A request hits your Node.js server. You wrote app.get('/users/:id', handler). Somewhere between curl pressing enter and your res.json(user) call, an absolute mountain of machinery moved: kernel queues, file descriptors, a C parser written in TypeScript, a JavaScript event emitter, a chain of middleware closures, and a stream that's secretly a writable. Most of it you never see.
This piece is the floor-to-ceiling tour. Not "Node.js uses an event loop, isn't that neat." The actual sequence, with the actual pieces named. By the end you should be able to point at every layer between the wire and your handler, and know why req is a readable stream, why middleware is a linked list of closures, and why res.end() doesn't always send bytes immediately.
We'll follow a single GET request the whole way through.
Stage 0: Before anyone calls your code
Your process is asleep. It already called server.listen(3000) minutes ago. What that actually did, in order:
- Created a TCP socket via
socket(AF_INET, SOCK_STREAM, 0). - Called
bind()on it to port 3000. - Called
listen(fd, backlog). The defaultbacklogNode passes is 511. Seenet.Server.listen()docs. The kernel then caps this at whatevernet.core.somaxconnis set to. On Linux that default was 128 until kernel 5.4 raised it to 4096 in late 2019. - Registered the listening file descriptor with libuv so the event loop wakes when something arrives.
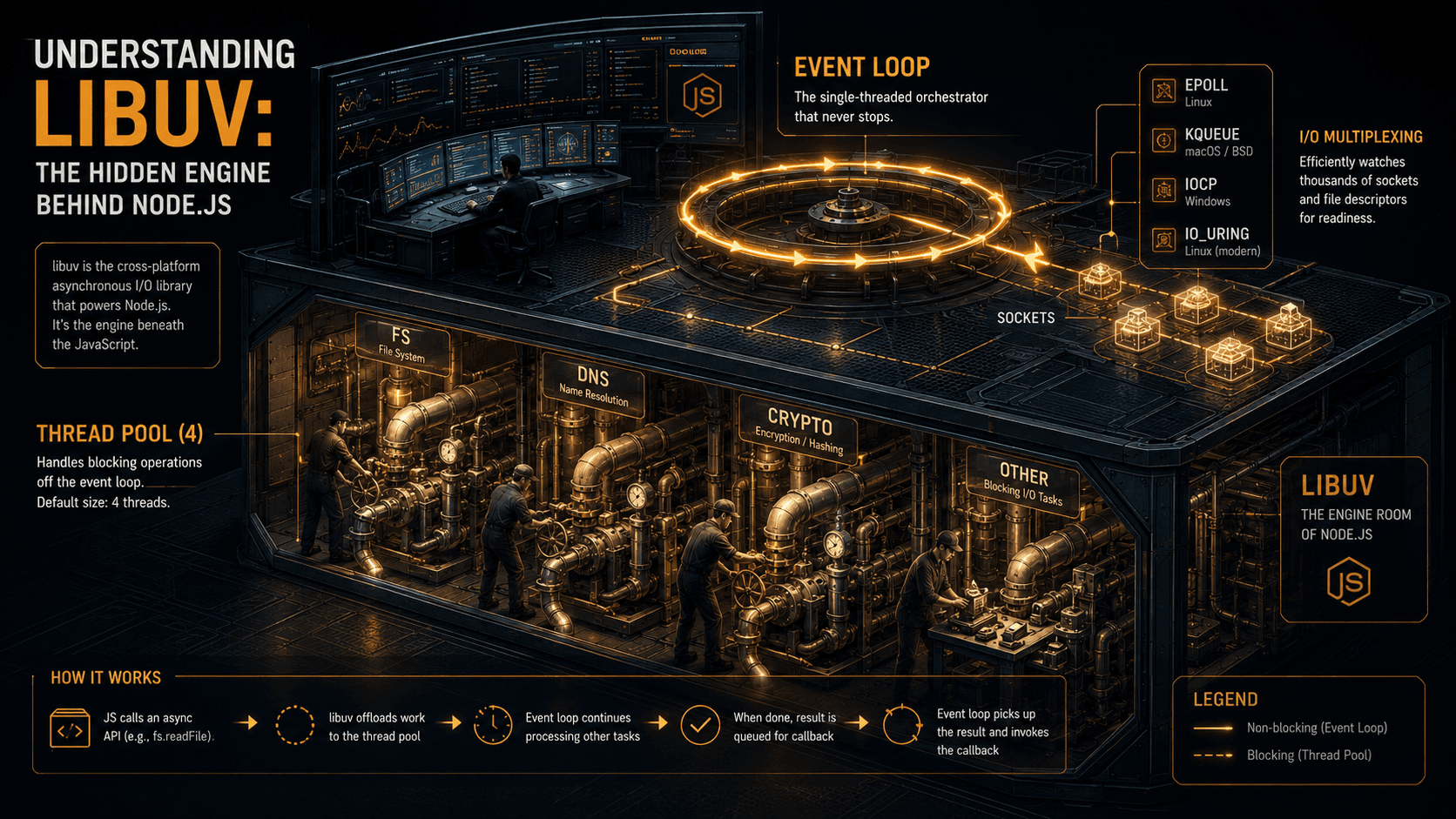
That last step is the one that matters. Libuv is the C library underneath Node that abstracts away the difference between epoll on Linux, kqueue on macOS/BSD, and IOCP on Windows. On Linux, what actually happens is epoll_ctl(EPOLL_CTL_ADD, listen_fd, EPOLLIN), meaning "wake me when this fd is readable." Then your process blocks in epoll_wait(), consuming roughly zero CPU. This is the famous "non-blocking" part. It's not magic; it's a single syscall that the kernel resolves whenever there's work.
So before any request arrives, your Node process is sitting inside epoll_wait, holding a file descriptor pointing at a kernel-managed queue, with a callback wired to fire when a connection lands.
Stage 1: The TCP handshake (kernel only, Node still asleep)
A client connects. The three-way handshake (SYN, SYN-ACK, ACK) happens entirely inside the kernel. Your Node process doesn't know yet. The kernel maintains two queues for your listening socket:
- The SYN queue (incomplete connections, half-open). Sized by
tcp_max_syn_backlog. - The accept queue (fully-established connections, ready for
accept()). Sized by the smaller of yourlisten()backlog andsomaxconn.
When the handshake finishes, the connection moves from the SYN queue to the accept queue. Now the listening fd becomes readable, and epoll_wait returns. Your event loop wakes up.
Stage 2: libuv wakes up and accepts
uv__io_poll returns. Libuv sees the listening fd is readable, calls accept4() to pull the new connection off the kernel's accept queue, and gets a fresh file descriptor for the connection itself. It registers that fd with epoll too, with both EPOLLIN and EPOLLOUT interest as needed.
Then libuv invokes the C++ callback that Node's net.Server registered. That callback constructs a new Socket JavaScript object (net.Socket extends stream.Duplex) and emits the 'connection' event on the server. This is the first moment JavaScript runs for this request. Everything up to here was kernel + libuv + C++.
A net.Server not wrapped in http.Server would hand you this socket directly via server.on('connection', ...). But you're running http.createServer(), which has an internal 'connection' listener that does one extra thing: it creates an HTTP parser and attaches it to the socket.
Stage 3: llhttp parses bytes into HTTP
You've maybe heard of the old http_parser C library (Joyent, mid-2000s). Node.js replaced it with llhttp, which has been the default parser since Node.js 12.0.0 (April 2019). It was written by Fedor Indutny: ~1,400 lines of TypeScript that describe the parser as a state machine, transpiled via llparse into pure C. The TypeScript-to-C generator means the same rules produce a parser fast enough to live on the hot path of every request.
Why does this matter? Because bytes off a TCP socket are not a request. They're a byte stream: possibly partial, possibly multiple requests pipelined, possibly broken. The parser is what turns:
GET /users/42 HTTP/1.1\r\n
Host: api.example.com\r\n
Accept: application/json\r\n
\r\n...into structured fields you can use from JavaScript. Bytes are fed in chunk by chunk as the socket emits 'data'. The parser is a state machine: expecting method, expecting URL, expecting header name, expecting header value, expecting body byte. Each chunk advances the state.
When the parser finishes the request line + headers, it calls back into Node's C++ binding, which constructs an IncomingMessage (your req) and a ServerResponse (your res), then emits 'request' on the http.Server. That is finally where your code enters the picture.
Stage 4: The request event reaches your code
http.Server extends EventEmitter. The 'request' event has one listener by default: the function you passed to createServer(handler), or in Express's case, the Express app itself (which is a function: (req, res, next) => router.handle(req, res, next)).
That listener gets called synchronously from inside the parser callback. There's no microtask hop yet. The same JavaScript turn that finished parsing the headers also runs the first line of your code.
A minimal raw-Node server makes this whole flow visible:
const http = require('node:http');
const server = http.createServer((req, res) => {
// req is an IncomingMessage (Readable stream)
// res is a ServerResponse (Writable stream)
console.log(req.method, req.url, req.headers.host);
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(JSON.stringify({ ok: true }));
});
server.listen(3000);Every framework you've used (Express, Fastify, Koa, Hapi, Hono on Node) is a function passed to that createServer call (or server.on('request', fn)). Frameworks add structure on top, but the entry point is the same.
Stage 5: The middleware chain (Express edition)
Now we're inside framework land. Express models its pipeline as a stack of Layer objects on a Router. Every app.use(fn) and every route handler creates a new Layer. A Layer holds:
- A path pattern (
/,/users,/users/:id). - A handle function (your middleware or route handler).
- Some metadata (HTTP method, whether it's a route or middleware).
When the request arrives, Express walks this stack in registration order. For each layer whose path matches, it invokes:
layer.handle(req, res, next)next is the trick. It's not a magical keyword. It's a function Express constructs and closes over the index of the next layer to try. Calling next() means: "I'm done, advance." Calling next(err) means: "I'm done, but jump to the next error-handling middleware" (the ones with four args, (err, req, res, next)). Not calling next() and not ending the response means: the request hangs forever. The router has no timer. It's just sitting there with no one calling the continuation.
A simplified mental model of the router loop:
function handle(req, res, done) {
let idx = 0;
function next(err) {
const layer = stack[idx++];
if (!layer) return done(err);
if (!matches(layer, req)) return next(err);
if (err) {
if (layer.length === 4) layer.handle(err, req, res, next);
else next(err);
} else {
if (layer.length === 4) next(); // skip error mw
else layer.handle(req, res, next);
}
}
next();
}This is why order matters absolutely. app.use(logger) before app.use(authMiddleware) means every request gets logged before auth runs. Swap them and unauthenticated requests skip the log. The order in your file is the order of the linked list.
Body parsing is middleware too
express.json() is not a special hook. It's a regular middleware. It subscribes to req's 'data' and 'end' events, accumulates the chunks, JSON-parses them, and assigns to req.body, then calls next(). This is why it has to happen before your route handler, and why streaming endpoints (file uploads, server-sent events) typically skip the body parser and consume req directly as a stream. The "body" is not something the framework magically gives you. Someone, somewhere, drained the readable.
Async handlers, then and now
Express 4 and earlier didn't await your handler's promise. If you did async (req, res) => { await db.fetch(...) } and it threw, Express never saw the rejection, and the request hung until the client gave up. Express 5 (released stable in October 2024) finally handles returned promises and forwards rejections into the error chain. If you're still on Express 4 you wrap with asyncHandler helpers; on 5 you can drop them.
Stage 6: The response side, res.write and res.end
res is a ServerResponse, which extends http.OutgoingMessage, which extends stream.Writable. So res.write(chunk) and res.end(chunk) are not "send this now." They're "queue this for the writable stream." A few subtle things happen in order:
res.writeHead(200, {...}): composes the status line and header lines into a buffer. Does not send.- The first
res.write()orres.end(): concatenates the header buffer in front of the body chunk and asks the underlying socket to write. - The socket's
write(): calls libuv'suv_write, which calls the kernel'swrite()/send()on the fd. The kernel copies into the TCP send buffer. - The kernel sends bytes over the wire when its TCP state machine says it can, respecting window size, congestion control, and Nagle's algorithm (unless you disabled it with
socket.setNoDelay(true)).
res.end() doesn't mean "bytes are on the network." It means "I have no more data to queue." The actual bytes leave when the kernel decides. If the receive buffer at the other end is full, your write may return false, which is Node's way of telling you to slow down. That's backpressure. Most handlers ignore it because their payloads fit in the send buffer comfortably, but for large streamed responses, ignoring backpressure means unbounded memory growth.
Keep-alive vs close
Once res.end() is called, what happens to the socket?
- If the request was HTTP/1.1 and neither side sent
Connection: close, the socket stays open. The same parser is reset for the next request. The whole stage-3-to-stage-6 dance repeats on the same fd. - If
Connection: closewas set, the socket is half-closed (your side sends FIN), and once the client's FIN arrives, the fd is removed from epoll, the socket is destroyed, the parser is freed.
This is why benchmarking tools like wrk or autocannon slam your server so much harder with keep-alive than without. You skip the entire handshake + parser-init cost per request.
Stage 7: Where the event loop actually fits
People talk about "the event loop" like it's the whole story. It's really the scheduler that ties everything we just walked through into one process. Each turn of the loop:
- Timers phase: fires
setTimeout/setIntervalcallbacks whose time has come. - Pending I/O callbacks: some deferred system-level callbacks.
- Poll phase: this is where
epoll_waitlives. Blocks for incoming I/O. This is the phase where your request arrives. - Check phase:
setImmediatecallbacks. - Close callbacks:
'close'events.
Between every phase (and inside many of them), Node drains the microtask queue: process.nextTick first, then resolved Promise.then callbacks. So when your await db.query(...) resolves, the .then doesn't wait for the next poll phase. It runs at the next microtask drain, which can be in the middle of the current phase.
The two patterns most worth knowing:
process.nextTickstarvation: keep recursively callingprocess.nextTick, and you'll never reach the poll phase. The server stops accepting new connections, buttopshows 100% CPU. The fix is to break the chain withsetImmediate, which yields to the loop.- Long synchronous handlers block everything. The event loop has no preemption. If your handler runs a 200ms regex on a 10MB payload, no other request gets parsed, accepted, or responded to during those 200ms. Hence "Node.js is single-threaded" warnings. The loop is the thread.
Putting it together
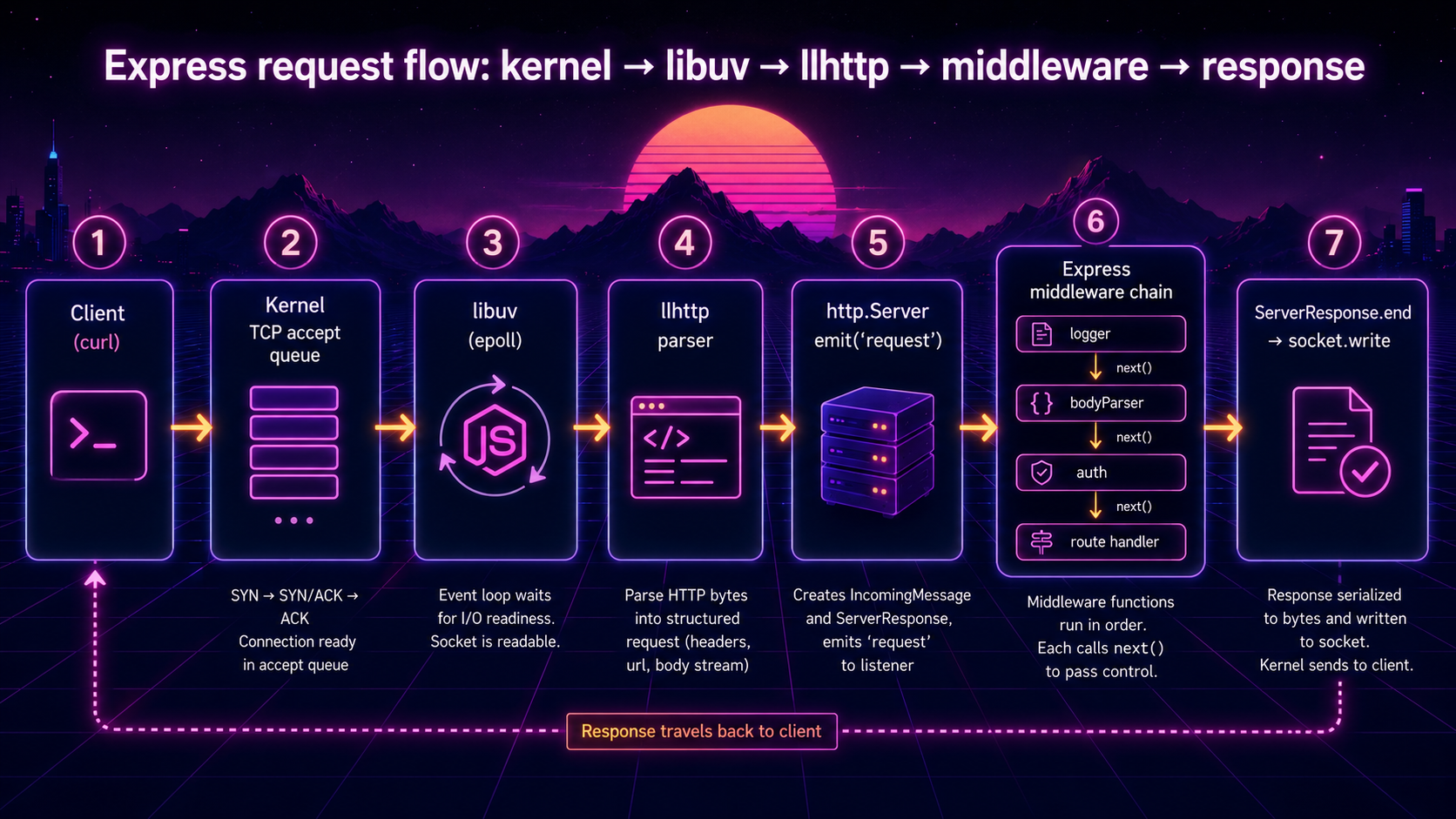
If you trace a single GET request through everything above, this is the sequence:
1. client sends SYN
2. kernel completes 3-way handshake, queues fd in accept queue
3. epoll wakes Node's event loop (poll phase)
4. libuv calls accept4(), gets connection fd
5. net.Socket created in JS, 'connection' event on http.Server
6. http.Server attaches an llhttp parser to the socket
7. socket 'data' events feed bytes into the parser
8. parser finishes headers → constructs IncomingMessage + ServerResponse
9. 'request' event fires → Express app function invoked
10. middleware chain walks: logger → bodyParser → auth → route handler
11. body parser drains req's readable, sets req.body
12. handler computes response, calls res.json(...)
13. res.writeHead composes headers, res.end queues body
14. socket.write → uv_write → kernel send buffer
15. kernel sends bytes; client receives
16. keep-alive: socket stays open, parser resets, back to step 7Sixteen steps. Half of them are running before your function does. Half of them happen after your function returns. The framework you use changes step 10. Fastify uses a radix tree router and synchronous hooks instead of Express's layer stack, Koa uses async/await composition with await next() instead of callback next(), Hono on Node uses its own minimal router. They all sit between step 9 and step 13. Everything outside that window is shared.
Why this matters
You don't need to memorise the steps. The reason this lifecycle is worth carrying around in your head is what it lets you reason about when things go wrong:
- "Why does my server return RST under load?" -> Accept queue is full because
somaxconnis 128 and you didn't raise it. - "Why does
req.bodyexist in this handler but not that one?" -> Body parser middleware wasn't reached, or the route is mounted before it. - "Why doesn't my error get caught?" -> Sync throw inside an async function on Express 4, and the promise rejection has nowhere to go.
- "Why does
res.end()followed byprocess.exit()lose bytes?" -> End queues, exit kills the loop before libuv flushes. - "Why does one slow regex tank latency for everyone?" -> The poll phase can't run while userland JavaScript runs.
Every one of these is something a developer hits eventually. Every one becomes obvious once you can name the layer where it lives.
The mental model that pays the most rent is the one where you can point at any stage and say "this is kernel," "this is libuv," "this is parser," "this is my code," "this is stream backpressure." The framework you're using is just one of those layers. Knowing where it sits, and what's underneath it, is what turns a guess into a diagnosis.