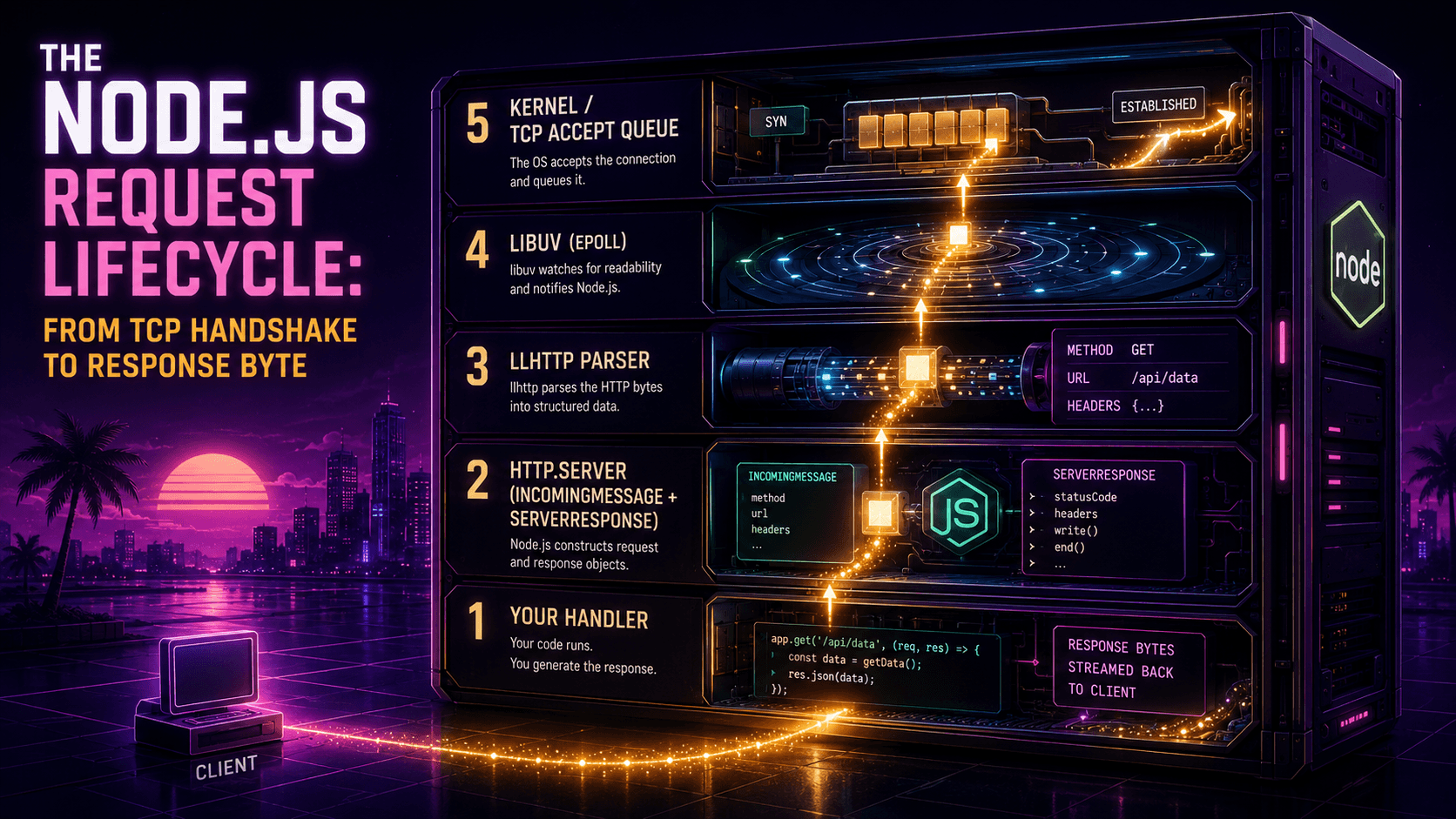
Here's a question that sounds simple and isn't. When you write fs.readFile('big.log', cb) in Node, and your CPU has 8 cores, and the file is 2 GB on a slow disk, what is actually doing the reading?
If your answer is "the event loop, asynchronously, that's the whole point of Node," you're half right and half wrong in a way that matters. The event loop isn't reading anything. It's sitting in a while loop waiting to be told the read is done. Something else is doing the read, and depending on which API you called, that "something else" is either the kernel directly, or a small pool of OS threads that ship with every Node process whether you knew about them or not.
Node is famously "single-threaded." The marketing is true and the engineering is more interesting. Let's pull the floor up.
The thing Node is actually selling
The pitch is: "non-blocking I/O on a single thread." Most explainers stop there, draw a circular arrow labeled "event loop," and call it a day. That diagram is correct and useless: it tells you the shape, not the mechanism.
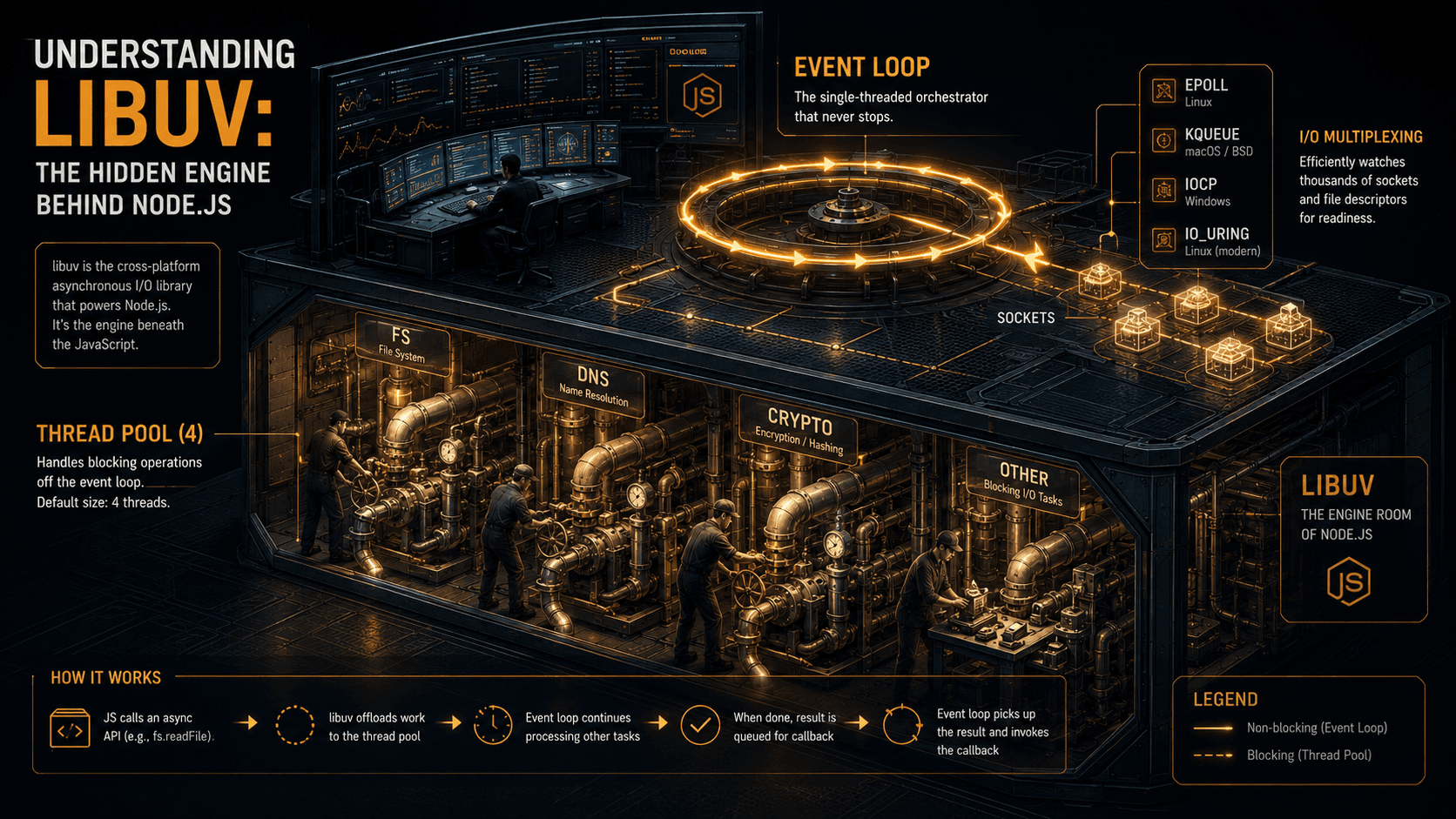
The mechanism is libuv. It's a C library, originally written for Node, that abstracts over four very different OS-level concurrency primitives:
epollon Linuxkqueueon macOS and the BSDsIOCP(I/O Completion Ports) on Windowsevent portson SunOS / illumos
These are the kernel's way of saying "here's a file descriptor, tell me when something happens to it, and let me go do other work in the meantime." They are the reason Node can hold tens of thousands of open sockets on a single thread without blowing up. Your JavaScript runs in one V8 thread; libuv hands the kernel a stack of "wake me when this socket is readable" requests and waits.
But not everything can be done that way. And that's where the second mechanism shows up: the thread pool.
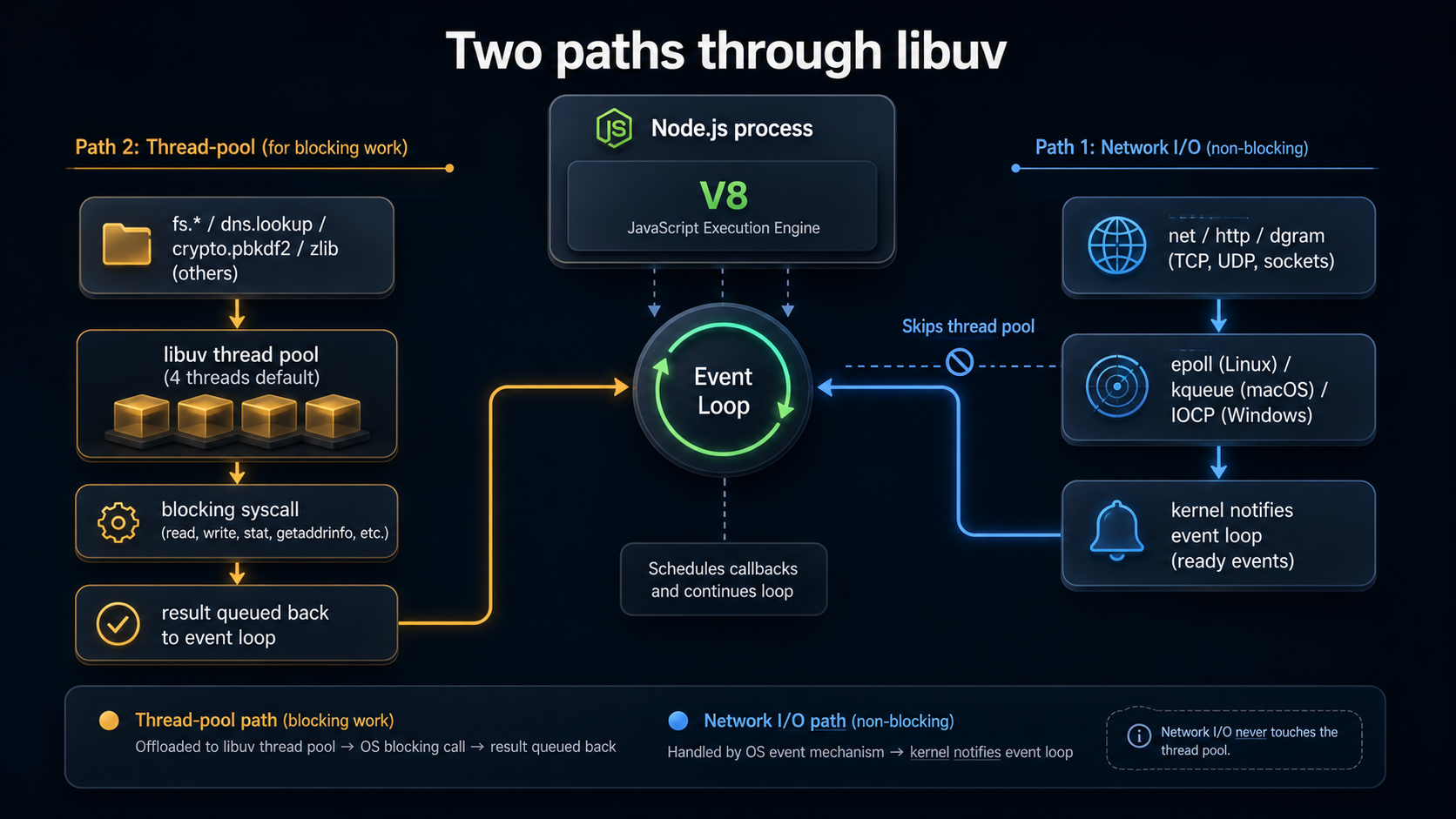
Two completely different worlds: sockets vs. files
This is the single most useful thing to internalise about Node concurrency. There are two different machines running underneath your async code, and the API surface looks identical from the JavaScript side.
World 1: network I/O. When you open a TCP socket, an HTTP request, a UDP datagram listener, libuv registers the file descriptor with the OS-native polling primitive (epoll, kqueue, IOCP). The kernel itself watches for activity. No extra thread is involved. When the socket becomes readable, the kernel notifies libuv, libuv puts a callback into the event loop's poll-phase queue, and your JS runs. This is the part Node is genuinely good at. It scales to enormous fan-out because the cost per connection is almost nothing.
World 2: file I/O, DNS lookups, crypto, zlib. These can't be done non-blockingly on every platform. On Linux, even with io_uring shipping in modern kernels, libuv's default file ops still go through a pool of worker threads. So libuv keeps a small pool, by default 4 threads, and hands these operations off. The thread blocks on the syscall. When it returns, the result is queued back to the event loop, and your callback fires.
That's why fs.readFile and https.get look the same to your code but behave nothing alike under load. Fire off 10,000 HTTP requests and Node is comfortable. Fire off 10,000 fs.readFile calls and Node will happily queue them, but only 4 are running at any moment, because that's how many threads are in the pool.
The default of 4 is older than you think, and you can change it
The thread pool defaults to 4 threads. That number has been the default since libuv was extracted from Node's original IOWatcher work in 2011. It's tunable via the UV_THREADPOOL_SIZE environment variable, and since libuv 1.30.0 the maximum was raised from 128 to 1024.
There is one catch that bites people: you have to set it before Node starts. Setting process.env.UV_THREADPOOL_SIZE inside your app does nothing. The pool has already been created by the time your code runs. It has to be in the shell, the systemd unit, the package.json script, the Dockerfile, anywhere that's evaluated before the node binary launches.
"scripts": {
"start": "UV_THREADPOOL_SIZE=16 node server.js"
}When does cranking it up actually help? Roughly: when your bottleneck is concurrent disk I/O, DNS lookups via dns.lookup, or thread-pool-bound crypto. A static-file server serving 200 cold reads/sec from a slow disk, yes, raise it. A REST API that just shuffles JSON between sockets and Postgres, no, you're network-bound and the pool is idle.
A subtle and underdiscussed footgun: dns.lookup() uses getaddrinfo via the thread pool, but dns.resolve4() and friends use libuv's native non-blocking resolver. If your app does heavy hostname resolution and you're seeing weird latency spikes, your DNS calls might be starving the same pool your file reads are using. Switching to dns.resolve removes that contention entirely. Most Node devs go their whole career without learning that distinction, and then one day a service-discovery DNS storm takes down their image-processing pipeline.
What "the event loop" actually does, step by step
Once you accept that libuv is doing the heavy lifting, the event loop itself stops being mysterious. It's a while (alive) { ... } in C that walks through six phases on every tick. Each phase drains a specific queue of callbacks, then moves on. The phases are:
- Timers: fires callbacks whose
setTimeout/setIntervaldeadline has passed. Note "has passed", not "is exact". AsetTimeout(fn, 100)is a minimum of 100 ms; the actual delay depends on how long previous phases ran. - Pending callbacks: runs a small set of I/O callbacks that were deferred from the previous iteration (e.g., certain TCP errors like
ECONNREFUSED). - Idle, prepare: libuv's internal housekeeping. You don't touch this from JS.
- Poll: the heart of it. This is where the loop asks the OS "anything ready?" via
epoll_wait/kevent/GetQueuedCompletionStatus. It runs the resulting I/O callbacks until the queue is empty or it hits a system-dependent hard limit. If nothing is ready and there are no other timers orsetImmediates, this is where the process sleeps, blocked in a kernel call, costing zero CPU. - Check: runs
setImmediatecallbacks. Specifically after poll, which is whysetImmediateis "the I/O-aware setTimeout(fn, 0)". - Close callbacks: runs
'close'event handlers for things likesocket.destroy().
Then the loop wraps around to timers and goes again.
Two queues are special: they are not phases, they drain between every callback in every phase. The process.nextTick queue runs first, then the microtask queue (promises). That's why a runaway process.nextTick recursion can starve I/O completely. The loop never gets back to the poll phase.
function evil() {
process.nextTick(evil);
}
evil();
setTimeout(() => console.log('I will never run'), 0);
http.get('http://example.com', () => console.log('me neither'));The timer fires "after 0ms" in human time, but the event loop is wedged before it can advance to the timers phase. Same goes for an unawaited while (true) in any callback. Node is cooperative, not preemptive. The thread that runs your JS is the same thread that decides when to check for I/O. If you don't yield, nothing yields for you.
"Single-threaded" is a lie of convenience
Open htop while a Node process is running and you'll see something like five or six threads. That's the V8 main thread (your JS), the four default libuv worker threads, and usually one or two more for V8's own background work (background compilation, GC marking, etc).
It is single-threaded for your JavaScript. That's the part of the contract Node preserves. Two callbacks never run at the same time. You don't need locks, mutexes, or atomic operations to protect a counter increment, because there is no second thread that could interrupt you mid-statement. That property is a gigantic productivity win, and every web developer who's chased a Java race condition through 30 stack frames knows what it's worth.
But concurrency and parallelism are not the same word. Node gives you cheap concurrency (lots of things in flight) without parallelism (multiple JS callbacks running simultaneously). For network-heavy workloads that's perfect. For CPU-heavy ones it's a wall, and the wall is the reason worker_threads and the cluster module exist.
When the single thread isn't enough: three escape hatches
The whole event-loop model assumes your callbacks return quickly. A callback that runs for 200 ms blocks every other connection on that process for 200 ms. So when you have actual CPU work, Node gives you three escape hatches, each with a different shape:
1. worker_threads: real threads, shared memory
Introduced as stable in Node 12 (2019). A Worker runs JavaScript in a separate OS thread with its own V8 isolate and its own event loop. Communication happens via postMessage (structured-clone copy) or, for performance, via SharedArrayBuffer for true shared memory plus Atomics for coordination.
Use this when you have CPU-bound JS that you want to run in parallel with your main thread: image resizing, parsing a 100 MB log, ML inference, parsing a huge JSON blob. The communication cost is non-trivial, so workers shine when the work-per-message is large.
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const w = new Worker(__filename);
w.postMessage({ n: 1_000_000_000 });
w.on('message', (sum) => console.log('sum:', sum));
} else {
parentPort.on('message', ({ n }) => {
let s = 0;
for (let i = 0; i < n; i++) s += i;
parentPort.postMessage(s);
});
}2. cluster: multiple processes, one port
cluster forks the whole Node process. Each worker has its own V8, its own event loop, its own memory. They share a listening port via the primary process and the OS load-balances incoming connections across them.
Use this when you want to scale a stateless HTTP server across CPU cores with crash isolation. If one worker segfaults, the others keep serving. It's the classic "spawn N workers where N = number of cores" pattern. The trade-off: no shared memory. Each worker is a separate Node instance with separate caches, separate database pools, separate everything. For most web APIs that's fine; for in-memory state it's a problem.
3. The libuv thread pool you already have
This is the unsexy one, but it's the answer more often than people realise. If your bottleneck is I/O concurrency (many parallel file reads, many pbkdf2 calls, many gzip compressions), you don't need workers or cluster. You just need to raise UV_THREADPOOL_SIZE and let libuv do the work it was built for.
The decision matrix is roughly: CPU-bound and parallel JS goes to worker_threads. Scale across cores for a stateless server goes to cluster. Lots of thread-pool-bound I/O goes to UV_THREADPOOL_SIZE. Plenty of real services end up combining all three.
A scene that explains everything
Imagine a restaurant with one waiter (the event loop) and four cooks in the back (the thread pool). The waiter takes orders, brings food, refills water, never stops moving, never stands still.
When a customer orders a salad (a network read, basically free), the waiter walks to the prep station, grabs it himself, brings it back. Fast, no help needed.
When a customer orders a slow-roasted brisket (a fs.readFile on a big file), the waiter hands the ticket to a cook. The cook starts the brisket; the waiter goes back to the floor. Twenty minutes later, the cook rings a bell, the waiter grabs the dish, delivers it.
Now imagine all five tables at once order brisket. The waiter hands out four tickets, but there are only four cooks. The fifth ticket sits on the rail. That table waits not because the kitchen is slow per se, but because the pool is full. Cranking UV_THREADPOOL_SIZE to 16 hires more cooks. Spawning cluster workers opens a second restaurant next door with its own kitchen. Spinning up worker_threads puts a second waiter on the floor of the same restaurant.
And in the middle of all of it, if the waiter stops to balance the books for 30 seconds (a long synchronous JS computation), nobody gets served. Not the salad people, not the brisket people, nobody. That's the whole risk model of Node in one image.
What to actually do with this
A few things drop out of all this that are worth holding onto:
- Network-heavy workloads are Node's home turf. The kernel poller scales to absurd numbers of connections at near-zero cost. Don't reach for
clusteror workers reflexively for an HTTP API. Measure first. - Watch the thread pool when you do a lot of
fs,crypto.pbkdf2, orzlib. A surprising number of "Node is slow under load" diagnoses end with raisingUV_THREADPOOL_SIZEfrom 4 to 16 or 32. - Prefer
dns.resolve*overdns.lookupif you do heavy hostname resolution.lookupcompetes for the same thread pool your file I/O uses. - Never run long CPU work on the main thread. Anything past ~10 ms of pure JS in a callback is making every other request on that process wait. Push it into a
Worker. - Don't recurse with
process.nextTickor chain microtasks forever. They run between every callback in every phase. They can starve I/O without your code ever looking like an infinite loop.
The reason Node's concurrency model is worth understanding deeply isn't to win arguments. It's that the failure modes (slow file reads under load, mysterious DNS latency, a single slow callback wrecking throughput) only make sense once you can see both worlds at once: the kernel poller doing one job, the thread pool doing another, and the event loop calmly stitching them back into your JS callbacks one at a time.
Node isn't single-threaded. It's single-threaded where it matters to you, and quietly multi-threaded everywhere else. Once you can see both halves, you stop being surprised by it.