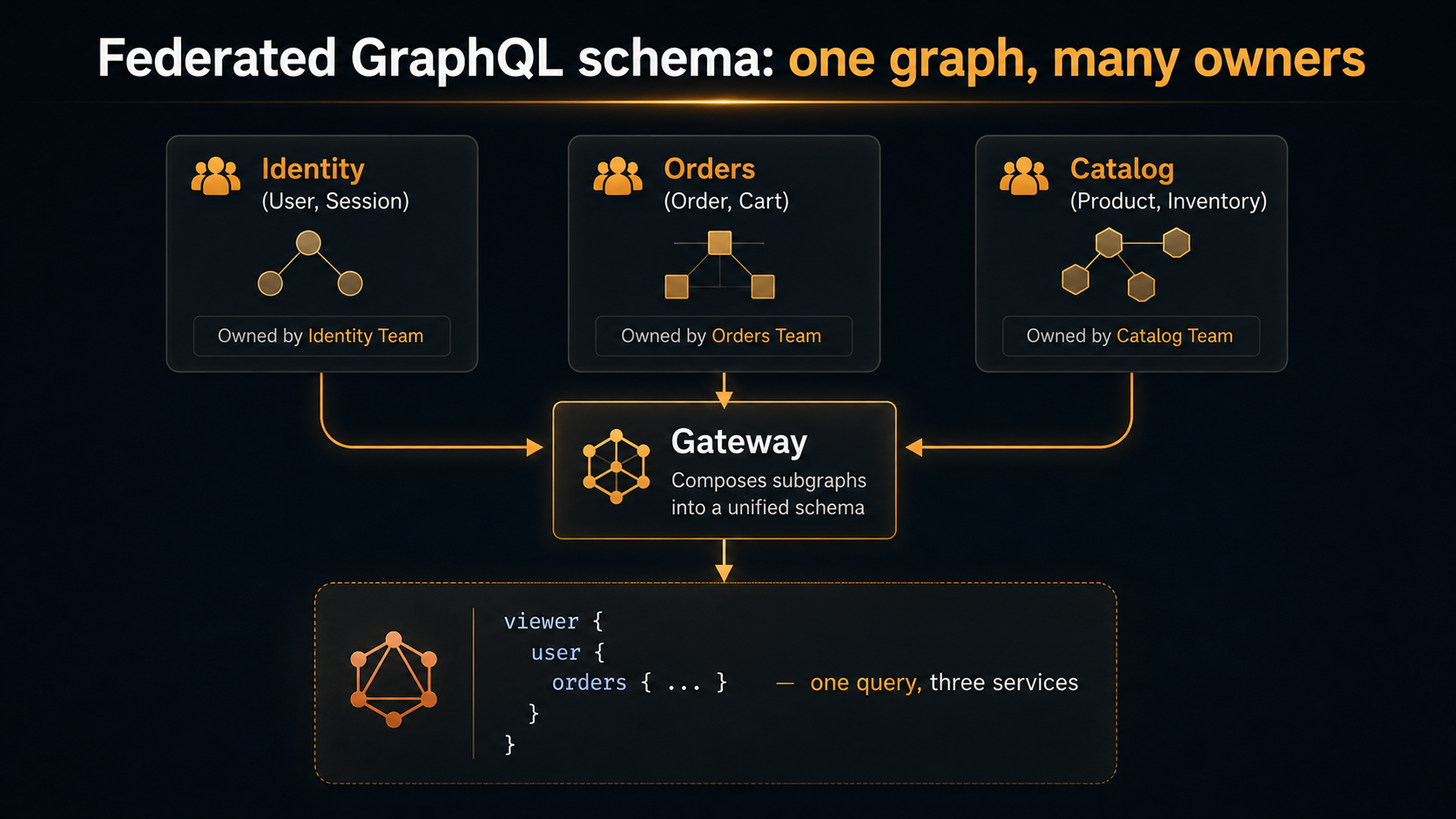
Federation isn't free. Composition errors are a new failure mode — your CI now has to verify that a change to the Orders subgraph doesn't break a User extension owned by Identity. Latency is additive across subgraphs unless you batch carefully. And the operational surface is bigger: one gateway, N subgraphs, N+1 things to monitor. The trade-off only makes sense when the team boundaries are real — when you genuinely can't have one team approving every PR.
Some practical rules either way:
One schema, many owners — every type has a # Owner: team-name annotation, in a comment, at the top of the type. This is more important than it sounds. When something breaks, the question "who owns this type?" needs an answer that doesn't require reading commit history. A one-line comment makes that answer searchable.
Cross-module relationships are by ID, not by object reference, by default. If Order needs Product, store productId: ID! in your data layer, then have the resolver fetch the Product via a dataloader at the gateway. This keeps the modules genuinely separable. If you let Order directly carry a Product reference, you've coupled the two at the data layer and you'll never unwind it.
Shared types live in a tiny, explicit, slow-moving module. Money, DateTime, EmailAddress, the error interfaces, PageInfo, Node. That module's review cycle is slower than everyone else's because changes ripple everywhere. Making this module physically small and explicitly listed in the schema's contributing guide reduces accidental additions.
Don't expose internal services through the schema 1:1. If your billing service has 47 endpoints, the schema doesn't need 47 mutations. It needs the 6 or 7 mutations that match what clients actually do — "start checkout", "apply coupon", "complete payment". The schema is a product surface, not an RPC bridge.
Evolution: how the schema gets older without breaking
The last big topic in large-schema design is evolution. The naive policy is "never break a client" — and it sounds noble, but in practice it produces schemas full of three versions of the same field, each subtly different, none of them documented.
The honest policy is "deprecate loudly, remove on a published schedule, monitor usage".
GraphQL gives you @deprecated(reason: "...") on fields, args, and enum values. Use it. Couple it with a real metric: every deprecated field's usage is logged, you watch the usage curve drop over weeks, and only when the curve hits zero do you actually remove the field. If a client team is still using it after the announced sunset, you have a conversation, not a surprise outage.
type User {
id: ID!
email: EmailAddress!
fullName: String! @deprecated(reason: "Use `displayName` — `fullName` will be removed on 2026-09-01. See ADR-0142.")
displayName: String!
}The deprecation message links to the decision record. The date is real. The replacement is in the message. Anybody who runs into the field knows what to do and how long they have.
A few additional habits that pay off:
Schema diffs run in CI. Tools like graphql-inspector or the Apollo schema check will flag any non-additive change against the previous schema. Breaking changes don't merge without a PR-level override and an explicit migration note. This is a five-minute setup that saves you from the "oh, we removed that field three weeks ago" conversation forever.
A @private-style directive for internal-only fields. Some fields exist for back-office tools, not for public clients. Marking them with a custom directive (@internal, @adminOnly) and having the gateway strip them based on the calling context keeps a single source of truth without polluting the public API. The downside is one more piece of infrastructure to maintain, so think hard before adopting it — if the difference between internal and external surfaces is large, a separate schema (or a separate subgraph) is cleaner.
Don't version the URL. Version the type. If a real breaking change is necessary and migration isn't possible, add UserV2 alongside User, deprecate User, and run them in parallel until adoption flips. Versioning the endpoint (/graphql/v2) breaks every introspection tool, splits your tooling, and signals that the schema is brittle. Versioning a type is local — only the affected callers care.
Schema reviews are real reviews. A type added to the schema in haste is much harder to remove than a function added to a service in haste. The asymmetry is severe: the function has maybe a dozen callers and they're all in your repo; the type has clients you've never met. A 30-minute schema review meeting per week, with a small standing group, catches more avoidable damage than any linter.
What this looks like a year in
If you do this for a year — intent-driven types, purpose-built inputs, result unions for mutations, named team ownership, federation when teams need it and modules when they don't, deprecation with metrics — your schema starts to feel like a product. New engineers can navigate it. Errors are typed. Changes are scoped. The graph doesn't fight you when you want to add a feature.
If you don't, the schema starts to feel like a database export with a foreign accent. Adding anything new requires reading the whole file. Removing anything is impossible because nobody knows who depends on it. Mutations return Boolean and the actual reasons for failure live in Sentry, where the product team can't see them.
The good news is none of this requires exotic tooling. SDL is the same SDL it was on day one. Custom scalars, interfaces, unions, input types, deprecation — these are all in the base spec. Federation is one library on top. The rest is taste, ownership, and the patience to type out a union CreatePostResult = ... instead of Post.
Worth it. Every time.